
1.环境配置
| 主机 | 操作系统 | IP地址 | 安装软件 |
| kafka1 | Centos7.5 | 192.168.106.160 | JDK1.8、zookeeper、kafka |
| kafka2 | Centos7.5 | 192.168.106.161 | JDK1.8、zookeeper、kafka |
| kafka3 | Centos7.5 | 192.168.106.162 | JDK1.8、zookeeper、kafka |
| F5 | BIGIP-12.1.6 | 192.168.202.22 | BIGIP-12.1.6 |
2.准备工作
1.关闭防火墙
kafka1,kafka2,kafka3三台主机均执行以下操作
##关闭防火墙
systemctl stop firewalld
##禁止开机启动
systemctl disable firewalld

2.下载JDK
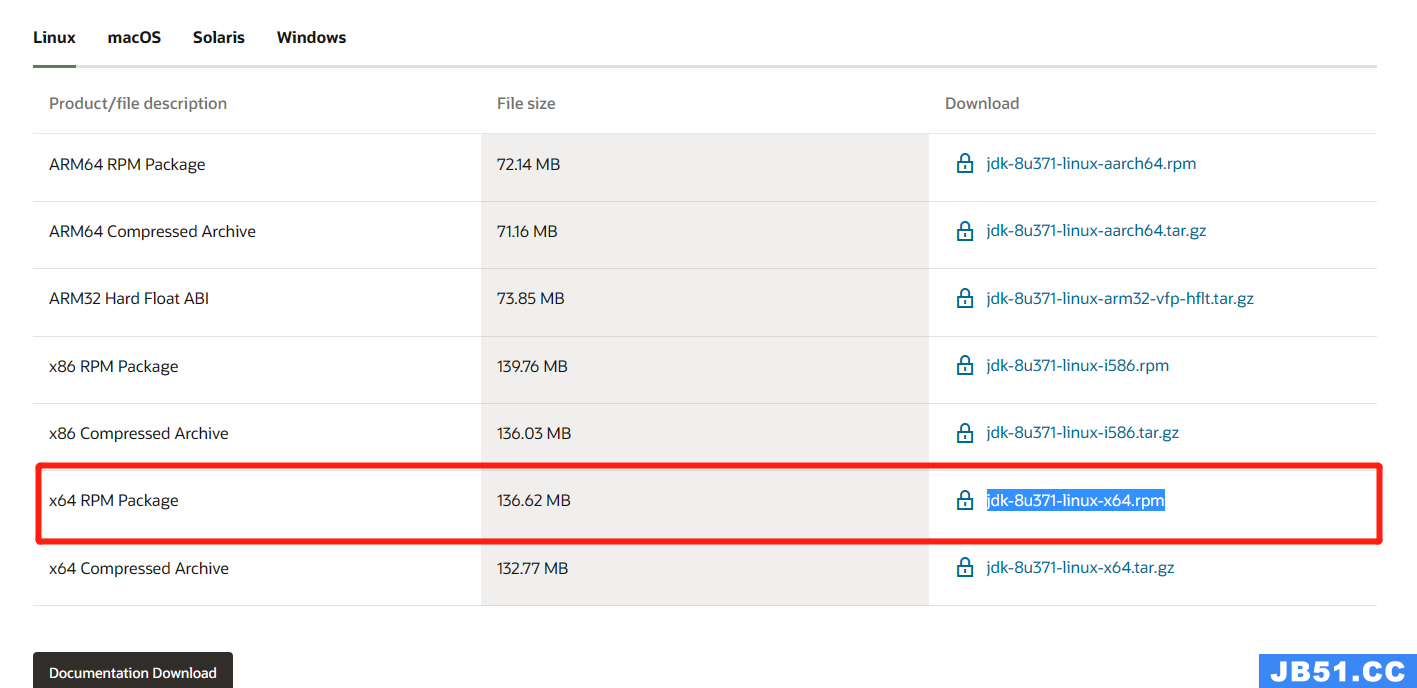
点击下载JDK:Java Downloads | Oracle
3.关于zookeeper
本次实验是用的kafka自带zookeeper
4.下载kafka
点击下载kafka:https://downloads.apache.org/kafka/3.0.2/kafka_2.12-3.0.2.tgz
5.下载F5
点击注册:MyF5 | Login
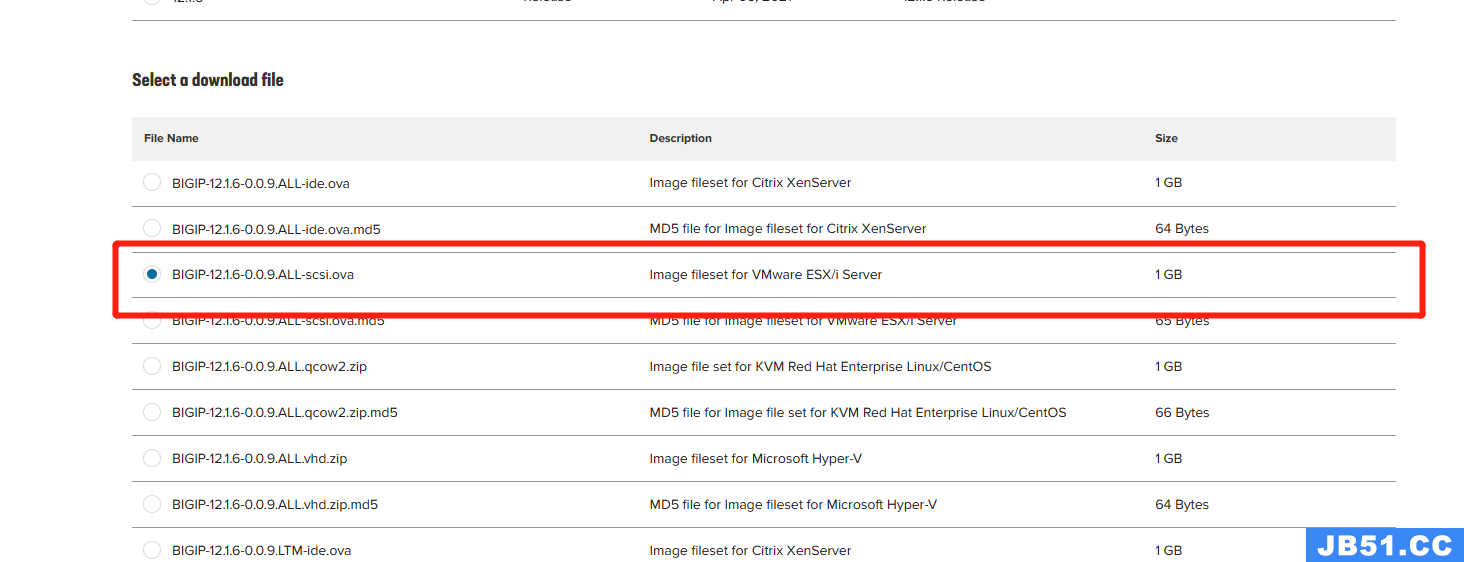
然后根据流程注册申请License,然后下载.OVA镜像

注意下载版本,我这里用的是BIGIP-12.1.6-0.0.9:
3.环境安装
1.安装JDK(在三台kafka主机操作)
上传JDK至主机kafka1根目录,然后执行代码安装,完成后验证是否安装成功
##安装JDK
yum install jdk-8u371-linux-x64.rpm
##验证安装成功
java -version因为是yum安装,不需要自行配置环境变量,主机kafka2跟主机kafka3 相同操作。

2.安装kafka(在三台kafka主机操作)
1.创建kafka运行目录,然后将kafka上传至目录解压
##创建文件夹
mkdir /opt/kafka
##将kafka压缩包上传至此目录
##进入此目录并解压
cd /opt/fakfa
tar zxvf kafka_2.12-3.0.2.tgz
2.创建日志保存地址
##创建日志保存地址
mkdir -p /opt/zookeeper-log/{data,log}
mkdir -p /opt/kafka-log/{data,log}
3.修改zookeeper.properties配置文件
##进入配置文件所在目录
cd /opt/kafka/kafka_2.12-3.0.2/config/
##修改配置文件
vi zookeeper.properties
##改为以下内容:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License,Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,software
# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND,either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=/opt/zookeeper-log/data
dataLogDir=/opt/zookeeper-log/logo
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
# 在后面添加这六行
tickTime=2000
initLimit=10
syncLimit=5
server.1=192.168.106.160:2888:3888
server.2=192.168.106.161:2888:3888
server.3=192.168.106.162:2888:3888
以上步骤三台kafka主机操作配置均相同。
4.修改server.properties配置文件
##进入配置文件所在目录
cd /opt/kafka/kafka_2.12-3.0.2/config/
##修改配置文件
vi server.propertieskafka1修改为:
###################### Server Basics ###################
# kafka1为0,kafka2为1,kafka3为2,以此类推
broker.id=0
####################### Socket Server Settings ######################
# 填写本机IP地址.
advertised.listeners=PLAINTEXT://192.168.106.160:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 填写刚刚创建的日志路径
log.dirs=/opt/fakfa-log
# 分区数写为3
num.partitions=3
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
#副本数改为3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
############################# Log Retention Policy #############################
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# 这里填写刚刚在zookeeper.properties添加的地址,以逗号隔开
zookeeper.connect=192.168.106.160:2181,192.168.106.161:2181,192.168.106.162:2181
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0
完成后命令行输入以下命令写入myid
echo "1" >/opt/zookeeper-log/data/myid
kafka2修改为:
###################### Server Basics ###################
# kafka1为0,kafka2为1,kafka3为2,以此类推
broker.id=1
####################### Socket Server Settings ######################
# 填写本机IP地址.
advertised.listeners=PLAINTEXT://192.168.106.161:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 填写刚刚创建的日志路径
log.dirs=/opt/fakfa-log
# 分区数写为3
num.partitions=3
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
#副本数改为3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
############################# Log Retention Policy #############################
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# 这里填写刚刚在zookeeper.properties添加的地址,以逗号隔开
zookeeper.connect=192.168.106.160:2181,192.168.106.162:2181
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0
完成后命令行输入以下命令写入myid
echo "2" >/opt/zookeeper-log/data/myidkafka3修改为:
###################### Server Basics ###################
# kafka1为0,kafka2为1,kafka3为2,以此类推
broker.id=2
####################### Socket Server Settings ######################
# 填写本机IP地址.
advertised.listeners=PLAINTEXT://192.168.106.162:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 填写刚刚创建的日志路径
log.dirs=/opt/fakfa-log
# 分区数写为3
num.partitions=3
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
#副本数改为3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
############################# Log Retention Policy #############################
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# 这里填写刚刚在zookeeper.properties添加的地址,以逗号隔开
zookeeper.connect=192.168.106.160:2181,192.168.106.162:2181
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
group.initial.rebalance.delay.ms=0
完成后命令行输入以下命令写入myid
echo "3" >/opt/zookeeper-log/data/myid
4.启动集群
1.启动zookeeper
三台主机均输入以下命令启动
##进入kafka目录
cd /opt/kafka/kafka_2.12-3.0.2/
##输入命令启动
bin/zookeeper-server-start.sh config/zookeeper.properties &
2.启动kafka:
bin/kafka-server-start.sh config/server.properties &3.输入jps查看是否启动成功

4.测试集群效果
将kafka1作为主机,kafka2跟3作为从机,在kafka1执行下列命令,创建一个test主题并查看
##创建主题
bin/kafka-topics.sh --bootstrap-server 192.168.106.160:9092 --create --topic test --partitions 1
##查看主题
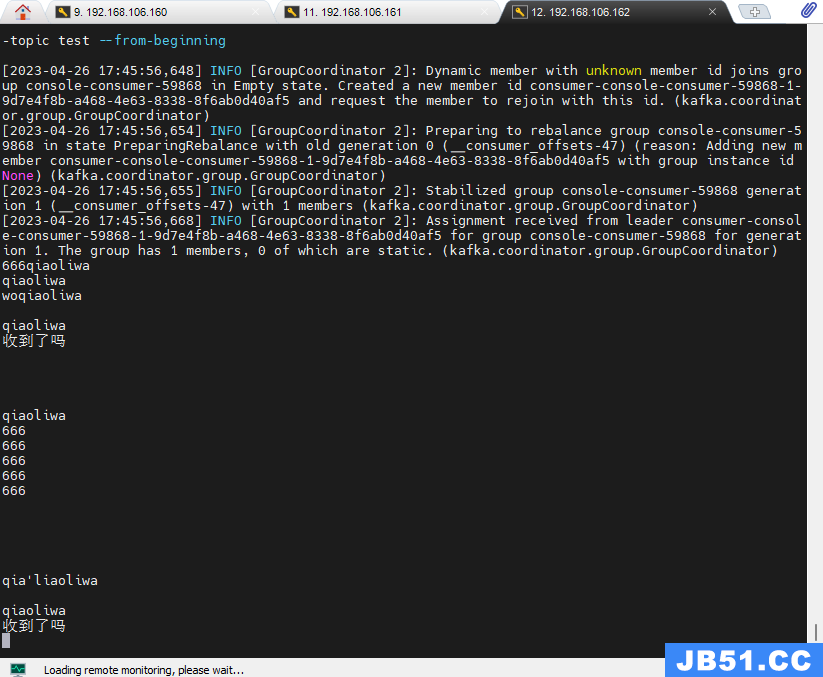
bin/kafka-topics.sh --bootstrap-server 192.168.106.160:9092 --list创建完成后,测试消息的订阅和发送功能:
# 在kafka1 上发布消息
bin/kafka-console-producer.sh --broker-list 192.168.106.160:9092 --topic test
# 在kafka2 上接收
bin/kafka-console-consumer.sh --bootstrap-server 192.168.106.161:9092 --topic test --from-beginning
# 在kafka2 上接收
bin/kafka-console-consumer.sh --bootstrap-server 192.168.106.162:9092 --topic test --from-beginning
实现效果:


5.负载均衡实现
负载均衡的安装等流程在我以前的文章有所提及,再次篇不再赘述,如有不懂的朋友们可以评论或者私信小编,小编看到会帮助其解答疑惑。
1.登陆后配置vlan
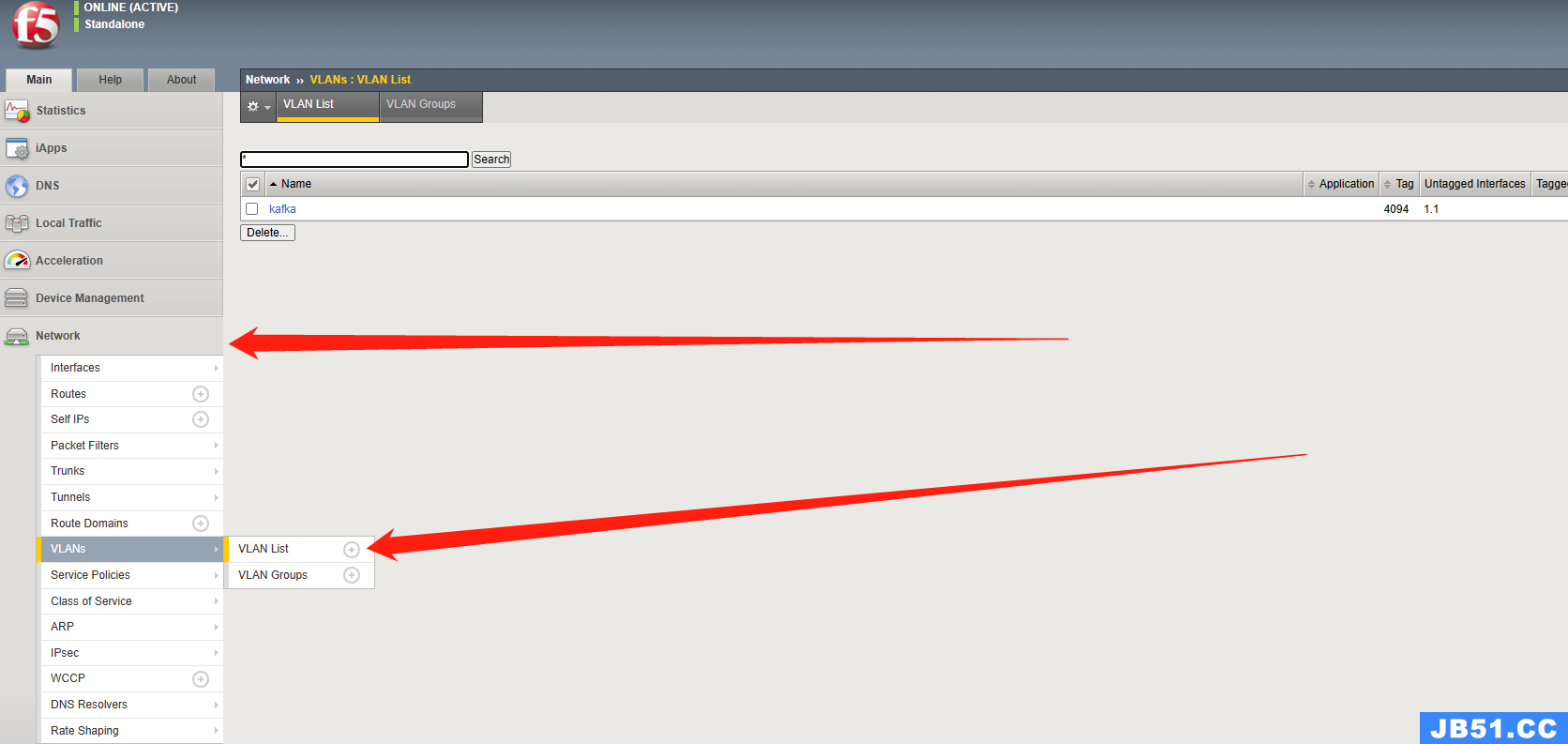

2.创建完成后添加IP


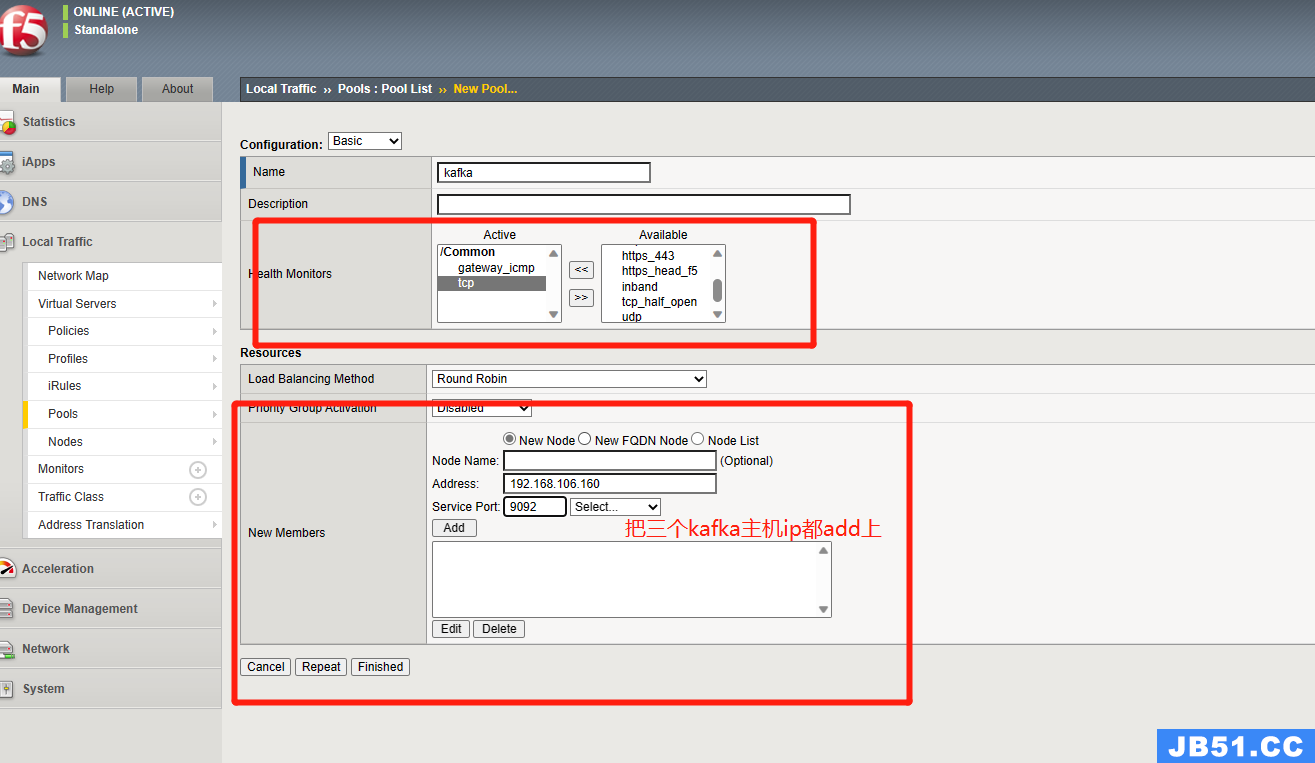
3.添加完IP后配置pools


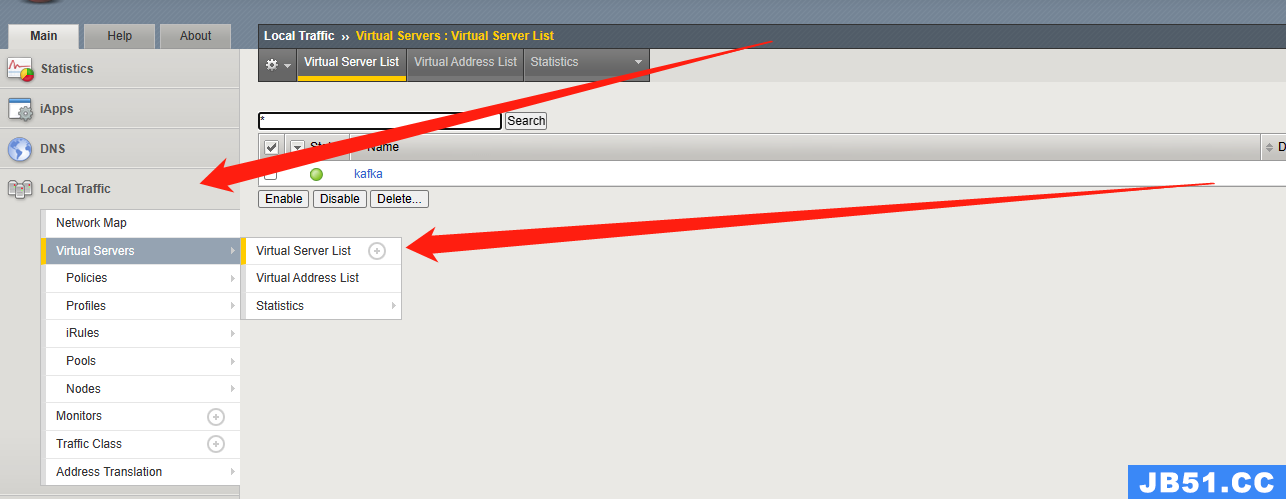
4.然后去配置virtual servers
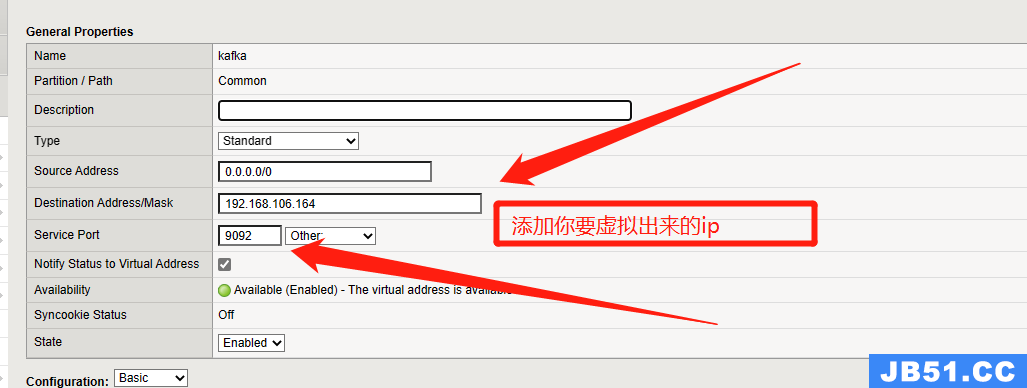
下拉修改,然后提交即可。

5.保存后点击你新建virtual servers的名字进入配置,然后点击Resources,进入后将其添加至pools。至此负载均衡已经配置完成

6.测试负载均衡效果
我在virtual servers添加的虚拟ip是192.168.106.164,下面测试我将用此IP进行展示。
# 在kafka1 上发布消息
bin/kafka-console-producer.sh --broker-list 192.168.106.164:9092 --topic test
# 在kafka2 上接收
bin/kafka-console-consumer.sh --bootstrap-server 192.168.106.164:9092 --topic test --from-beginning
# 在kafka2 上接收
bin/kafka-console-consumer.sh --bootstrap-server 192.168.106.164:9092 --topic test --from-beginning
可以看到现在将收发消息的ip都换成了192.168.106.164,并且现在也不分主从,三台主机随便都可以做收发端,下面是效果展示

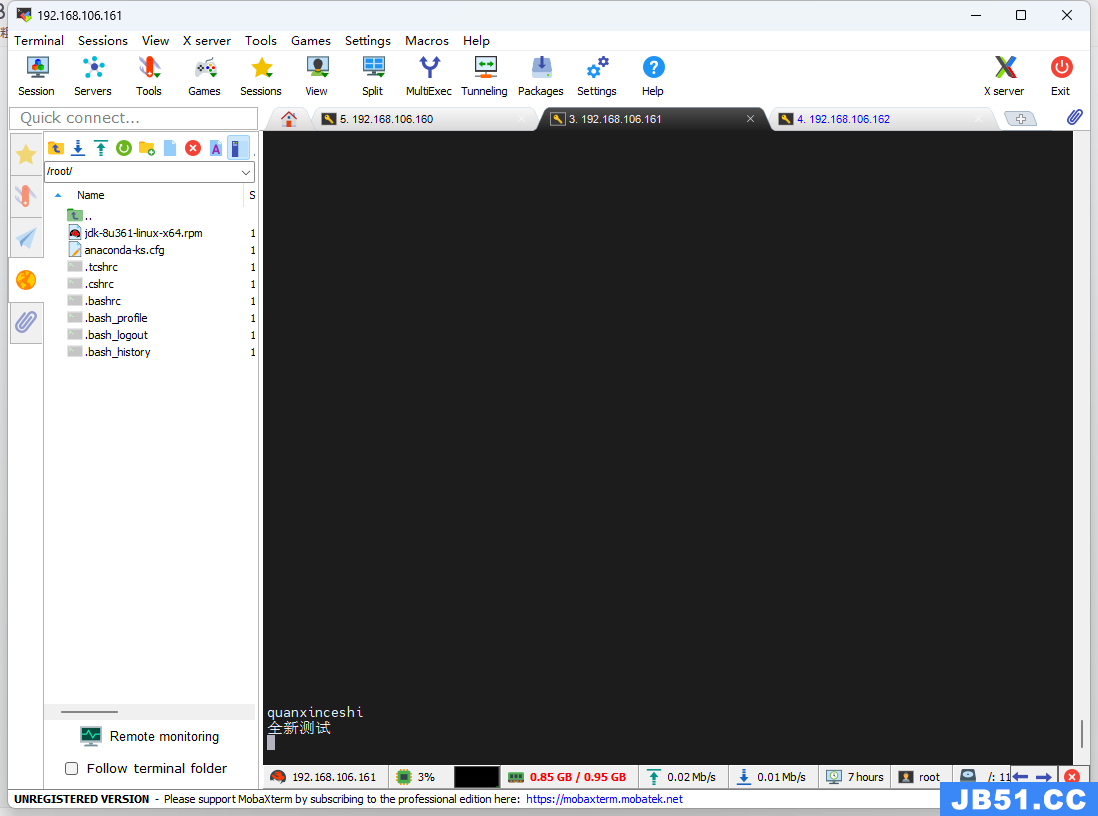

此次实验已经完美结束了,中间也有很多小问题,不过到最后都完美解决了,上述就是全部的实验流程,大家如果有什么不懂的可以留言或者私信小编,小编看到后会第一时间给大家解答。
原文地址:https://blog.csdn.net/weixin_45109326/article/details/130382100
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。