
Kafka-Kraft 模式架构部署
Kafka网址:https://kafka.apache.org/
PS:因环境原因此文档内端口都有修改!
1.去官网下载二进制包
PS:3.4.0是目前最新的版本!需要jdk1.8及以上版本启动。
[root@k8s-node1 ~]# wget https://downloads.apache.org/kafka/3.4.0/kafka_2.12-3.4.0.tgz
[root@k8s-node1 ~]# tar zxvf kafka-3.4.0-src.tgz
[root@k8s-node1 ~]# cd kafka_2.12-3.4.0/
[root@k8s-node1 kafka_2.12-3.4.0]# ls
bin config libs LICENSE licenses NOTICE site-docs
2.修改配置文件
[root@k8s-node1 ~]# cd kafka_2.12-3.4.0/config/kraft/
[root@k8s-node1 kraft]# vim server.properties
......
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@192.168.1.10:9094,2@192.168.1.11:9094,3@192.168.1.12:9094
listeners=PLAINTEXT://192.168.12.10:9093,CONTROLLER://192.168.12.10:9094
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.1.10:9093
log.dirs=logs
- process.roles:kafka的角色 controller相当于主、broker节点相当于从,主类似zk功能;
- node.id:节点ID标识每台机器;
- controller.quorum.voters:controller角色的集群IP+访问端口;
- listeners:代理将用于创建服务器套接字的内容;
- inter.broker.listener.name:内部角色代理名称(主从可配置PLAINTEXT,从配置CONTROLLER);
- advertised.listeners:角色代理向外暴露的IP+端口;
- log.dirs:数据日志文件及Kafka启动生成的UUID存储位置;
集群内配置文件示例:
PS:配置文件内是三controller,五broker;
#node1
process.roles=broker,CONTROLLER://192.168.12.10:9094
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.1.10:9093
log.dirs=logs
#node2
process.roles=broker,controller
node.id=2
controller.quorum.voters=1@192.168.1.10:9094,3@192.168.1.12:9094
listeners=PLAINTEXT://192.168.12.11:9093,CONTROLLER://192.168.12.11:9094
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.1.11:9093
log.dirs=logs
#node3
process.roles=broker,controller
node.id=3
controller.quorum.voters=1@192.168.1.10:9094,3@192.168.1.12:9094
listeners=PLAINTEXT://192.168.12.12:9093,CONTROLLER://192.168.12.12:9094
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.1.12:9093
log.dirs=logs
#node4
process.roles=broker
node.id=4
controller.quorum.voters=1@192.168.1.10:9094,3@192.168.1.12:9094
listeners=PLAINTEXT://192.168.12.13:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.1.13:9093
log.dirs=logs
#node5
process.roles=broker
node.id=5
controller.quorum.voters=1@192.168.1.10:9094,3@192.168.1.12:9094
listeners=PLAINTEXT://192.168.12.14:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://192.168.1.14:9093
log.dirs=logs
3.启动
3.1 在node01执行
# 生成集群uuid
[root@k8s-node1 kafka_2.12-3.4.0]# KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
# 格式日志目录
[root@k8s-node1 kafka_2.12-3.4.0]# bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
3.2 在集群内剩余机器执行
# 格式日志目录
[root@k8s-node2 kafka_2.12-3.4.0]# bin/kafka-storage.sh format -t (node01生成的UUID) -c config/kraft/server.properties
[root@k8s-node3 kafka_2.12-3.4.0]# bin/kafka-storage.sh format -t (node01生成的UUID) -c config/kraft/server.properties
[root@k8s-node4 kafka_2.12-3.4.0]# bin/kafka-storage.sh format -t (node01生成的UUID) -c config/kraft/server.properties
[root@k8s-node5 kafka_2.12-3.4.0]# bin/kafka-storage.sh format -t (node01生成的UUID) -c config/kraft/server.properties
3.3 启动Kafka
[root@k8s-node1 kafka_2.12-3.4.0]# bin/kafka-server-start.sh config/kraft/server.properties
[root@k8s-node1 kafka_2.12-3.4.0]# ss -lnt| grep -E '9093|9094'
LISTEN 0 50 [::ffff:192.168.12.134]:9093 [::]:*
LISTEN 0 50 [::ffff:192.168.12.134]:9094 [::]:*
PS:9093是PLAINTEXT的端口,9094是broker的端口。
4.命令测试Kafka集群
[root@k8s-node1 kafka_2.12-3.4.0]# ./kafka-topics.sh --create --bootstrap-server 192.168.1.10:9093 --replication-factor 2 --partitions 5 --topic test
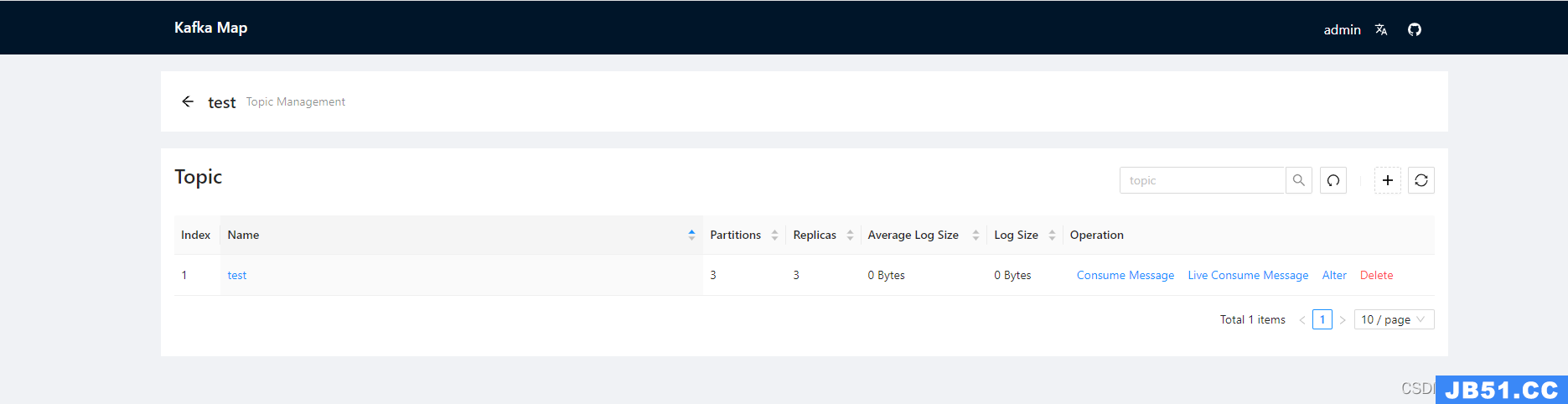
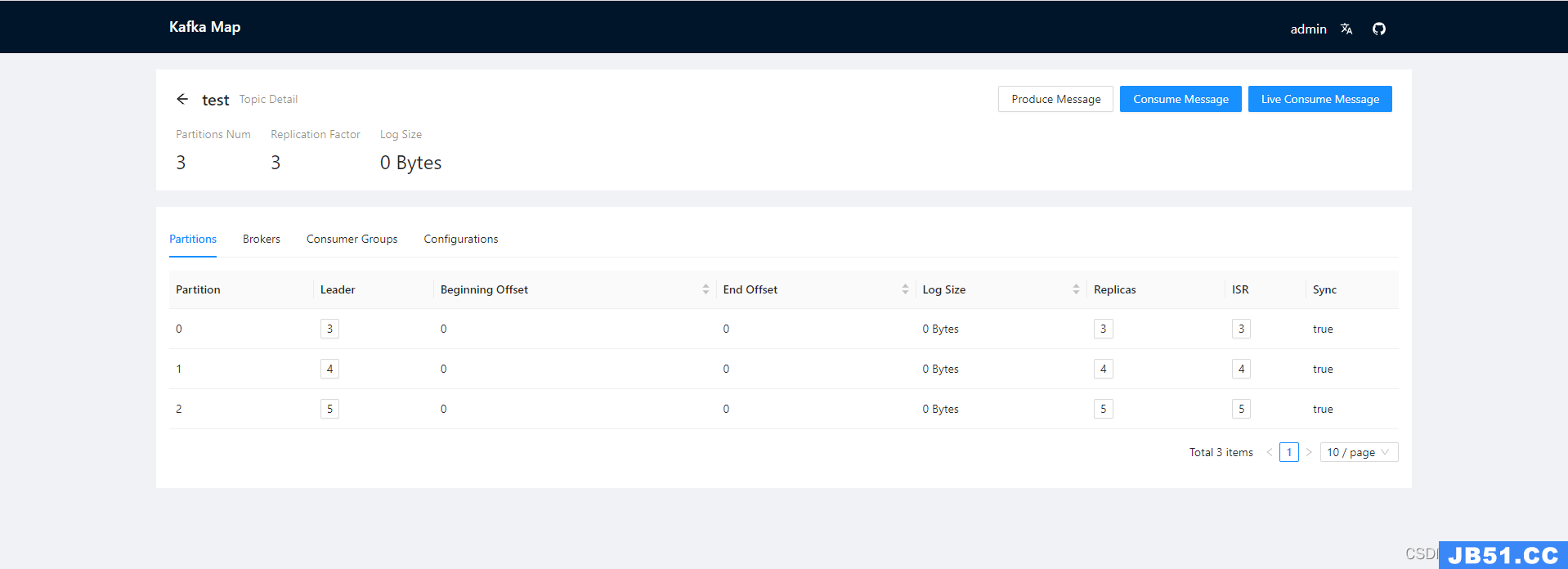
5.Kafka Map 测试访问
PS:Kafka Map是一款可视化平台软件,可参考链接自行搭建。 https://gitee.com/dushixiang/kafka-map/

原文地址:https://blog.csdn.net/weixin_45191791/article/details/129277464
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。