
On the heels of part 1 in this blog series, Spring for Apache Kafka – Part 1: Error Handling,Message Conversion and Transaction Support,here in part 2 we’ll focus on another project that enhances the developer experience when building streaming applications on Kafka: Spring Cloud Stream.
We will cover the following in this post:
- Overview of Spring Cloud Stream and its programming model
- Apache Kafka® integration in Spring Cloud Stream
- How Spring Cloud Stream makes application development easier for Kafka developers
- Stream processing using Kafka Streams and Spring Cloud Stream
Let’s begin by looking at what Spring Cloud Stream is and how it works with Apache Kafka.
What is Spring Cloud Stream?
Spring Cloud Stream is a framework that lets application developers write message-driven microservices. This is done by using the foundations provided by Spring Boot while supporting programming models and paradigms exposed by other Spring portfolio projects,such as Spring Integration, Spring Cloud Function and Project Reactor. It supports writing applications with a type-safe programming model that describes the input and output components. Common examples of applications include source (producer), sink (consumer) and processor (both producer and consumer).
A typical Spring Cloud Stream application includes input and output components for communication. These inputs and outputs are mapped onto Kafka topics. A Spring Cloud Stream application can receive input data from a Kafka topic,and it may choose to produce an output to another Kafka topic. These are different from the Kafka Connect sinks and sources. For more information about the various Spring Cloud Stream out-of-the-box apps,please visit the project page.
The bridge between a messaging system and Spring Cloud Stream is through the binder abstraction. Binders exist for several messaging systems,but one of the most commonly used binders is for Apache Kafka.
The Kafka binder extends on the solid foundations of Spring Boot,Spring for Apache Kafka and Spring Integration. Since the binder is an abstraction,there are implementations available for other messaging systems also.
Spring Cloud Stream supports pub/sub semantics, consumer groups and native partitioning,and delegates these responsibilities to the messaging system whenever possible. In the case of the Kafka binder,these concepts are internally mapped and delegated to Kafka,since Kafka supports them natively. When the messaging systems do not support these concepts natively,Spring Cloud Stream provides them as core features.
Here is a pictorial representation of how the binder abstraction works with inputs and outputs:
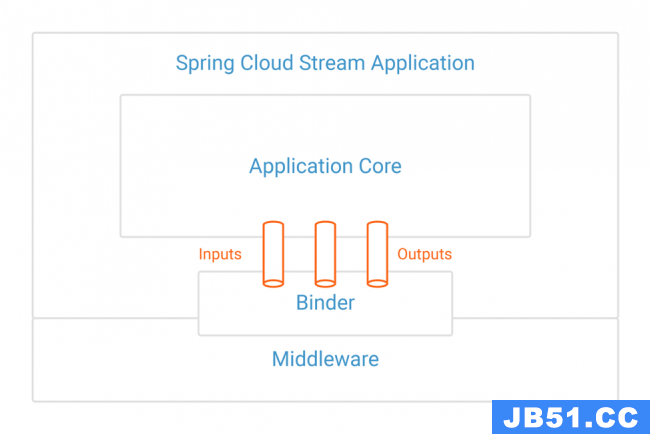
Creating a Kafka application by using Spring Cloud Stream
Spring Initializr is the best place to create a new application using Spring Cloud Stream. The blog post How to Work with Apache Kafka in Your Spring Boot Application covers all the steps required to create an application from Spring Initializr. The only difference when it comes to Spring Cloud Stream is that you request “Cloud Stream” and “Kafka” as components. Here is an example of what you need to select:
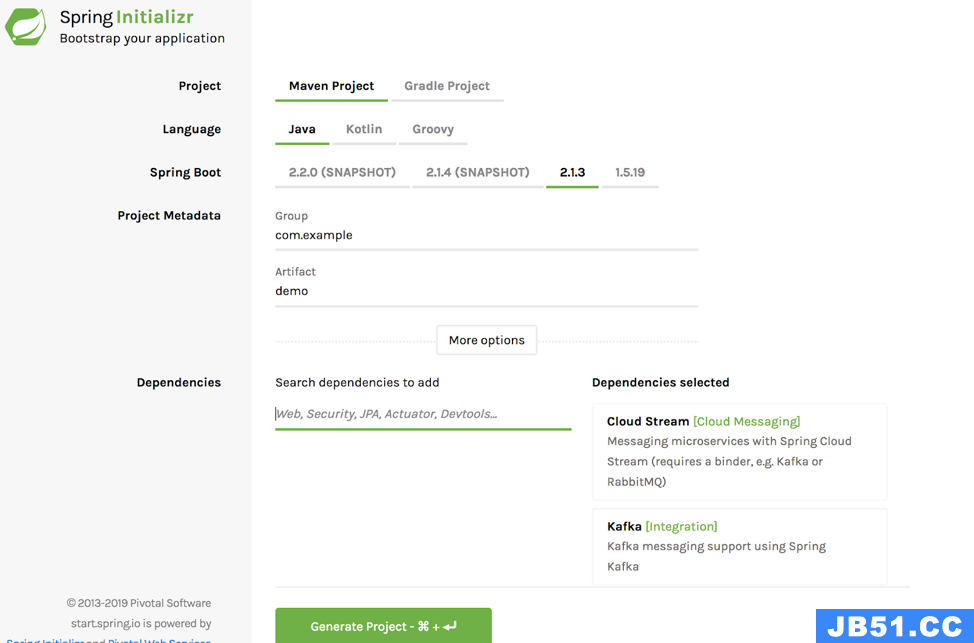
Initializr includes all the required dependencies for developing a streaming application. By using Initializr,you can also choose your build tool (such as Maven or Gradle) and select your target JVM language (for example,Java or Kotlin).
The build will produce an uber JAR that is capable of running as a standalone application,e.g.,from the command line.
Spring Cloud Stream programming model for Apache Kafka
Spring Cloud Stream provides a programming model that enables immediate connectivity to Apache Kafka. The application needs to include the Kafka binder in its classpath and add an annotation called @EnableBinding,which binds the Kafka topic to its input or an output (or both).
Spring Cloud Stream provides three convenient interfaces to bind with @EnableBinding: Source (single output), Sink (single input) and Processor (single input and output). It can be extended to custom interfaces with multiple inputs and outputs as well.
The following code snippet shows the basic programming model of Spring Cloud Stream:
Copy
@SpringBootApplication
@EnableBinding(Processor.class)
public class UppercaseProcessor {
@StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public String process(String s) { return s.toUpperCase(); } }
In this application,notice that the method is annotated with @StreamListener,which is provided by Spring Cloud Stream to receive messages from a Kafka topic. The same method is also annotated with SendTo,which is a convenient annotation for sending messages to an output destination. This is a Spring Cloud Stream Processor application that consumes messages from an input and produces messages to an output.
There is no mention of Kafka topics in the preceding code. A natural question that may arise at this point is,“How is this application communicating with Kafka?” The answer is: Inbound and outbound topics are configured by using one of the many configuration options supported by Spring Boot. In this case,we are using a YAML configuration file named application.yml,which is searched for by default. Here is the configuration for input and output destinations:
Copy
spring.cloud.stream.bindings:
input:
destination: topic1
output:
destination: topic2
Spring Cloud Stream maps the input to topic1 and the output to topic2. This is a very minimal set of configurations,but there are more options that can be used to customize the application further. By default,the topics are created with a single partition but can be overridden by the applications. Please refer to these docs for more information.
The bottom line is that the developer can simply focus on writing the core business logic and let infrastructure concerns (such as connecting to Kafka,configuring and tuning the applications and so on) be handled by Spring Cloud Stream and Spring Boot.
The following example shows another simple application (a consumer):
Copy
@SpringBootApplication
@EnableBinding(Sink.class)
public class LoggingConsumerApplication {
@StreamListener(Sink.INPUT) public void handle(Person person) { System.out.println("Received: " + person); }
public static class Person { private String name; public String getName() { return name; } public void setName(String name) { this.name = name; } public String toString() { return this.name; } } }
Note that @EnableBinding is provided with a Sink,which indicates that this is a consumer. One main difference from the previous application is that the method annotated with @StreamListener is taking a POJO called Person as its argument instead of a string. How is the message coming from the Kafka topic converted to this POJO? Spring Cloud Stream provides automatic content-type conversions. By default,it uses application/JSON as the content type,but other content types are supported as well. You can provide the content type by using the property spring.cloud.stream.bindings.input.contentType,and then set it to the appropriate content types,such as application/Avro.
The appropriate message converter is picked up by Spring Cloud Stream based on this configuration. If the application wants to use the native serialization and deserialization provided by Kafka rather than using the message converters provided by Spring Cloud Stream,the following properties can be set.
For serialization:
Copy
spring.cloud.stream.bindings.output.useNativeEncoding=true
For deserialization:
Copy
spring.cloud.stream.bindings.input.useNativeDecoding=true
Auto-provisioning of topics
The Apache Kafka binder provides a provisioner to configure topics at startup. If the topic creation is enabled on the broker,Spring Cloud Stream applications can create and configure Kafka topics as part of the application startup.
For instance,partitions and other topic-level configurations can be provided to the provisioner. These customizations can be done at the binder level,which would apply for all topics used in the applications,or at the individual producer and consumer levels. This is handy especially during development and testing of the application. There are various examples of how topics can be configured for multiple partitions.
Support for consumer groups and partitions
Well-known properties like consumer group and partitions are available for configuration using Spring Cloud Stream. The consumer group can be set by the property:
Copy
spring.cloud.stream.bindings.input.group=group-name
As indicated earlier,internally,this group will be translated into Kafka’s consumer group.
When writing a producer application,Spring Cloud Stream provides options for sending data to specific partitions. Here again,the framework delegates these responsibilities to Kafka.
In the case of a consumer,specific application instances can be limited to consume messages from a certain set of partitions if auto-rebalancing is disabled,which is a simple configuration property to override. See these configuration options for more details.
Binding visualization and control
Using Spring Boot’s actuator mechanism,we now provide the ability to control individual bindings in Spring Cloud Stream.
While running,the application can be stopped,paused,resumed,etc.,using an actuator endpoint,which is Spring Boot’s mechanism for monitoring and managing an application when it is pushed to production. This feature enables users to have more controls on the way applications process data from Kafka. If the application is paused for a binding,then processing records from that particular topic will be suspended until resumed.
Spring Cloud Stream also integrates with Micrometer for enabling richer metrics,emitting messing rates and providing other monitoring-related capabilities. These can be further integrated with many other monitoring systems. The Kafka binder provides extended metrics capabilities that provide additional insights into consumer lag for topics.
An application health check is provided through a special health endpoint by Spring Boot. The Kafka binder provides a special implementation of the health indicator that takes into account connectivity to the broker,and checks if all the partitions are healthy. If any partition is found without a leader or if the broker cannot be connected,the health check reports the status accordingly.
Overview of Kafka Streams support in Spring Cloud Stream
When it comes to writing stream processing applications,Spring Cloud Stream provides another binder specifically dedicated for Kafka Streams. As with the regular Kafka binder,the Kafka Streams binder also focuses on developer productivity,so developers can focus on writing business logic for KStream,KTable,GlobalKTable,instead of infrastructure code. The binder takes care of connecting to Kafka,as well as creating,configuring and maintaining the streams and topics. For example,if the application method has a KStream signature,the binder will connect to the destination topic and stream from it behind the scenes. The application developer does not have to explicitly do that,as the binder already provides it for the application.
The same is applied for other types like KTable and GlobalKTable. The underlying KafkaStreams object is provided by the binder for dependency injection and,thus,the application does not directly maintain it. Rather,it is done for you by Spring Cloud Stream.
To get started on Kafka Streams with Spring Cloud Stream,go to Spring Initializr and select the options shown in the following image to generate an app with the dependencies for writing Kafka Streams applications using Spring Cloud Stream:
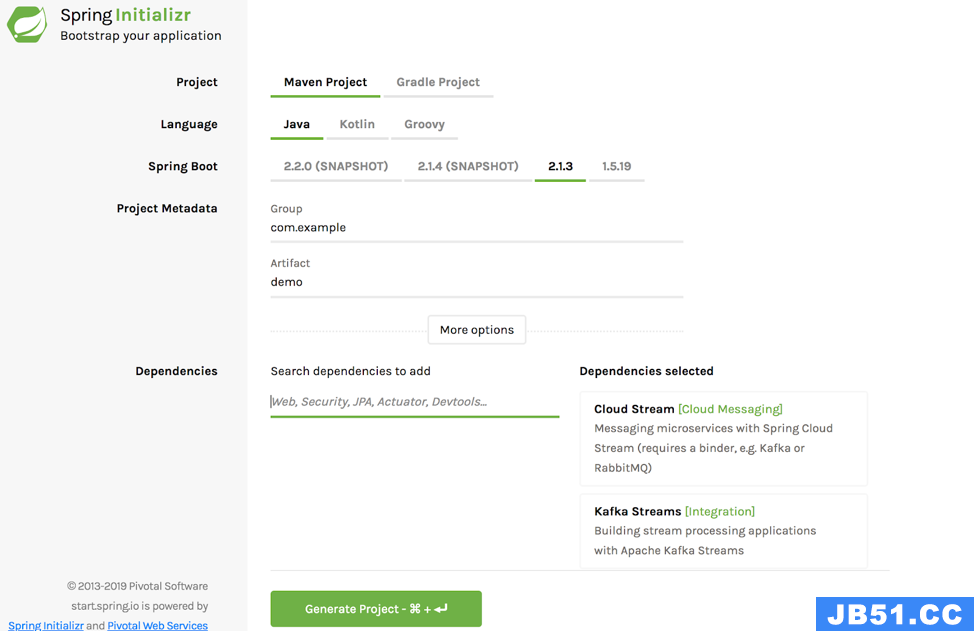
The example below shows a Kafka Streams application written with Spring Cloud Stream:
Copy
@SpringBootApplication
public class KafkaStreamsTableJoin {
@EnableBinding(StreamTableProcessor.class) public static class KStreamToTableJoinApplication {
Copy
@StreamListener
@SendTo("output")
public KStream<String,Long> process(@Input("input1") KStream<String,Long> userClicksStream,@Input("input2") KTable<String,String> userRegionsTable) {
return userClicksStream
.leftJoin(userRegionsTable,(clicks,region) -> new RegionWithClicks(region == null ? "UNKNOWN" : region,clicks),Joined.with(Serdes.String(),Serdes.Long(),null))
.map((user,regionWithClicks) -> new KeyValue<>(regionWithClicks.getRegion(),regionWithClicks.getClicks()))
.groupByKey(Serialized.with(Serdes.String(),Serdes.Long()))
.reduce((firstClicks,secondClicks) -> firstClicks + secondClicks)
.toStream();
}
}
interface StreamTableProcessor {
Copy
@Input("input1")
KStream<!--?,?--> inputStream();
@Output("output")
KStream<!--?,?-->outputStream();
@Input("input2")
KTable<!--?,?--> inputTable();
} }
There are a few things to note in the preceding code. In the @StreamListener method,there is no code for setting up the Kafka Streams components. The application does not need to build the streams topology for correlating KStream or KTable to Kafka topics,starting and stopping the stream and so on. All those mechanics are handled by the Spring Cloud Stream binder for Kafka Streams. By the time the method is invoked,a KStream and a KTable have already been created and made available for the application to use.
The application creates a custom interface,called StreamTableProcessor,that specifies the Kafka Streams types for input and output binding. This interface is used with @EnableBinding. This interface is used in the same way as we used in the previous example with the processor and sink interfaces. Similar to the regular Kafka binder,the destination on Kafka is also specified by using Spring Cloud Stream properties. You can provide these configuration options for the preceding application to create the necessary streams and table:
Copy
spring.cloud.stream.bindings.input1.destination=userClicksTopic spring.cloud.stream.bindings.input2.destination=userRegionsTopic spring.cloud-stream.bindings.output.destination=userClickRegionsTopic
We use two Kafka topics for creating the incoming streams: one for consuming messages as KStream and another as KTable. The framework appropriately uses the type needed,based on the bindings provided in the custom interface StreamTableProcessor. These types will then be paired with the method signatures in order to be used in the application code. On the outbound,the outgoing KStream is sent to the output Kafka topic.
Queryable state store support in Kafka Streams
Kafka Streams provides first class primitives for writing stateful applications. When stateful applications are built using Spring Cloud Stream and Kafka Streams,it is possible to have RESTful applications that can pull information from the persisted state stores in RocksDB. See below for an example of a Spring REST application that relies on the state stores from Kafka Streams:
Copy
@RestController
public class FooController {
private final Log logger = LogFactory.getLog(getClass());
@Autowired private InteractiveQueryService interactiveQueryService;
@RequestMapping("/song/id") public SongBean song(@RequestParam(value="id") Long id) {
final ReadOnlyKeyValueStore<Long,Song> songStore =
interactiveQueryService.getQueryableStore(“STORE-NAME”,
QueryableStoreTypes.<Long,Song>keyValueStore());
final Song song = songStore.get(id);
if (song == null) {
throw new IllegalArgumentException("Song not found.");
}
return new SongBean(song.getArtist(),song.getAlbum(),song.getName());
} }
InteractiveQueryService is an API that the Apache Kafka Streams binder provides,which the applications can use to retrieve from the state storage. Instead of directly accessing the state stores through the underlying stream infrastructure,applications can query them by name using this service. This service also provides user-friendly ways to access the server host information when multiple instances of Kafka Streams applications are running,with partitions spread across them.
Normally in this situation,applications have to find the host where the partition hosting the key is located by accessing the Kafka Streams API directly. The InteractiveQueryService provides wrappers around those API methods. Once the application gains access to the state storage,it can formulate further insights by querying from it. Eventually,these insights can be made available through a REST endpoint as shown above. You can find an example on GitHub of a Kafka Streams application that was written using Spring Cloud Stream,in which it adapts to the Kafka music example using the features mentioned in this section.
Branching in Kafka Streams
It is possible to use the branching feature of Kafka Streams natively in Spring Cloud Stream by using the SendTo annotation.
Copy
@StreamListener("input")
@SendTo({“englishTopic”,“frenchTopic”,“spanishTopic”})
public KStream<?,WordCount>[] process(KStream<Object,String> input) {
Predicate<Object,WordCount> isEnglish = (k,v) -> v.word.equals("english"); Predicate<Object,WordCount> isFrench = (k,v) -> v.word.equals("french"); Predicate<Object,WordCount> isSpanish = (k,v) -> v.word.equals("spanish");
return input .flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\W+"))) .groupBy((key,value) -> value) .windowedBy(timeWindows) .count(Materialized.as("WordCounts-1")) .toStream() .map((key,value) -> new KeyValue<>(null,new WordCount(key.key(),value,new Date(key.window().start()),new Date(key.window().end())))) .branch(isEnglish,isFrench,isSpanish); }
Notice that the SendTo annotation has bindings for three different outputs,and the method itself returns a KStream[]. Spring Cloud Stream internally sends the branches into the Kafka topics to which the outputs are bound. Observe the order of outputs specified on the SendTo annotation. These output bindings will be paired with the outgoing KStream[] in the order that it comes in the array.
The first KStream in the first index of the array might be mapped to englishTopic,then the next one to frenchTopic and so on and so forth. The idea here is that the applications can focus on the functional side of things and setting up all these output streams with Spring Cloud Stream,which otherwise the developer would have to do individually for each stream.
Error handling in Spring Cloud Stream
Spring Cloud Stream provides error handling mechanisms for handling failed messages. They can be sent to a dead letter queue (DLQ),which is a special Kafka topic created by Spring Cloud Stream. When failed records are sent to the DLQ,headers are added to the record containing more information about the failure,such as the exception stack trace,message,etc.
Sending to the DLQ is optional,and the framework provides various configuration options to customize it.
For Kafka Streams applications in Spring Cloud Stream, error handling is mostly centered around deserialization errors. The Apache Kafka Streams binder provides the ability to use the deserialization handlers that Kafka Streams provides. It also provides the ability to send the failed records to a DLQ while the main stream continues processing. This is useful when the application needs to come back to visit the erroneous records.
Schema evolution and Confluent Schema Registry
Spring Cloud Stream supports schema evolution by providing capabilities to work with Confluent Schema Registry as well as a native schema registry server provided by Spring Cloud Stream. Applications enable Schema Registry by including the @EnableSchemaRegistryClient annotation at the application level. Spring Cloud Stream provides various Avro based message converters that can be conveniently used with schema evolution. When using the Confluent Schema Registry,Spring Cloud Stream provides a special client implementation (ConfluentSchemaRegistryClient) that the applications need to provide as the SchemaRegistryClient bean.
Conclusion
Spring Cloud Stream makes it easier for application developers to focus on the business logic by automatically addressing the other equally important non-functional requirements,such as provisioning,automatic content conversion,error handling,configuration management,consumer groups,partitioning,monitoring,health checks,thus improving productivity while working with Apache Kafka.
Learn more
To learn more about using Spring Boot with Apache Kafka, take this free course with expert videos and guides.
You can sign up for Confluent Cloud and use the promo code SPRING200 for an additional $200 of free Confluent Cloud usage.*
Further reading
- Spring for Apache Kafka Deep Dive – Part 1: Error Handling,Message Conversion and Transaction Support
- Spring for Apache Kafka Deep Dive – Part 3: Apache Kafka and Spring Cloud Data Flow
- Spring for Apache Kafka Deep Dive – Part 4: Continuous Delivery of Event Streaming Pipelines
- How to Work with Apache Kafka in Your Spring Boot Application
- Code samples for Spring Boot and Apache Kafka
- Spring for Apache Kafka documentation
- Spring Tips: Spring Cloud Stream Kafka Streams
原文地址:https://blog.csdn.net/moshowgame/article/details/135315331
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。