
消息队列的作用就是提高运行速度,防止线程堵塞。
kafka的作用
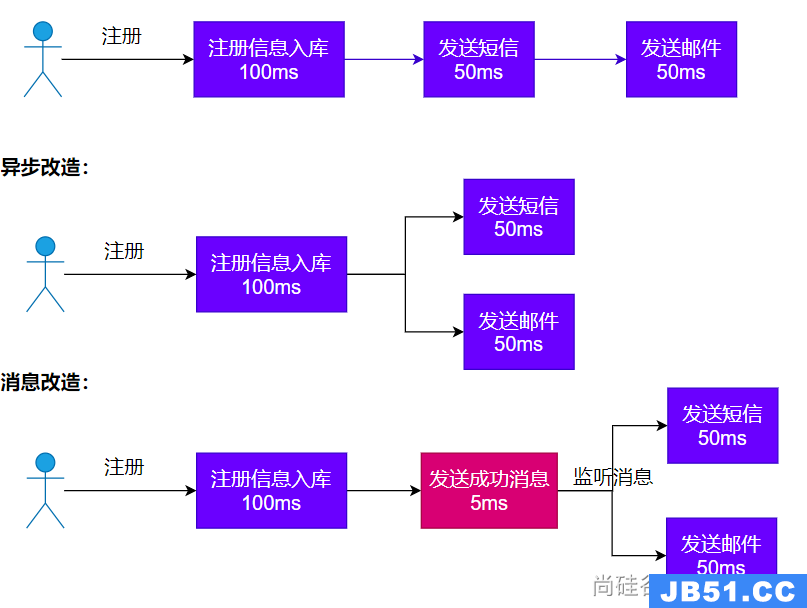
异步
解耦
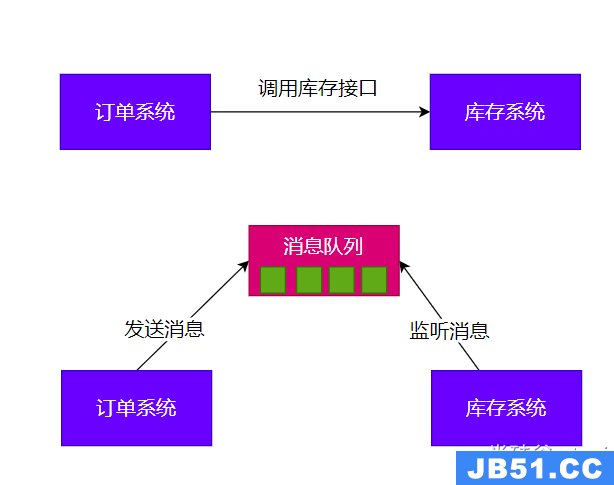
如果使用原来的直接调用对应业务的方式,在被调用业务发生修改是,调用业务也需要修改代码,存在很大的耦合,所以使用消息队列的方式,后续我们只需要关注消息的发送,无需关注业务的内部实现,大大的降低了耦合性。
削峰
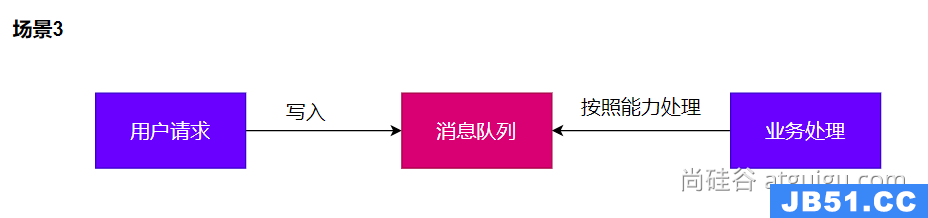
在一些业务场景小(如:限时秒杀),此时在同一个时间内会有大量的请求发向服务器,这就会导致服务器瘫痪,所以这里引入的消息队列的方式,这些请求会一一的给消息队列发送消息,服务器通过一次处理对应个数的消息来处理对应的请求,最终实现削峰,防止服务器瘫痪。
缓冲
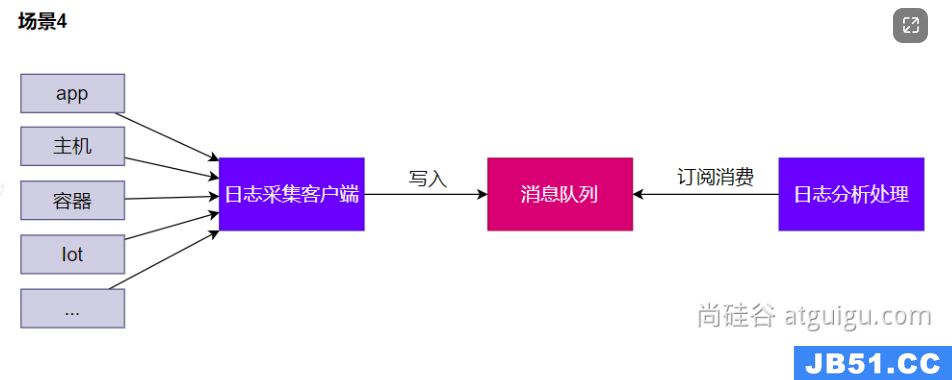
和削峰类似就是通过消息队列的形式处理请求,防止服务器瘫痪。
消息模式
1.消息点对点模式

2.消息发布订阅模式

kafka工作原理
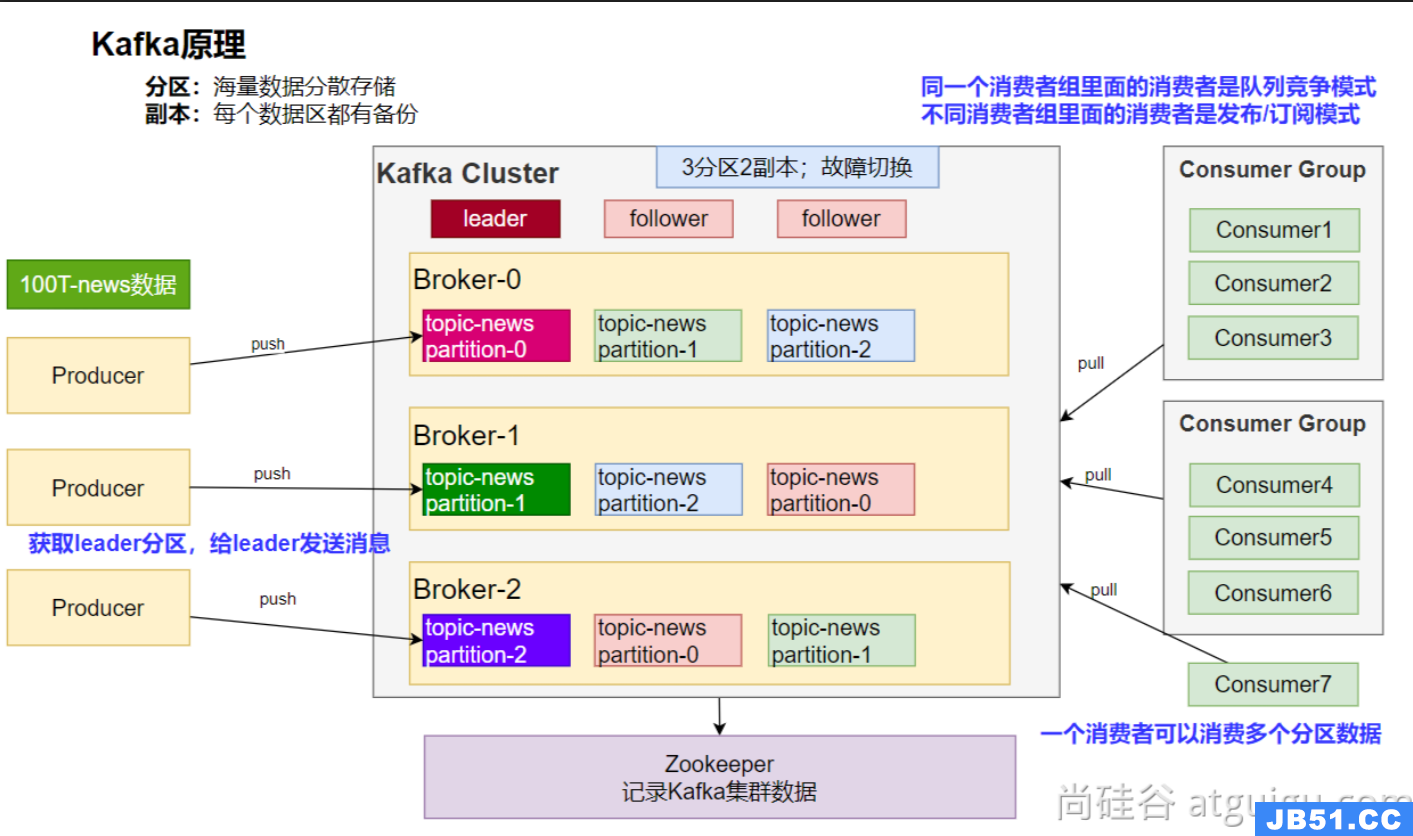
在未来的项目中,我们大多都是已微服务的形式进行开发,此时消息队列中同个topic中的消息可能会存在于不用的服务器上,这就是进行分区。为了防止其中某太服务器发生宕机后影响项目的运行,我们可以在对应分区中存储其他分区中的消息,实现备份在宕机时不影响项目的运行,此过程就是创建副本。
springboot整合kafka
导入kafka整合springboot依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency><dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>发布消息
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.kafka.core.KafkaTemplate;
@SpringBootTest
class KafkatestApplicationTests {
@Autowired
KafkaTemplate kafkaTemplate;
@Test
void test1() {
//设置默认的主题
kafkaTemplate.setDefaultTopic("tiktop");
//在对应主题中添加消息,此消息以键值对的形式
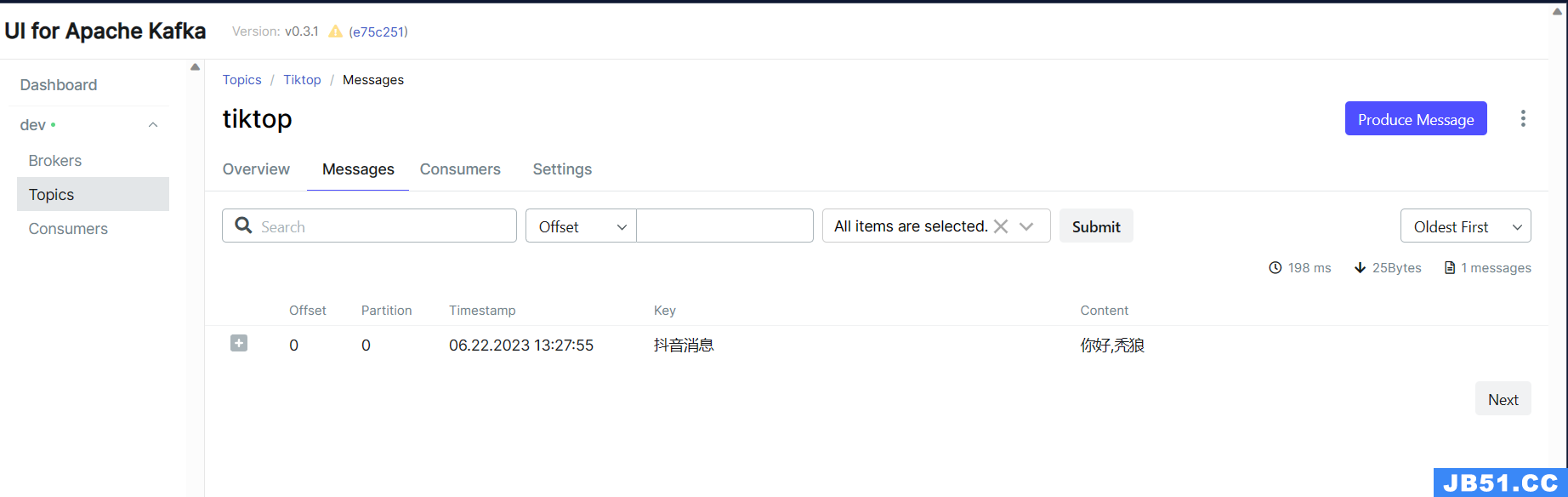
kafkaTemplate.send("tiktop","抖音消息","你好,秃狼");
}
}
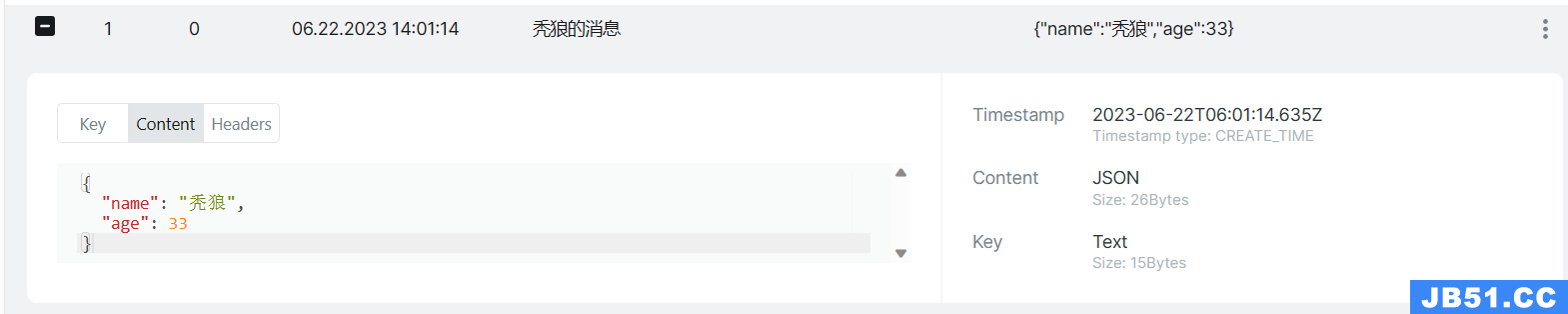
测试结果为下:
特殊情况(无法识别到主机)
通过火绒修改hosts。
设置消息的value为实体类类型
我们通过application.properties进行设置。
#设置消息值的类型,这里设置为json类型,这样我们就可以在消息中传入实体类
spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.JsonSerializer默认的value的序列化类型是:
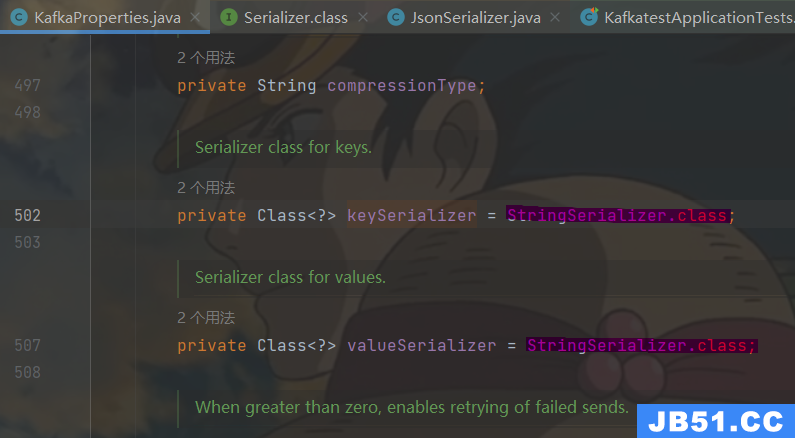
可以设置的序列化类型为下:

创建消费者
创建消费者
group表示该消费者的分组。 topicPartitions是监听的所有的topic和分区,@TopicPartition就是设置对应topic区的topic名字,和对应偏移量和分区(在监听中可能会同时监听多个topic)。 partitionOffsets就是设置所有分区和偏移量(在监听中可能同时监听多个分区中,在该分区中会有不同的偏移量)
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.PartitionOffset;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.stereotype.Component;
@Component
public class Listener {
/**
* group表示该消费者的分组
* topicPartitions是监听的所有的topic和分区,和对应偏移量和分区(在监听中可能会同时监听多个topic)
* partitionOffsets就是设置所有分区和偏移量(在监听中可能同时监听多个分区中,在该分区中会有不同的偏移量)
*/
@KafkaListener(groupId = "toktop-server",topicPartitions = {
@TopicPartition(topic = "tiktop",partitionOffsets = {
@PartitionOffset(partition = "0",initialOffset = "0")
})
})
public void listen(ConsumerRecord consumerRecord) {
//ConsumerRecord就是整个消费者的信息
Object key = consumerRecord.key();
System.out.println("key=" + key);
Object value = consumerRecord.value();
System.out.println("value=" + value);
}
}
在启动类上添加kafka的注解驱动,这样@KafkaListener才会被识别。(@Enablekafka)
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.kafka.annotation.EnableKafka;
@SpringBootApplication
//开启kafka的注解驱动
@EnableKafka
public class KafkatestApplication {
public static void main(String[] args) {
SpringApplication.run(KafkatestApplication.class,args);
}
}
进行启动测试,测试结果为下
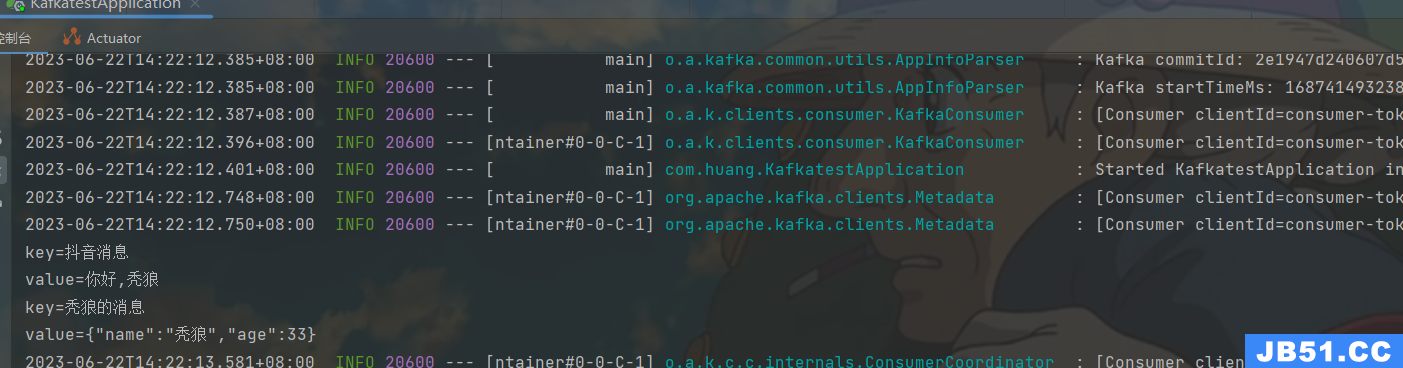
在启动后消费者会直接监听消息队列,测试我们将偏移量设置为0,也就是从头部开始,此时消费者监听到消息队列中的两个消息,最终将通过的信息输出。(注意使用的模式是:发布和订阅模式,所以接收到消息后不会将消息删除,而是改变偏移量)
kafka自动配置
kafka 自动配置在KafkaAutoConfiguration
- 容器中放了 KafkaTemplate 可以进行消息收发
- 容器中放了KafkaAdmin 可以进行 Kafka 的管理,比如创建 topic 等
- kafka 的配置在KafkaProperties中
- @EnableKafka可以开启基于注解的模式
原文地址:https://blog.csdn.net/Ostkakah/article/details/131339691
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。