
这篇文章将为大家详细讲解有关Kafka如何实现副本同步,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
follower副本同步的过程大致就是向leader发起获取数据请求,leader给出响应并返回数据,然后follower副本更新自己的HW和LEO值,并且follower的请求数据过程中,leader也会更新自己的HW和LE,在这里注意一下,leder副本除了维护自己的HW和LEO值以外,还维护了一份各个follower副本的LEO值,这里我们就暂时叫他RemoteLEO。
再总结一下,follower副本的同步过程无非就是从leader副本获取数据写入log,然后更新HW和LEO的值。
HW、LEO更新机制
假设我们新的kafka集群刚刚建立,没有任何生产者,没有消息,follower此时向leader发起fetch数据的请求,leader发现没有数据会将该请求暂时存在purgatory(用于临时存放暂时无法被处理的请求,但是这些请求有超时设置,如果超时则强制完成)中。Leader和follower的初始状态如下:

此时,假设生产者向kafka某个topic的分区发送了一条消息,leader副本会将自己的LEO值+1,HW值不变,RemoteLEO值不变。状态图如下:
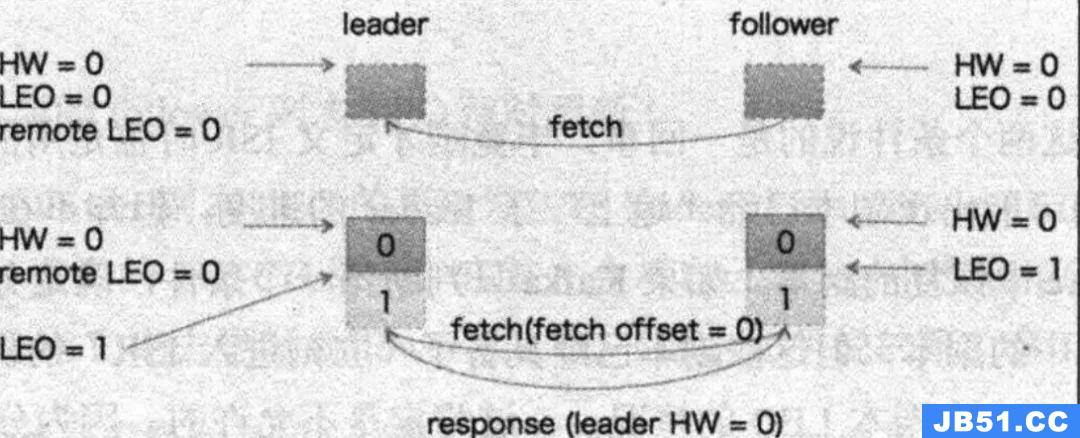
kafka在接受到生产者的消息后,主要经历下述过程(这里假设follower暂时无发出fetch数据的请求):
leader将数据写入底层日志,并更新自己的LEO值
leader会尝试更新自己的HW值,因为此时RemoteLEO值为0,LEO值为1,两者之间取较小的值,所以HW的值依然是0,不进行更新
当写入消息后,假设follower发出了fetch数据请求,因为有新的数据产生,所以leader会将新的数据响应给follower,follower在接收到新的数据以后,会将数据写入底层日志并且更新自己的LEO。状态图如下:

follower从发起fetch数据请求,到响应完成,leader和follower主要会经历下述过程:
follower发起fetch数据的请求,并且在请求中会携带自己自己的fetch offset因为此时follower中没有任何数据,所以fetch offset为0
leader在收到请求后,读取底层的log数据
leader会尝试更新RemoteLEO,因为follower请求中的fetch offset为0,所以不做更新
leader会尝试更新HW,比较LEO和RemoteLEO两者的大小,取较小的值,因此HW的值依然为0,不做更新
leader此时会把数据和HW值响应给follower
follower收到响应以后,会将数据写入底层log日志,并更新其LEO
follower尝试更新其HW值,比较自身的LEO值和响应中的HW,两者取较小的值,因此HW值依然为0,不做更新
以上步骤,一次fetch数据请求已全部完成,leader的HW、LEO、RemoteLEO均没有做出更新,follower将数据写入了底层日志并且更新了LEO。那么关于HW的更新则需要伴随再一次的fetch数据请求更新才能成功。正是因为HW需要两次fetch请求才能更新,因此kafka利用水印进行follower同步会产生数据丢失、数据不一致的问题(这个下一节讲)。下面让我们看一下第二次fetch请求后的结果状态图。
在经历过第二次fetch数据请求后,leader中的RemoteLEO和HW会成功更新为1,follower中的HW也会更新为1。状态图如下:
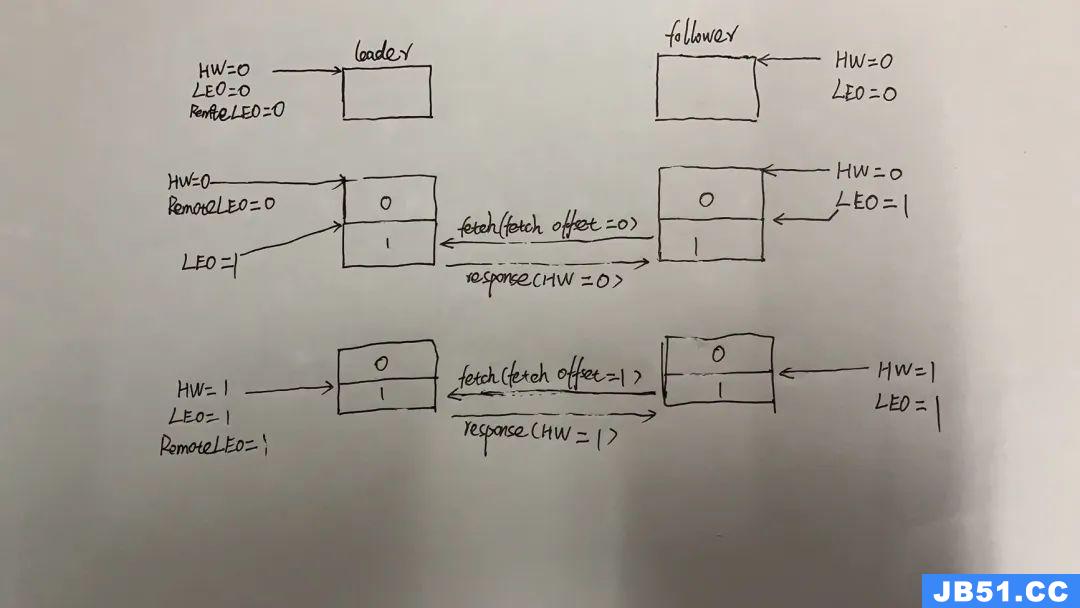
follower第二次发起fetch数据请求,到响应完成,leader和follower经历的过程和第一次没什么区别,只是请求和响应中的数据发生了变化:
follower再次发起fetch数据请求,这一次携带的fetch offset为1而不再是0
leader在收到请求后,读取底层log日志
leader尝试更新RemoteLEO,这一次本地的LEO和fectch offset都为1,因此RemoteLEO成功更新为1
leader尝试更新HW,比较LEO和RemoteLEO,两者的值均为1,因此HW也成功更新为1
leader此时会把数据(实际上这次没有数据,)和HW值响应给follower
follower收到响应后,因为此次没有数据过来,所以不再写底层log日志,LEO也不会发生更新
follower尝试更新HW,比较自身的LEO和响应中HW,因为两者都为1,所以follower的HW成功更新。
LEO、HW更新关键点
Leader LEO:消息写入底层log后便发生更新
Leader RemoteLEO:需要比较本地的RemoteLEO和fetch offset的值,两者取较小
Leader HW:需要比较RemoteLEO和LEO的值,两者取较小
更新顺序:有数据写入底层日志LEO更新,其次会尝试更新RemoteLEO,再尝试更新HW
Follower LEO:取决于response中是否有日志数据
Follower HW:response中的HW和LEO进行比较,两者取较小
关于“Kafka如何实现副本同步”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。