

一、什么是栈
栈(stack)是一种先进后出的有序列表,其中的元素只能在线性表的同一端进出,
允许元素插入和删除的一端被称为栈顶(top),固定的另一端被称为栈底(button)。

二、数组简单实现栈
由于栈是只在一端进出,也就是说相比队列实际上只需要有一个栈顶指针top即可:
- 当栈空时top为-1
- 入栈后top+1
- 出栈后top-1
根据思路我们可以用数组实现一个简单的栈:
/**
* @Author:huang
* @Date:2020-06-23 16:51
* @Description:使用数组模拟栈
*/
public class Stack {
private int maxSize;
private int top = -1;
private Object[] arr;
public Stack(int maxSize) {
this.maxSize = maxSize;
this.arr = new Object[maxSize];
}
/**
* 判断栈满
* @return
*/
public boolean isFull() {
return top == maxSize - 1;
}
/**
* 判断栈空
* @return
*/
public boolean isEmpty() {
return top == -1;
}
/**
* 入栈
* @param item
*/
public void push(Object item) {
//判断栈是否已满
if (isFull()) {
throw new RuntimeException("栈已满");
}
//入栈
top = top + 1;
arr[top] = item;
}
/**
* 出栈
*/
public Object pop() {
if (isEmpty()) {
throw new RuntimeException("栈为空!");
}
Object item = arr[top];
top--;
return item;
}
/**
* 遍历栈
*/
public void show() {
if (isEmpty()) {
throw new RuntimeException("栈为空!");
}
//遍历并打印栈中元素
for (int i = top; i >= 0; i--) {
System.out.println("stack" + i + ":" + arr[i]);
}
}
}
三、链表简单模拟栈
数组可以比较简单的实现一个栈,但是缺点的数组随着元素的增加会需要扩容,如果初始化申请的存储空间太大,会造成空间的浪费,如果申请的存储空间太小,后期会经常需要扩充存储空间,为此我们可以用链表实现的栈来避免这个问题。
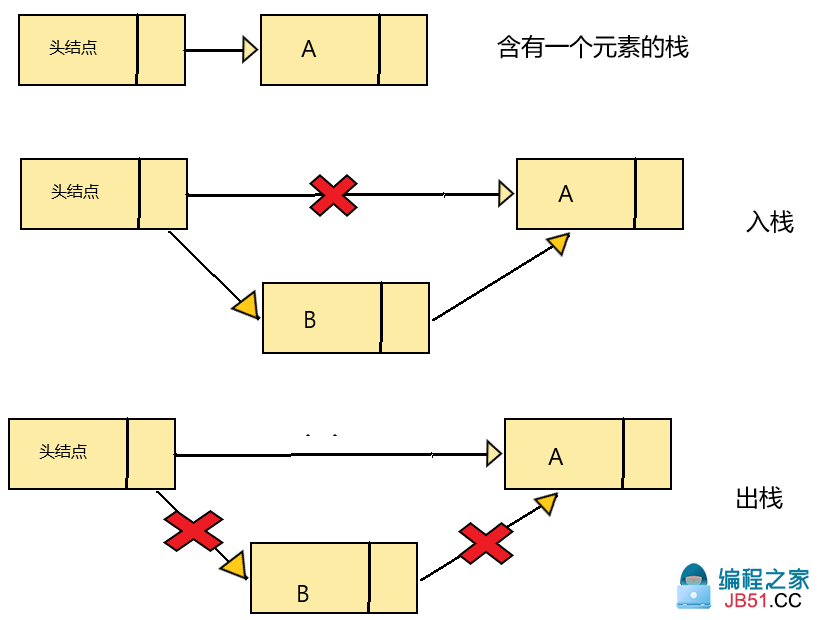
假设现有头结点,一号元素A,我们需要往里面插入或弹出B,,由于要实现“先进后出”的效果:
- 入栈时,B需要插入头结点和A之间,取代A的位置:
-
B.next = head.next,也就是B指向A -
head.next = B.next,也就是让头结点指向B
-
- 出栈时,B需要从头结点和A之间移除:
-
head.next = A,也就是让头结点直接指向A即可
-
按照这个思路,我们先写一个节点类:
/**
* @Author:huang
* @Date:2020-06-20 10:19
* @Description:节点类
*/
public class Node {
//数据
Object data;
//下一个节点
Node next;
public Node(Object data) {
this.data = data;
}
}
然后简单实现一个链表栈:
/**
* @Author:huang
* @Date:2020-06-23 21:30
* @Description:链表栈
*/
public class LinkListStack {
private Node head = new Node("我是头结点");
/**
* 判断是否空栈
* @return
*/
public boolean isEmpty() {
return head.next == null;
}
/**
* 添加节点到链表
* @param item 要插入的元素
*/
public void push(Object item) {
Node node = new Node(item);
Node temp = head;
//如果空栈就直接插入
if (isEmpty()) {
temp.next = node;
return;
}
//不是空栈就插到头结点头面
node.next = temp.next;
temp.next = node;
}
/**
* 将元素出栈
* @return 出栈元素
*/
public Object pop() {
if (isEmpty()) {
throw new RuntimeException("栈为空!");
}
Node node = head.next;
head.next = node.next;
return node.data;
}
/**
* 遍历栈
*/
public void show() {
if (isEmpty()) {
throw new RuntimeException("栈为空!");
}
Node temp = head.next;
while (true) {
if (temp == null) {
break;
}
System.out.println(temp.data);
temp = temp.next;
}
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
