
前言
我们小猿在学习到kafka这门技术的时候,相信大家已经学习过其它消息队列中间件,例如RabbitMq、RocketMq、activeMq了,对于消息队列的基本概念和作用有了一定的了解。
如果没有学习过其它消息队,我们需要了解下消息队列MQ的基本概念。
为什么需要Kafka
我学习过其他消息队列为何还要学kafka呢 ?
目前 Apache Kafka 被认为是整个消息引擎领域的执牛耳者,仅凭这一点就值得我们好好学习一下它。另外,从学习技术的角度而言,Kafka 也是很有亮点的。我们仅需要学习一套框架就能在实际业务系统中实现消息引擎应用、应用程序集成、分布式存储构建,甚至是流处理应用的开发与部署,听起来还是很超值的吧。
Kafka的优势
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,既然是消息队列,那么Kafka也就拥有消息队列的相应的特性了,例如 异步、解耦、削峰等。
Kafka的优势如下:
-
高吞吐量、低延迟:
kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒; -
可扩展性:
kafka集群支持热扩展; -
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
-
容错性:允许集群中节点故障(若副本数量为n,则允许
n-1个节点故障); -
高并发:支持数千个客户端同时读写。
Kafka应用场景
Kafka做消息队列
比起大多数的消息系统来说,Kafka有更好的吞吐量,内置的分区,冗余及容错性,这让Kafka成为了一个很好的大规模消息处理应用的解决方案。消息系统 一般吞吐量相对较低,但是需要更小的端到端延时,并尝尝依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMQ或RabbitMQ。
Kafka行为跟踪
Kafka的另一个应用场景是跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到hadoop/离线数据仓库里处理。
Kafka元信息监控
作为操作记录的监控模块来使用,即汇集记录一些操作信息,可以理解为运维性质的数据监控吧。
Kafka日志收集
日志收集方面,其实开源产品有很多,包括Scribe、Apache Flume。很多人使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉 文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的 系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
Kafka流处理
这 个场景可能比较多,也很好理解。保存收集流数据,以提供之后对接的Storm或其他流式计算框架进行处理。很多用户会将那些从原始topic来的数据进行 阶段性处理,汇总,扩充或者以其他的方式转换到新的topic下再继续后面的处理。例如一个文章推荐的处理流程,可能是先从RSS数据源中抓取文章的内 容,然后将其丢入一个叫做“文章”的topic中;后续操作可能是需要对这个内容进行清理,比如回复正常数据或者删除重复数据,最后再将内容匹配的结果返 还给用户。这就在一个独立的topic之外,产生了一系列的实时数据处理的流程。Strom和Samza是非常著名的实现这种类型数据转换的框架。Kafka事件源
事件源是一种应用程序设计的方式,该方式的状态转移被记录为按时间顺序排序的记录序列。Kafka可以存储大量的日志数据,这使得它成为一个对这种方式的应用来说绝佳的后台。比如动态汇总(News feed)。
Kafka持久性日志(commit log)
Kafka可以为一种外部的持久性日志的分布式系统提供服务。这种日志可以在节点间备份数据,并为故障节点数据回复提供一种重新同步的机制。Kafka中日志压缩功能为这种用法提供了条件。在这种用法中,Kafka类似于Apache BookKeeper项目。
Kafka消费模式
Kafka的消费模式主要有两种:一种是一对一的消费,也即点对点的通信,即一个发送一个接收。第二种为一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的订阅拉取消息消费。
一对一
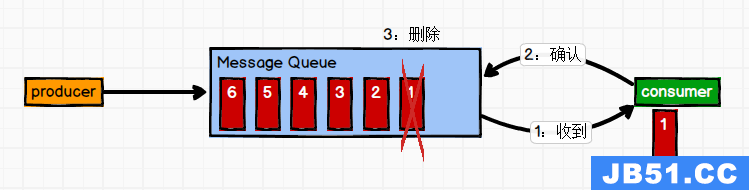
消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费。
一对多

这种模式也称为发布/订阅模式,即利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除。
Kafka的基础架构
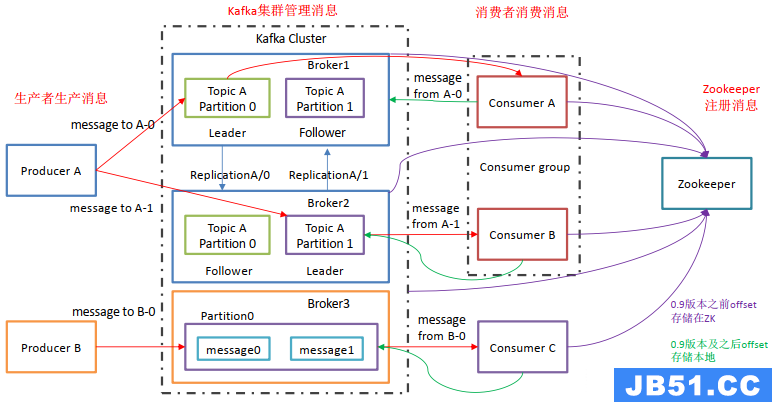
Kafka像其他Mq一样,也有自己的基础架构,主要存在生产者Producer、Kafka集群Broker、消费者Consumer、注册消息Zookeeper.
Producer:消息生产者,向Kafka中发布消息的角色。Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个TopicPartition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个-FollowerLeader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
上述一个Topic会产生多个分区Partition,分区中分为Leader和Follower,消息一般发送到Leader,Follower通过数据的同步与Leader保持同步,消费的话也是在Leader中发生消费,如果多个消费者,则分别消费Leader和各个Follower中的消息,当Leader发生故障的时候,某个Follower会成为主节点,此时会对齐消息的偏移量。
原文地址:https://blog.csdn.net/qq_29917503/article/details/136042705
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。