
很抱歉大家,最近经常有朋友私信问我关于这篇信号处理的一些问题,因为最近比较忙所以没能一一回复,给大家说句抱歉,希望那些给我私信的人可以看到。
大家问的问题大多是运行了我笔记上的代码但是结果不太好,可能是因为之前编辑错误所以笔记上的代码出现问题,在此向大家提供源码与音频,有需要的同学可以自取
链接如下:
https://download.csdn.net/download/zsisinterested/87222376
一、前言
之前一直对硬件上的内容比较关注,但是可能是因为硬件方面的东西可能真的是比较杂,而且需要渗透的东西太多了,所以学习进展比较缓慢。
因为也很少有单纯的硬件学习研究,总是会伴随着各种理论需要硬件做支撑,所以还是想要慢慢接触理论学习。但是之前总找不到切入点,不知道从哪里开始,就一直拖着。最近稍微接触了一点信号处理,就用这个当作切入点,开始接触理论学习。
二、信号分析及加噪
信号处理选用了matlab做工具,选了一个最简单的语音信号处理方式,用MATLAB先对原语音信号添加一个正弦噪声,在通过合适的滤波器去除噪声。
原语音信号需要自己录制一段或者找一段简短的音频,然后先对原语音信号进行分析。原语音信号尽量频率成分少一点,因为是初学,所以目的在于对信号处理有一个大概的了解,复杂的可以留待以后深入学习在做研究。
原语音信号做成.mp4或者.wav格式都可以,尽量做单声道的信号方便分析。如果录制时候是双声道,为了方便,就在处理时候选取单声道处理。
clc;clear
[x,Fs]=audioread('E:\test\tests.wav'); %读文件
N=length(x);
X=fft(x,N); %做傅里叶变换
k=0:N-1;
D=Fs/N;%计算频率分辨率
stem(k*D,abs(X),'Marker','none');
axis([0,4000,150])
用傅里叶变换可以看一下语音信号的频谱,由于人声的频率比较低,所以频率大多都集中在低频段,得到这个信息就得考虑一下需要如果有噪声的话,需要用什么样的滤波器。
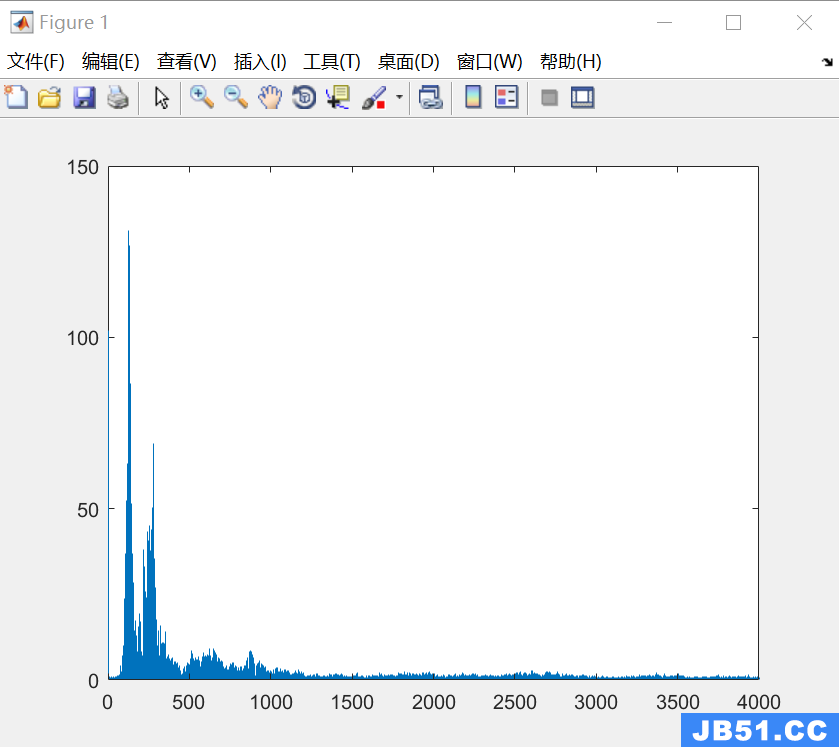
下面对这个语音信号加上噪音,噪音采用正弦波 0.01* sin(2* pi* f) 函数,频率为1800HZ,加上噪声以后再对信号频谱观察
f=1800;
noise=0.01*sin(2*pi*f*k/Fs);
noise=noise';
xa=x+noise;
Xa=fft(xa,N);
stem(k*D,abs(Xa),'Marker','none');
axis([0,4000,0,150])
对信号进行分析,得到频谱:

可以很明显的看到在1800HZ左右出现一个信号幅度,这个就是我们添加的噪音。但是真实的信号处理应该的有用信号的频带比较宽,而噪声的频带也会和有用信号更加的接近,或者说更复杂。
三、滤波去噪
对带有噪声的信号进行处理,一般选用合适的滤波器对信号进行过滤,根据频率滤除噪声。上面可以看到有用信号大部分都在1500HZ频段以下,而噪声在1800,所以就可以选用带阻滤波器对信号进行处理。
低通滤波器可以只过滤掉1800HZ的信号,留下其他信号。
先设计一个巴特沃斯带阻滤波器
Fs=8000; %采样频率
fp1=1500;fp2=2100;
fs1=1750;fs2=1850;
wp1=fp1/Fs*2*pi; wp2=fp2/Fs*2*pi; %通带截止频率
wp=[wp1,wp2];
ws1=fs1/Fs*2*pi; ws2=fs2/Fs*2*pi; %阻带截止频率
ws=[ws1,ws2];
Rp=1;As=30;
[n,wc]=buttord(wp/pi,ws/pi,Rp,As)
[b,a]=butter(n,wc,'stop') %求数字带阻滤波器系数
[H,w]=freqz(b,a);
dbH=20*log10(abs(H)/max(abs(H)));
plot(w/2/pi*Fs,dbH,'r');
axis([0,-40,2]);
整个程序可以画出来滤波器的样子,但实际用到的时候,只需要用到里面的b、a参数,也就是滤波器系统函数的系数,只需要用filter( )函数设定滤波器系数就可以了。
可以看到滤波器的样子:
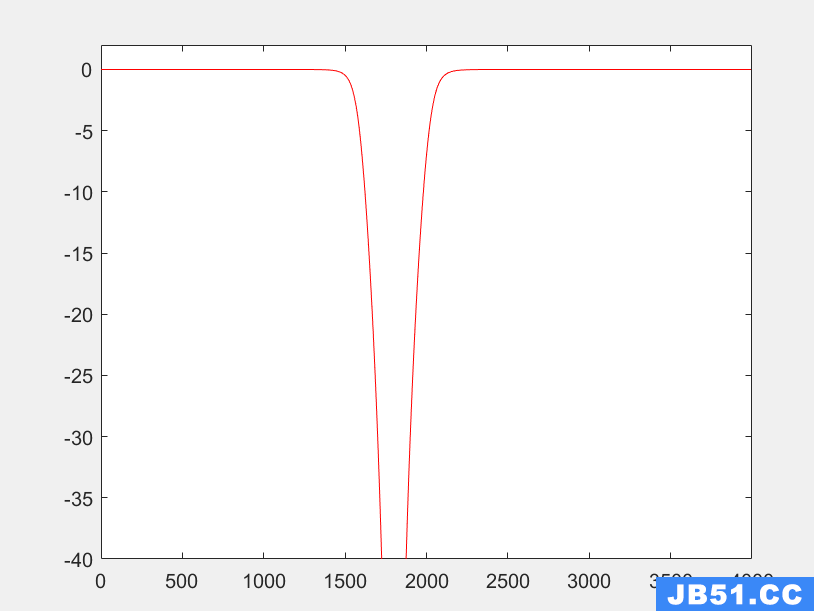
使用该滤波器对信号进行滤波,xa为叠加过噪声的信号,进行滤波以后,可以在通过傅里叶变换观察一下频谱
y=filter(b,a,xa);
Y=fft(y,abs(Y),150])
频谱如下:
可以明显看到1800HZ的频率被抑制
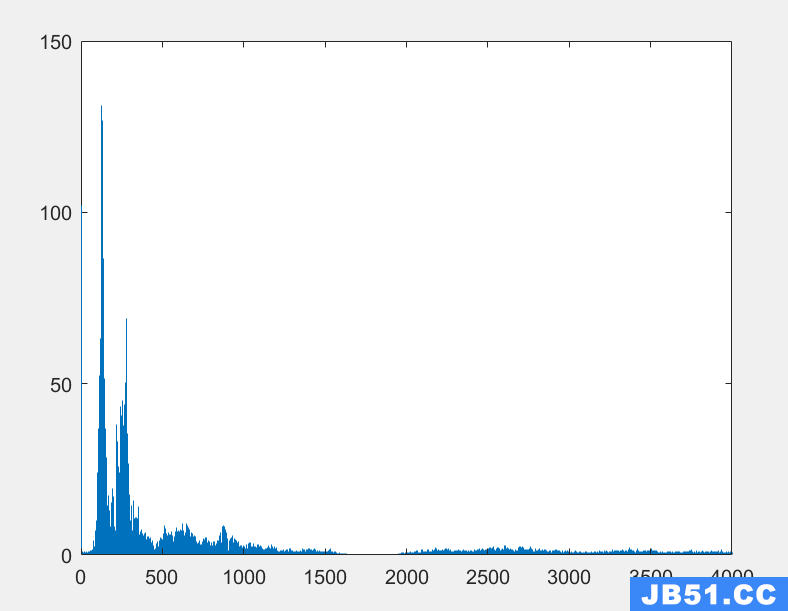
最后,通过对比频谱图观察一下整个滤波过程:

四、总结
很久没有写过博客了,之前总想着切入信号处理方面或者其他理论方面,结果总是找不到切入点,硬件方面因为太复杂进度又比较慢,所以这么长时间几乎没什么进展。只是趁着最近学习数字信号处理正好找到一个切入点,以后可能也会多多的注意这个方面。当然,硬件学习也会一直持续下去。
【注】 个人学习笔记,请不吝赐教!
原文地址:https://blog.csdn.net/zsisinterested" target="_blank" rel="noopener" title="肆意..">肆意..</a> <img class="article-time-img article-heard-img" src="https://csdnimg.cn/release/blogv2/d
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。