
KAFKA (2.12-2.2.1)常用命令
查看topic
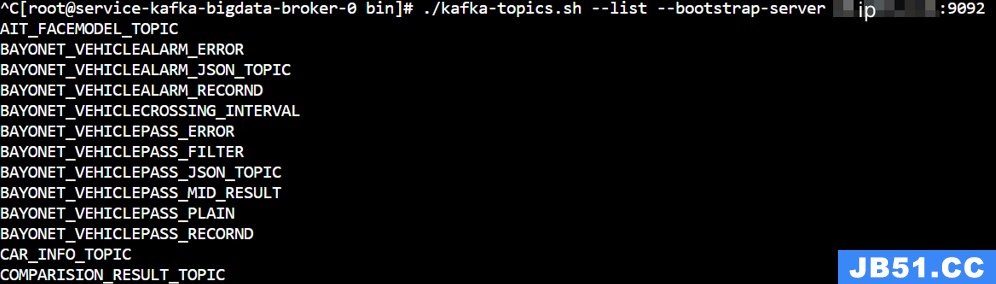
查看所有topic列表
#集群地址以逗号分隔如 ip1:9092,ip2:9092,ip3:9092
./kafka-topics.sh --list --bootstrap-server ip:9092
新建分区1副本1的topic
./kafka-topics.sh --bootstrap-server ip:9092 --create --topic demo0218 --partitions 1 --replication-factor 1
查看某个topic
./kafka-topics.sh --bootstrap-server ip:9092 --describe --topic demo0218

#修改demo0218分区为3(分区数建议只增不减,分区数据不好处理)
#分区内部消息有序,分区之间消息无序
./kafka-topics.sh --bootstrap-server ip:9092 --alter --topic demo0218 --partitions 3

生产消息
./kafka-console-producer.sh --broker-list ip:9092 --topic demo0218

消费消息
#–from-beginning :
#加上:会把topic中以往所有的数据都读取出来
#不加:此时只会消费最新的数据,原来topic中的数据不会被消费
./kafka-console-consumer.sh --bootstrap-server ip:9092 -from-beginning --topic demo0218 --group hik0218

查看指定消费者组的消费topic 的位置情况,查看消费是否存在积压(LAG)
./kafka-consumer-groups.sh --bootstrap-server ip:9092 --group hik0218 –describe

删除topic demo0228
./kafka-topics.sh --bootstrap-server ip:9092 --delete --topic demo0218

Kafka tool简介
Kafka tool为kafka 较为通用的客户端连接工具之一,通过连接kafka直接明了的查看kafka数据、创建删除topic,添加kafka数据完成简单流程验证、查看topic消费情况等功能
Kafka Tool 工具下载地址:
http://www.kafkatool.com/download.html
Kafka 连接配置
1)启动 Kafka Tool
在安装目录下,双击可执行文件 kafkatool.exe,启动 Kafka Tool
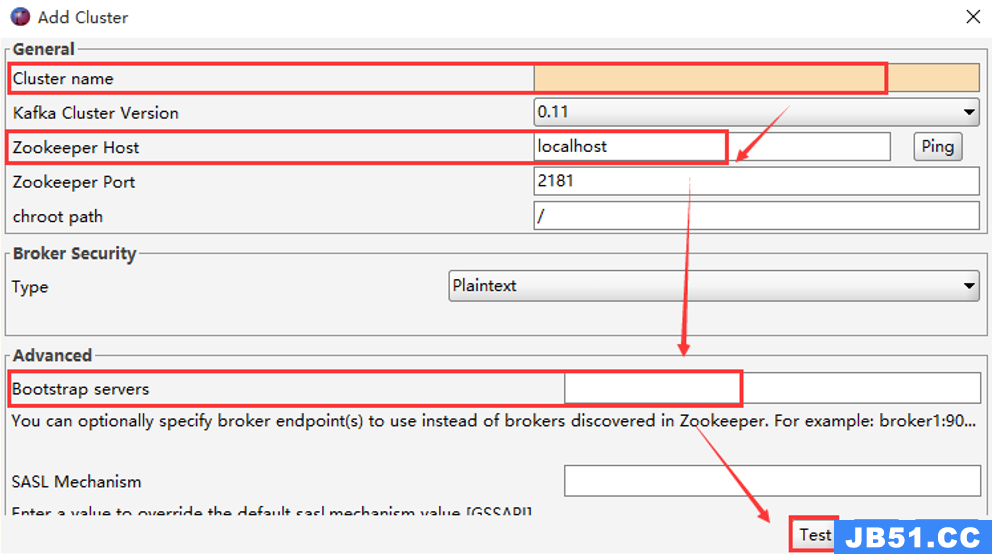
2)配置 Kafka 连接信息
File -> Add New Connection…
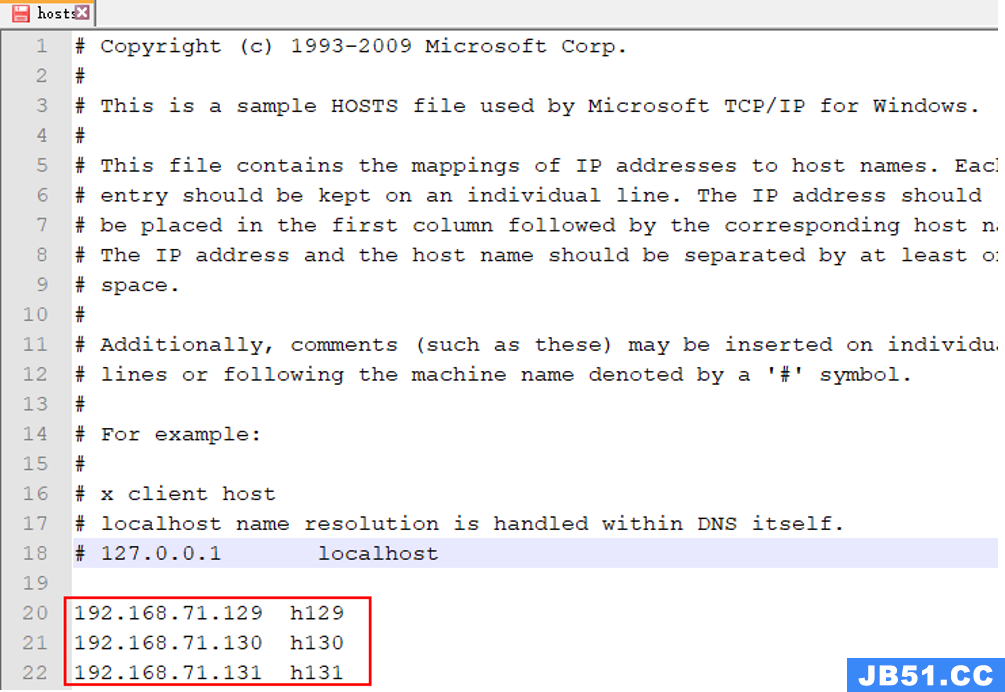
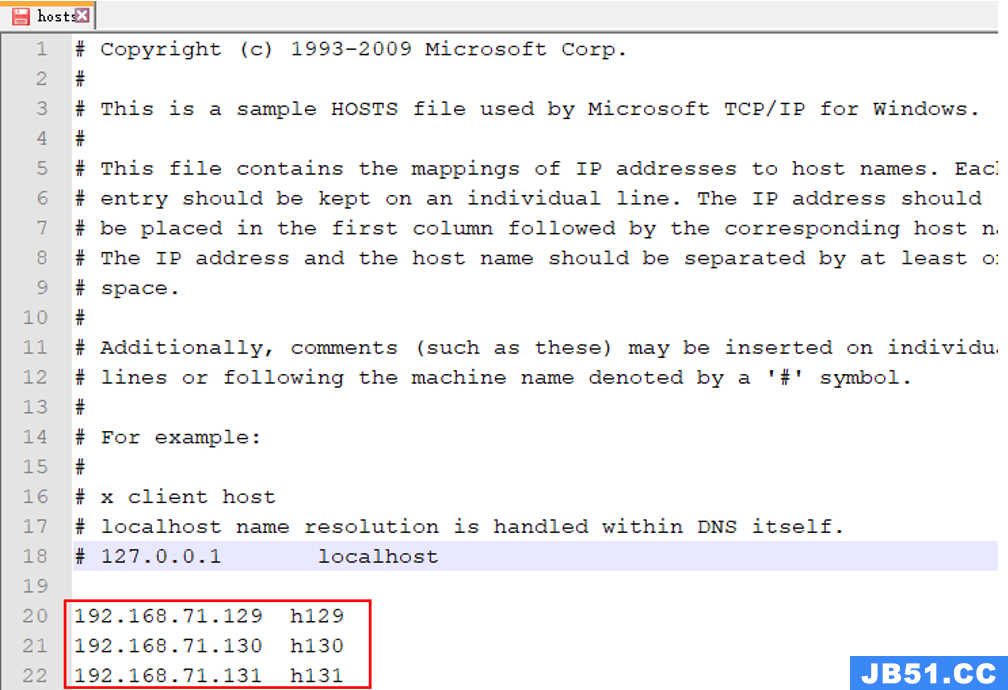
【注意】需要在 C:\Windows\System32\drivers\etc 下的 hosts 文件中,添加入 kafka 的集群域名(配置保存后,需要重启KafkaTools才能读取hosts文件中的内容)
例如:
查看 Kafka 数据
1)查看 Kafka 数据
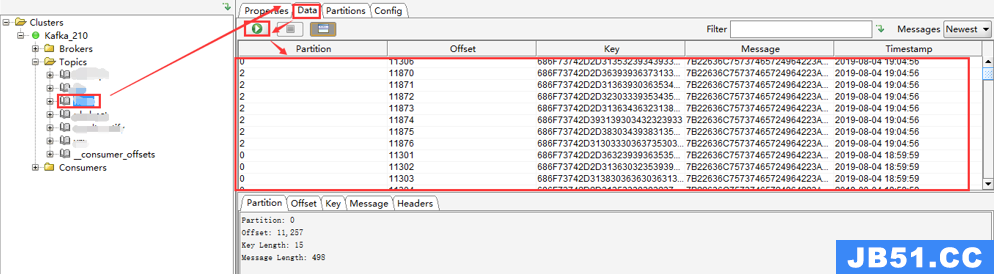
选择一个Topic -> Data,点击查询即可看到数据(但是Key和Message是二进制的,不能直观的看到具体的消息信息,需要设置展示格式)
Messages选择Newest,表示查看最新的Kafka数据;
结果列表中的每列,通过点击表头,可以按照升序或者降序排序(一般用在时间字段排序,方便查看最新数据)。
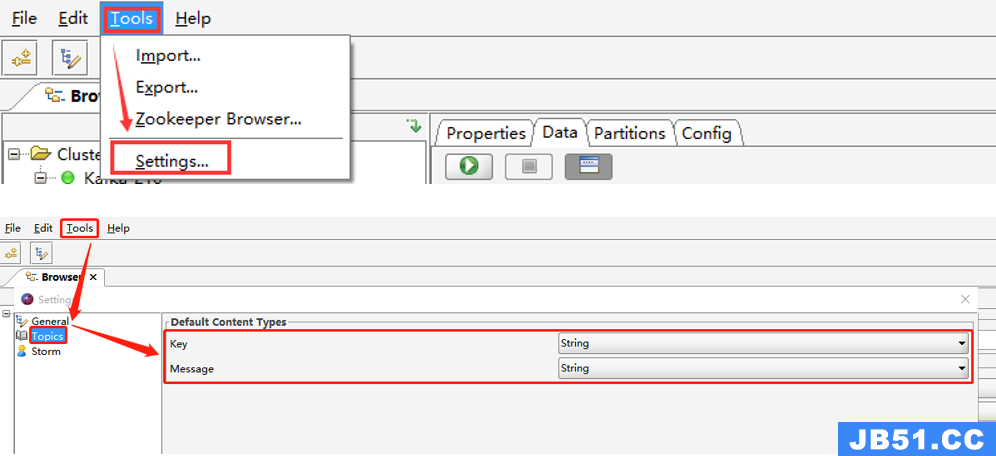
2)设置 Kafka 数据展示格式
在Tools -> Settings -> Topics,将 Key 和 Message 均设置为String 保存。这样是全局设置,对所有 Topic 均生效。
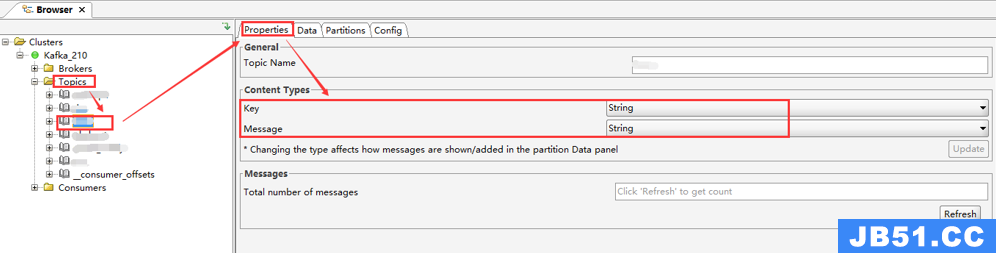
如果只是想单独设置某个 Topic,可以选中某个 Topic,在 Properties -> Content Type 中,将显示格式设置为String,点击 Update -> Refresh 即可生效
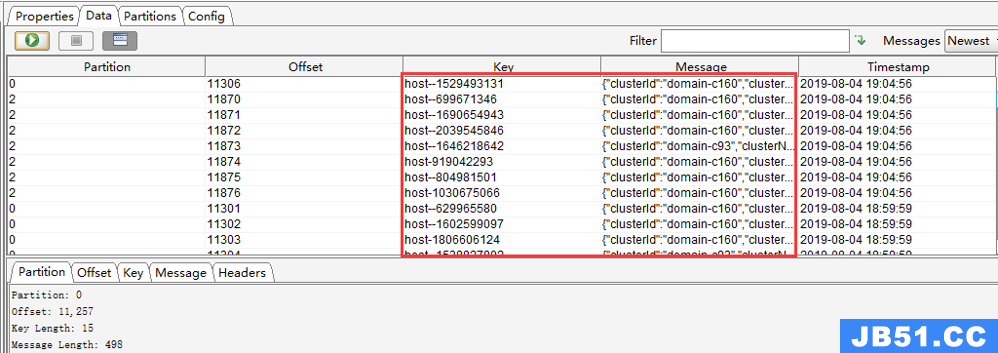
设置后的数据列表如下
3)查看具体某一条消息
选中某一个message,点击“Message”查看详情,默认是“Text”格式(如果想看到JSON格式,只需要设置下“View Data As”即可)
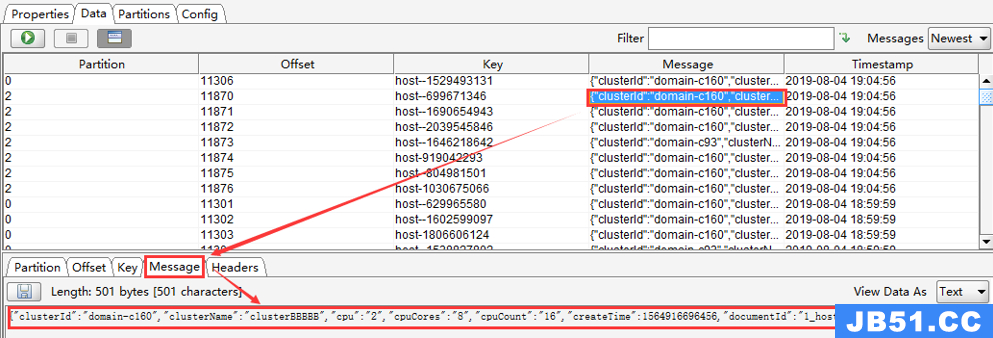
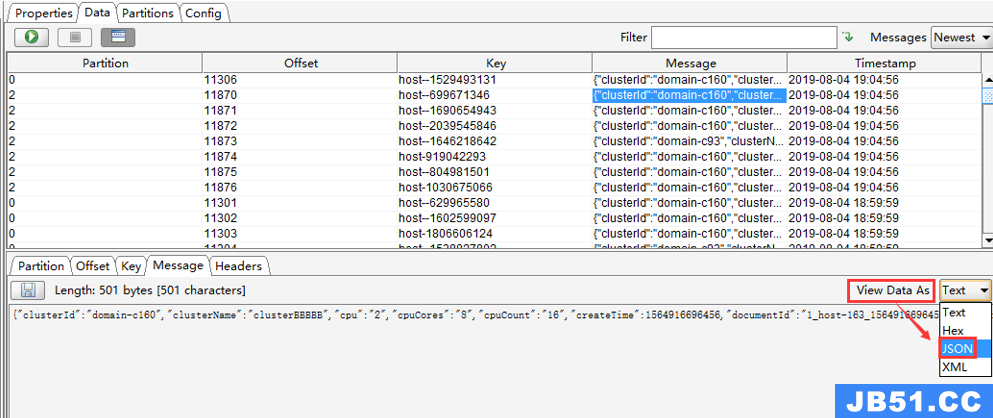
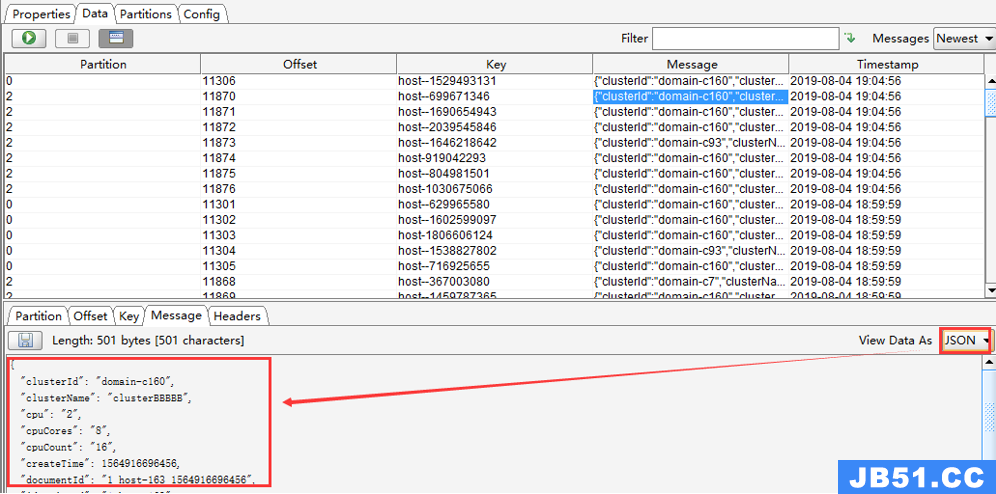
“View Data As”设置为 JSON 后,消息信息格式如下
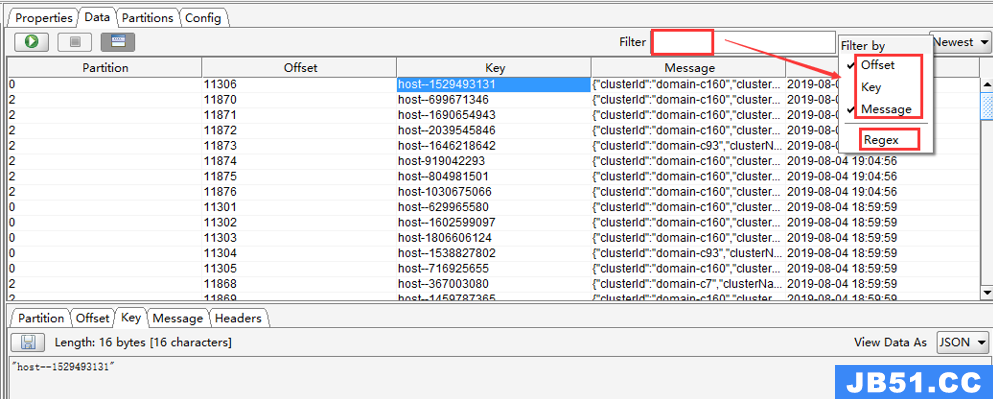
4)过滤查询 Kafka 消息
可以按照Offset(偏移量),Key(消息key),Message(消息主体),Regex(正则表达式)进行单个或者组合查询
使用 Kafka Tool 创建 Topic
1) 创建 Topic
步骤如下:
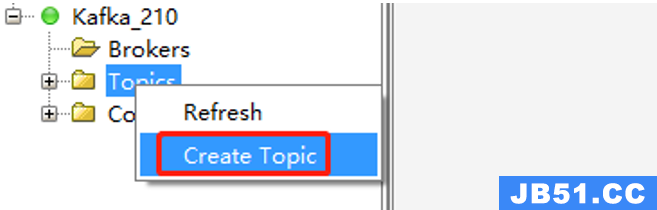
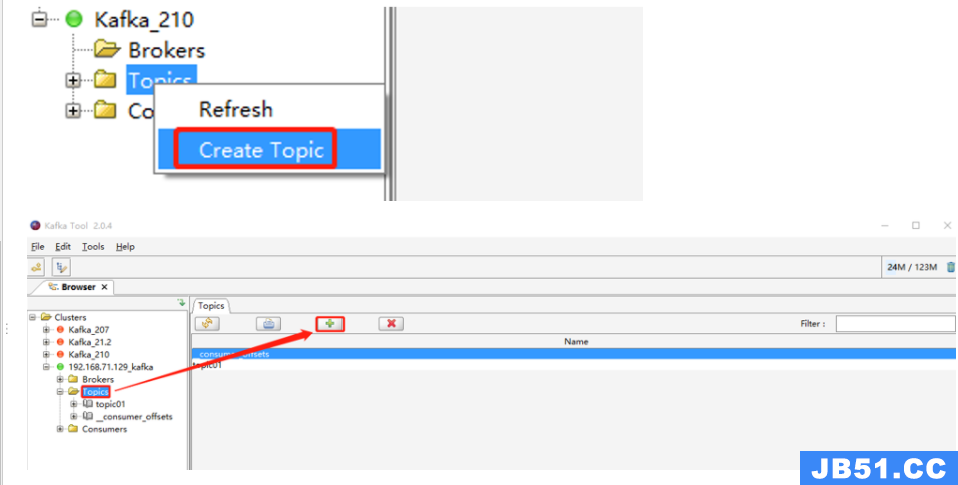
1、鼠标右键点击 “Topics” 文件夹图标 -> 选择 “Create Topic”,或者点击“Topics”,单击右侧页面中的“+”,会弹出“Add Topic”页面;
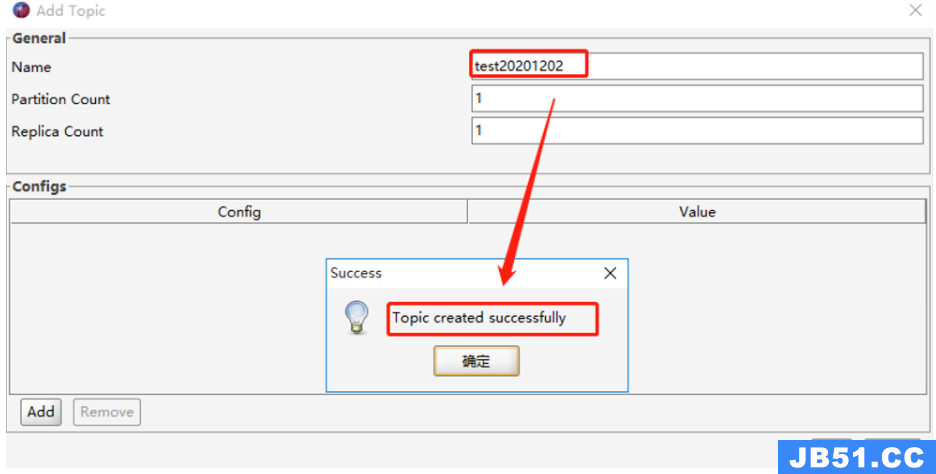
2、填写需要创建的Topic名称,分区数和备份数,点击“Add”添加,即可创建 topic。
效果如下:
2)查看创建的 Topic
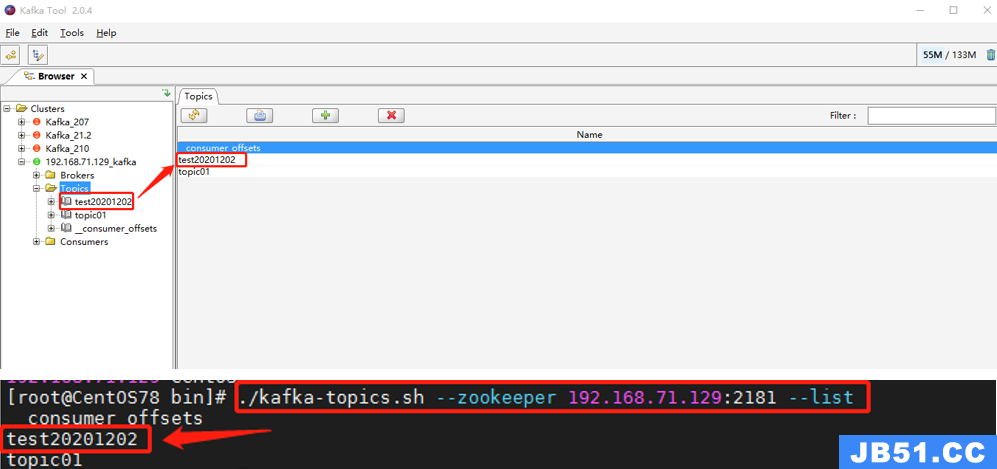
创建的出来的 topic,可以在 Topic 列表或者通过 Kafka topic 命令查看。
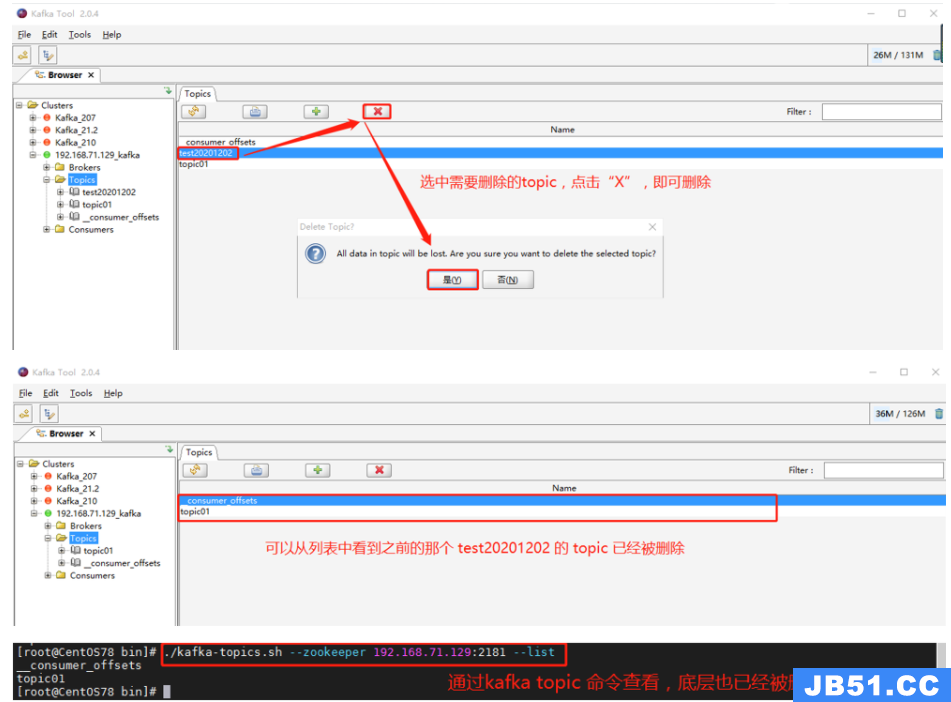
3)删除 Topic
如果因为失误导致创建的 topic 不是自己想要的,想进行删除,也可以通过 KafkaTool 进行界面化删除。
效果如下:
4)补充说明
如果通过 Kafka Tool 创建 topic 失败,请确认如下两点:
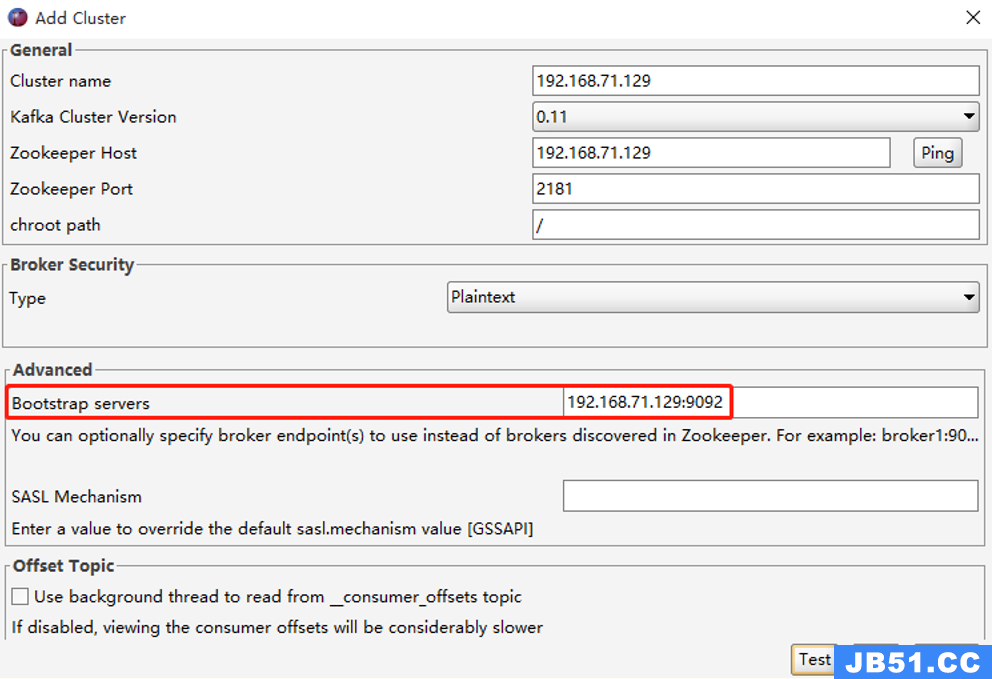
a)是否按照如下截图配置的Cluster Connection
(本次举例是单台机器,如果实际是集群,需要把 bootstrap servers进行集群配置,如3台集群配置:192.168.71.129:9092,192.168.71.130:9092,192.168.71.131:9092)
b)是否按照kafka连接配置的说明在hosts文件中配置了域名
使用 Kafka Tool 模拟发送 Messages
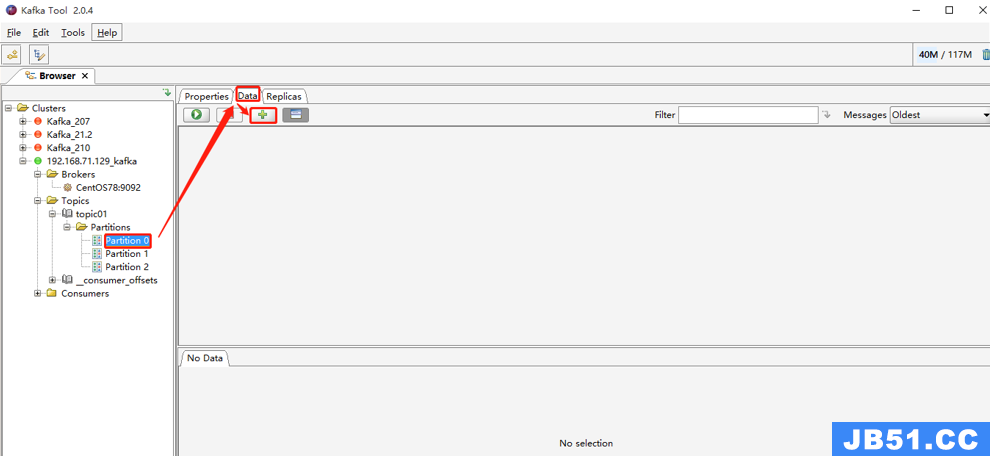
操作步骤如下:
点击“Topics” -> 选择一个 topic(如:topic01) -> 选择分区(如:Partition 0),点击右侧“Data”里的“+”,会弹出“Add Message”页面。
其中,Key 和 Message 均支持两种方式:From file 和 Enter Manually[Text]
From file:就是数据来源于文件,需要上传文件(个人建议上传txt格式文件)
Enter Manually[Text]:手动输入
二者可以混合搭配使用,并且 Key 和 Message 二者必须有值,否则会报错.
效果如下:
场景1:Key 和 Message 均选择手动输入
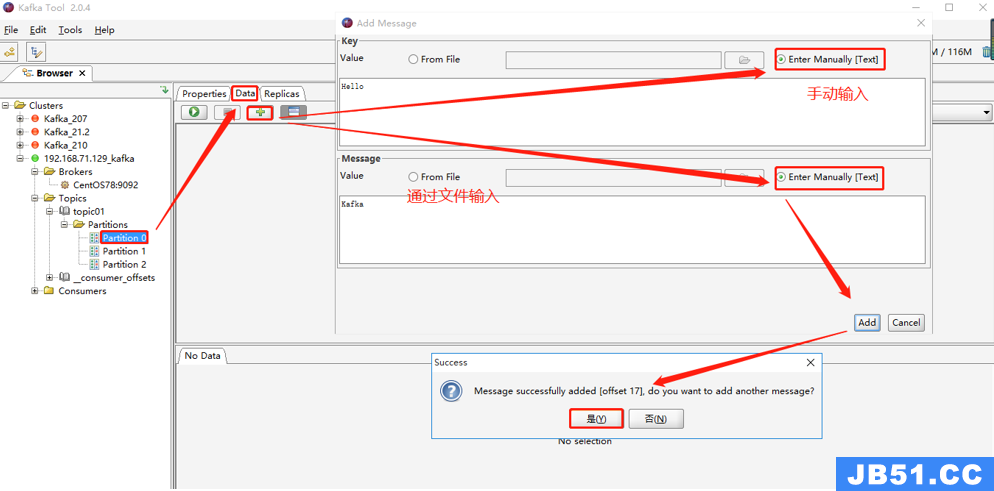
场景2:Key 和 Message 均选择来自文件
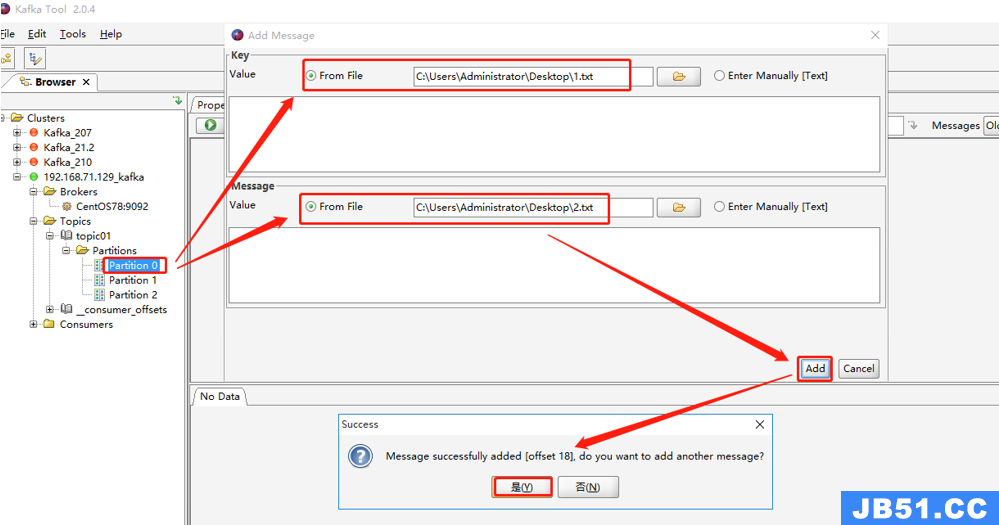
场景3:Key 和 Message 其中一个来自文件,一个来自手动输入
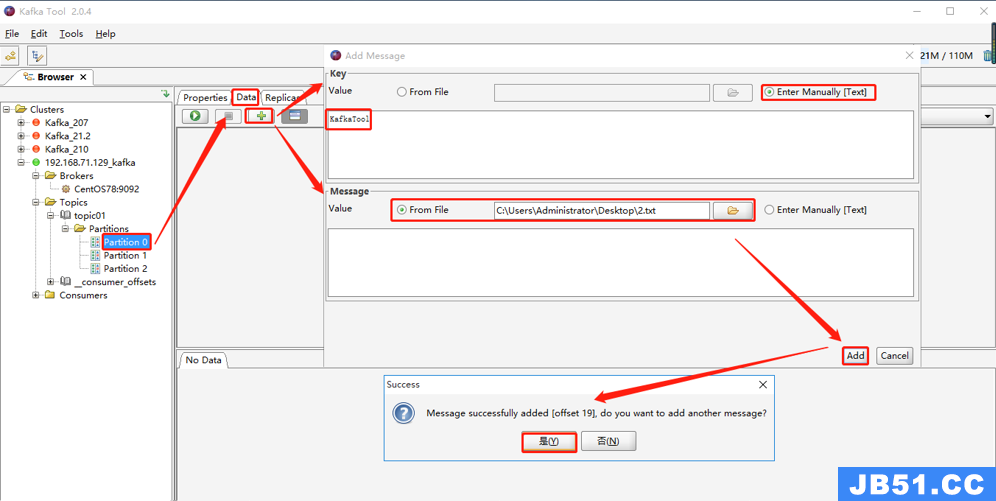
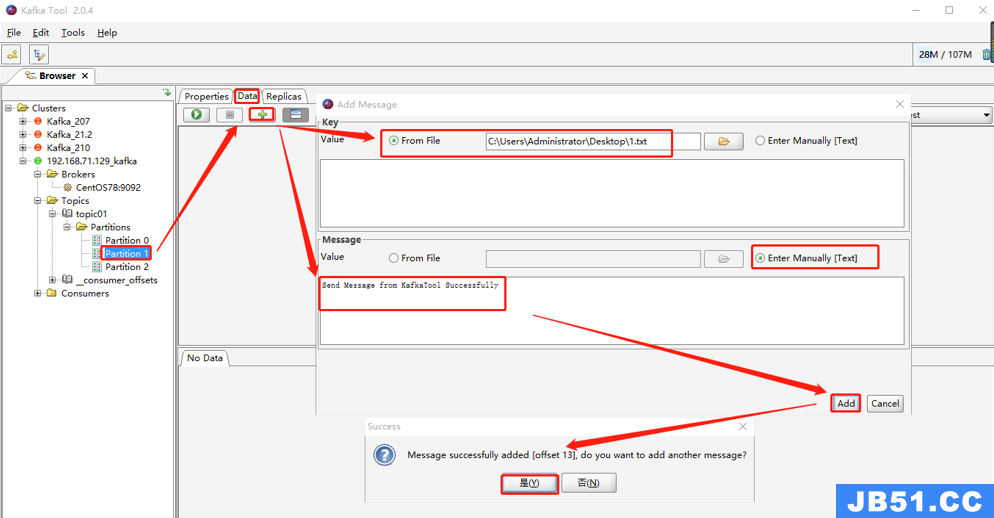
txt文件中内容如下:

消费者消费到的模拟数据
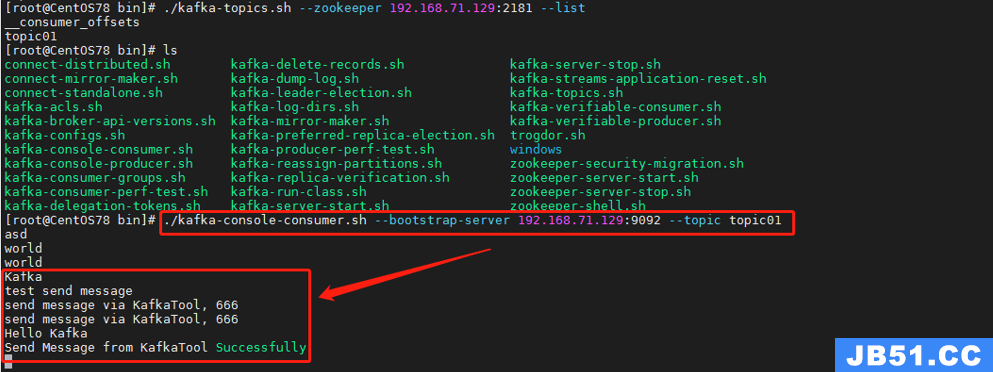
消费命令如下:
./kafka-console-consumer.sh --bootstrap-server 192.168.71.129:9092 --topic topic01
原文地址:https://blog.csdn.net/tian830937/article/details/129831509
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。