
【本站】5月16日消息,富士 X Summit BKK 2023与FUJIKINA Bangkok 2023将于5月24日和27日在曼谷举行。消息来源透露,富士公司有可能在这两个活动上发布全新相机富士X-S20,然而官方并未对此进行证实。此外,富士的镜头产品线也将迎来一位新成员。根据最新爆料

【本站】4月5日消息,据最新曝光的消息,富士将推出全新的 XF8mm f/3.5 R WR 大广角镜头。这款镜头适用于富士 APS-C 相机,相当于全画幅相机的12mm焦距,最大光圈为F3.5,并配有光圈环,可以全天候使用。富士已经推迟了 X Summit 2023 发布会的日期,但是相信
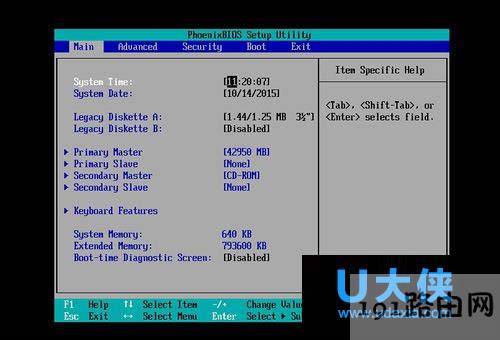
原标题:"Win7系统开机显示EXITING INTEL PXE ROM无法启动"相关电脑问题教程分享。 - 来源:191路由网。
众所周知,电脑在开机的时候经常会遇到各种提示导致开机故障,比如有
没有最强的式神,只有相对强大的阵容。sr属性一般为一条s,r卡主要是辅助,属性并不重要。阵容里面主力输出要技能和属性都要够好,其他的辅助只需要技能好用就可以了。
1.山兔:山兔是一个必练的式神,在大佬的阵容中山兔和镰鼬搭配将是一个非常恐怖的存在,山 兔的三技能兔子舞能给全体成员增加30%的行动条和10%的攻击,仅消耗两鬼火。 御魂搭配:2号位速度,4号位效果抵抗、6号位生命加成。可配置招财猫、火灵。 式神搭配:百搭。2.座敖童子:座敖童子在没有辉夜姬和追月神的时候可谓是占据主导地位。座敖童子的二技能福运昌 隆在开场前获得三鬼火,三技能消耗30%的生命获得三鬼火,非常传统的一个打火式 神。 御魂搭配:2、4、6号位生命加成,副属性有速度,最好保持在115左右。可搭配火 灵、招财猫、木魅。 式神搭配:百搭。3.丑时之女:丑时之女可能在刚入坑的时候回把它当做“仓库管理员”,但是丑时之女是一个非常有 用的辅助式神,三技能稻草人能给输出式神打出高伤害。 丑时之女在御魂、逢魔中的作用非常大哦。 御魂搭配:2、4、6号位生命加成,副属性最好有速度,可搭配被服、心眼等。 式神搭配:玉藻前、大天狗等群攻式神4.独眼小僧:独眼小僧可谓是R式神中最有毒的存在,在般诺没有封被自动技能时群攻技能式神总会 在打的过程中不知不觉的消失,所以独眼小僧在结界突破和道馆中的作用是非常巨
先把主机架好,先到人物的选择界面,系统出现一个手柄匹配的界面让你匹配手柄,按住手柄的“L,R”两个按键三秒就可以连接,或者回到主界面,点击“手柄”点击“更改握法/顺序”按住手柄的“L,R”两个按键三秒就可以连接。

文章目录说明1. 新罗马字体、字体大小、加粗、标题居中2.排序倒序3.ggplot 按组排序和按水平排序4.修改图例移除图例5.去掉背景以及x轴标签(

原文链接:https://www.cnblogs.com/tecdat/p/11064949.htmlTableau是当今数据科学和商业智能专
我有一些每周的价值,我想根据配置文件向量进行细分。
假设我的每周数据是:
<pre><code>data <- data
我的目标是在数据框中设置列名。该数据帧的名称存储在变量name_of_table中。
<pre><code>name_of_table<-
这可能非常简单,但是我不确定为什么它不起作用。
对于输入向量<code>b</code>,我想编写一个函数
我有一个1000名员工的数据集。这有800名在职员工和200名已辞职。
我正在尝试进行logistic回归以预测
使用以下方法读取高大的XLSX文件让我有些不高兴:
<pre><code>> file = readxl::read_xlsx(filename, "sheetname
我有一个看起来像这样的数据集:
<pre><code>AccountID Product1 Product2 Product3 Product4
1
我有一个如下所示的excel工作表设置,并已作为df加载:
<pre><code>GPS_Lat GPS_Lon Location
50.70528 -12
我正在尝试将类似<a href="https://infra.clarin.eu/content/libs/DataTables-1.10.6/examples/api/show_hide.html" rel="nofollow norefe
这是我在这里的第一条消息。我正在尝试从edX R课程解决R练习,但我陷入其中。如果有人可以帮助我解
当我尝试运行Shinyproxy时遇到错误500。这些是我得到的错误。
<pre><code>Caused by: com.spotify.docker.client.excep
<strong>回答:非常感谢Bob,ffs问题没有指定comment ='#'。当“跳过”应该跳过违规行时,为什么这样做仍
我正在尝试解析估算的薪水字符串以创建一个名为“ Salary.Min”的新字段,该字段应为数字值。看起来很
