
大家好,我是东邪狂想,本文是Redis、MySQL、Kafka系列第一篇。
本专题主要讲解Redis/MySQL/Kafka,先阐述它们之间的共性的设计思想,然后逐步讲解Redis/MySQL/Kafka分别是如何具体实现,最终被塑造成这样一个“有血有肉”的系统
在学习MySQL、Redis、Kafka的过程中,发现了它们之间其实存在一定的共性,在设计之初,均考虑过相同的问题,在《Designing Data-Intensive Applications》这本中便提到了很多系统的设计思想。本篇文章精炼一下其中通用的设计框架,一文搞懂Redis/MySQL/Kafka设计理念。
其实好多系统都是对这套框架的具体实现,个人认为只要理解这套框架,学习其它类似的系统也没有啥困难,仅仅是不同系统在具体实现有所差别,但是搞懂框架,就相当于学到一套数学公式,摸透了系统的“骨架”,其余的只是在“血肉”上有所差别,即有的系统“腿部肌肉”强壮,而有的系统“肱二头肌”更发达,如此而已。
废话不多说,直接介绍设计思想中的三大骨骼,分别是可扩展性,高可用,持久化,太抽象?不明白?没关系,下面分别一一介绍这三大中流砥柱:
一、高可用:简单来说就是系统是否可靠,系统容灾能力如何,是否有多个节点提供服务,某个节点突然挂掉,系统是否还能正常提供服务或者某个节点挂掉是否会导致用户的部分数据丢失等。
二、可扩展性:也可以说是伸缩性,即系统应对负载增长的能力,比如系统是否可以通过增加节点来应对徒增的流量或者负载,服务依旧保持良好的性能。
三、持久化:保存系统的状态信息,使得系统因为某种原因重启,但数据不会丢。
图书馆
本文尝试通过讲述如何经营一个能够应对高流量阅读任务、容灾等级强的图书馆,来讲明白MySQL\Redis\Kafka的设计框架
比如现在我们需要设计一个数据存储系统,那么设计之初我们将所有的数据均放在一个机器节点上,那么这样会有什么问题呢?
所有的数据“放在一个篮子里”,意味着后续所有用户查询数据时,所有的查询请求将全部打在同一个机器节点上,形成了一种“一夫当关,万夫莫开”的局面。
这里我给大家举个例子,好比大家去图书馆借阅图书,如果图书馆仅有一本《射雕英雄传》,但是有10同学想要借本书,但最终只有一位同学能把《射雕英雄传》借到手,其余的9位同学只能依次等上一位同学把书归还之后,再继续借阅。
那么,如何才能想办法要10位同学尽快读上《射雕英雄传》呢,毕竟武侠小说谁能不爱呢?办法之一就是图书馆可以把《射雕英雄传》这本书多复印几本或者把一本书的各个章节撕开分别借阅,这样就可以应对多位同学同时借阅图书的情况了!这样即使后续借书的同学再次增多,依旧可以按照同样的方法,再复制同样的一本书,放到其它书架上,提高图书馆的服务能力,这便是“可扩展性”。
其中,原版书籍所在的书架可以称为“主库节点Leader”,复印的书籍所在的书架可以称为“从库节点Follower”。
虽然图书馆已经可以应对高流量阅读人群了,进一步试想在图书馆运营过程中,假如图书馆的“小说类书架”不慎发生火灾,导致书架上的书焚毁了,那么意味同学们无法读到《射雕英雄传》等小说了!!!
那我们应该怎么办?比如《射雕英雄传》这本小说已经复印了多本,图书馆可以它们放到不同的书架上,这样即使某个书架不慎毁灭,那么还可以有其它的书架依旧可以找到《射雕英雄传》并提供服务,这便是“高可用”。
对应在系统中也是一样,我们可以将一个机器节点上的数据复制多份,备份的同时,还可以将其分散到其它机器节点上,这样多个机器均可以提供查询服务,并发访问量以及访问速度自然而然就大大提升了。
但是试想后面数据量逐渐增加,一个机器节点上根本放不下完整的一份数据集合,那该怎么办?类似把一本书按照章节撕开,同样可以将一个大型的数据集合拆分成较小的子集(称分区),然后不同的分区可以放在不同的机器节点上。
如图,我们将数据集合拆分成了2份Partition1和Partition2,同时为了保证高可用,Partition1和Partition2各自有一个副本,避免因为某个机器节点挂掉导致数据丢失
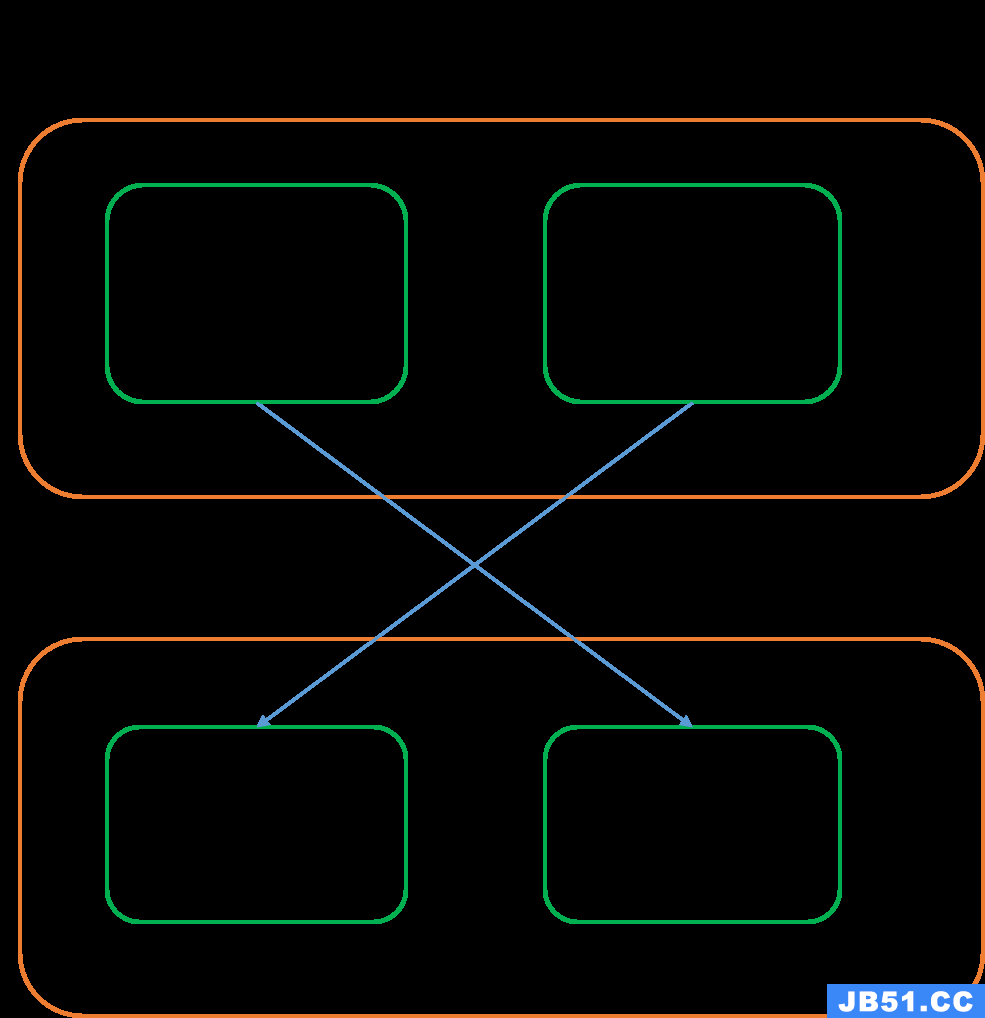
注:分区一是提高服务的并发能力,另一方面是考虑到单一机器节点无法直接持有整个数据集
以上通过改造图书馆的例子,详细阐述了“分区和复制”的思想,成功让图书馆既可以应对高流量人群,又可以提高容灾能力。
主从节点引入的新挑战
目前我们的“图书馆”还并不能完全算作高扩展性,高可用的系统,因为还有一系列的问题需要解决。
比如目前图书馆为了应对高流量的阅读人群,增加了新的书架(即系统增加了新的节点),那么图书馆的书是否需要重新分配吗(重平衡分区),比如分到新书架上一些书?
如果之前的旧书架(主节点)上增加了新订阅的小说《天龙八部》,那新增的书架(从节点)如何才能拿到《天龙八部》的复印本呢?这便涉及到主从同步问题。
另外考虑新增书架与旧书架之间 同步书籍出现延迟,那么将会导致一个问题,即旧书架的阅读人群能读到《天龙八部》,而新书架的阅读人群需要再等几天才能阅读,这便是主从同步延迟问题。
另外,假如同学小明向图书馆捐赠了一本《天龙八部》,然后图书馆放在了旧书架上,小明过了一周后图书馆借阅,发现在书架上根本没有《天龙八部》,哦!原来这是新增的书架,上面还没有复印版的《天龙八部》,这便是主从同步延迟导致的主从不一致问题。
主从同步
前面提到系统为了支持更高的并发量以及高可用性,会增设多个节点,即系统由主节点和多个从节点组成,其中一般只有主节点处理写请求,从节点仅支持读请求,主节点接收写请求而新增的数据会逐渐同步到从节点上,即主从同步
主从同步如何实现才能保证新增节点拥有主库节点的精确副本呢?仅仅将数据文件从主节点拷贝到新节点是不可以的,因为客户端总是在不断的向数据库写入数据,换句话说数据是不断变化的。
一般可以通过如下流程进行主从同步:
a. 在某个时刻获取主库的一致性快照,而不必锁定整个数据库;
b. 将快照复制到新的从库节点;
c. 从库连接到主库,并拉取快照之后发生的所有变更;
d. 当从库处理完快照之后积压的数据变更,便“赶上”了主库;
过程很简单,但是快照是什么,如何获取得到快照呢,这便涉及到数据落盘(持久化)问题。
快照指的是系统在某个时刻的状态,类似“照片”可以将某个时刻的人物定格,快照也可以将系统的某个时刻的状态保存下来。一般有如下几种方式,可以对系统的状态进行刻画:
1. 基于语句:简单来说,主库记录下每个写入请求的语句,从节点拿到这些语句执行一般就能获取同样的数据。这种实现方式很粗糙,在某些场景下式不适合的,比如一些非确定性函数语句now()等,在不同时间执行得到的数据是不一样的
2. 预写式日志(Write Ahead Log):是一种物理日志,系统的存储引擎也是直接使用该日志存储数据,直接记录了磁盘块的哪些字节发生了修改,因此从库使用该日志便可以直接建立和主库节点一模一样的数据副本
3. 逻辑日志:基于行的一种逻辑日志,以行为粒度,描述对数据库表的修改:对于新插入的行,日志直接包含所有列的新值;对于删除的行,日志包含足够信息标识已删除的行(通常是主键);对于更新的行,日志同样需要包含足够的信息标识更新的行,另外需要记录更改后的列的新值
注:其实在MySQL、Redis、Kafka均有上述类似的实现,比如个人认为Redis中的RDB文件便是一种预写式日志,RDB文件为二进制的格式,通过该文件可以将数据库还原到生成RDB文件是的状态,同时Redis中还有AOF日志,那便是基于行的逻辑日志。
同样的MySQL中的binlog日志也是预写式二进制日志,而redo log则是逻辑日志
那上述的同步过程是同步复制还是异步复制呢?通常不同的系统有不同的实现,或者是一个配置项。同步复制优点是能保证从库有与主库一致的最新数据副本,如果主库突然失效,那么从库上的数据并不落后与主库;缺点是如果同步从库没有及时响应,主库便无法执行写入操作。因此将所有从库设置为同步不切实际,因为任何一个节点的中断,均会导致整个系统stop the world。
通常情况下,基于领导者(主节点)的复制都设置成异步,异步复制优点是主从复制并不阻塞主节点处理写入;缺点是如果主库失效,那么尚未同步给从库的数据将会丢弃,意味着即使已经向客户端写入成功,但是其实因为主库故障,数据已经丢失了;
比如在Redis中主从同步便是异步操作,大致过程与前面介绍的流程一致:
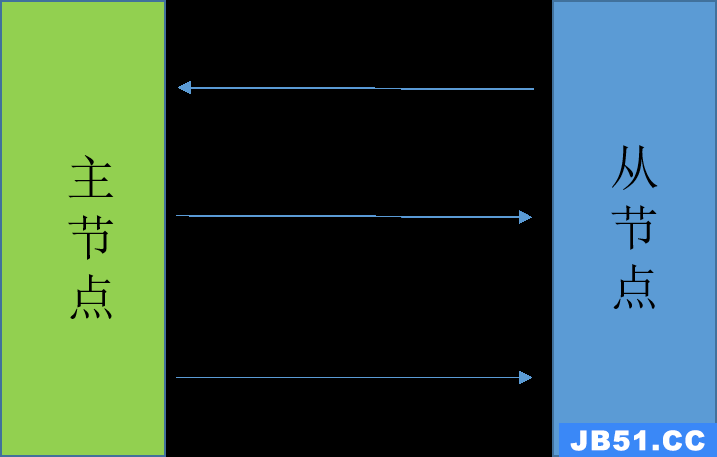
a. 首先,redis从节点向主节点返送SYNC命令
b. 主节点收到SYNC命令后,会执行BGSAVE命令,在后台生成一个RDB快照文件,同时使用一个缓冲记录后续执行的写命令
c. 主节点将生成的RDB文件发送给从节点,从节点便可以更新至主节点执行BGSAVE命令时的数据库状态
d. 主节点再把缓冲区中记录的所有写命令发送给从节点,这样从节点便完全追赶上了主节点,主从同步完成
同样的MySQL中的主从同步也是异步操作,大致原理类似只不是日志文件是binlog,具体细节不再赘述。
到这里本篇文章对设计框架的介绍已经接近尾声,但是还有好多问题,这里没有做过多概述,比如:主从异步复制时,同步延迟会导致主从数据不一致的问题,这里各个系统均会存在类似的问题,但是优化方法不太一样,后续准备单独介绍Redis、MySQL、Kafka时会一一解答。
小结
本篇以图书馆为例子,讲解了Redis、MySQL、Kafka三大系统的设计框架,通过分区和复制的思想保证系统可扩展、高可用,又对主从节点同步(同步复制/异步复制)做了节点的介绍,关于主从同步还有许多问题待解决,本篇文章碍于篇幅并没有一一提及,后续系列文章会一一解答。
本篇文章希望大家有所收获,通过设计框架的“三大骨骼”,懂得如何一步一步思考,比如为了系统的高扩展高可用,需要多增加从节点,那么便涉及到主从同步?是同步复制还是异步复制?引入从节点之后,数据需要重新分配吗?从节点中的数据稍微落后与主节点,即主从延迟问题会导致不同的用户读到的数据可能不一致?节点挂掉之后(区分主节点还是从节点),系统如何处理?系统是否支持事务?
欢迎大家留言讨论,指出不足之处!

原文地址:https://blog.csdn.net/qq_44886707/article/details/135307726
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。