
概述
介绍
Apache Atlas为组织提供开放式元数据管理和治理功能,用以构建其数据资产目录,对这些资产进行分类和管理,并为数据分析师和数据治理团队,提供围绕这些数据资产的协作功能。
如果想要对这些数据做好管理,光用文字、文档等东西是不够的,必须用图。Atlas就是把元数据变成图的工具。
Atlas的具体功能如下:
| 元数据分类 | 支持对元数据进行分类管理,例如个人信息,敏感信息等 |
|---|---|
| 元数据检索 | 可按照元数据类型、元数据分类进行检索,支持全文检索 |
| 血缘依赖 | 支持表到表和字段到字段之间的血缘依赖,便于进行问题回溯和影响分析等 |
(1)表与表之间的血缘依赖

(2)字段与字段之间的血缘依赖
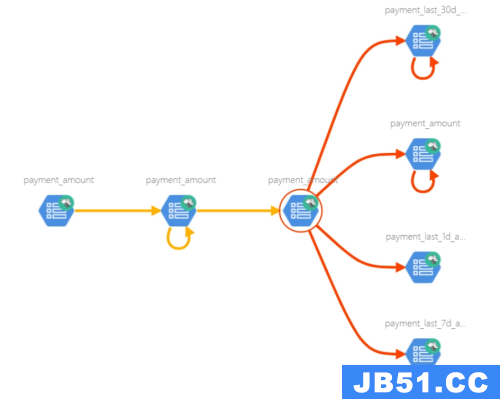
架构发展
(1)下图描述了第一代元数据架构。它通常是一个经典的单体前端(可能是一个 Flask 应用程序),连接到主要存储进行查询(通常是 MySQL/Postgres),一个用于提供搜索查询的搜索索引(通常是 Elasticsearch),并且对于这种架构的第 1.5 代,也许一旦达到关系数据库的“递归查询”限制,就使用了处理谱系(通常是 Neo4j)图形查询的图形索引。
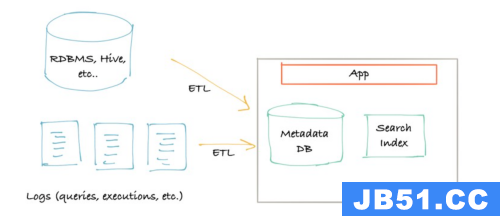
(2)很快,第二代的架构出现了。单体应用程序已拆分为位于元数据存储数据库前面的服务。该服务提供了一个 API,允许使用推送机制将元数据写入系统。
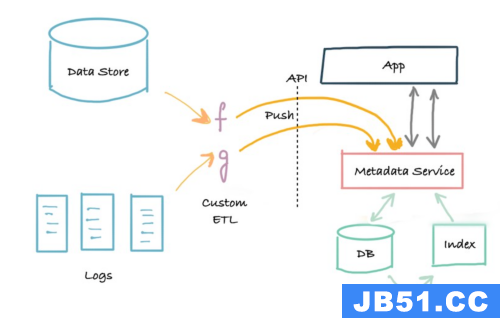
(3)第三代架构是基于事件的元数据管理架构,客户可以根据他们的需要以不同的方式与元数据数据库交互。
元数据的低延迟查找、对元数据属性进行全文和排名搜索的能力、对元数据关系的图形查询以及全扫描和分析能力。
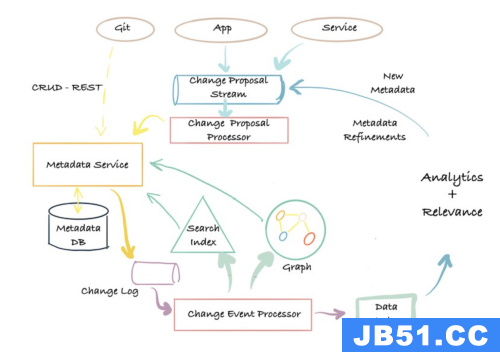
Apache Atlas 就是采用的这种架构,并且与Hadoop 生态系统紧密耦合。
架构原理
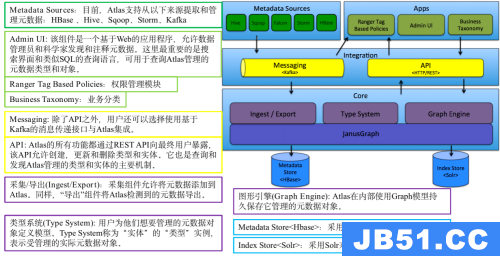
Atlas包括以下组件:
- 采用Hbase存储元数据
- 采用Solr实现索引
- Ingest/Export 采集导出组件、 Type System类型系统 、 Graph Engine图形引擎 共同构成Atlas的核心机制
- 所有功能通过API向用户提供,也可以通过Kafka消息系统进行集成
- Atlas支持各种源获取元数据:Hive,Sqoop,Storm。。。
- 还有优秀的UI支持
(1)Core层
Atlas核心包含以下组件:
-
采集/导出:采集组件允许将元数据添加到Atlas。同样,“导出”组件将Atlas检测到的元数据更改公开为事件。消费者可以使用这些更改事件来实时响应元数据的变更。
-
类型(Type)系统: Atlas允许用户为他们想要管理的元数据对象定义模型。该模型由称为“类型”的定义组成。称为“实体”的“类型”实例表示受管理的实际元数据对象。 Type System是一个允许用户定义和管理类型和实体的组件。开箱即用的Atlas管理的所有元数据对象(例如Hive表)都使用类型建模并表示为实体。要在Atlas中存储新类型的元数据,需要了解类型系统组件的概念。
需要注意的一个关键点是Atlas中建模的一般特性允许数据管理员和集成商定义技术元数据和业务元数据。也可以使用Atlas的功能定义两者之间的丰富关系。
-
图形引擎: Atlas在内部使用Graph模型持久保存它管理的元数据对象。这种方法提供了很大的灵活性,可以有效地处理元数据对象之间的丰富关系。图形引擎组件负责在Atlas类型系统的类型和实体之间进行转换,以及底层图形持久性模型。除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便可以有效地搜索它们。 Atlas使用JanusGraph存储元数据对象。
(2)Integration层
在Atlas中,用户可以使用以下的两种方式管理元数据:
- API: Atlas的所有功能都通过REST API向最终用户暴露,该API允许创建,更新和删除类型和实体。它也是查询和发现Atlas管理的类型和实体的主要机制。
- Messaging: 除了API之外,用户还可以选择使用基于Kafka的消息传递接口与Atlas集成。这对于将元数据对象传递到Atlas以及使用Atlas使用可以构建应用程序的元数据更改事件都很有用。如果希望使用与Atlas更松散耦合的集成来实现更好的可伸缩性,可靠性等,则消息传递接口特别有用。Atlas使用Apache Kafka作为通知服务器,用于钩子和元数据通知事件的下游消费者之间的通信。事件由钩子和Atlas写入不同的Kafka主题。
(3)Metadata sources层
Atlas支持开箱即用的多种元数据源集成。未来还将增加更多集成。目前,Atlas支持从以下来源提取和管理元数据:
- HBase
- Hive
- Sqoop
- Storm
- Kafka
集成意味着两件事:Atlas定义的元数据模型用于表示这些组件的对象。 Atlas提供了从这些组件中摄取元数据对象的组件(在某些情况下实时或以批处理模式)。
(4)Applications层
Atlas管理的元数据被各种应用程序使用,以满足许多治理需求。
Atlas Admin UI: 该组件是一个基于Web的应用程序,允许数据管理员和科学家发现和注释元数据。这里最重要的是搜索界面和类似SQL的查询语言,可用于查询Atlas管理的元数据类型和对象。 Admin UI使用Atlas的REST API来构建其功能。
Tag Based Policies:Apache Ranger是Hadoop生态系统的高级安全管理解决方案,可与各种Hadoop组件进行广泛集成。通过与Atlas集成,Ranger允许安全管理员定义元数据驱动的安全策略以实现有效的治理。 Ranger是Atlas通知的元数据更改事件的使用者。
类型系统介绍
Atlas允许用户为他们想要管理的元数据对象定义模型。该模型由称为type(类型)的定义组成。称为entities(实体)的type(类型)实例表示受管理的实际元数据对象。 Type System是一个允许用户定义和管理类型和实体的组件。开箱即用的Atlas管理的所有元数据对象(例如Hive表)都使用类型建模并表示为实体。要在Atlas中存储新类型的元数据,需要了解类型系统组件的概念。
类型
Atlas中的 “类型” 定义了如何存储和访问特定类型的元数据对象。类型表示了所定义元数据对象的一个或多个属性集合。具有开发背景的用户可以将 “类型” 理解成面向对象的编程语言的 “类” 定义的或关系数据库的 “表模式”。
- 可以通过该API获取Atlas的所有类型:http://atlas:21000/api/atlas/v2/types/typedefs
- 下面通过该API获取hive_table类型的定义:http://atlas:21000/api/atlas/v2/types/typedef/name/hive_table
hive_table类型介绍
使用Atlas的类型的其中一个示例是Hive表。 Hive表定义了以下属性:
Name: hive_table
TypeCategory: Entity
SuperTypes: DataSet
Attributes:
name: string
db: hive_db
owner: string
createTime: date
lastAccessTime: date
comment: string
retention: int
sd: hive_storagedesc
partitionKeys: array<hive_column>
aliases: array<string>
columns: array<hive_column>
parameters: map<string,string>
viewOriginalText: string
viewExpandedText: string
tableType: string
temporary: boolean
{
"category": "ENTITY","guid": "30a12b7c-faed-4ead-ad83-868893ebed93","createdBy": "cloudera-scm","updatedBy": "cloudera-scm","createTime": 1536203750750,"updateTime": 1536203750750,"version": 1,"name": "hive_table","description": "hive_table","typeVersion": "1.1","options": {
"schemaElementsAttribute": "columns"
},"attributeDefs": [
{
"name": "db","typeName": "hive_db","isOptional": false,"cardinality": "SINGLE","valuesMinCount": 1,"valuesMaxCount": 1,"isUnique": false,"isIndexable": false,"includeInNotification": false
},{
"name": "createTime","typeName": "date","isOptional": true,"valuesMinCount": 0,{
"name": "lastAccessTime",{
"name": "comment","typeName": "string",{
"name": "retention","typeName": "int",{
"name": "sd","typeName": "hive_storagedesc","includeInNotification": false,"constraints": [
{
"type": "ownedRef"
}
]
},{
"name": "partitionKeys","typeName": "array<hive_column>","cardinality": "SET","valuesMaxCount": 2147483647,{
"name": "aliases","typeName": "array<string>",{
"name": "columns",{
"name": "parameters","typeName": "map<string,string>",{
"name": "viewOriginalText",{
"name": "viewExpandedText",{
"name": "tableType",{
"name": "temporary","typeName": "boolean","isIndexable": true,"includeInNotification": false
}
],"superTypes": [
"DataSet"
],"subTypes": []
}
从上面的例子中可以注意到以下几点:
-
Atlas中的类型(Type)由
name唯一标识 -
attributeDefs表示该类型中属性的定义
-
Type具有元类型。Atlas中有以下元类型:
- 原始元类型(Primitive metatypes):boolean,byte,short,int,long,float,double,biginteger,bigdecimal,string,date
- 枚举元型(Enum metatypes)
- 集合元类型(Collection metatypes:):array,map
- 复合元类型(Composite metatypes):Entity,Struct,Classification,Relationship
-
实体(Entity)和分类(Classification)类型可以从其他类型继承,称为“超类型/父类型”(supertype) ,它包括在超类型中定义的属性。这允许建模者在一组相关类型等中定义公共属性。类似于面向对象语言如何为类定义父类。 Atlas中的类型也可以从多个超类型扩展。
在此示例中,每个配置单元表都从称为
DataSet的预定义超类型扩展。稍后将提供有关此预定义类型的更多详细信息。 -
具有元类型
Entity,Struct,Classification或Relationship的类型可以具有属性的集合。每个属性都有一个名称(例如:name)和一些其他相关属性。可以使用表达式type_name.attribute_name引用属性。值得注意的是,属性本身是使用Atlas元类型定义的。在此示例中,hive_table.name是String,hive_table.aliases是一个字符串数组,hive_table.db是指一个名为hive_db的类型的实例,依此类推。
-
属性中的类型引用(如hive_table.db)特别有趣,使用这样的属性,我们可以定义Atlas中定义的两种类型之间的任意关系,从而构建丰富的模型。此外,还可以将引用列表收集为属性类型(例如,hive_table.columns,表示从hive_table到hive_column类型的引用列表)
DataSet类型定义
{
"category": "ENTITY","guid": "d31c0a02-6999-4f81-a62a-07d7654aec84","createTime": 1536203676149,"updateTime": 1536203676149,"name": "DataSet","description": "DataSet","attributeDefs": [],"superTypes": [
"Asset"
],"subTypes": [
"rdbms_foreign_key","rdbms_db","kafka_topic","hive_table","sqoop_dbdatastore","hbase_column","rdbms_instance","falcon_feed","jms_topic","hbase_table","rdbms_table","rdbms_column","rdbms_index","hbase_column_family","access_info","hive_column","avro_type","fs_path"
]
}
可以看到DataSet有很多的子类型,部分Atlas自带的类型都继承自DataSet。
同时DataSet继承自Asset,Asset表示资产的意思,其中定义了一些通用的属性。
Asset类型定义
{
"category": "ENTITY","guid": "349a5c61-47c3-4f4b-9a79-7fd59454a73a","createTime": 1536203676083,"updateTime": 1536203676083,"name": "Asset","description": "Asset","attributeDefs": [
{
"name": "name",{
"name": "description",{
"name": "owner","superTypes": [
"Referenceable"
],"DataSet","Infrastructure","Process","hbase_namespace","hive_db"
]
}
Asset类型中定义了3个属性
- name:名称
- owner:所属人
- description:描述
它也有不少子类型,表示资产的意义,比如说hive数据库hive_db,hbase命名空间hbase_namespace。它继承自Referenceable类型。
Referenceable类型定义
{
"category": "ENTITY","guid": "34c72533-2e80-4e5c-9226-e15b163f98d1","createTime": 1536203673540,"updateTime": 1536203673540,"name": "Referenceable","description": "Referenceable","typeVersion": "1.0","attributeDefs": [
{
"name": "qualifiedName","isUnique": true,"superTypes": [],"subTypes": [
"hive_storagedesc","Asset"
]
}
该类型定义了一个非常重要的属性,qualifiedName, 该类型中唯一限定名,可以通过该属性配合类型名在Atlas中查找对应的唯一实体内容,注意与guid的区别,guid是全局唯一的。
例如:
- 一个hive数据库的qualifiedName:test@primary
- 该数据库test下表test_table的qualifiedName:test.test_table@primary
- 该表test_table中字段name的qualifiedName:test.test_table.name@primary
@primary表示集群默认名字,通过如下配置集群名称,通过加上集群名称,在不同集群间唯一标识一个实体
atlas.cluster.name
primary
Process类型定义
{
"category": "ENTITY","guid": "7c03ccad-29aa-4c5f-8a27-19b536068f69","createTime": 1536203677547,"updateTime": 1536203677547,"name": "Process","description": "Process","attributeDefs": [
{
"name": "inputs","typeName": "array<DataSet>",{
"name": "outputs","subTypes": [
"falcon_feed_replication","falcon_process","falcon_feed_creation","sqoop_process","hive_column_lineage","storm_topology","hive_process"
]
}
- Process类型继承自Asset类型,所以自带有name,owner,description,quailifiedName四种属性
- 它自己特有的inputs和outputs表示该过程的输入输出,它是Atlas血缘管理中所有类型的超类
在概念上,它可以用于表示任何数据变换操作。例如,将原始数据的 hive 表转换为存储某个聚合的另一个 hive 表的 ETL 过程可以是扩展过程类型的特定类型。流程类型有两个特定的属性,输入和输出。输入和输出都是 DataSet 实体的数组。因此,Process 类型的实例可以使用这些输入和输出来捕获 DataSet 的 lineage 如何演变。
Entities(实体)
Atlas中的entity是type的特定值或实例,因此表示现实世界中的特定元数据对象。用我们对面向对象编程语言的类比,实例(instance)是某个类(Class)的对象(Object)。
实体的其中一个示例就是Hive表。Hive在’default’数据库中有一个名为’customers’的表。该表是hive_table类型的Atlas中的“实体”。由于是实体类型的实例,它将具有作为Hive表’type’的一部分的每个属性的值,例如:
guid: "9ba387dd-fa76-429c-b791-ffc338d3c91f"
typeName: "hive_table"
status: "ACTIVE"
values:
name: “customers”
db: { "guid": "b42c6cfc-c1e7-42fd-a9e6-890e0adf33bc","typeName": "hive_db" }
owner: “admin”
createTime: 1490761686029
updateTime: 1516298102877
comment: null
retention: 0
sd: { "guid": "ff58025f-6854-4195-9f75-3a3058dd8dcf","typeName": "hive_storagedesc" }
partitionKeys: null
aliases: null
columns: [ { "guid": ""65e2204f-6a23-4130-934a-9679af6a211f","typeName": "hive_column" },{ "guid": ""d726de70-faca-46fb-9c99-cf04f6b579a6",...]
parameters: { "transient_lastDdlTime": "1466403208"}
viewOriginalText: null
viewExpandedText: null
tableType: “MANAGED_TABLE”
temporary: false
从上面的例子中可以注意到以下几点:
-
实体类型的每个实例都由唯一标识符GUID标识。此GUID由Atlas服务器在定义对象时生成,并在实体的整个生命周期内保持不变。在任何时间点,都可以使用其GUID访问此特定实体。
在此示例中,默认数据库中的“customers”表由GUID“9ba387dd-fa76-429c-b791-ffc338d3c91f”唯一标识。
-
实体具有给定类型,并且类型的名称随实体定义一起提供。
在此示例中,'customers’表是’hive_table’类型。
-
该实体的值是hive_table类型定义中定义的属性的所有属性名称及其值的映射。
属性值将根据属性的数据类型。实体类型属性将具有AtlasObjectId类型的值。
有了实体的这个设计,我们现在可以看到Entity和Struct元类型之间的区别。实体(Entity)和结构(Struct)都构成其他类型的属性。但是,实体类型的实例具有标识(具有GUID值),并且可以从其他实体引用(例如,从hive_table实体引用hive_db实体)。 Struct类型的实例没有自己的标识。 Struct类型的值是在实体本身内“嵌入”的属性集合。
{
"referredEntities" : {
"779734cc-9011-4066-9bb1-25df6f28ac72" : {
"typeName" : "hive_column","attributes" : {
"owner" : "wangjian5185","qualifiedName" : "test.student.age@primary","name" : "age","description" : null,"comment" : null,"position" : 1,"type" : "int","table" : {
"guid" : "75a0c17a-dfdb-4532-9aae-c87b64be958d","typeName" : "hive_table"
}
},"guid" : "779734cc-9011-4066-9bb1-25df6f28ac72","status" : "ACTIVE","createdBy" : "admin","updatedBy" : "admin","createTime" : 1536215508751,"updateTime" : 1536215508751,"version" : 0
},"c47aed54-e4d2-4080-aa7a-5428075f5b20" : {
"typeName" : "hive_column","qualifiedName" : "test.student.phone@primary","name" : "phone","position" : 2,"guid" : "c47aed54-e4d2-4080-aa7a-5428075f5b20","7c4b4cd5-841d-409b-b38a-77ec8779e252" : {
"typeName" : "hive_column","qualifiedName" : "test.student.name@primary","name" : "name","position" : 0,"type" : "string","guid" : "7c4b4cd5-841d-409b-b38a-77ec8779e252","a6038b00-ce2d-4612-9436-d63092d09182" : {
"typeName" : "hive_storagedesc","attributes" : {
"bucketCols" : null,"qualifiedName" : "test.student@primary_storage","sortCols" : null,"storedAsSubDirectories" : false,"location" : "hdfs://cdhtest/user/hive/warehouse/test.db/student","compressed" : false,"inputFormat" : "org.apache.hadoop.mapred.TextInputFormat","outputFormat" : "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat","parameters" : null,"typeName" : "hive_table"
},"serdeInfo" : {
"typeName" : "hive_serde","attributes" : {
"serializationLib" : "org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe","name" : null,"parameters" : null
}
},"numBuckets" : 0
},"guid" : "a6038b00-ce2d-4612-9436-d63092d09182","version" : 0
}
},"entity" : {
"typeName" : "hive_table","attributes" : {
"owner" : "wangjian5185","temporary" : false,"lastAccessTime" : 1533807252000,"aliases" : null,"qualifiedName" : "test.student@primary","columns" : [ {
"guid" : "7c4b4cd5-841d-409b-b38a-77ec8779e252","typeName" : "hive_column"
},{
"guid" : "779734cc-9011-4066-9bb1-25df6f28ac72",{
"guid" : "c47aed54-e4d2-4080-aa7a-5428075f5b20","typeName" : "hive_column"
} ],"viewExpandedText" : null,"sd" : {
"guid" : "a6038b00-ce2d-4612-9436-d63092d09182","typeName" : "hive_storagedesc"
},"tableType" : "MANAGED_TABLE","createTime" : 1533807252000,"name" : "student","partitionKeys" : null,"parameters" : {
"transient_lastDdlTime" : "1533807252"
},"db" : {
"guid" : "a804165e-77ff-4c60-9ee7-956760577a1e","typeName" : "hive_db"
},"retention" : 0,"viewOriginalText" : null
},"guid" : "75a0c17a-dfdb-4532-9aae-c87b64be958d","updateTime" : 1536281983181,"version" : 0
}
}
表名:student 包含3个列:name,age,phone
- 开头referredEntities中包含了该table的引用的实体对象,即3个列实体和一个hive_storagedesc实体(表示该表的存储信息),实际存储时存储的为它们的guid
- entity中包含了该表student的一些信息,name,owner,guid,status,attribute等等
- 作为 Class Type 实例的每个实体都由唯一标识符 GUID 标识。此 GUID 由 Atlas 服务器在定义对象时生成,并在实体的整个生命周期内保持不变。在任何时间点,可以使用其 GUID 来访问该特定实体。
Attributes(属性)
我们已经看到,属性(attributes)是在实体(Entity),结构(Struct),分类(Classification)和关系(Relationship)等元类型中定义的。但我们将属性列举为具有名称和元类型值。然而,Atlas中的attributes具有一些properties,这些properties定义了与类型系统相关的更多概念。
attributes具有以下properties:
name: string,typeName: string,isOptional: boolean,isIndexable: boolean,isUnique: boolean,cardinality: enum
"attributeDefs" : [ {
"name" : "db","typeName" : "hive_db","isOptional" : false,//请注意“isOptional = false”约束 - 如果没有db引用,则无法创建表实体。
"cardinality" : "SINGLE","valuesMinCount" : 1,"valuesMaxCount" : 1,"isUnique" : false,"isIndexable" : false
},{
"name" : "createTime","typeName" : "date","isOptional" : true,"cardinality" : "SINGLE","valuesMinCount" : 0,{
"name" : "columns","typeName" : "array<hive_column>","cardinality" : "SET","valuesMaxCount" : 2147483647,"isIndexable" : false,"constraints" : [ {
"type" : "ownedRef" //请注意列的“ownedRef”约束。通过这样,我们指出定义的列实体应始终绑定到它们所定义的表实体。
} ]
}
述属性具有以下含义:
-
name: 属性的名称 -
typeName:该属性类型,包括基本类型,以及date,各种type类型,和集合类型等等 -
isOptional:是否可选,false表示该属性必须指定 -
cardinality:有三种:SINGLE(单个),LIST(可重复多个),SET(不可重复多个) -
valuesMinCount:该属性最小个数 -
valuesMaxCount:该属性最大个数 -
isComposite:- 该标志表示建模的一个方面。如果将属性定义为复合(composite),则意味着它不能具有独立于其所包含的实体的生命周期。这个概念的一个很好的示例是构成hive表的一部分的列集。由于列在hive表外部没有意义,因此它们被定义为复合属性。
- 必须在Atlas中创建复合属性及其包含的实体。即,必须与hive表一起创建配置单元列。
-
isIndexable:标志指示是否应该对此属性建立索引,以便可以使用属性值作为谓词来执行查找,并且可以有效地执行查找。 -
isUnique- 同样与索引相关。如果指定为唯一,则表示在JanusGraph中为此属性创建了一个特殊索引,允许基于相等的查找。
- 具有该标志的真值的任何属性都被视为主键,以将该实体与其他实体区分开。因此,应该注意确保此属性确实在现实世界中为唯一属性建模。
- 对于例如考虑hive_table的name属性。在单独的情况下,名称不是hive_table的唯一属性,因为具有相同名称的表可以存在于多个数据库中。如果Atlas在多个集群中存储hive表的元数据,那么即使是一对(数据库名称,表名)也不是唯一的。在物理世界中,只有集群位置,数据库名称和表名称才能被视为唯一。
-
multiplicity: 标示该属性是必选(required),可选(optional)的还是可以是多值的(multi-valued)。如果实体的属性值定义与类型定义中的多重性声明不匹配,则这将违反约束,并且实体添加将失败。因此,该字段可用于定义元数据信息的一些约束。 -
constraints:限制类型,该属性的限制类型,猜测可以通过该值来实现类似于MySQL中外键的功能,默认值有如下3个:
根据上面的内容,让我们展开下面的hive表的一个attributes的属性定义。让我们看一下名为’db’的属性,它表示hive表所属的数据库:
安装
(1)Atlas官网地址:https://atlas.apache.org/
(2)文档查看地址:https://atlas.apache.org/2.1.0/index.html
(3)下载地址:https://www.apache.org/dyn/closer.cgi/atlas/2.1.0/apache-atlas-2.1.0-sources.tar.gz
安装环境准备
Atlas安装分为:集成自带的HBase + Solr;集成外部的HBase + Solr。通常企业开发中选择集成外部的HBase + Solr,方便项目整体进行集成操作。
以下是Atlas所以依赖的环境及集群规划。本文只包含Solr和Atlas的安装指南,其余所依赖服务的安装请参考前边章节。
| 服务名称 | 子服务 | 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 |
|---|---|---|---|---|
| JDK | √ | √ | √ | |
| Zookeeper | QuorumPeerMain | √ | √ | √ |
| Kafka | Kafka | √ | √ | √ |
| HBase | HMaster | √ | ||
| HRegionServer | √ | √ | √ | |
| Solr | Jar | √ | √ | √ |
| Hive | Hive | √ | ||
| Atlas | atlas | √ | ||
| 服务数总计 | 13 | 7 | 7 |
安装Solr-7.7.3
(1)在每台节点创建系统用户solr
[root@hadoop102 ~]# useradd solr
[root@hadoop102 ~]# echo solr | passwd --stdin solr
[root@hadoop103 ~]# useradd solr
[root@hadoop103 ~]# echo solr | passwd --stdin solr
[root@hadoop104 ~]# useradd solr
[root@hadoop104 ~]# echo solr | passwd --stdin solr
(2)解压solr-7.7.3.tgz到/opt/module目录,并改名为solr
[root@hadoop102 ~]# tar -zxvf solr-7.7.3.tgz -C /opt/module/
[root@hadoop102 ~]# mv solr-7.7.3/ solr
(3)修改solr目录的所有者为solr用户
[root@hadoop102 ~]# chown -R solr:solr /opt/module/solr
(4)修改solr配置文件
修改/opt/module/solr/bin/solr.in.sh文件中的以下属性:
ZK_HOST="hadoop102:2181,hadoop103:2181,hadoop104:2181"
(5)分发solr
[root@hadoop102 ~]# xsync /opt/module/solr
(6)启动solr集群
-
启动Zookeeper集群
[root@hadoop102 ~]# zk.sh start -
启动solr集群
出于安全考虑,不推荐使用root用户启动solr,此处使用solr用户,在所有节点执行以下命令启动solr集群
[root@hadoop102 ~]# sudo -i -u solr /opt/module/solr/bin/solr start [root@hadoop103 ~]# sudo -i -u solr /opt/module/solr/bin/solr start [root@hadoop104 ~]# sudo -i -u solr /opt/module/solr/bin/solr start出现 Happy Searching! 字样表明启动成功。

说明:上述警告内容是:solr推荐系统允许的最大进程数和最大打开文件数分别为65000和65000,而系统默认值低于推荐值。如需修改可参考以下步骤,修改完需要重启方可生效,此处可暂不修改。
(1)修改打开文件数限制 修改/etc/security/limits.conf文件,增加以下内容: * soft nofile 65000 * hard nofile 65000 (2)修改进程数限制 修改/etc/security/limits.d/20-nproc.conf文件 * soft nproc 65000 (3)重启服务器
(7)访问web页面
默认端口为8983,可指定三台节点中的任意一台IP,http://hadoop102:8983

提示:UI界面出现Cloud菜单栏时,Solr的Cloud模式才算部署成功。
安装Atlas2.1.0
(1)把apache-atlas-2.1.0-server.tar.gz 上传到hadoop102的/opt/software目录下
(2)解压apache-atlas-2.1.0-server.tar.gz 到/opt/module/目录下面
[root@hadoop102 software]# tar -zxvf apache-atlas-2.1.0-server.tar.gz -C /opt/module/
(3)修改apache-atlas-2.1.0的名称为atlas
[root@hadoop102 ~]# mv /opt/module/apache-atlas-2.1.0 /opt/module/atlas
Atlas配置
Atlas集成Hbase
(1)修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数
atlas.graph.storage.hostname=hadoop102:2181,hadoop104:2181
(2)修改/opt/module/atlas/conf/atlas-env.sh配置文件,增加以下内容
export HBASE_CONF_DIR=/opt/module/hbase/conf
Atlas集成Solr
(1)修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数
atlas.graph.index.search.backend=solr
atlas.graph.index.search.solr.mode=cloud
atlas.graph.index.search.solr.zookeeper-url=hadoop102:2181,hadoop104:2181
(2)创建solr collection
[root@hadoop102 ~]# sudo -i -u solr /opt/module/solr/bin/solr create -c vertex_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
[root@hadoop102 ~]# sudo -i -u solr /opt/module/solr/bin/solr create -c edge_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
[root@hadoop102 ~]# sudo -i -u solr /opt/module/solr/bin/solr create -c fulltext_index -d /opt/module/atlas/conf/solr -shards 3 -replicationFactor 2
Atlas集成Kafka
修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数
atlas.notification.embedded=false
atlas.kafka.data=/opt/module/kafka/data
atlas.kafka.zookeeper.connect= hadoop102:2181,hadoop104:2181/kafka
atlas.kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
Atlas Server配置
(1)修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数
######### Server Properties #########
atlas.rest.address=http://hadoop102:21000
# If enabled and set to true,this will run setup steps when the server starts
atlas.server.run.setup.on.start=false
######### Entity Audit Configs #########
atlas.audit.hbase.zookeeper.quorum=hadoop102:2181,hadoop104:2181
(2)记录性能指标,进入/opt/module/atlas/conf/路径,修改当前目录下的atlas-log4j.xml
[root@hadoop101 conf]# vim atlas-log4j.xml
#去掉如下代码的注释
<appender name="perf_appender" class="org.apache.log4j.DailyRollingFileAppender">
<param name="file" value="${atlas.log.dir}/atlas_perf.log" />
<param name="datePattern" value="'.'yyyy-MM-dd" />
<param name="append" value="true" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d|%t|%m%n" />
</layout>
</appender>
<logger name="org.apache.atlas.perf" additivity="false">
<level value="debug" />
<appender-ref ref="perf_appender" />
</logger>
Kerberos相关配置
若Hadoop集群开启了Kerberos认证,Atlas与Hadoop集群交互之前就需要先进行Kerberos认证。若Hadoop集群未开启Kerberos认证,则本节可跳过。
(1)为Atlas创建Kerberos主体,并生成keytab文件
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"addprinc -randkey atlas/hadoop102"
[root@hadoop102 ~]# kadmin -padmin/admin -wadmin -q"xst -k /etc/security/keytab/atlas.service.keytab atlas/hadoop102"
(2)修改/opt/module/atlas/conf/atlas-application.properties配置文件,增加以下参数
atlas.authentication.method=kerberos
atlas.authentication.principal=atlas/hadoop102@EXAMPLE.COM
atlas.authentication.keytab=/etc/security/keytab/atlas.service.keytab
Atlas集成Hive
(1)安装Hive Hook
-
解压Hive Hook
[root@hadoop102 ~]# tar -zxvf apache-atlas-2.1.0-hive-hook.tar.gz -
将Hive Hook依赖复制到Atlas安装路径
[root@hadoop102 ~]# cp -r apache-atlas-hive-hook-2.1.0/* /opt/module/atlas/ -
修改/opt/module/hive/conf/hive-env.sh配置文件
注:需先需改文件名
[root@hadoop102 ~]# mv hive-env.sh.template hive-env.sh增加如下参数
export HIVE_AUX_JARS_PATH=/opt/module/atlas/hook/hive
(2)修改Hive配置文件,在/opt/module/hive/conf/hive-site.xml文件中增加以下参数,配置Hive Hook。
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
(3)修改/opt/module/atlas/conf/atlas-application.properties配置文件中的以下参数
######### Hive Hook Configs #######
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
(4)将Atlas配置文件/opt/module/atlas/conf/atlas-application.properties
[root@hadoop102 ~]# cp /opt/module/atlas/conf/atlas-application.properties /opt/module/hive/conf/
Atlas启动
(1)启动Hadoop集群
在NameNode节点执行以下命令,启动HDFS:
[root@hadoop102 ~]# start-dfs.sh
在ResourceManager节点执行以下命令,启动Yarn:
[root@hadoop103 ~]# start-yarn.sh
(2)启动Zookeeper集群:
[root@hadoop102 ~]# zk.sh start
(3)启动Kafka集群:
[root@hadoop102 ~]# kf.sh start
(4)启动Hbase集群:
在HMaster节点执行以下命令,使用hbase用户启动HBase:
[root@hadoop102 ~]# sudo -i -u hbase start-hbase.sh
(5)启动Solr集群:
在所有节点执行以下命令,使用solr用户启动Solr:
[root@hadoop102 ~]# sudo -i -u solr /opt/module/solr/bin/solr start
[root@hadoop103 ~]# sudo -i -u solr /opt/module/solr/bin/solr start
[root@hadoop104 ~]# sudo -i -u solr /opt/module/solr/bin/solr start
(6)进入/opt/module/atlas路径,启动Atlas服务
[root@hadoop102 atlas]# bin/atlas_start.py
提示:
- 错误信息查看路径:/opt/module/atlas/logs/*.out和application.log
- 停止Atlas服务命令为atlas_stop.py
(7)访问Atlas的WebUI
注意:等待若干分钟。
账户:admin
密码:admin
Atlas使用
Atlas的使用相对简单,其主要工作是同步各服务(主要是Hive)的元数据,并构建元数据实体之间的关联关系,然后对所存储的元数据建立索引,最终未用户提供数据血缘查看及元数据检索等功能。
Atlas在安装之初,需手动执行一次元数据的全量导入,后续Atlas便会利用Hive Hook增量同步Hive的元数据。
Hive元数据初次导入
Atlas提供了一个Hive元数据导入的脚本,直接执行该脚本,即可完成Hive元数据的初次全量导入。
(1)导入Hive元数据
执行以下命令:
[root@hadoop102 ~]# /opt/module/atlas/hook-bin/import-hive.sh
按提示输入用户名:admin;输入密码:admin
Enter username for atlas :- admin
Enter password for atlas :-
等待片刻,出现以下日志,即表明导入成功:
Hive Meta Data import was successful!!!
(2)查看Hive元数据
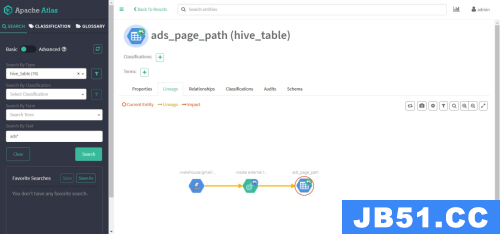
-
搜索hive_table类型的元数据,可已看到Atlas已经拿到了Hive元数据

-
任选一张表查看血缘依赖关系
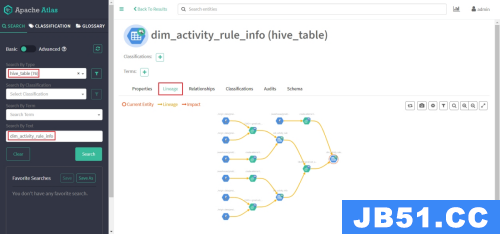
发现此时并未出现期望的血缘依赖,原因是Atlas是根据Hive所执行的SQL语句获取表与表之间以及字段与字段之间的依赖关系的,例如执行insert into table_a select * from table_b语句,Atlas就能获取table_a与table_b之间的依赖关系。此时并未执行任何SQL语句,故还不能出现血缘依赖关系。
Hive元数据增量同步
Hive元数据的增量同步,无需人为干预,只要Hive中的元数据发生变化(执行DDL语句),Hive Hook就会将元数据的变动通知Atlas。除此之外,Atlas还会根据DML语句获取数据之间的血缘关系。
全流程调度
为查看血缘关系效果,此处使用Azkaban将数仓的全流程调度一次。
(1)新数据准备
-
用户行为日志
a. 启动日志采集通道,包括Zookeeper,Kafka,Flume等
b. 修改hadoop102,hadoop103两台节点的/opt/module/applog/application.yml文件,将模拟日期改为2020-06-17如下:
#业务日期 mock.date: "2020-06-17"c. 执行生成日志的脚本:
# lg.shd. 等待片刻,观察HDFS是否出现2020-06-17的日志文件
-
业务数据
a. 修改/opt/module/db_log/application.properties,将模拟日期修改为2020-06-17,如下:
#业务日期 mock.date=2020-06-17b. 进入到/opt/module/db_log路径,执行模拟生成业务数据的命令,如下:
# java -jar gmall2020-mock-db-2021-01-22.jarc. 观察mysql的gmall数据中是否出现2020-06-17的数据
(2)启动Azkaban
注意需使用azkaban用户启动Azkaban
-
启动Executor Server
在各节点执行以下命令,启动Executor:
[root@hadoop102 ~]# sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh" [root@hadoop103 ~]# sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh" [root@hadoop104 ~]# sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-exec;bin/start-exec.sh" -
激活Executor Server,任选一台节点执行以下激活命令即可:
[root@hadoop102 ~]# curl http://hadoop102:12321/executor?action=activate [root@hadoop102 ~]# curl http://hadoop103:12321/executor?action=activate [root@hadoop102 ~]# curl http://hadoop104:12321/executor?action=activate -
启动Web Server:
[root@hadoop102 ~]# sudo -i -u azkaban bash -c "cd /opt/module/azkaban/azkaban-web;bin/start-web.sh"
(3)全流程调度
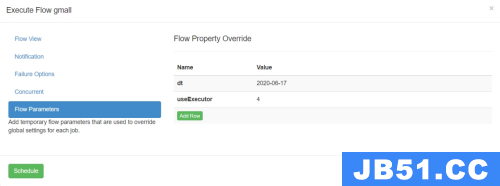
-
工作流参数
-
运行结果

查看血缘依赖
此时在通过Atlas查看Hive元数据,即可发现血缘依赖:
扩展内容
Atlas源码编译
安装Maven
(1)Maven下载:https://maven.apache.org/download.cgi
(2)把apache-maven-3.6.1-bin.tar.gz上传到linux的/opt/software目录下
(3)解压apache-maven-3.6.1-bin.tar.gz到/opt/module/目录下面
[root@hadoop102 software]# tar -zxvf apache-maven-3.6.1-bin.tar.gz -C /opt/module/
(4)修改apache-maven-3.6.1的名称为maven
[root@hadoop102 module]# mv apache-maven-3.6.1/ maven
(5)添加环境变量到/etc/profile中
[root@hadoop102 module]#vim /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven
export PATH=$PATH:$MAVEN_HOME/bin
(6)测试安装结果
[root@hadoop102 module]# source /etc/profile
[root@hadoop102 module]# mvn -v
(7)修改setting.xml,指定为阿里云:
[root@hadoop101 module]# cd /opt/module/maven/conf/
[root@hadoop102 maven]# vim settings.xml
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>UK</id>
<name>UK Central</name>
<url>http://uk.maven.org/maven2</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>repo1</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo1.maven.org/maven2/</url>
</mirror>
<mirror>
<id>repo2</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo2.maven.org/maven2/</url>
</mirror>
编译Atlas源码
(1)把apache-atlas-2.1.0-sources.tar.gz上传到hadoop102的/opt/software目录下
(2)解压apache-atlas-2.1.0-sources.tar.gz到/opt/module/目录下面
[root@hadoop101 software]# tar -zxvf apache-atlas-2.1.0-sources.tar.gz -C /opt/module/
(3)下载Atlas依赖
[root@hadoop101 software]# export MAVEN_OPTS="-Xms2g -Xmx2g"
[root@hadoop101 software]# cd /opt/module/apache-atlas-sources-2.1.0/
[root@hadoop101 apache-atlas-sources-2.1.0]# mvn clean -DskipTests install
[root@hadoop101 apache-atlas-sources-2.1.0]# mvn clean -DskipTests package -Pdis
#一定要在${atlas_home}执行
[root@hadoop101 apache-atlas-sources-2.1.0]# cd distro/target/
[root@hadoop101 target]# mv apache-atlas-2.1.0-server.tar.gz /opt/software/
[root@hadoop101 target]# mv apache-atlas-2.1.0-hive-hook.tar.gz /opt/software/
提示:执行过程比较长,会下载很多依赖,大约需要半个小时,期间如果报错很有可能是因为TimeOut造成的网络中断,重试即可。
Atlas内存配置
如果计划存储数万个元数据对象,建议调整参数值获得最佳的JVM GC性能。以下是常见的服务器端选项:
修改配置文件/opt/module/atlas/conf/atlas-env.sh:
#设置Atlas内存
export ATLAS_SERVER_OPTS="-server -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dumps/atlas_server.hprof -Xloggc:logs/gc-worker.log -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1m -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps"
#建议JDK1.7使用以下配置
export ATLAS_SERVER_HEAP="-Xms15360m -Xmx15360m -XX:MaxNewSize=3072m -XX:PermSize=100M -XX:MaxPermSize=512m"
#建议JDK1.8使用以下配置
export ATLAS_SERVER_HEAP="-Xms15360m -Xmx15360m -XX:MaxNewSize=5120m -XX:MetaspaceSize=100M -XX:MaxMetaspaceSize=512m"
#如果是Mac OS用户需要配置
export ATLAS_SERVER_OPTS="-Djava.awt.headless=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
参数说明: -XX:SoftRefLRUPolicyMSPerMB 此参数对管理具有许多并发用户的查询繁重工作负载的GC性能特别有用。
配置用户名密码
Atlas支持以下身份验证方法:File、Kerberos协议、LDAP协议。
通过修改配置文件atlas-application.properties文件开启或关闭三种验证方法:
atlas.authentication.method.kerberos=true|false
atlas.authentication.method.ldap=true|false
atlas.authentication.method.file=true|false
如果两个或多个身份证验证方法设置为true,如果较早的方法失败,则身份验证将回退到后一种方法。例如,如果Kerberos身份验证设置为true并且ldap身份验证也设置为true,那么,如果对于没有kerberos principal和keytab的请求,LDAP身份验证将作为后备方案。
本文主要讲解采用文件方式修改用户名和密码设置。其他方式可以参见官网配置即可。
(1)打开/opt/module/atlas/conf/users-credentials.properties文件
[atguigu@hadoop102 conf]$ vim users-credentials.properties
#username=group::sha256-password
admin=ADMIN::8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
rangertagsync=RANGER_TAG_SYNC::e3f67240f5117d1753c940dae9eea772d36ed5fe9bd9c94a300e40413f1afb9d
admin是用户名称
8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918是采用sha256加密的密码,默认密码为admin。
(2)例如:修改用户名称为atguigu,密码为atguigu
-
获取sha256加密的atguigu密码:
[atguigu@hadoop102 conf]$ echo -n "atguigu"|sha256sum 2628be627712c3555d65e0e5f9101dbdd403626e6646b72fdf728a20c5261dc2 -
修改用户名和密码:
[atguigu@hadoop102 conf]$ vim users-credentials.properties #username=group::sha256-password atguigu=ADMIN::2628be627712c3555d65e0e5f9101dbdd403626e6646b72fdf728a20c5261dc2 rangertagsync=RANGER_TAG_SYNC::e3f67240f5117d1753c940dae9eea772d36ed5fe9bd9c94a300e40413f1afb9d
原文地址:https://blog.csdn.net/qq_44766883/article/details/131228442
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。