
zalenium 应用
zalenium是一个Selenium Grid扩展,用Docker容器动态扩展你的本地网格。它使用docker-selenium在本地运行Firefox和Chrome中的测试,如果需要不同的浏览器,你的测试可以重定向到云测试提供商(Sauce Labs,BrowserStack,TestingBot)。 Zalenium也可以在Kubernetes中使用。
繁杂的问题:
- 有一个稳定的网格来运行Selenium的UI测试
- 随着时间的推移保持它(跟上新的浏览器,Selenium和驱动程序版本)
- 提供涵盖所有浏览器和平台的功能
这就是为什么开发zalenium的原因,在需求中创建了docker-selenium节点。在Firefox和Chrome中进行的UI测试将运行得更快,因为它们在本地网格上运行,在从头开始创建并在测试完成后处理的节点上运行。
如果需要docker-selenium无法实现的功能,测试会重定向到云测试提供程序(Sauce Labs,BrowserStack,TestingBot)。
Zalenium的主要目标是:允许任何人拥有一次性和灵活的Selenium Grid基础设施。
zalenium的由来
由Zalando和Selenium两个单词组成。如前所述,这个项目的目的是提供一个简单的方法来创建一个Grid,并服务于Selenium社区。不过,这不是一个正式的Selenium项目。
注:Zalando只是一个电商平台。Zalenium由该平台的研发团队开发与维护。
安装
如果你从未安装和使用过Docker ,请参考 Docker教程
1、安装Docker Engin,版本 > = 1.11.1(可能适用于早期版本,尚未测试)。
2、docker daemon 正在运行(例如,docker info可以正常工作)。
3、拉取 docker-selenium镜像。
$ sudo docker pull elgalu/selenium注:这里拉取的是非官方的docker-selenium镜像。
4、拉取zalenium镜像。
$ sudo docker pull dosel/zalenium速度太慢,可以使用国内镜像:
https://www.docker-cn.com/registry-mirror
查看镜像:
$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
elgalu/selenium latest d39de56e57b 3 days ago 1.GB
dosel/zalenium latest e5a39a962b2c 8 days ago 46MB
运行
Zalenium使用docker来按需扩展,因此我们需要为docker.sock提供完全的访问权限,这就是所谓的“Docker alongside docker”。
docker run --rm -ti --name zalenium -p 4444:4444 \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /tmp/videos:/home/seluser/videos \
--privileged dosel/zalenium start--privileged 为可选项,建议运行zalenium的privileged参数,通过Haveged增加熵(entropy)水平节点注册过程的速度。因为它可以提高性能。
准备测试脚本
grid_demo.py
from selenium import webdriver
from time import sleep
driver = webdriver.Remote(
command_executor='http://127.0.0.1:4444/wd/hub',desired_capabilities={'browserName': 'chrome'})
driver.get('https://www.baidu.com')
driver.find_element_by_id("kw").send_keys("docker selenium")
driver.find_element_by_id("su").click()
sleep(1)
driver.quit()现在可以运行测试了,通过 http://localhost:4444/wd/hub 主节点。
$ python3 grid_demo.py
附加属性
相比于官方的docker-selenium,zalenium最直观的感受的就在此处。
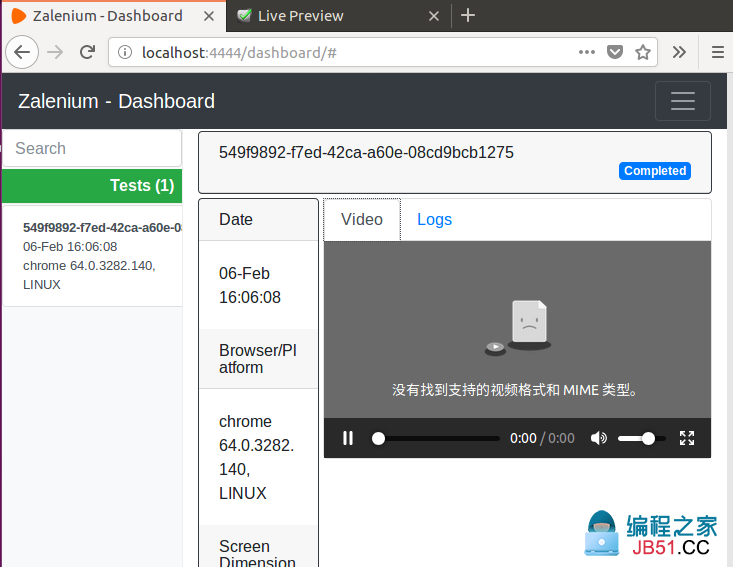
通过浏览器后台执行Selenium总有一种不安全的感觉,zalenium可以将脚本的执行录制成视频,供你回放观看。不过,我这里提示:“没有找到支持的视频格式和MIME类型”也许是因为我的Ubuntu没有安装视频播放器。好在还有Logs可以查看。
视频录制,默认在/tmp/videos文件夹可以找到保存的视频。
- 运行测试的实时预览: http://localhost:4444/grid/admin/live(通过浏览器打开)
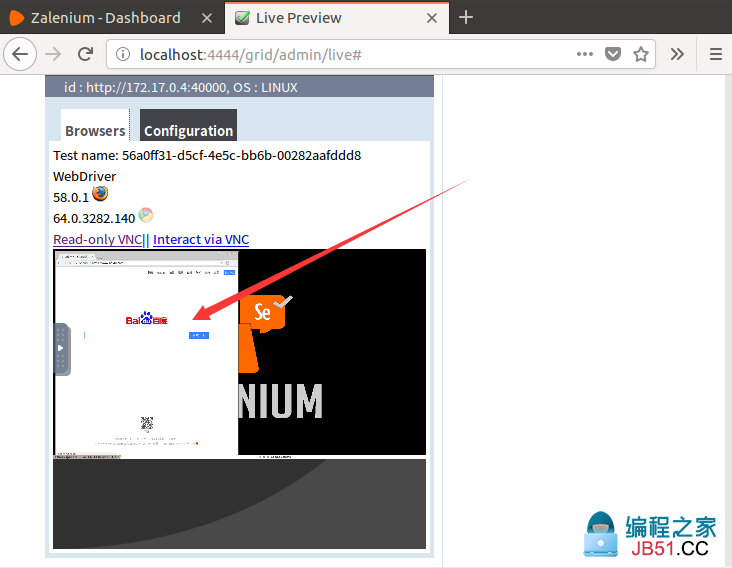
当运行测试脚本的过程中,可以通过该页面观看脚本的执行过程,这功能还是666的。
更多用法:
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。