
这篇文章主要会介绍Redis的集群搭建、主从复制、哨兵模式、缓存击穿、缓存穿透、缓存雪崩等
目录
一、Redis集群搭建
要先说明一下,因为宝宝很穷,没办法去购买好几台服务器,只能在一台服务器上搭建一个伪集群,哈哈。
1、基本服务搭建
单机服务的搭建这里就不再重复了,因为在上一篇文章里已经写过了,按照上篇文章的步骤操作即可。要想在一台服务器上运行多个redis服务,只要通过不同的配置文件启动就可以了,单机服务搭建好后(只需搭建一个),多复制几个redis.conf文件,可以命名为redis1.conf,redis2.conf,redis3.conf等,然后修改配置文件中的端口号、服务id,让他们不要相同即可,如果是在同一目录下的话,还需修改日志文件名称、dump.rdb名称。
示例:
port 6379 #主机可不进行修改、从机可以改为6380、6381、6382等
pidfile /var/run/redis_6379.pid #主机可不进行修改、从机改为其他不一致的名称都可
logfile "6379.log" #默认是没有名称的,如果不是在同一目录下,可不进行修改,同目录时也只需不一致就行
dbfilename dump.rdb #同样如果不在同一目录下可以不修改,同目录时也只需不一致就行
修改完后进入安装目录正常通过:redis-server /bug路径/redis/redis1.conf 启动即可。
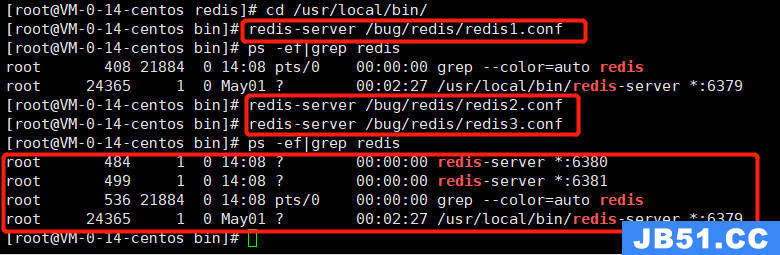
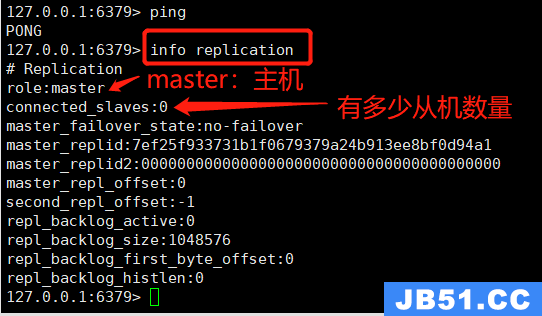
配了3个服务,都已正常启动, 那现在问题来了,怎么知道哪个是主机哪个是从机呢,重点:redis默认所有的都为主机,怎么查看呢,连接客户端后(redis-cli -p 6379端口 -a 密码,没密码的可以去掉-a),通过指令:info replication 查看信息,如图:
如果不是在同一台服务器上的话,其实上面的操作都可以不用进行,要怎么配置从机呢?
2、从机连接主机
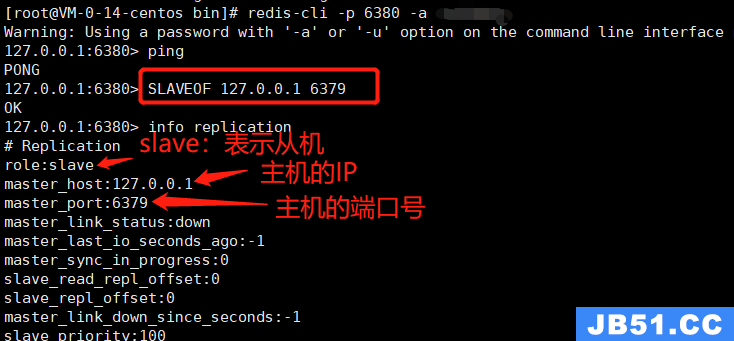
① 临时连接,只需执行命令:SLAVEOF 127.0.0.1 6379 ,如图:
② 永久连接,修改配置文件redis.conf里的配置,如图:(注意:是修改从机的配置文件)

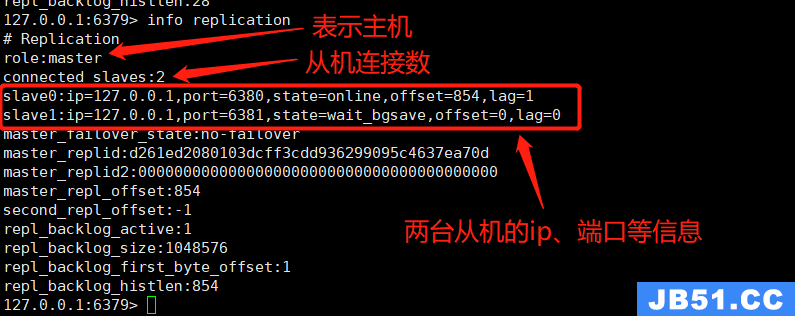
配置好后重启服务即可(不在同一服务器的话要注意防火墙哦),那连接后主机会显示什么信息呢,如图:
其实还有一种连接形式,现在的这种相当于:B->A,C->A。还有一种则为:C->B->A,A为主机,B和C为从机,B连接主机A,C则连接从机B,两种形式都是可行的。
二、Redis的主从复制
1、什么是主从复制
简单的说,在一主多从中,把主机的数据复制到从机上,就叫主从复制,主从复制只存在于集群环境中。
2、特点
① 读写分离:主机只负责写,从机只负责读。
② 单向性:只能由主机复制给从机。
③ 数据的保存、备份:在集群环境中,即使主机挂掉了,数据也可在从机上恢复。
④ 服务的可靠性:通过哨兵模式,主机挂掉后,会选举一台从机立马变成主机,从而保证项目的正常运行。
⑤ 负载均衡:因为是集群,而且又实现了读写分离,所以从机可以方便的实现负载均衡。
3、复制的两种规则
全量复制:复制全部数据,当一台从机断开连接后,再重新接入,这时会执行全量复制。
增量复制:复制新增的数据,主机写入一条数据后,会即时复制给从机,这时只会复制新增的数据,不会复制全部数据。
主从复制就差不多了,其实也没多少东西,只要搭建好集群后,redis都是自己运行的,根本不需要其他的处理,就很人性化。
三、哨兵模式
如果只按照上面的方式搭建redis服务,那么当主机掉线后,维护人员没有第一时间处理,就会导致整个服务将不可用,无法再进行写操作,而且每次都需要人员去重新配置主机,非常的不方便!
所以就延伸出了哨兵模式,当主机掉线后,哨兵通过投票选举,在从机里自动选举出一台成为主机,从而保证服务的可用性。
哨兵服务最常用、也是最基本的3个配置:
sentinel down-after-milliseconds mymaster 1000
#sentinel down-after-milliseconds 名称 每隔1秒校验一次,可以理解为主机的心跳,超过1秒没跳动就表示可能出问题了
sentinel monitor mymaster 127.0.0.1 6379 2
#sentinel monitor 名称 主机ip 端口 确认数量,1秒钟没跳动哨兵就会觉得主机可能出问题了,但是这时不会立即就认为主机掉线了,而是会发送请求给其他哨兵,询问他们是否也认为主机掉线了,如果超过上面的配置2台以上都认为主机掉线了,那么才会确认主机确实掉线了,这时候哨兵就会进行选举,选举出新的主机
sentinel auth-pass mymaster xxxxx
#sentinel auth-pass 名称 主机的密码,如果主机没有密码,可以不用配置
最重要的是上面两个配置,配置完就可以启动哨兵了,当然如果是搭建的伪集群,在一台服务器上,那还得配置端口号。
开始修改配置了,首先在我们的解压目录下找到sentinel.conf文件,这个就是哨兵的配置文件,其他几个常用的配置:
daemonize yes #是否以保护进程的方式运行,一般会改为yes
port 26379 #哨兵的端口号,搭建哨兵集群的注意修改端口号
logfile "" #哨兵的日志文件名称
sentinel monitor mymaster 127.0.0.1 6379 2 #上面单独解释了
sentinel auth-pass mymaster xxxxx #redis主机密码
sentinel down-after-milliseconds mymaster 30000 #上面单独解释了
sentinel parallel-syncs <master-name> <numslaves> #从机有时会不能处理请求,这里配置允许多少的从机不能处理请求,一般会设为1
通过配置文件启动哨兵:redis-sentinel /bug/redis/sentinel.conf(注意要进入你自己的服务路径哦),查看进程:ps -ef|grep redis

哨兵注意事项:
1、搭建哨兵集群的话,哨兵服务一定要是单数。
2、主机掉线后,已经选举出了新的主机,那么原来的主机上线后会变成从机。
就是这么简单,搞定收工!
四、什么是缓存击穿、缓存穿透、缓存雪崩及怎么避免和解决
在讲这些之前,要先了解一下我们正常的一个请求流程:
用户发起查询-->后端接收到请求-->程序查询redis缓存-->存在即可返回数据
-->不存在则查询数据库-->数据库返回数据-->程序存入redis缓存-->返回数据
1、缓存击穿
出现原因:缓存击穿主要出现在“查询redis缓存”流程,高并发环境中,当大量的请求查询同一条数据时,该数据不存在或者刚好过期了,这时大量的请求就会全部去查询数据库,数据库承受不住压力就会导致崩溃。
解决方式:
1、既然问题是redis里数据过期导致的,那么让数据永不过期不就行了,哈哈,当然这样会占用大量的空间,而且也不可能永不过期,对于热点数据可以适量的延长过期时间。
2、采用互斥锁,意思就是一次只允许一个线程去查询,阻塞后面的查询请求,然后当查询出数据后存入redis缓存,让后面的查询请求去查询redis缓存,这样就可以很好的解决缓存击穿问题(注意:这样会对互斥锁要求比较高哦)。
2、缓存穿透
出现原因:缓存穿透主要出现在“查询数据库”流程,当查询请求出现时,大量的参数在redis缓存里查不到数据,数据库里也查不到数据,而请求却一直不停的查询,这时也会导致数据库服务器崩溃。
解决方式:
1、当redis缓存里没有,数据库里也没有时,可以返回一个空字符串存入缓存,这时就不会再去请求数据库,但这种方式不太建议使用,会存在一些其他问题。
2、采用布隆过滤器,过滤掉不符合规则的参数。
3、缓存雪崩
出现原因:缓存雪崩也主要出现在“查询数据库”流程,当redis的大量缓存数据同时过期或者redis服务直接掉线了,而这时又有大量的请求出现,请求就只能去查数据库,这也会导致我们的数据库服务器崩溃。
解决方式:
1、不要把大量的数据设置同时过期,在有可能出现大量请求的时候,要先对数据进行预热,先把数据分时加载进缓存,确保数据不在同时过期。
2、加锁,和我们上面的缓存击穿处理方式一样,虽然这样会降低用户的体验,但至少保证了服务的可用性。
3、增加redis服务器的数量,这样即使有一两台服务器掉线了,也对整体的服务影响不大。
总结
我的五年java开发经验告诉我,如果项目真的到了要用到redis集群的时候,那么就一定会配备一个专门的运维人员,但是在现在的这个环境中,都在要求我们这些可怜的程序员要成为一个全栈工程师,所以即使我们不能对redis精通,但也一定要会用,知道一些基本的概念。
原文地址:https://blog.csdn.net/xiaobug_zs/article/details/124553645
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。