
我们都知道,用户数据一般都是存储在数据库中,而数据库的数据是落地于磁盘的,如果我们读取数据库的数据那是很慢的。一旦,用户访问量上来,就很容易引起数据库崩溃。所以,我们一般会加入一层缓存避免直接访问数据库,而redis就是不错的缓存层。因为redis是内存数据库,所以存放redis中的数据跟存放在内存中的数据差不多。
但是,引入缓存层会引来三大问题:
缓存雪崩、缓存击穿、缓存穿透
这也是我们今天要解决的问题,要知道它们怎么发生的,然后该怎么解决。
缓存雪崩
什么是缓存雪崩
就是当大量缓存数据在同一时间过期(失效)或者redis故障宕机时,这时候有大量的用户请求,而都无法在redis中处理,于是都直接去请求访问数据库,从而数据库的压力剧增,严重的会导致数据库宕机,从而引发一系列的连锁反应,导致整个系统崩溃,这就是缓存雪崩。如下图:
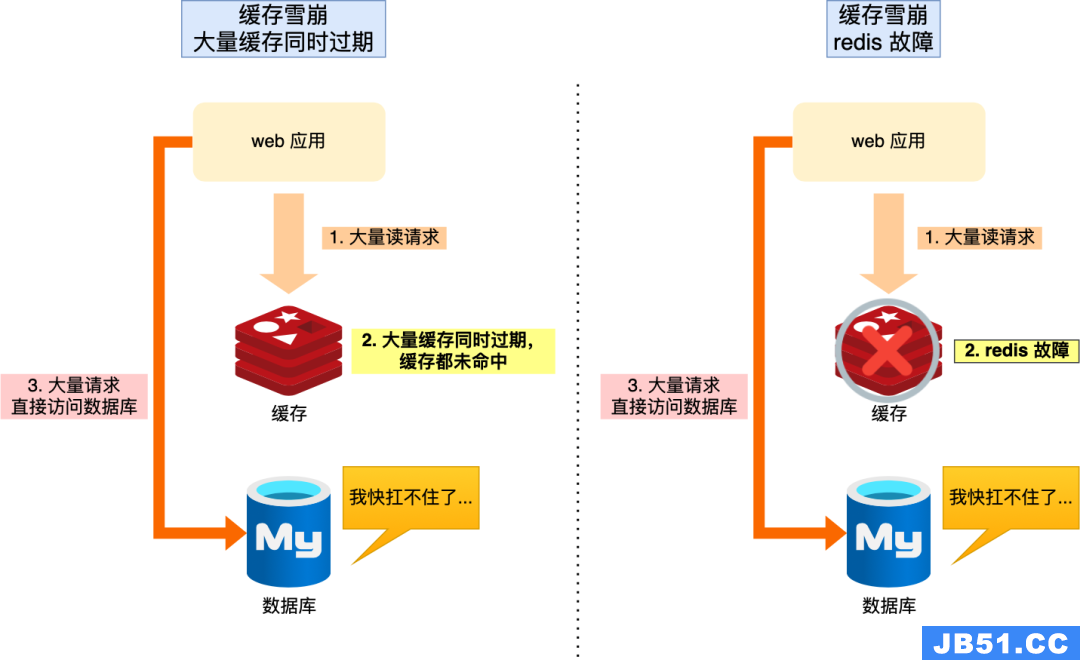
缓存雪崩
从概念和上图可以知道,导致缓存雪崩的原因有:
1. 同一时间大量的缓存数据过期(失效)
2. redis故障宕机
那么如何去解决这个问题呢?我们就从这两个原因入手。
同一时间大量的缓存数据过期(失效)
对于同一时间大量的缓存数据过期引发的缓存雪崩的解决办法如下:
1. 均匀设置过期时间:就是将key的过期时间后面加上一个
随机数(比如随机1-5分钟),让key均匀的失效
2. 互斥锁或者队列:这样保证缓存单线程写,但这种方案可能会影响并发量。当然最好在互斥锁也加入超时时间,防止锁一直不释放,导致堵塞
3. 使用后台程序定时更新数据:热点数据可以考虑不失效,后台异步更新缓存(就是后台定时的检测缓存是否失效而淘汰和更新缓存数据,也可以业务线程通知后台的方式让后台更新缓存),适用于不严格要求缓存一致性的场景
4. 双key策略:主key设置过期时间,备key不设置过期时间,当主key失效时,直接返回备key值(即只有一个请求去更新缓存,在这期间有别的请求到来就使用旧值返回)。更新缓存的时候,同时更新两个key的数据
redis故障宕机
对于redis故障宕机引发的缓存雪崩的解决办法如下:
1. 构建缓存高可用集群:即可以通过主从模式实现
2. 当缓存雪崩发生时,服务熔断、限流、降级等措施保障
服务熔断机制:暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力,保证数据库系统的正常运行,然后等到 Redis 恢复正常后,再允许业务应用访问缓存服务。
请求限流机制:只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
缓存击穿
缓存雪崩是指只大量热点key同时失效的情况,而如果是单个热点数据过期了(失效),此时有大量的请求访问了该热点数据,在缓存无法读取到数据,而直接访问数据库数据库很容易就被高并发的请求冲垮,这就是缓存击穿。如下图:
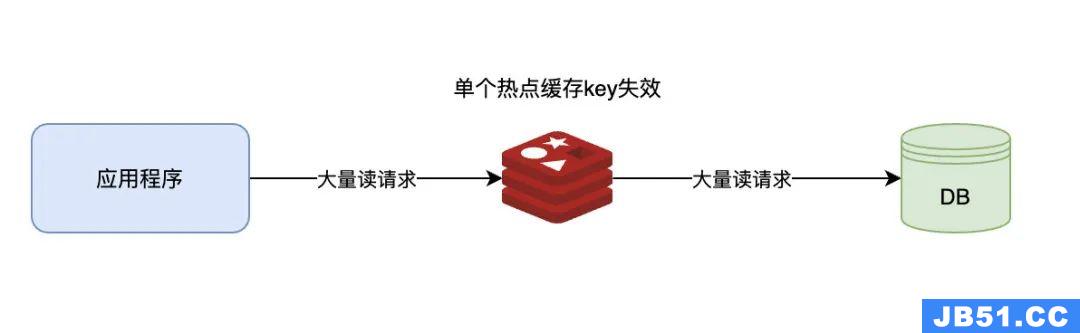
缓存击穿
从定义上看,我们看出缓存雪崩和缓存击穿很相似,只不过缓存击穿是一个热点key失效,而缓存雪崩是大量热点key失效。因此,可以认为缓存击穿是缓存雪崩的一个子集。
缓存击穿的解决方案:
1. 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。单机通过synchronized或lock来处理,分布式环境采用分布式锁
2. 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间。适用于不严格要求缓存一致性的场景
3.”提前“使用互斥锁(Mutex Key):在value内部设置一个比缓存(Redis)过期时间短的过期时间标识,当异步线程发现该值快过期时,马上延长内置的这个时间,并重新从数据库加载数据,设置到缓存中去。
缓存穿透
从上面的介绍我们知道缓存雪崩或击穿,只是数据不在缓存中(失效),但是数据库是有的,只要把数据库的数据加载入缓存即可解决。但是如果数据库也没有怎么办呢?这就是下面要谈论的问题了。
当用户访问的数据,即不在缓存中,也不在数据库中。导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,则不写入缓存。这就导致每次请求都会到底层数据库进行查询,缓存也失去了意义。当高并发或有人利用不存在的Key频繁攻击时,数据库的压力骤增,甚至崩溃,这就是缓存穿透。如下图:
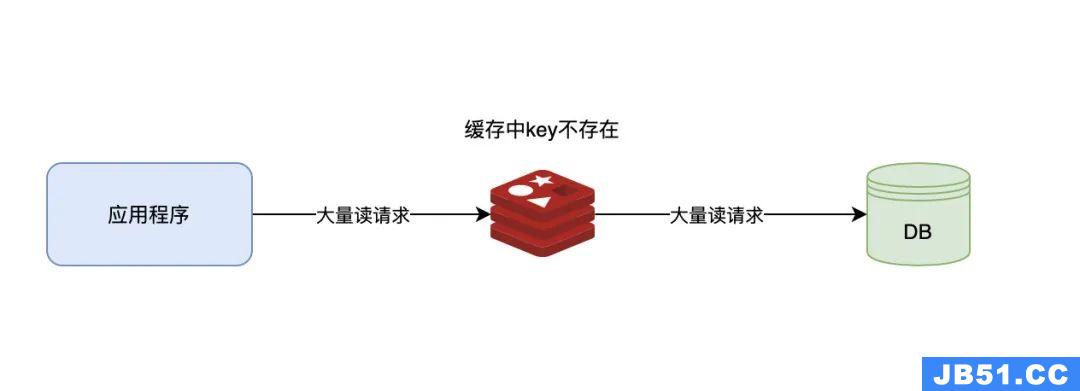
缓存穿透
那么怎么混出现这种情况呢?主要有两个方面:
1. 业务操作上失误:原来数据是存在的,但由于某些原因(误删除、主动清理等)在缓存和数据库层面被删除了,但前端或前置的应用程序依旧保有这些数据
2. 黑客恶意攻击:利用不存在的Key或者恶意尝试导致产生大量不存在的业务数据请求
如果出现上面这个情况,我们如何解决呢?
1. 缓存空值(null)或默认值
2. 业务逻辑前置校验
3. 用户黑名单限制
4. 使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
缓存空值(null)或默认值
当我们在业务中发现缓存击穿情况时,我们可以针对相应的查询数据在缓存中设置一个空值或者默认值,当后续有相对应的业务请求过来时,则可以直接从缓存中取出数据返回给应用端,不再需要访问数据库。但是要注意的是,在缓存中设置这样的空值(默认值)的时候,要为其设置相应的过期时间(不宜过长)。同时也要注意,如果我们操作数据库的时候,写入或者更新到有该key的数据,则一定记得更新缓存数据,防止数据不一致的出现。
业务逻辑前置校验
我们在写业务请求相关的接口时要对数据的合法性进行校验,即检查请求参数是否合理、是否包含非法值、是否恶意请求、请求字段是否存在,这样可以提前阻止非法请求。
用户黑名单限制
当发现异常的时候,我们可以实时监控访问的对象和数据,分析用户行为,针对故意请求、爬虫或攻击者,进行特定用户的限制。
使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在
我们在写数据的时候,使用布隆过滤器进行标记(相当于设置白名单),当业务请求到来的数据,如果在缓存中找不到对应的数据,那么可以先通过查询布隆过滤器判断数据是否在白名单内,如果不存在,就不用通过查询数据库来判断数据是否存在。这样即使发生了缓存穿透,大量的请求也只会查询缓存(redis)和布隆过滤器,而不会去查数据库,从而保证数据库的稳定性。
什么是布隆过滤器?
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
-
第一步,使用 N 个哈希函数分别对数据做哈希计算,得到 N 个哈希值;
-
第二步,将第一步得到的 N 个哈希值对位图数组的长度取模,得到每个哈希值在位图数组的对应位置。
-
第三步,将每个哈希值在位图数组的对应位置的值设置为 1;
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
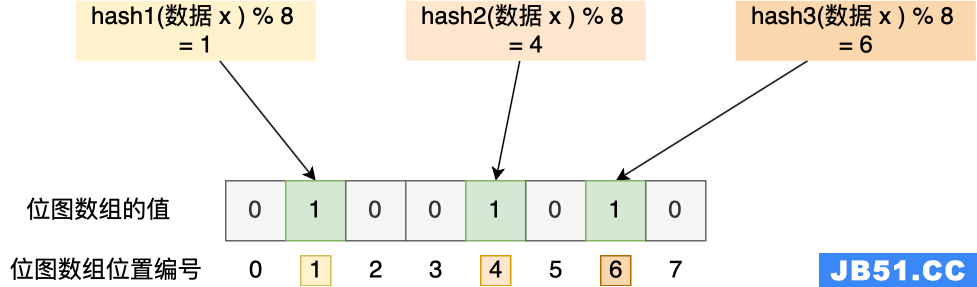
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
当然,可能针对缓存穿透的情况,也有可能是其他的原因引起,可以针对具体情况,采用对应的措施。
总结
本文介绍了在使用缓存时经常会遇到的三种异常情况:缓存穿透、缓存雪崩和缓存击穿。整理如下:

针对不同的缓存异常场景,可选择不同的方案来进行处理。当然,除了上述方案,我们还可以限流、降级、熔断等服务层的措施,也可以考虑数据库层是否可以进行横向扩展,当缓存异常发生时,确保数据库能够抗住流量,不至于让整个系统崩溃。
原文地址:https://blog.csdn.net/sanylove/article/details/127885951
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。