


文章目录
1、前言
现实生活中,我们听到的声音都是时间连续的,我们称为这种信号叫模拟信号。模拟信号需要进行数字化以后才能在计算机中使用。
目前我们在计算机上进行音频播放都需要依赖于音频文件。那么音频文件如何生成的呢?
音频文件的生成过程是将声音信息采样、量化和编码产生的数字信号的过程,我们人耳所能听到的声音频率范围为(20Hz~20KHz),因此音频文件格式的最大带宽是20KHZ。
根据奈奎斯特的理论,音频文件的采样率一般在40~50KHZ之间。
奈奎斯特采样定律,又称香农采样定律,即:为了不失真地恢复模拟信号,采样频率应该大于等于模拟信号频谱中最高频率的2倍。
2、概念
声音的本质是一种能量波,由振动而产生的能量波,通过传输介质传输出去。
声音有三个属性:
- 音调:声音频率的高低,表示人的听觉分辨一个声音的调子高低的程度。音调主要由声音的频率决定,同时也与声音强度有关。
- 音量:由“振幅”(amplitude)和人离声源的距离决定,振幅越大响度越大。
- 音色:又称声音的品质,波形决定了声音的音色。
波长是决定音调高低;振幅是决定音量高低;波纹是决定音色。
3、 PCM介绍
PCM(Pulse Code Modulation),即脉冲编码调制技术。
由于我们人耳听到的声音均为模拟信号,那么我们如何将听到的信息存储起来呢?这就涉及到了PCM技术。
PCM技术就是把声音从模拟信号转化为数字信号的技术,即对声音进行采样、量化的过程,经过PCM处理后的数据,是最原始的音频数据,即未对音频数据进行任何的编码和压缩处理。
4、 PCM原理
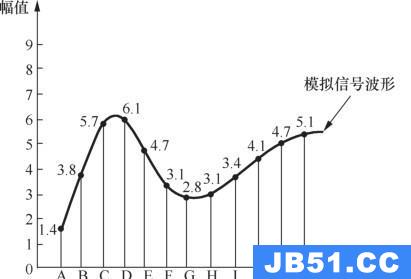
脉冲编码调制就是把一个时间连续,取值连续的模拟信号变换成时间离散,取值离散的数字信号后在信道中传输。脉冲编码调制就是对模拟信号先抽样,再对样值幅度量化,编码的过程。
简化来说:PCM脉冲编码调制,以一个固定的频率对模拟信号进行采样,并将采样的信号按照一定精度进行量化,最终量化后的值被输出,记录到存储介质中。
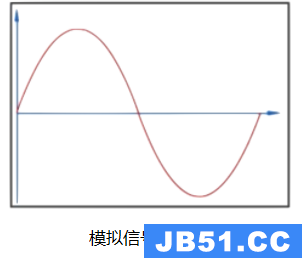
如下图所示:
- 原始模拟音频数据如下:
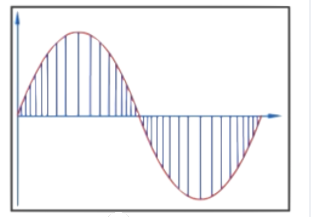
- 按照固定频率进行采样,得到:
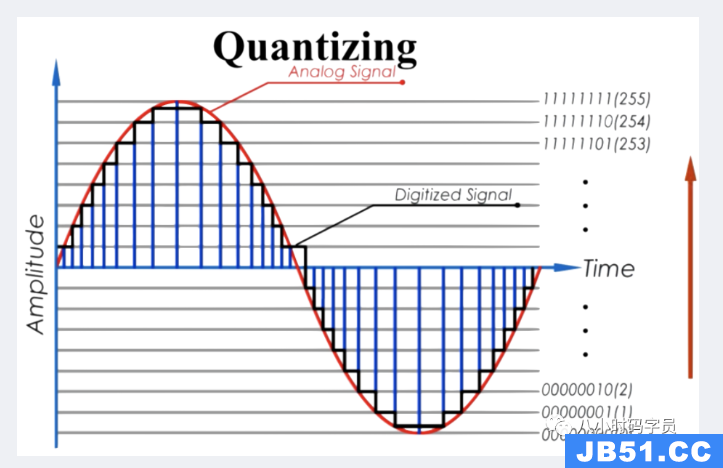
- 最后,对采样后的数据选择合适精度进行量化:
5、PCM相关概念
5.1 采样频率
采样频率:单位时间内对模拟信号的采样次数,它用赫兹(Hz)来表示。采样频率越高,声音的还原就越真实越自然,当然数据量就越大。采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级。
Tip:
5kHz的采样率仅能达到人们讲话的声音质量。
11kHz的采样率是播放小段声音的最低标准,是CD音质的四分之一。
22kHz采样率的声音可以达到CD音质的一半,目前大多数网站都选用这样的采样率。
44kHz的采样率是标准的CD音质,可以达到很好的听觉效果。
48KHz:miniDV、数字电视、DVD、电影和专业音频。
5.2 采样位数
采样位数(Sample Bits):又称为采样精度,量化级,也相当于每个采样点所能被表示的数据范围。
采样位数通常有8bits或16bits两种,采样位数越大,所能记录声音的变化度就越细腻,相应的数据量就越大。
8bits为低品质,16bits为高品质,16bits最为常见。
5.3 声道数
声道数(Channels):又称为通道数,指的是:能支持不同发声的音响个数,它是衡量音响设备的重要指标之一。
Tip:
- 单声道的声道数为1个声道;
- 双声道的声道数为2个声道;
- 立体声道的声道数默认为2个声道;
- 立体声道(4声道)的声道数为4个声道。
5.4 音频数据大小计算
知道上面三个概念,我们就能够计算出来一个原始的音频文件所占用空间大小了。
空间大小
(
B
y
t
e
)
=
采样频率
(
h
z
)
∗
时长
(
s
)
∗
采样位数
(
b
i
t
)
∗
声道数
/
8
空间大小(Byte)=采样频率(hz) * 时长(s) * 采样位数(bit)*声道数/8
空间大小(Byte)=采样频率(hz)∗时长(s)∗采样位数(bit)∗声道数/8
5.5 量化
量化: 量化就是通过四舍五入的方法将采样后的模拟信号转换成一种数字信号的过程。
对于采样来说,就是在时间轴上对信号数字化;
对于量化来说,就是在幅度轴上对信号数字化
通过采样时测的的模拟电压值,要进行分级量化,按整个电压变化的最大幅度划分成几个区段,把落在某区段的采样到的样品值归成一类,并给出相应的量化值。
5.6 其他参数相关
-
帧(Frame):一个声音的基本数据单元,其长度为采样位数和通道数的乘积。
-
周期(Period Size):音频设备一次处理所需要的帧数,对于音频设备的数据访问以及音频数据的存储,都是以此为单位。硬件缓冲传输单位,即完成这么多采样帧的传输,就会回馈一个中断。
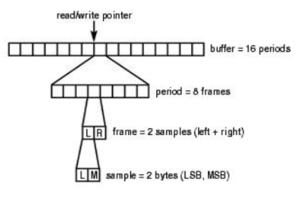
-
Buffer Bytes: 一个应用
Buffer有多少个字节,DMA缓冲区大小。
因为Buffer Size由应用设置,其可大可小,若其太大,则传输的延时太大,所以对此进行分片,提出Period的概念。overrun,录制时,数据都满了,应用来不及取走;underrun,需要数据来播放,应用来不及写入数据
-
Sign :表示样本数据是否是有符号位
-
Byte Ordering:字节序,表明数据是小端(little-endian)存储还是大端(big-endian)存储,通常均为
little-endian。 -
nteger Or Floating Point :整形或者浮点型,大多数格式的PCM样本数据使用整形表示。
-
**交错模式:**数字音频信号存储的方式。数据以连续帧的方式存放,即首先记录第一帧的左声道样本和右声道样本,再开始第2帧的记录…
-
非交错模式: 首先记录的是一个周期内所有帧的左声道样本,再记录所有右声道样本。
以FFmpeg中常见的PCM数据格式s16le为例:它描述的是有符号16位小端PCM数据。
s表示有符号,16表示位深,le表示小端存储。
6、PCM数据流
对于PCM数据都是一些文本化的描述,那么一段PCM格式的数据流怎么表示的呢?
以8-bit有符号为例,长得像这样:
+---------+-----------+-----------+----
binary | 0010 0000 | 1010 0000 | ...
decimal | 32 | -96 | ...
+---------+-----------+-----------+----
每个分割符"|"分割字节。因为是 8-bit 有符号表示的采样数据,所以采样的范围为-128~128。
OK,对于PCM数据流的存储而言,上面仅仅只是单声道。对于多声道的PCM数据而言,通常会交错排列,就像这样:
+---------+-----------+-----------+-----------+-----------+----
FL | FR | FL | FR | FL |
+---------+-----------+-----------+-----------+-----------+----
对于8-bit有符号的PCM数据而言,上图表示第一个字节存放第一个左声道数据(FL),第二个字节放第一个右声道数据(FR),第三个字节放第二个左声道数据(FL)…
7、编码
一个完整的音频,经过采样和量化后的信号,需要将它转化为数字编码脉冲,这一过程称为编码。
编码简单来说,就是按一定格式记录采样和量化后的数字数据。
PCM技术仅仅包含采样和量化,并不包含编码部分,这里仅简单介绍。
7.1 音频编码协议ACC
AAC(Advanced Audio Coding) 高级音频编码,是一种声音数据的文件压缩格式。AAC分为ADIF和ADTS两种文件格式。
- ADIF(Audio Data Interchange Format): 音频数据交换格式。这种格式的特征是只有音频数据最前面具有头字节,音频数据流中间没有头字节。因此它的解码只能在头字节处开始进行。故这种格式常用在磁盘文件中。
-
ADTS(Audio Data Transport Stream): 音频数据传输流。这种格式的特征是它每一单元音频数据都有一个
header字节,解码可以在这个流中任何位置开始。
7.2 压缩
PCM数据是最原始的音频数据,完全无损,所以PCM数据虽然音质优秀但体积庞大,为了解决这个问题先后诞生了一系列的音频格式,这些音频格式运用不同的方法对音频数据进行压缩,其中有无损压缩和有损压缩两种。
-
无损压缩:将数据压缩之后,通过解码还能还原成与原始数据一模一样的数据为无损压缩。
- ALAC、APE、FLAC
-
有损压缩:消除冗余信息,如人耳能听到的声音为20Hz - 20000Hz 以内,所以可以将此范围外的声音去除掉。
- MP3、AAC、OGG、WMA
7.3 其他概念
- 码率:(也成位速、比特率) 是指在一个数据流中每秒钟能通过的信息量,代表了压缩质量。
比如MP3常用码率有128kbit/s、160kbit/s、320kbit/s等等,越高代表着声音音质越好。
MP3中的数据有ID3和音频数据组成,ID3用于存储歌名、演唱者、专辑、音轨等我们可以常见的信息。
码率 = 采样率 ∗ 采样位数 ∗ 声道数 码率 = 采样率 * 采样位数 * 声道数 码率=采样率∗采样位数∗声道数
例如:
如果是CD音质,采样率44.1KHz,采样位数16bit,立体声(双声道), 码率 = 44.1 * 1000 * 16 * 2 = 1411200bps = 176400Bps,那么录制一分钟的音乐, 大概176400 * 1 * 60 / 1024 / 1024 =10.09MB。
- 音频帧: 音频数据是流式的,本身没有明确的一帧帧的概念,在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取2.5ms~60ms为单位的数据量为一帧音频。

8、参考文章
[1]:https://blog.csdn.net/weixin_41910694/article/details/107644742
[2]:https://blog.csdn.net/qq_22310551/article/details/123905051

原文地址:https://blog.csdn.net/dong__ge" target="_blank" rel="noopener" title="卍一十二画卍">卍一十二画卍</a> <img class="article-time-img article-heard-img" src="https://csdnimg.cn/release/blogv2/dis
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。