
3.1 生产者消息发送流程
3.1.1 发送原理
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程
中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,
Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
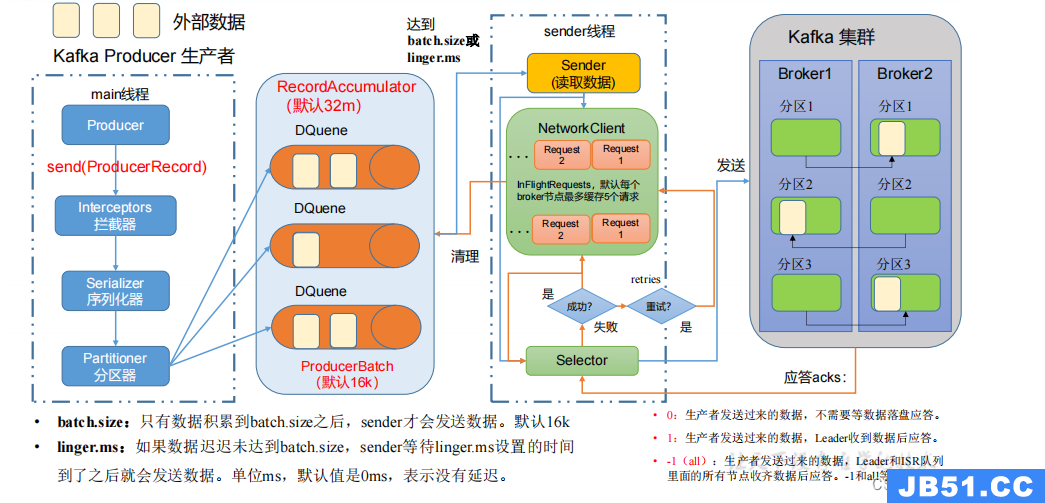
3.1.2 生产者重要参数列表

3.2 异步发送 API
3.2.1 普通异步发送
1)需求:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
2)代码编写
(1)创建工程 kafka
(2)导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
(3)创建包名:com.atguigu.kafka.producer
(4)编写不带回调函数的 API 代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducer {
public static void main(String[] args) throws
InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<String, String>(properties);
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new
ProducerRecord<>("first","atguigu " + i));
}
// 5. 关闭资源
kafkaProducer.close();
}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
3.2.2 带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元
数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发
送成功,如果 Exception 不为 null,说明消息发送失败。
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallback {
public static void main(String[] args) throws
InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 3. 创建 kafka 生产者对象
KafkaProducer<String,发送消息
for (int i = 0; i < 5; i++) {
// 添加回调
kafkaProducer.send(new ProducerRecord<>("first",
"prince " + i), new Callback() {
// 该方法在 Producer 收到 ack 时调用,为异步调用
@Override
public void onCompletion(RecordMetadata metadata,
Exception exception) {
if (exception == null) {
// 没有异常,输出信息到控制台
System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition());
} else {
// 出现异常打印
exception.printStackTrace();
}
}
});
// 延迟一会会看到数据发往不同分区
Thread.sleep(2);
}
// 5. 关闭资源
kafkaProducer.close();
}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
prince 0
prince 1
prince 2
prince 3
prince 4
③在 IDEA 控制台观察回调信息。
主题:first->分区:0
主题:first->分区:0
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
3.3 同步发送 API
只需在异步发送的基础上,再调用一下 get()方法即可。
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class CustomProducerSync {
public static void main(String[] args) throws
InterruptedException, ExecutionException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");
// key, String>(properties);
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 10; i++) {
// 异步发送 默认
// kafkaProducer.send(new
ProducerRecord<>("first","kafka" + i));
// 同步发送
kafkaProducer.send(new
ProducerRecord<>("first","kafka" + i)).get();
}
// 5. 关闭资源
kafkaProducer.close();
}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
3.4 生产者分区
3.4.1 分区好处
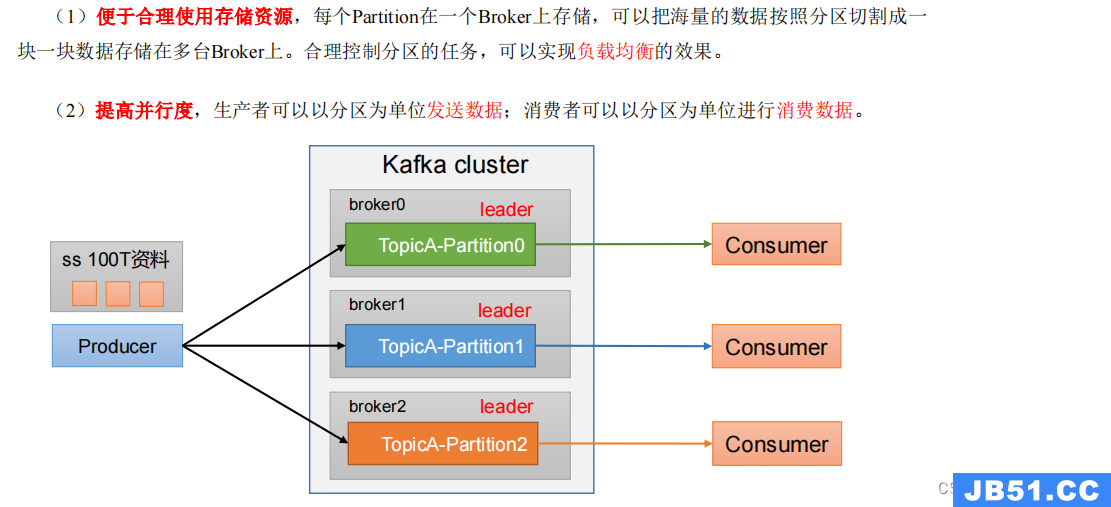
3.4.2 生产者发送消息的分区策略
1)默认的分区器 DefaultPartitioner
在 IDEA 中 ctrl +n,全局查找 DefaultPartitioner。
/**
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record,use it
* <li>If no partition is specified but a key is present choose a
partition based on a hash of the key
* <li>If no partition or key is present choose the sticky
partition that changes when the batch is full.
*
* See KIP-480 for details about sticky partitioning.
*/
public class DefaultPartitioner implements Partitioner {
… …
}

2)案例一
将数据发往指定 partition 的情况下,例如,将所有数据发往分区 1 中。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallbackPartitions {
public static void main(String[] args) {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
StringSerializer.class.getName());
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
// 指定数据发送到 1 号分区,key 为空(IDEA 中 ctrl + p 查看参数)
kafkaProducer.send(new ProducerRecord<>("first",
1,"","prince " + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata,
Exception e) {
if (e == null){
System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition()
);
}else {
e.printStackTrace();
}
}
});
}
kafkaProducer.close();
}
}
测试:
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
prince 0
prince 1
prince 2
prince 3
prince 4
③在 IDEA 控制台观察回调信息。
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
3)案例二
没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取
余得到 partition 值。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallback {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102
:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, String> kafkaProducer = new
KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
// 依次指定 key 值为 a,b,f ,数据 key 的 hash 值与 3 个分区求余,
分别发往 1、2、0
kafkaProducer.send(new ProducerRecord<>("first",
"a",
Exception e) {
if (e == null){
System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition()
);
}else {
e.printStackTrace();
}
}
});
}
kafkaProducer.close();
}
}
测试:
①key="a"时,在控制台查看结果。
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
②key="b"时,在控制台查看结果。
主题:first->分区:2
主题:first->分区:2
主题:first->分区:2
主题:first->分区:2
主题:first->分区:2
③key="f"时,在控制台查看结果。
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
3.4.3 自定义分区器
如果研发人员可以根据企业需求,自己重新实现分区器。
1)需求
例如我们实现一个分区器实现,发送过来的数据中如果包含 atguigu,就发往 0 号分区,
不包含 atguigu,就发往 1 号分区。
2)实现步骤
(1)定义类实现 Partitioner 接口。
(2)重写 partition()方法。
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 1. 实现接口 Partitioner
* 2. 实现 3 个方法:partition,close,configure
* 3. 编写 partition 方法,返回分区号
*/
public class MyPartitioner implements Partitioner {
/
* 返回信息对应的分区
* @param topic 主题
* @param key 消息的 key
* @param keyBytes 消息的 key 序列化后的字节数组
* @param value 消息的 value
* @param valueBytes 消息的 value 序列化后的字节数组
* @param cluster 集群元数据可以查看分区信息
* @return
*/
@Override
public int partition(String topic, Object key, byte[]
keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取消息
String msgValue = value.toString();
// 创建 partition
int partition;
// 判断消息是否包含 atguigu
if (msgValue.contains("atguigu")){
partition = 0;
}else {
partition = 1;
}
// 返回分区号
return partition;
}
// 关闭资源
@Override
public void close() {
}
// 配置方法
@Override
public void configure(Map<String, ?> configs) {
}
}
(3)使用分区器的方法,在生产者的配置中添加分区器参数。
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class CustomProducerCallbackPartitions {
public static void main(String[] args) throws
InterruptedException {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
StringSerializer.class.getName());
// 添加自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.atgui
gu.kafka.producer.MyPartitioner");
KafkaProducer<String, String> kafkaProducer = new
KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<>("first",
Exception e) {
if (e == null){
System.out.println(" 主题: " +
metadata.topic() + "->" + "分区:" + metadata.partition()
);
}else {
e.printStackTrace();
}
}
});
}
kafkaProducer.close();
}
}
(4)测试
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 控制台观察回调信息。
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
主题:first->分区:0
3.5 生产经验——生产者如何提高吞吐量

import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerParameters {
public static void main(String[] args) throws
InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// batch.size:批次大小,默认 16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// linger.ms:等待时间,默认 0
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// RecordAccumulator:缓冲区大小,默认 32M:buffer.memory
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,
33554432);
// compression.type:压缩,默认 none,可配置值 gzip、snappy、
lz4 和 zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
// 3. 创建 kafka 生产者对象
KafkaProducer<String,"prince " + i));
}
// 5. 关闭资源
kafkaProducer.close();
}
}
测试
①在 hadoop102 上开启 Kafka 消费者。
[hadoop103 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
[hadoop102 kafka]$ bin/kafka-console-consumer.sh --
bootstrap-server hadoop102:9092 --topic first
prince 0
prince 1
prince 2
prince 3
prince 4
3.6 生产经验——数据可靠性
1)ack 应答原理
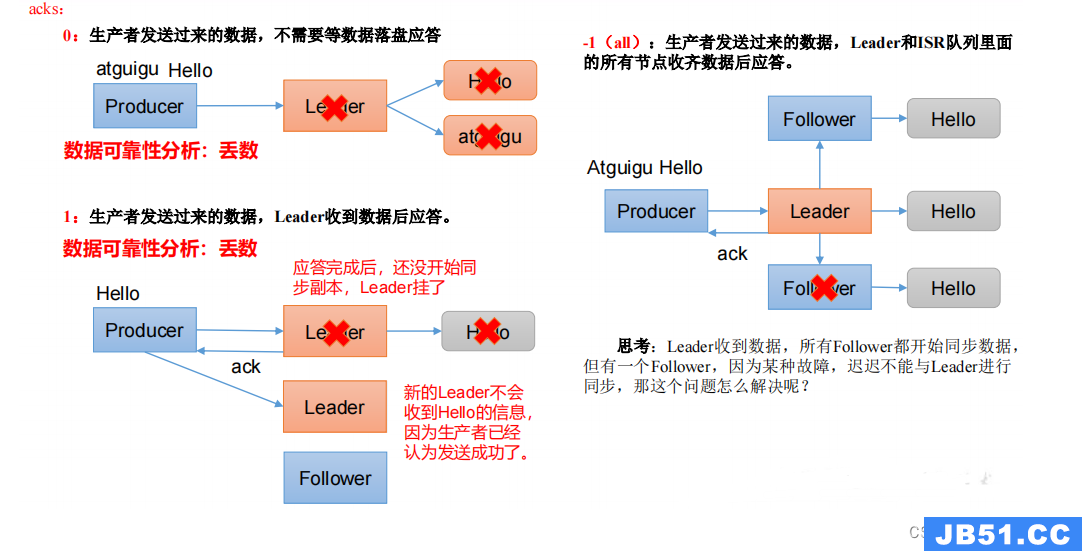
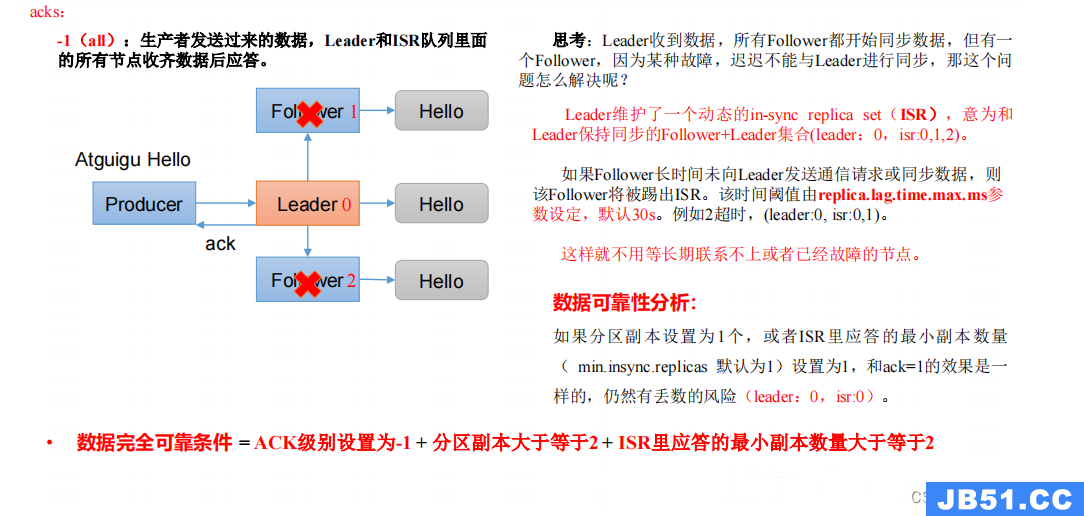

2)代码配置
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerAck {
public static void main(String[] args) throws
InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
102:9092");
// key,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 设置 acks
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 重试次数 retries,默认是 int 最大值,2147483647
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 3. 创建 kafka 生产者对象
KafkaProducer<String,"prince " + i));
}
// 5. 关闭资源
kafkaProducer.close();
}
}
3.7 生产经验——数据去重
3.7.1 数据传递语义

3.7.2 幂等性
1)幂等性原理

2)如何使用幂等性
开启参数 enable.idempotence 默认为 true,false 关闭。
3.7.3 生产者事务
1)Kafka 事务原理
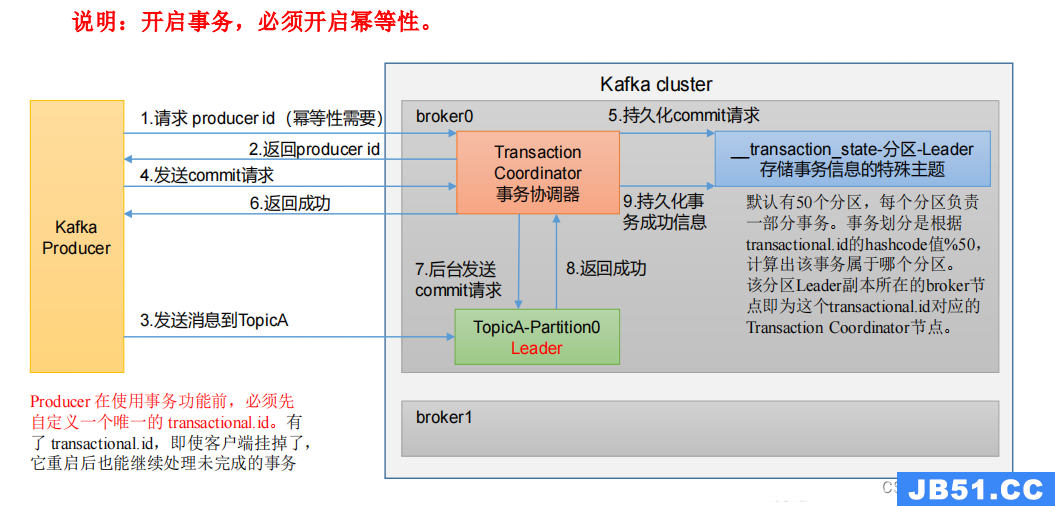
2)Kafka 的事务一共有如下 5 个 API
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws
ProducerFencedException;
// 4 提交事务
void commitTransaction() throws ProducerFencedException;
// 5 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;
3)单个 Producer,使用事务保证消息的仅一次发送
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerTransactions {
public static void main(String[] args) throws
InterruptedException {
// 1. 创建 kafka 生产者的配置对象
Properties properties = new Properties();
// 2. 给 kafka 配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
"hadoop102:9092");
// key,value 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 设置事务 id(必须),事务 id 任意起名
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,
"transaction_id_0");
// 3. 创建 kafka 生产者对象
KafkaProducer<String, String>(properties);
// 初始化事务
kafkaProducer.initTransactions();
// 开启事务
kafkaProducer.beginTransaction();
try {
// 4. 调用 send 方法,发送消息
for (int i = 0; i < 5; i++) {
// 发送消息
kafkaProducer.send(new ProducerRecord<>("first",
"prince " + i));
}
// int i = 1 / 0;
// 提交事务
kafkaProducer.commitTransaction();
} catch (Exception e) {
// 终止事务
kafkaProducer.abortTransaction();
} finally {
// 5. 关闭资源
kafkaProducer.close();
}
}
}
3.8 生产经验——数据有序
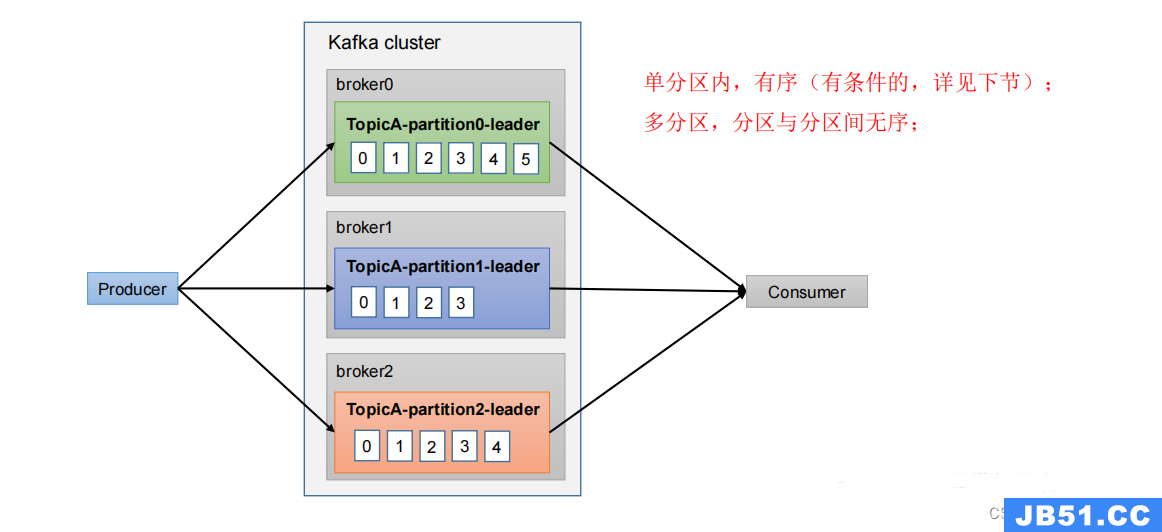
3.9 生产经验——数据乱序
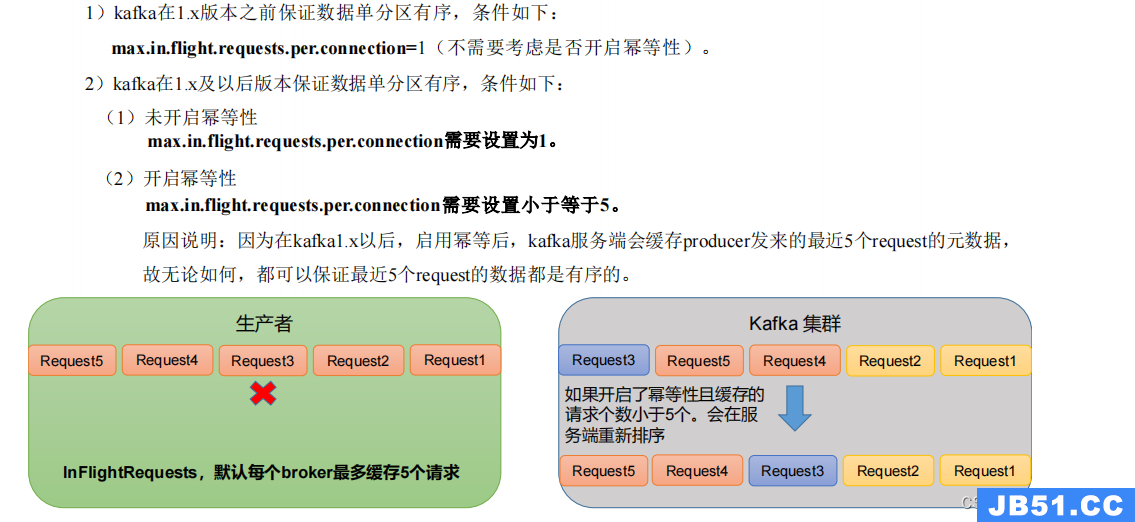
原文地址:https://blog.csdn.net/weixin_45817985/article/details/133939024
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。