
上节我们获取了广州的房价数据,并存入了MongoDB中
数据展示:
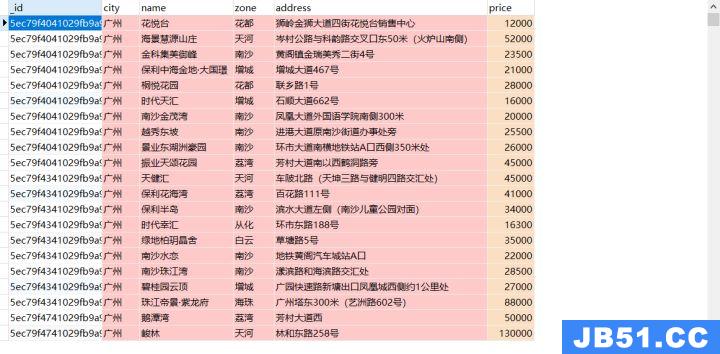
这节我们的目标就是计算出广州最高的房价、最低的房价、平均房价以及每个区的平均房价。
目录:
1、提取数据
2、计算最高的房价、最低的房价、平均房价
3、计算每个区的平均房价
4、数据可视化(和2019年12月的房价数据进行对比)
5、房价涨跌幅度
1、提取数据
从MongoDB中提取的数据是一个游标对象,而每个数据是以字典的形式存储的
需要循环提取数据
def output_mongo(self,city):
"""提取数据"""
results = collection.find({'city': city})
for i in results:
analyze = {}
analyze['zone'] = i.get('zone')
analyze['price'] = i.get('price')
yield analyze
这里指定city为广州,数据只要价格和地区名
2、计算最高的房价、最低的房价、平均房价
将output_mongo返回的数据传入analyze_data
def analyze_data(self,data):
"""
对全城房价数据进行分析,得出平均房价、最高房价、最低房价
"""
price = ([i['price'] for i in data])
a = []
for i in price:
a.append(i)
# 平均值
avg_price = sum(a) / len(a)
print('平均房价是:' + str(avg_price) + '每平方米')
# 最高的价格
max_price = max(a)
print('该城市最高的房价为' + str(max_price) + '每平方米')
# 最低的价格
min_price = min(a)
print('该城市最低的房价为' + str(min_price) + '每平方米')
先将价格数据提取出来,之后计算最大值、最小值、平均值都很容易了
3、计算每个区的平均房价
将output_mongo返回的数据传入analyze_zone
def analyze_zone(self, data):
"""分析同城不同地区的房价"""
a = []
for i in data:
a.append(i)
zone_name = []
house_price = []
for i in a:
zone_name.append(i.get('zone'))
zone_name = set(zone_name) # 对地区名进行去重
for i in zone_name:
price = 0
zone_num = 0 # 地区出项的次数
for j in a:
if j['zone'] == i:
zone_num += 1
price += j['price']
house_price.append(price//zone_num) # 得到平均房价
zone_data_dict = dict(zip(zone_name, house_price)) # 得到地区与价格的字典
z = list(zip(list(zone_data_dict), list(zone_data_dict.values())))
zone_price_list = sorted(z, key=lambda x: (x[1]))
return zone_price_list
analyze_zone方法会将每个地区的房价相加求平均值
4、数据可视化(和2019年12月的房价数据进行对比)
我这里将数据都计算并整理好,房价和地区一一对应
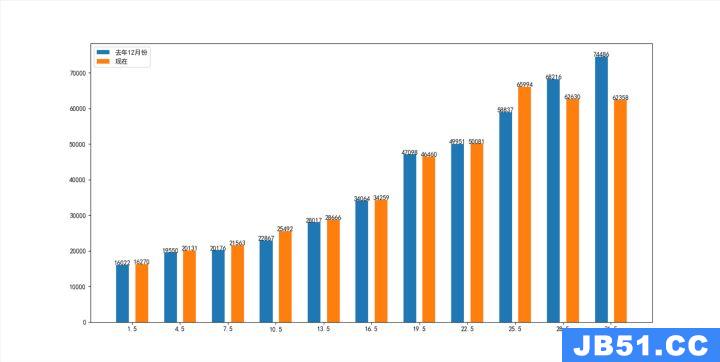
price04 = [16022,19550,20176,22867,28017,34064,47098,49951,58837,68216,74486]
now_price = [16270,20131,21563,25492,28666,34259,46460,50081,65994,62630,62358]
zone = ['从化','花都','增城','南沙','黄埔','番禺','白云','荔湾','海珠','越秀','天河']
怎么对比比较好呢?这里采用柱状图的方式,图例如下:
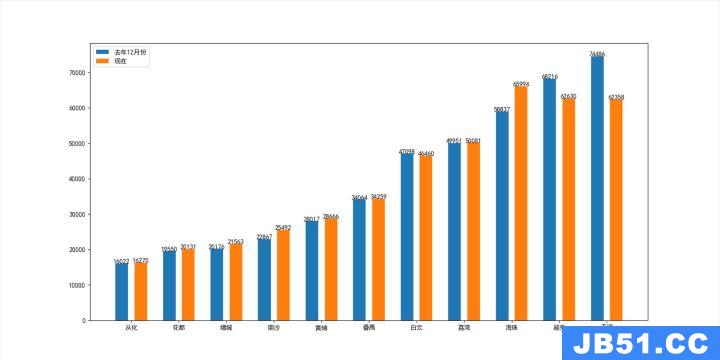
将需要对比的两组数据放在一起,这样就可以直观的看出差距
代码如下:
import numpy as np
import matplotlib.pyplot as plt
price04 = [16022,'天河']
x = np.array([i for i in range(0,33,3)])
x1 = x + 0.9
x2 = x + 2.1
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.bar(x1,price04,label='去年12月份')
plt.bar(x2,now_price,label='现在')
for i in range(len(x)):
plt.text(x1[i],price04[i],ha='center')
plt.text(x2[i],now_price[i],ha='center')
plt.xticks(x + 1.5,zone)
plt.legend()
plt.show()
我们没有直接将地区名作为x轴,而是将一个数组作为了x轴,但是最后x轴显示的还是地区名,这是因为xticks()方法,我们还是先看看xticks()的源码是如何解释的吧
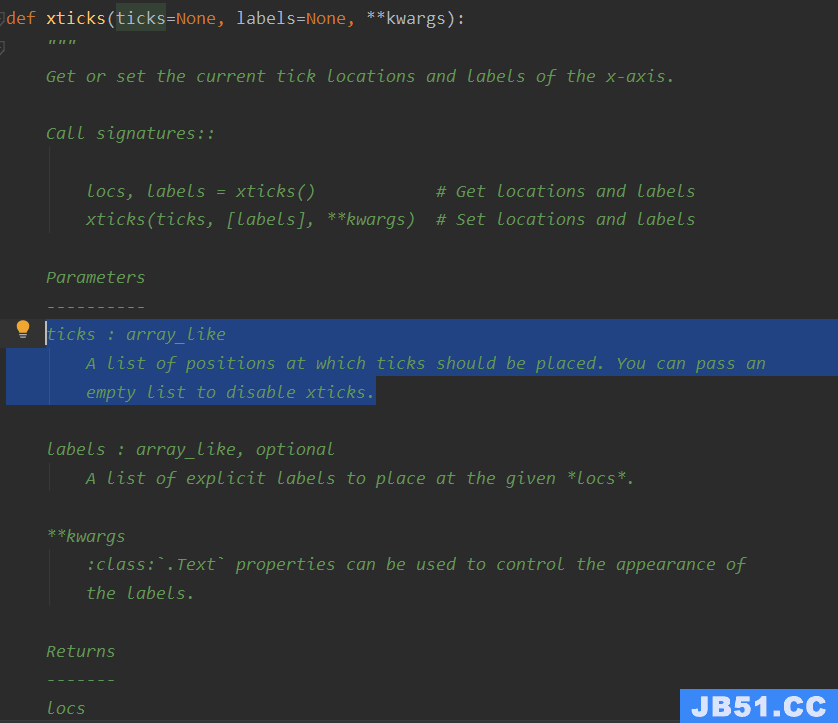
xticks()方法的ticks参数的意思就是,指定刻度放置x轴的标签,labels这个标签可以覆盖bar()方法设置的x轴标签,上图帮助我们理解,我们试试看如果没有添加labels参数会是什么结果吧,
将
plt.xticks(x + 1.5,zone)改为plt.xticks(x + 1.5)
图例:
这次x轴的标签就变为一个个数字了(这其实就是x轴的刻度)
通过图我们就能比较直观的看出广州各个区的平均房价在这次疫情中的变化,可以看出天河区、越秀区的房价下降的是比较明显的,海珠区的房价上涨是比较明显的。
5、房价涨跌幅度(可视化)
上面的图只能比较直观的看出涨跌明不明显,但是我不但想知道谁涨了谁跌了,而且还要知道具体的涨跌幅度是多少,这才更容易帮助我分析。
计算方法:涨跌幅 = (现在的房价-去年房价)/去年房价
代码如下:
price04 = [16022,62358]
percent = []
for i in range(len(price04)):
percent.append(round(((now_price[i] - price04[i])/price04[i]) * 100,3))
print(percent)
运行结果:
[1.548,2.972,6.875,11.479,2.316,0.572,-1.355,0.26,12.164,-8.189,-16.282]
可视化展示:
代码如下:
import numpy as np
import matplotlib.pyplot as plt
price04 = [16022,3))
zone = ['从化','天河']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.bar(zone,percent,color='r',label='涨跌幅度')
for i in range(len(percent)):
if percent[i] < 0:
plt.text(zone[i],percent[i]-1,percent[i],ha='center')
else:
plt.text(zone[i],percent[i]+1,ha='center')
plt.legend()
plt.show()
运行结果:
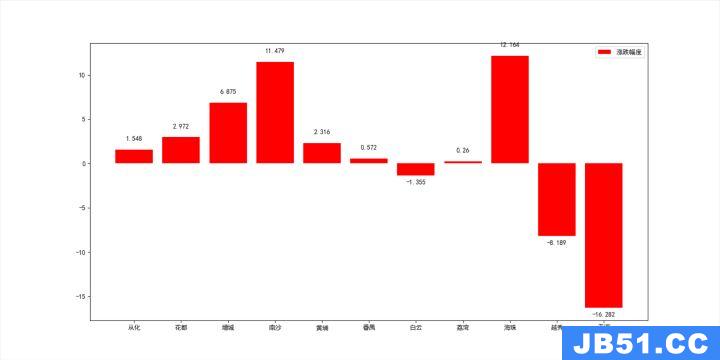
从这幅图中我们可以看出在疫情期间只有白云、越秀、天河三个区的房价有所下降,尤其是天河区下降了16.282%,南沙区和海珠区领涨分别涨了11.479%、12.164%
原文地址:https://blog.csdn.net/weixin_44623587/article/details/126070861
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。