
在当前环境下,通常我们会首选redis缓存来减轻我们数据库访问压力。但是也会遇到以下这种情况:大量用户来访问我们系统,首先会去查询缓存, 如果缓存中没有数据,则去查询数据库,然后更新数据到缓存中,并且如果数据库中的数据发生了改变则需要同步到redis中,同步过程中需要保证 MySQL与redis数据一致性问题,在这个同步过程中出现短暂的数据延迟也是正常现象,但是最终需要保证mysql与缓存中的一致性。
//我们通常使用redis的逻辑
//通常我们是先查询reids
String value = RedisUtils.get(key);
if (!StringUtils.isEmpty(value)){
return value;
}
//从数据库中获取数据
value = getValueForDb(key);
if (!StringUtils.isEmpty(value)){
RedisUtils.set(key,value);
return value;
}1、什么是延迟双删?
延迟双删策略是分布式系统中数据库存储和缓存数据保持一致性的常用策略,但它不是强一致。其实不管哪种方案,都避免不了Redis存在脏数据的问题,只能减轻这个问题,要想彻底解决,得要用到同步锁和对应的业务逻辑层面解决。
2、为什么要进行延迟双删?
一般我们在更新数据库数据时,需要同步redis中缓存的数据 所以我们一般会给出两种方案:
第一种方案:先执行update操作,再执行缓存清除。
第二种方案:先执行缓存清除,再执行update操作。
但是这两种方案在并发请求中容易出现以下问题
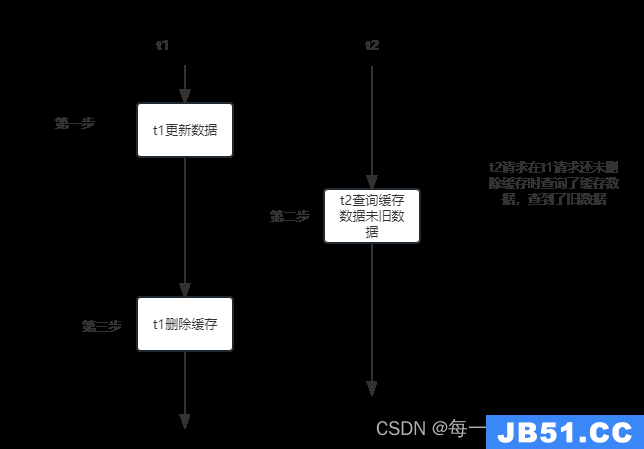
第一种方案弊端:当请求1去执行数据库更新操作之后,还没执行缓存清除时,请求2就进来了查询了缓存,此时缓存中数据还是旧数据,还没来得机删除导致数据出现问题,但是当t1执行缓存删除操作之后,后面的请求查询不到缓存,再到数据中查询,然后更新到缓存中,这种影响是比较小的
t1线程 先更新db;
t2线程查询命中缓存 返回旧的数据;
假设t1线程更新完db,预计5毫秒删除完缓存key 在5毫秒内 其他线程查询缓存结果还是为旧的数据,但是 5毫秒后查询缓存结果是为空,在从新将db最新的结果同步到Redis中。
一个项目中出现延迟是非常正常的,所以该情况发生的延迟对业务的影响其实很小。但是如果发生了,删除缓存失败呢?
1.不断重试----如果是在http协议接口中 会导致接口响应变慢 调用该接口 会发生响应超时 2.或者通过mq异步的形式同步
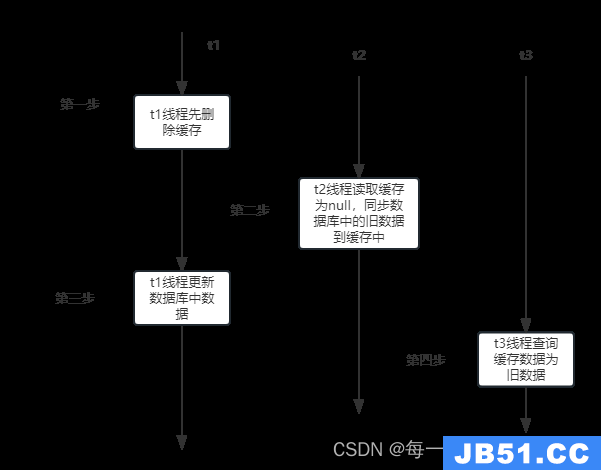
第二种方案弊端:当请求1执行清除缓存后,还未执行数据更新操作的时,请求2进来查询到数据库的旧数据,并写入了redis,这就导致了数据库与redis数据不一致问题。
t1线程先删除缓存;
t2线程读取缓存为null,同步db数据到缓存中;
t1线程更新db中的数据;
t3线程查询缓存中数据是旧数据;
3、对于方案处理都有弊端,那么我们需要使用延迟双删策略
先进行缓存清除,再执行update,最后(延迟N秒)再执行缓存清除。进行两次删除,且中间需要延迟一段时间
RedisUtils.del(key);// 先删除缓存 updateDB(user);// 更新db中的数据 Thread.sleep(N);// 延迟一段时间,在删除该缓存key RedisUtils.del(key);// 先删除缓存4、需要注意的点
上述中(延迟N秒)的时间要大于一次写操作的时间。原因:如果延迟时间小于写入redis的时间,会导致请求1清除了缓存,但是请求2缓存还未写入的尴尬。。。
5、延迟的时间如何确定?
在业务程序运行时,统计业务逻辑执行读数据和写缓存的操作时间,以此为基础来进行估算。因为这个方案会在第一次删除缓存值后,延迟一段时间再次进行删除,所以称为“延迟双删”。
小结
延迟双删策略只是一种同步数据库与缓存的手段,在系统并发量不高的情况下可以使用这种方式解决,如果是并发量高的情况下我们也可以另寻其他解决方案 如:canal
原文地址:https://blog.csdn.net/weixin_38310780/article/details/128780548
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。