
消费者端自动和手动提交offset
一、自动提交offset
1、概念
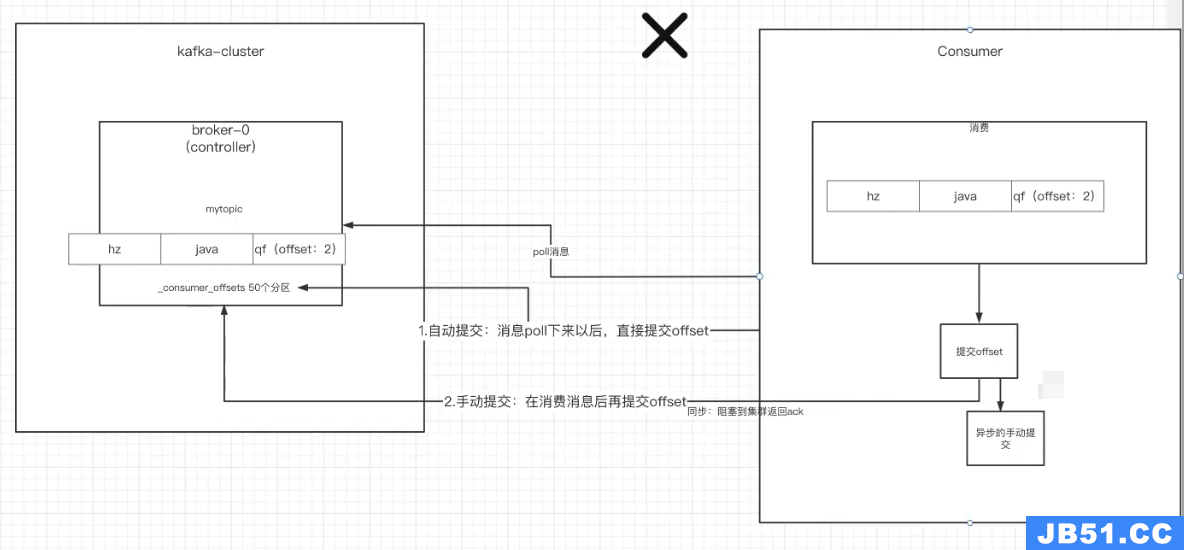
Kafka中默认是自动提交offset。消费者在poll到消息后默认情况下,会自动向Broker的_consumer_offsets主题提交当前
主题-分区消费的偏移量
2、自动提交offset和手动提交offset流程图
3、在Java中实现配置

4、自动提交offset问题
自动提交会丢消息。因为如果消费者还没有消费完poll下来的消息就自动提交了偏移量,那么此时消费者挂了,
于是下一个消费者会从已经提交的offset的下一个位置开始消费消息。之前未被消费的消息就丢失掉了。
二、手动提交offset
1、在Java中配置手动提交
![]()
2、手动提交两种方式
1)手动同步提交
同步提交的时候,会阻塞等待,等待Kafka集群确认收到这个offset,并返回给消费者一个ACK后,才会继续执行下面的业务代码

2)手动异步提交
在消息消费完后,不需要等待集群返回ACK,直接执行之后的逻辑,可以设置回调方法,供Kafka的Broker集群调用

消费者poll消息细节
消费者poll消息。就是消费者与Broker建立长连接拉取数据
一、在Java中,默认的配置是一次性poll500条数据
![]()
二、一次性poll的消息可以根据消费速度的快慢设置,因为如果两次poll的事件超出了30秒的时间间隔,Kafka会认为其消费能力过弱,将其提出消费组。将分区分配给其他消费者
注意:rebalance机制,也就是重新分配的工作是比较消耗性能的,一般尽量避免出现rebalance的情况。一般都会避免出现重新分配的情况,因为重新分配也是比较消耗性能的,所以如果一开始我们发现这个消费者的消费能力比较弱,那么就降低一次拉取消息的数量
![]()
如果每隔1s内没有poll到任何的消息,则会继续的poll,循环往复,直到poll到消息。如果时间超出了1s,则此次长轮询结束
代码中设置长轮询为1000毫秒:

意味着:
1、如果一次poll到了500条,直接执行下面的for循环
2、如果这一次没有poll到500条消息,且在1秒内,那么长轮询继续poll,要么到500条,要么时间到1秒
3、如果多次poll都没有达到500条,且1秒时间到了,那么直接执行for循环
三、消费者发送心跳的时间间隔
![]()
四、Kafka如果超过10s没有收到消费者的心跳,则会把消费者踢出消费组,进行rebalance,把分区分配给其他的消费者
注意:rebalance机制,也就是重新分配的工作是比较消耗性能的,一般尽量避免出现rebalance的情况
![]()
消费者健康状态检查(心跳机制)
消费者每隔1s向kafka集群发送心跳,集群发现如果有超过10s没有续约心跳的消费者,将被踢出消费组,出发该消费组的rebalance机制,
将该分区交给消费组里的其他消费者进行消费

指定分区消费
下面的代码表示指定某个主题的0号分区进行消费
命令:
![]()
Java代码实现:

消息回溯消费
所谓消息回溯消费,指的是默认情况下会从某个分区的偏移量+1进行消费,但是我们也可以指定从某个主题下的某个分区的最开始进行消费
命令:
![]()
Java代码实现:

控制台:
发现从第0个偏移量的消息也被消费了!

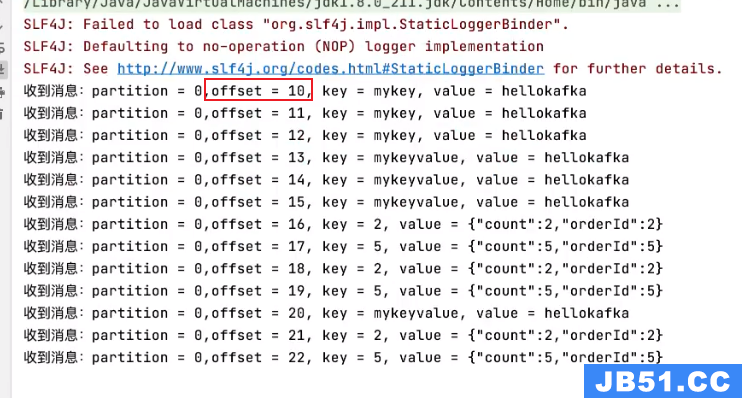
指定offset消费
命令:
![]()
Java代码实现:

控制台:
发现从偏移量10的地方开始消费了!
从指定时间点消费
根据时间,去所有的partition中确定该时间对应的offset,然后去所有的partition分区中找到该offset偏移量之后的消息开始消费
Java代码实现:
下面的案例是从当前时间的前1小时开始消费消息

新消费组消费offset规则
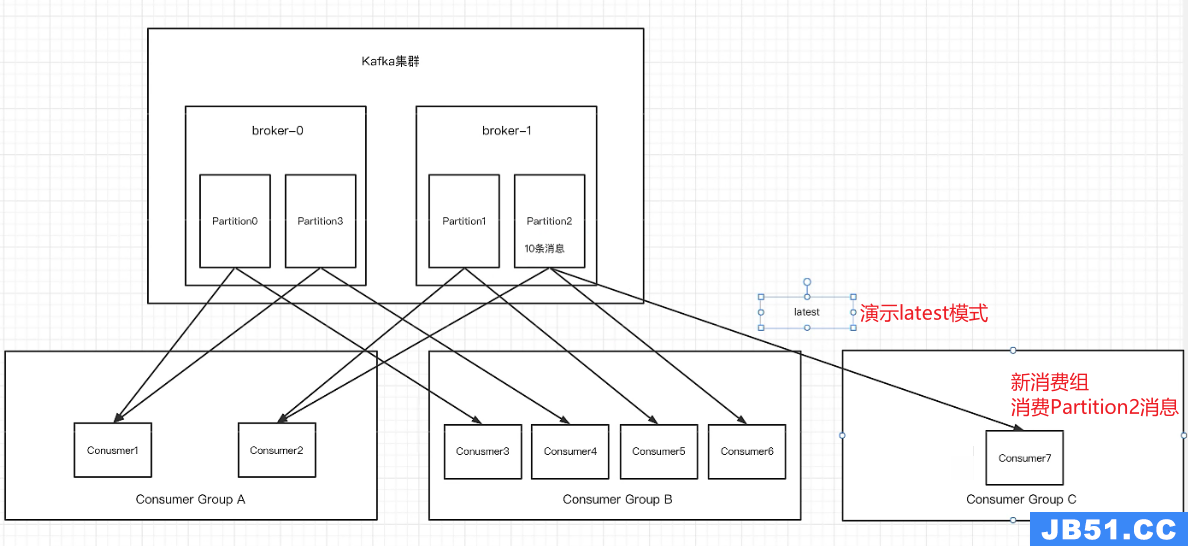
当新创建一个消费组去消费分区中的消息的时候,会有两种模式,分别是latest和earliest模式,下面是对两种模式的介绍
latest(默认):只消费自己启动后生产者发送到主题上的消息
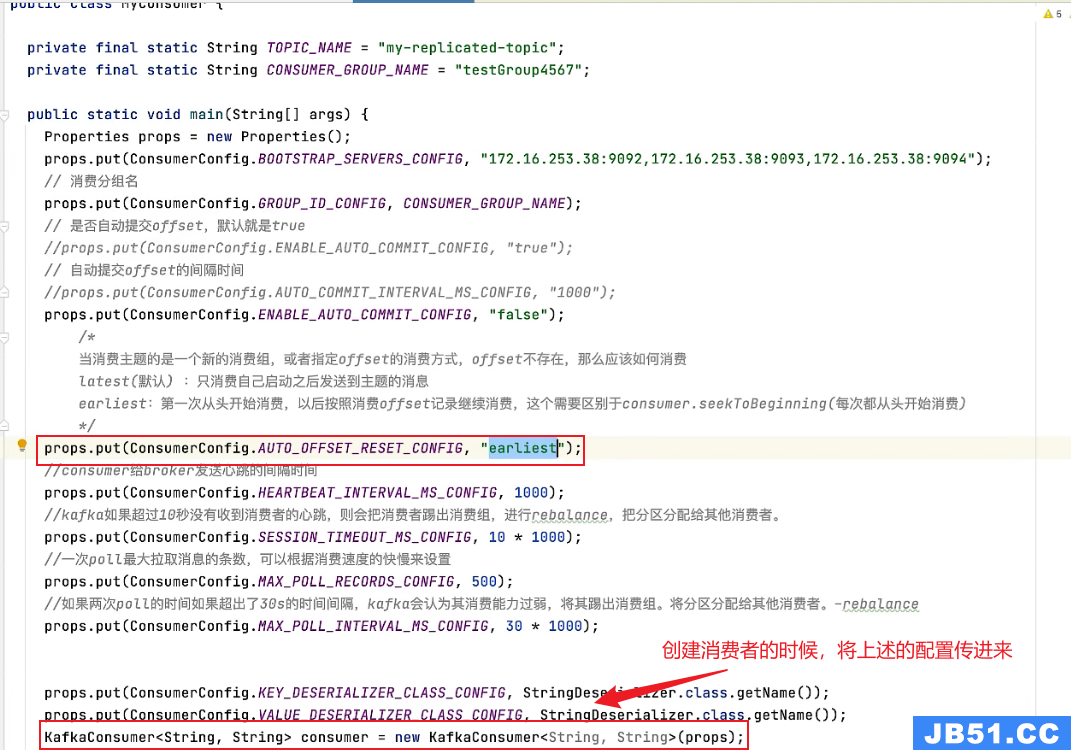
earliest:第一次会从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBegining(每次都从头开始)
1、新消费组流程图
2、Java中配置新消费组消费方式
![]()
3、整体代码回顾
至此,关于Kafka中消费者相关的配置介绍完毕,内容较多,知识点比较分散,希望大家能够坚持反复学习。
后续还会持续更新,敬请期待~~~
原文地址:https://blog.csdn.net/CNpeaceful/article/details/135594704
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。