
课题题目:
1. 课题背景
某股票交易机构已上线一个在线交易平台,平台注册用户量近千万,每日均 接受来自全国各地的分支机构用户提交的交易请求。鉴于公司发展及平台管理要 求,拟委托开发一个在线实时大数据系统,可实时观测股票交易大数据信息,展 示部分重要业绩数据。
2. 数据源
为提供更真实的测试环境,公司的技术部门委托相关人员已设计了一个股票 交易数据模拟器,可模拟产生客户在平台中下单的信息,数据会自动存入指定文 件夹中的文本文件。 该模拟器允许调节进程的数量,模拟不同量级的并发量,以充分测试系统的 性能。数据的具体字段说明详见下表:
(1) 数据字段说明
序号 字段名 中文含义 备注
1 stock_name 股票名
2 stock_code 股票代码
3 time 交易时间 时间戳
4 trade_volume 交易量 数值型
5 trade_price 交易单价 数值类型
6 trade_type 交易类型 [买入,卖出]
7 trade_place 交易地点 交易所在省份
8 trade_platform 交易平台 该交易发生的分支交易平台
9 industry_type 股票类型 该股票所在行业
(2) 数据模拟器使用说明
该模拟器能够模拟用户在平台中下单的行为,并且能够生成包括股票代码、收盘 价格、交易量、交易时间等详细信息的模拟交易数据。模拟器能够生成指定条股 票数据,生成的数据会自动存储到指定文件夹中,方便后续的数据分析和测试验 证。
⚫ 文件夹中包含“place.json”和“stock.exe” “place.json”是地址生成文件,必须与“stock.exe”在同一文件夹下。
⚫ 运行“stock.exe”,初始默认股票数目为 10 支
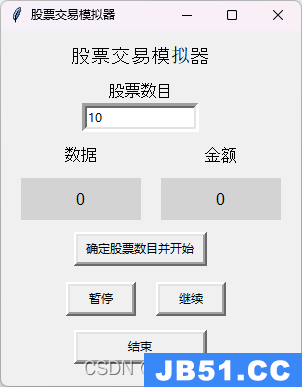

(3) 任务要求:
a) 订单的已处理速度,单位为“条/秒”;
b) 近 1 分钟与当天累计的总交易金额、交易数量;
c) 近 1 分钟与当天累计的买入、卖出交易量;
d) 近 1 分钟与当天累计的交易金额排名前 10 的股票信息;
e) 近 1 分钟与当天累计的交易量排名前 10 的交易平台;
f) 展示全国各地下单客户的累计数量(按省份),在地图上直观展示;
g) 展示不同股票类型的交易量分布情况;
环境:
在三台CentOS虚拟机中配置好docker,并使用docker配置好zookeeper集群、kafka集群、storm集群并且能正常运行,kafka集群和storm集群能正常连接虚拟机外部的主机。
依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>KafkaStormMySQL</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.4.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.13</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.28</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-jdbc</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>5.0.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>storm连接kafka
1.创建并配置Kafka消费者
定义一个名为 MyKafkaConsumer 的类,用于连接到 Kafka 集群并从指定的主题中读取数据。
package org.storm.spout;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class MyKafkaConsumer {
private KafkaConsumer<String,String> consumer;
public MyKafkaConsumer(String bootstrapServers,String groupId,String topic) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(topic)); // 订阅主题
}
public void subscribe(String topic) {
consumer.subscribe(Collections.singletonList(topic));
}
public ConsumerRecords<String,String> poll() {
return consumer.poll(Duration.ofMillis(1000));
}
public void close() {
consumer.close();
}
}2.创建Spout,从kafka中读取数据并发送到storm的拓扑中
定义一个名为 StockTransactionSpout 的 Spout,用于从 Kafka 中读取股票交易数据并将其发送到 Storm 的拓扑中。
其中的BOOTSTRAP_SERVERS要根据自己的虚拟机ip设置
package org.storm.spout;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.IRichSpout;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.sql.Timestamp;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.time.Duration;
import java.util.Date;
import java.util.Map;
public class StockTransactionSpout implements IRichSpout {
private SpoutOutputCollector collector;
private MyKafkaConsumer myKafkaConsumer;
private static final String BOOTSTRAP_SERVERS = "192.168.10.102:9092,192.168.10.103:9092,192.168.10.104:9092";
private static final String TOPIC_NAME = "stock-data";
private static final String GROUP_ID = "stock-transaction-group";
@Override
public void open(Map conf,TopologyContext context,SpoutOutputCollector collector) {
this.collector = collector;
this.myKafkaConsumer = new MyKafkaConsumer(BOOTSTRAP_SERVERS,GROUP_ID,TOPIC_NAME);
// Initialize your KafkaConsumer here
}
@Override
public void nextTuple() {
ConsumerRecords<String,String> records = myKafkaConsumer.poll();
for (ConsumerRecord<String,String> record : records) {
String[] fields = record.value().split(",");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date parsedDate;
try {
parsedDate = dateFormat.parse(fields[0]);
} catch (ParseException e) {
e.printStackTrace();
continue; // 如果日期解析失败,跳过这条记录
}
Timestamp time = new java.sql.Timestamp(parsedDate.getTime());
String stockCode = fields[1];
String stockName = fields[2];
double tradePrice = Double.parseDouble(fields[3]);
int tradeVolume = Integer.parseInt(fields[4]);
String tradeType = fields[5];
String tradePlace = fields[6];
String tradePlatform = fields[7];
String industryType = fields[8];
Values values = new Values(stockName,stockCode,time,tradeVolume,tradePrice,tradeType,tradePlace,tradePlatform,industryType);
collector.emit(values);
}
}
@Override
public void ack(Object o) {
}
@Override
public void fail(Object o) {
}
// Implement other necessary methods...
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("stockName","stockCode","time","tradeVolume","tradePrice","tradeType","tradePlace","tradePlatform","industryType"));
}
@Override
public Map<String,Object> getComponentConfiguration() {
return null;
}
@Override
public void close() {
// 在这里添加关闭资源的代码
// 例如,如果您在Spout中打开了一些资源(如数据库连接、文件等),那么应该在这里关闭它们
if (myKafkaConsumer != null) {
myKafkaConsumer.close();
}
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
}storm整合mybatis并连接mysql
因篇幅限制,这里仅展示一个bolt,即统计不同股票类型的交易量分布情况的bolt的具体结构
1.定义实体类
package org.storm.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class IndustryTradeVolume {
private String industry_type;
private int trade_volume;
}2.定义mapper类
package org.storm.mapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.storm.pojo.IndustryTradeVolume;
import java.util.List;
//@Mapper
public interface IndustryTradeVolumeMapper {
void insertAllIndustryTradeVolumes(@Param("industry_type") String industry_type,@Param("trade_volume") int trade_volume);
}
3.定义Service类
package org.storm.service;
import org.storm.pojo.IndustryTradeVolume;
import java.util.List;
public interface IndustryTradeVolumeService {
void insertAllIndustryTradeVolumes(String industry_type,int trade_volume);
}package org.storm.service.Impl;
import org.storm.mapper.IndustryTradeVolumeMapper;
import org.storm.pojo.IndustryTradeVolume;
import org.storm.service.IndustryTradeVolumeService;
import java.util.List;
public class IndustryTradeVolumeServiceImpl implements IndustryTradeVolumeService {
private IndustryTradeVolumeMapper industryVolumeMapper;
@Override
public void insertAllIndustryTradeVolumes(String industry_type,int trade_volume){
industryVolumeMapper.insertAllIndustryTradeVolumes(industry_type,trade_volume);
}
}4.MyBatis映射
每个mapper均需要MyBatis映射
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.storm.mapper.IndustryTradeVolumeMapper">
<!--统计不同股票类型的交易量分布情况-->
<select id="insertAllIndustryTradeVolumes">
INSERT INTO industry_volume (`industry_type`,`trade_volume`) VALUES (#{industry_type},#{trade_volume}) ON DUPLICATE KEY UPDATE trade_volume = trade_volume + VALUES(`trade_volume`)
</select>
</mapper>5.MyBatis配置文件
修改数据库、用户名及密码
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="mysql">
<environment id="mysql">
<!--配置事务管理器 -->
<transactionManager type="JDBC"></transactionManager>
<!-- 配置数据源-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/stock_db?useSSL=false&useUnicode=true&characterEncoding=utf8&
serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="1221005a"/>
</dataSource>
</environment>
</environments>
<!--指明映射文件的位置。-->
<mappers>
<mapper resource="mapper/IndustryVolumeMapper.xml"></mapper>
<mapper resource="mapper/OrderSpeedMapper.xml"></mapper>
<mapper resource="mapper/ProvinceCustomerCountMapper.xml"></mapper>
<mapper resource="mapper/PlatformVolumeMapper.xml"></mapper>
<mapper resource="mapper/TransactionAmountMapper.xml"></mapper>
<mapper resource="mapper/TradeInfoMapper.xml"></mapper>
<mapper resource="mapper/TradeVolumeMapper.xml"></mapper>
<mapper resource="mapper/TransactionInfoMapper.xml"></mapper>
</mappers>
</configuration>6.创建SqlSessionFactoryBuilder类
package org.storm.config;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.Reader;
public class SqlSessionConfig {
public static SqlSessionFactory GetConn() {
Reader reader = null;
try {
reader = Resources.getResourceAsReader("mybatis.xml");
return new SqlSessionFactoryBuilder().build(reader);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
7.创建bolt类
package org.storm.bolt;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Tuple;
import org.storm.config.SqlSessionConfig;
import org.storm.mapper.IndustryTradeVolumeMapper;
import org.storm.mapper.TradeVolumeMapper;
import org.storm.service.IndustryTradeVolumeService;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Map;
import java.util.HashMap;
import java.sql.PreparedStatement;
//统计不同股票类型的交易量分布情况
public class IndustryTradeVolumeBolt extends BaseRichBolt {
private OutputCollector collector;
IndustryTradeVolumeService industryTradeVolumeService;
IndustryTradeVolumeMapper industryTradeVolumeMapper;
@Override
public void prepare(Map<String,Object> topoConf,OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String industryType = input.getStringByField("industryType");
int tradeVolume = input.getIntegerByField("tradeVolume");
SqlSessionFactory factory = SqlSessionConfig.GetConn();
SqlSession session = factory.openSession();
IndustryTradeVolumeMapper db = session.getMapper(IndustryTradeVolumeMapper.class);
db.insertAllIndustryTradeVolumes(industryType,tradeVolume);
session.commit();
session.close();
// industryTradeVolumeMapper.insertAllIndustryTradeVolumes(industryType,tradeVolume);
// 确认处理成功
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 本例中不输出任何字段
}
}8.创建Topology类
package org.storm;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.kafka.spout.KafkaSpoutRetryExponentialBackoff;
import org.apache.storm.kafka.spout.KafkaSpoutRetryService;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.utils.Utils;
import org.storm.bolt.*;
import org.storm.spout.StockTransactionSpout;
public class StockTransactionTopology {
public static void main(String[] args) throws Exception {
// 创建TopologyBuilder实例
final TopologyBuilder builder = new TopologyBuilder();
// 设置Spout
builder.setSpout("kafka_spout",new StockTransactionSpout(),1).setNumTasks(1);
// 设置Bolts
builder.setBolt("order-speed-bolt",new OrderSpeedBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("transaction-statistics-bolt",new TransactionStatisticsBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("trade-volume-bolt",new TradeVolumeBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("province-customer-count-bolt",new ProvinceCustomerCountBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("industry-trade-volume-bolt",new IndustryTradeVolumeBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("top-platforms-bolt",new TopPlatformsBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("top-transactions-bolt",new TopTransactionsBolt(),1).shuffleGrouping("kafka_spout");
builder.setBolt("trade-info-bolt",new TradeInfoBolt(),1).shuffleGrouping("kafka_spout");
Config conf = new Config();
conf.setDebug(true);
// // 提交Topology
// StormSubmitter.submitTopology("stock-transaction-topology",conf,builder.createTopology());
// 本地测试
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("myTopology",builder.createTopology());
// // 运行10分钟后停止
Utils.sleep(600000);
cluster.killTopology("myTopology");
cluster.shutdown();
}
private static KafkaSpoutConfig<String,String> getKafkaSpoutConfig(String bootstrapServers,String topic) {
return KafkaSpoutConfig.builder(bootstrapServers,topic)
// 除了分组ID,以下配置都是可选的。分组ID必须指定,否则会抛出InvalidGroupIdException异常
.setProp(ConsumerConfig.GROUP_ID_CONFIG,"stock-transaction-group")
.setProp(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG,200)
// 定义重试策略
.setRetry(getRetryService())
// 定时提交偏移量的时间间隔,默认是15s
.setOffsetCommitPeriodMs(10000)
.setMaxUncommittedOffsets(200)
.build();
}
// 定义重试策略
private static KafkaSpoutRetryService getRetryService() {
return new KafkaSpoutRetryExponentialBackoff(KafkaSpoutRetryExponentialBackoff.TimeInterval.microSeconds(500),KafkaSpoutRetryExponentialBackoff.TimeInterval.milliSeconds(2),Integer.MAX_VALUE,KafkaSpoutRetryExponentialBackoff.TimeInterval.seconds(10));
}
}代码完成后,本地测试直接运行即可,若要打包上传到虚拟机需注释掉:
// 本地测试
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("myTopology",builder.createTopology());并取消注释这段代码:
// // 提交Topology
// StormSubmitter.submitTopology("stock-transaction-topology",builder.createTopology());
原文地址:https://blog.csdn.net/Huailizhi/article/details/135017561
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。