


目录
前言
提示:爬虫本身并不违法,所有爬虫都应遵守Robots协议,虽然Robots协议并不是强制性要求,但由此可能引发法律纠纷等问题。如非必要,我们在使用爬虫过程中,也应该尽量避免大量,快速反复请求网站,造成网站资源占用,甚至造成网站服务器的宕机,请文明使用爬虫;需要了解更多Robots协议详情请参考:Robots协议想要查看网站Robots协议,可以在网站域名后添加/robots.txt;例如CSDN的Robots协议就是:https://www.csdn.net/robots.txt
一、Selenium简介
二、浏览器驱动
1.浏览器驱动参考
| 浏览器 | 支持的操作系统 | 维护者 | 下载 | 问题追溯 |
|---|---|---|---|---|
| Chromium/Chrome | Windows/macOS/Linux | 下载 | Issues | |
| Firefox | Windows/macOS/Linux | Mozilla | 下载 | Issues |
| Edge | Windows/macOS | Microsoft | 下载 | Issues |
| Internet Windows | Windows/macOS/Linux | Selenium Project | 下载 | Issues |
| Safari | macOS | High Sierra and newer Apple | 内置 | Issues |
注意: Opera驱动程序不支持w3c语法, 因此我们建议使用chromedriver来处理Opera. 请参见Opera浏览器的代码示例
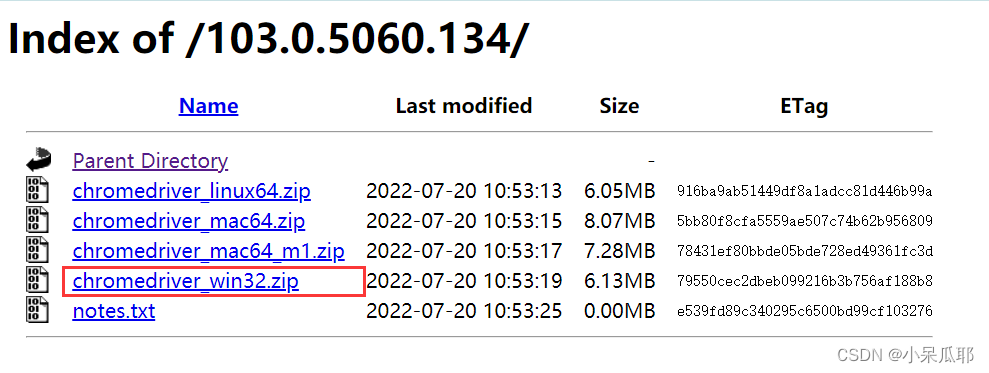
下载版本以自己安装的浏览器版本为主,我这里以 Windows10 Chrome 103.0.5060.134为例
2.Windows下载Chrome驱动
三、代码实现
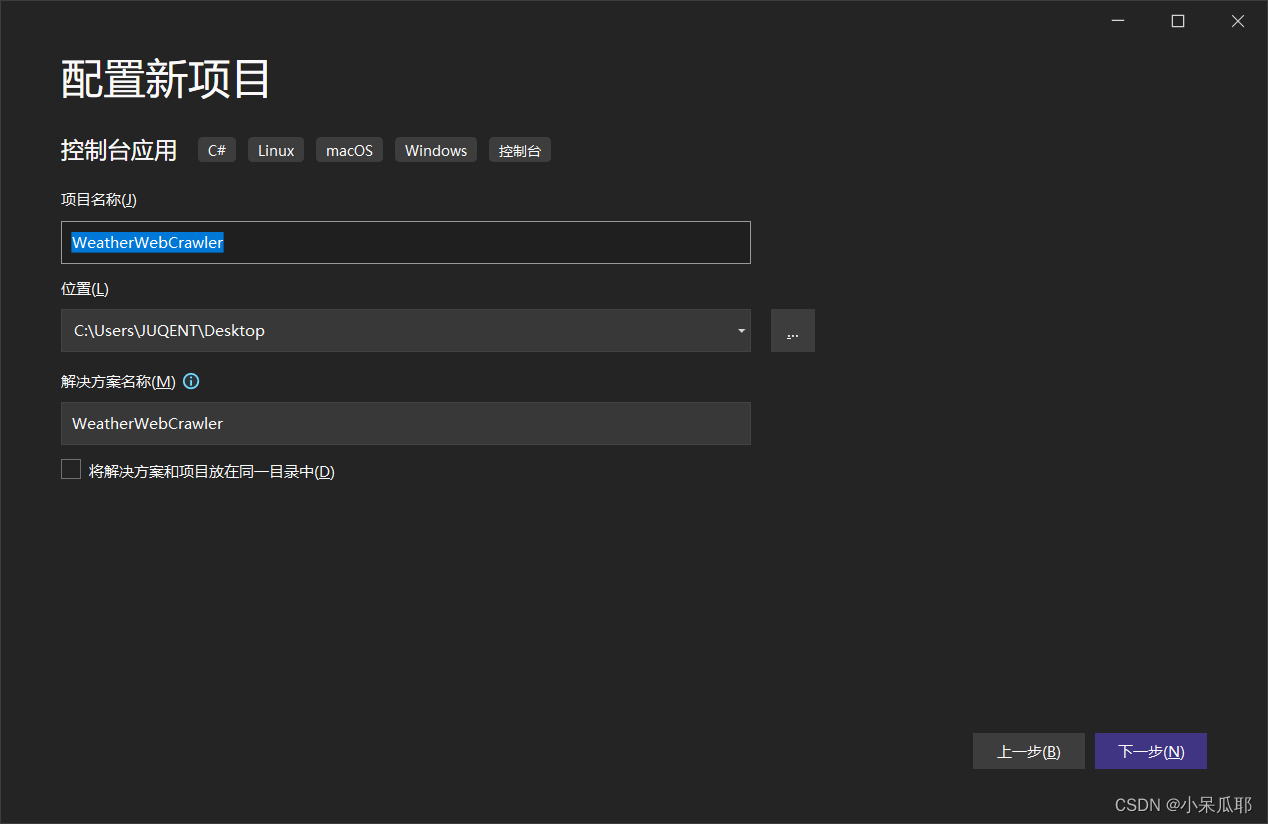
1.新建控制台项目WeatherWebCrawler
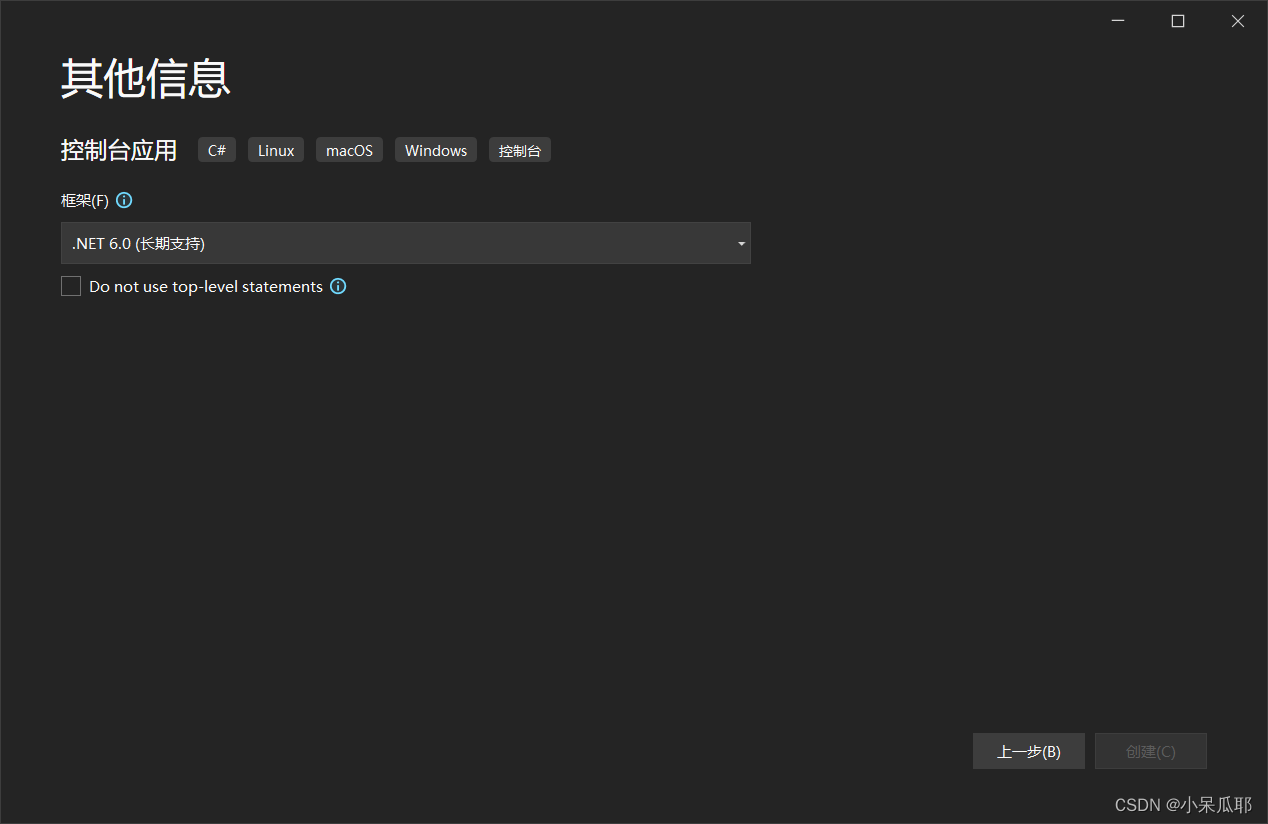
2.选择.NET 6.0
.NET 6.0和.NET Core 3.1最大区别是Program.cs中Main函数的取消,该代码在NET Core 3.1中也可使用
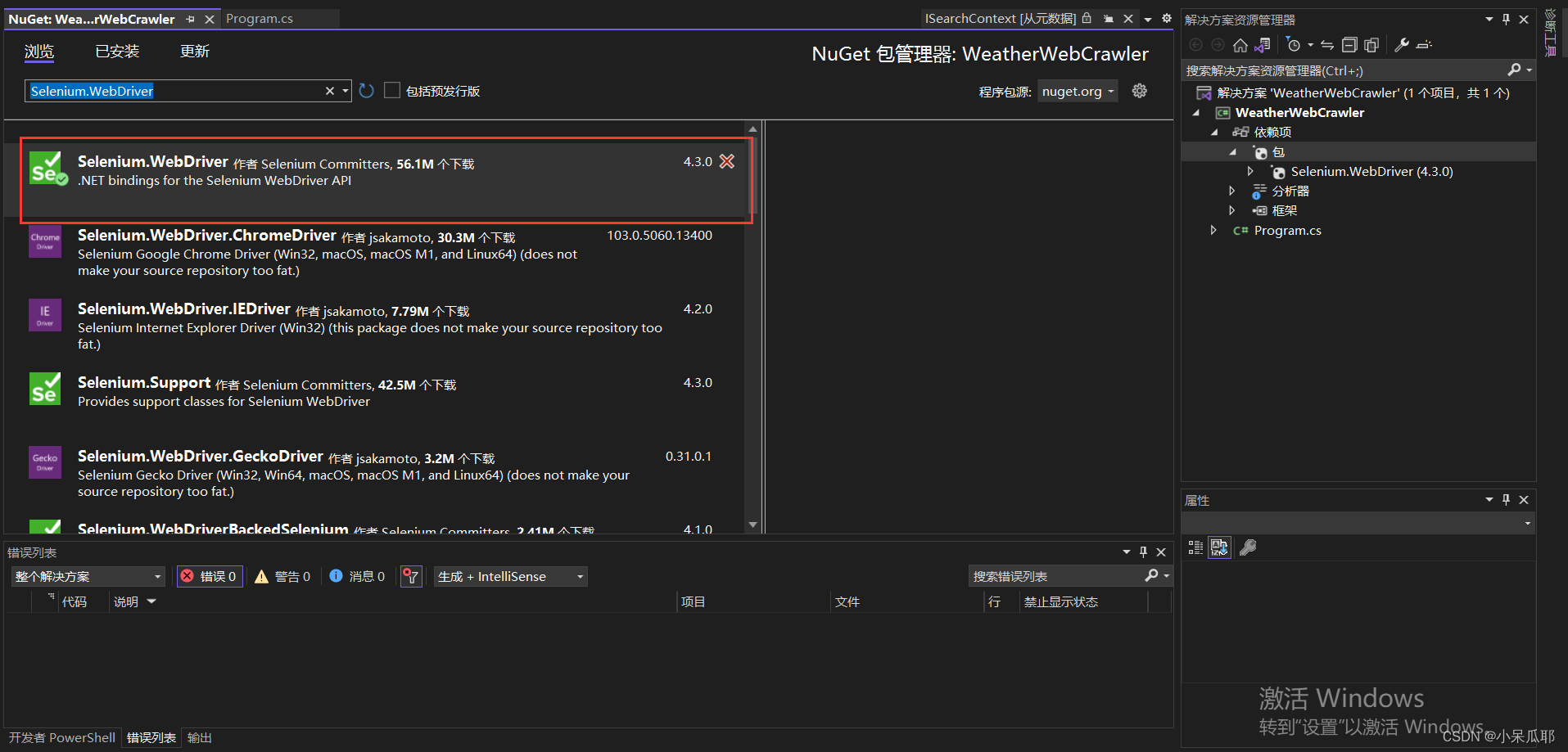
3.安装NuGet包
命令:Install-Package Selenium.WebDriver -Version 4.3.0
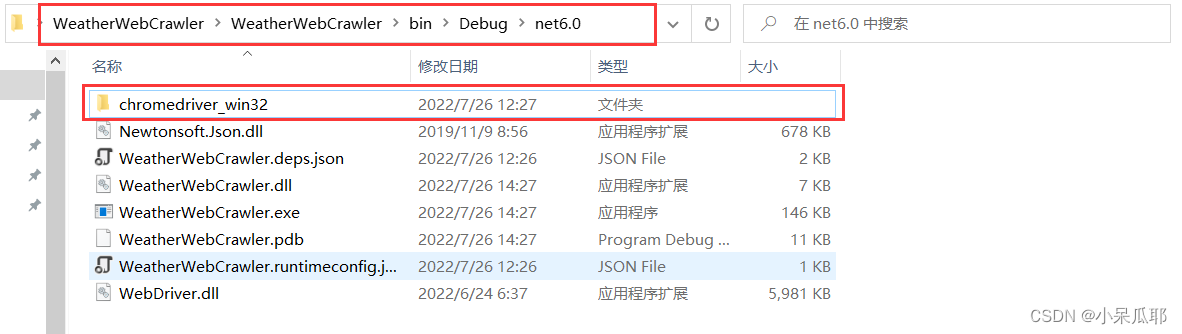
4.将下载好的驱动放到项目生成目录下
没有目录的把项目生成下就有了,注意不是项目根目录,而是项目生成的目录下;
或者知道自己放在哪个目录,代码中driverServicePath改成文件夹路径也行,路径只到文件夹,不要包含驱动文件
5.编写代码
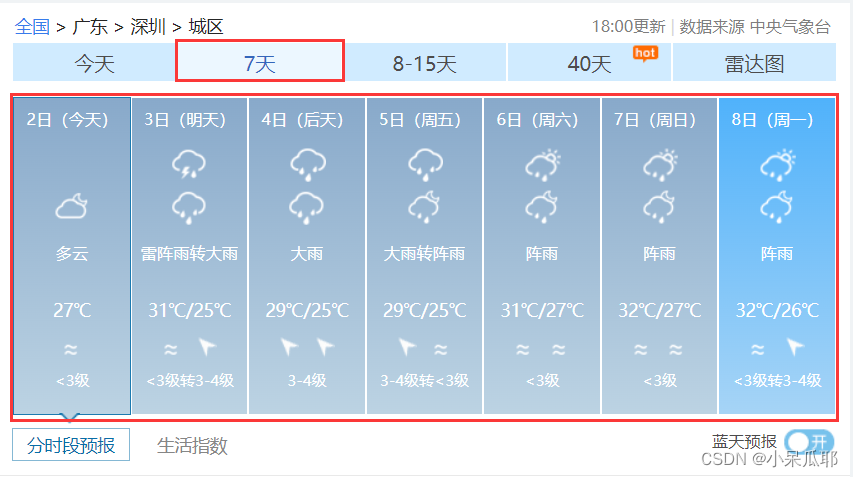
网站地址
首先拿到页面的url,根据需求选择想要城市的url,当前也可以拿到全部城市,用xml或者配置文件可动态选择,这里就不过多展开,等有时间后面会单独出一篇文章详解,代码中是以我当前所在地为例。
using OpenQA.Selenium.Chrome;
//驱动路径(注意不要包含驱动文件)
string driverServicePath = Path.Combine(Directory.GetCurrentDirectory(), "chromedriver_win32");
//创建驱动服务
ChromeDriverService service = ChromeDriverService.CreateDefaultService(driverServicePath);
//实例化浏览器驱动
ChromeDriver driver = new ChromeDriver(service);
//页面地址
string url = "http://www.weather.com.cn/weather/101280601.shtml";
//打开页面
driver.Navigate().GoToUrl(url);
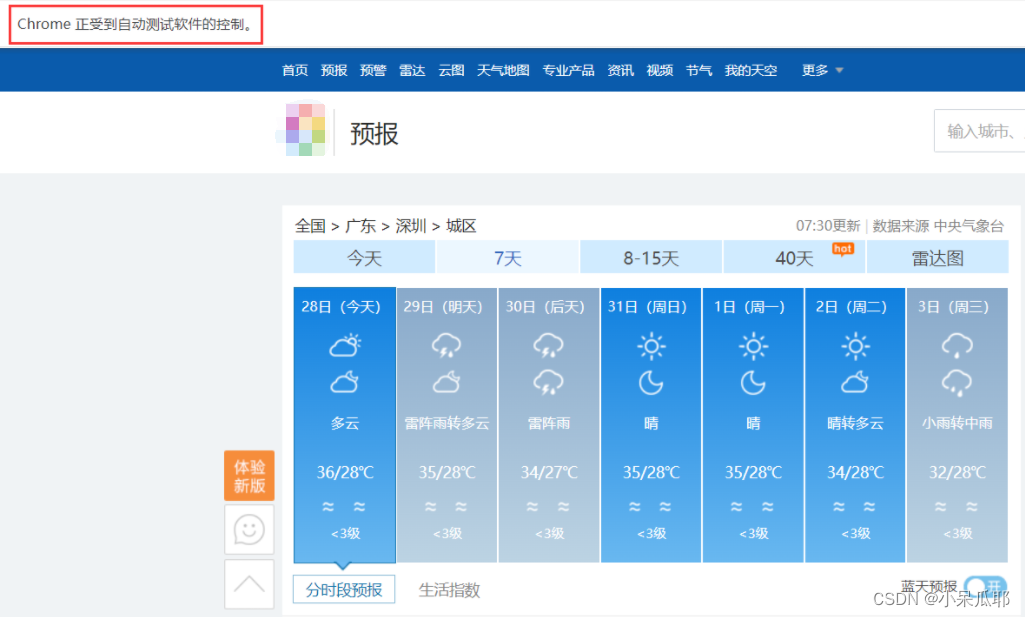
运行成功就可以看到程序自己打开浏览器了,并且有一行标识:Chrome 正受到自动测试软件的控制。
接着找到七天天气这块元素
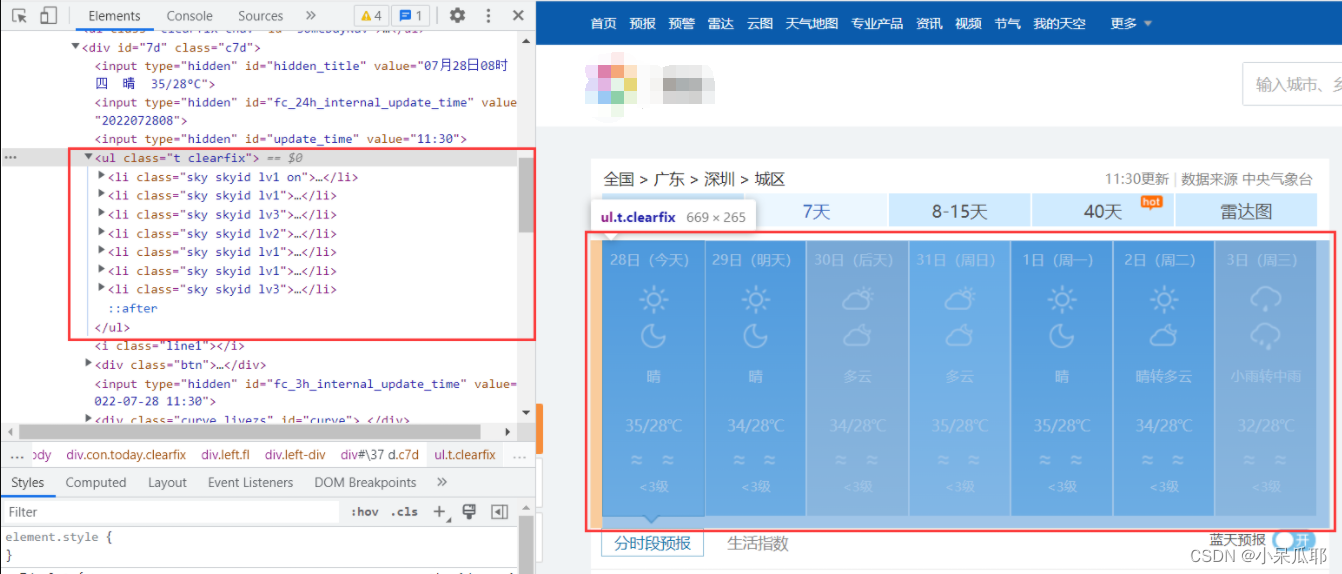
提示:class中带有空格的,只能用By.CssSelector获取元素
这里需要一点点前端知识,需要了解的同学可以前往:CSS选择器
扩展知识
不会前端的可以直接获取想要的元素的XPath:
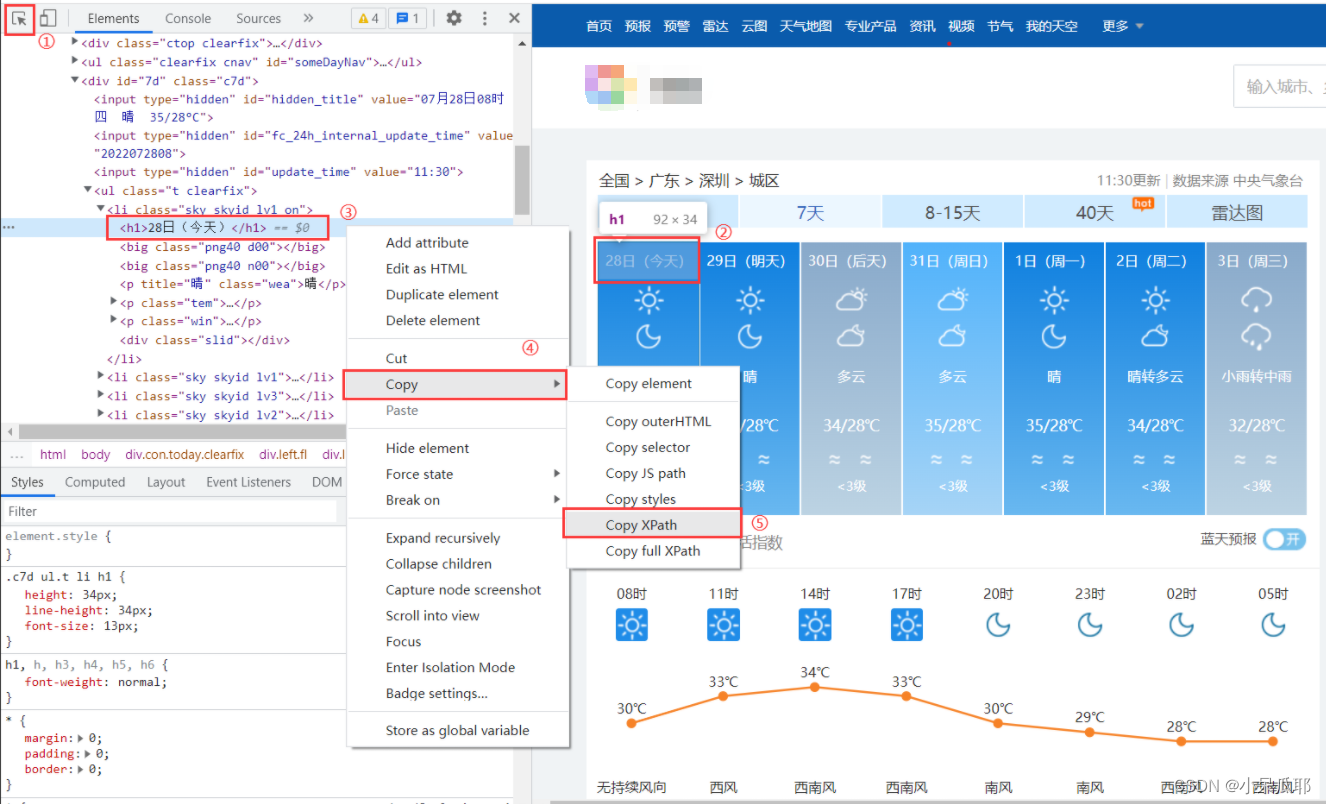
//获取七天天气
ReadOnlyCollection<IWebElement> sky = driver.FindElements(By.CssSelector("li[class^='sky skyid'"));
获取每一天天气信息
Console.Out.WriteLineAsync("\n********************************************************");
Console.Out.WriteLineAsync("\t\t近七天天气");
//输出每天天气信息
foreach (var item in sky)
{
//天气信息中的日期
string date = item.FindElement(By.TagName("h1")).Text;
//天气信息中的天气描述
string wea = item.FindElement(By.CssSelector("p[class='wea']")).Text;
//天气信息中的气温
string tem = item.FindElement(By.CssSelector("p[class='tem']")).Text;
//天气信息中的风向
string win = item.FindElement(By.CssSelector("p[class='win']>em>span:nth-child(1)")).GetAttribute("title");
//天气信息中的风力
var wins = item.FindElement(By.CssSelector("p[class='win']>i")).Text;
Console.Out.WriteLineAsync($"\n{date}天气信息:\n描述:{wea}\n气温:{tem}\n风向:{win}\n风力:{wins}");
}
Console.Out.WriteLineAsync("********************************************************");
可以看到控制台输出了七天天气信息,但是输出了很多没用得信息,看着很乱
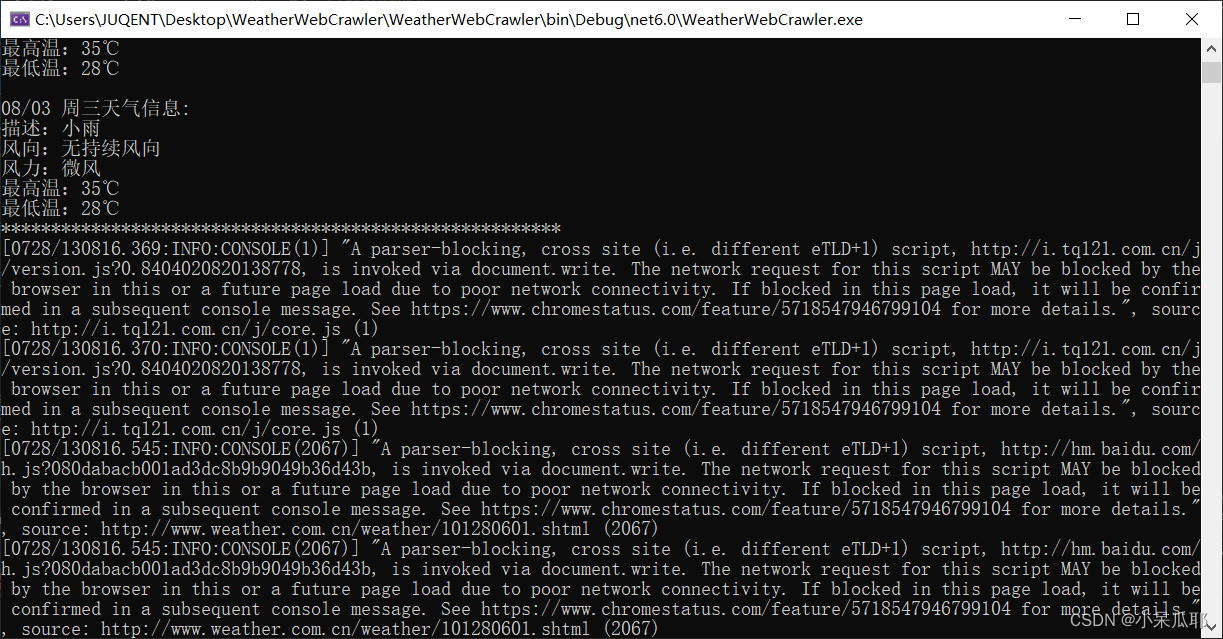
在平时开发过程中,我们其实没必要每次都打开浏览器,这速度非常缓慢,我们可以设置浏览器属性,想了解其他的设置项可以前往Chrome设置项
//浏览器设置项
ChromeOptions options = new ChromeOptions();
options.AddArgument("--headless");//无头模式(不打开浏览器)
options.AddArgument("--no-sandBox");//禁用沙箱(Linux下我试了只有加上该属性才能启动成功)
options.AddArgument("--incognito");//隐身模式(无痕模式)
options.AddArgument("--disable-gpu");//禁用GPU加速
options.AddArgument("--disable-gpu-program-cache");//禁用GPU程序缓存
options.AddArgument("--log-level=3");//控制台舒服信息非常多,日志级别设置高点只会输出失败的日志信息,日志的最低级别(INFO = 0, WARNING = 1, LOG_ERROR = 2, LOG_FATAL = 3)
//实例化浏览器驱动
ChromeDriver driver = new ChromeDriver(service, options);
再次启动,浏览器没有打开了,而且可以看到控制台日志信息少了很多输出信息,这样看着舒服多了

四、完整代码
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.Collections.ObjectModel;
#region 实例浏览器驱动
//驱动路径(注意不要包含驱动文件)
string driverServicePath = Path.Combine(Directory.GetCurrentDirectory(), "chromedriver_win32");
//创建驱动服务
ChromeDriverService service = ChromeDriverService.CreateDefaultService(driverServicePath);
//浏览器设置项
ChromeOptions options = new ChromeOptions();
options.AddArgument("--headless");//无头模式(不打开浏览器)
options.AddArgument("--no-sandBox");//禁用沙箱
options.AddArgument("--incognito");//隐身模式(无痕模式)
options.AddArgument("--disable-gpu");//禁用GPU加速
options.AddArgument("--disable-gpu-program-cache");//禁用GPU程序缓存
//options.AddArgument("--log-level=3");//日志的最低级别(INFO = 0, WARNING = 1, LOG_ERROR = 2, LOG_FATAL = 3)
//实例化浏览器驱动
ChromeDriver driver = new ChromeDriver(service, options);
#endregion
//获取天气
Weather();
Console.ReadKey();
#region 网站地址 http://www.weather.com.cn/
void Weather()
{
#region 获取网页信息
//页面地址
string url = "http://www.weather.com.cn/weather/101280601.shtml";
//打开页面
driver.Navigate().GoToUrl(url);
//获取七天天气
ReadOnlyCollection<IWebElement> sky = driver.FindElements(By.CssSelector("li[class^='sky skyid'"));
//获取七天天气(By.XPath)
//ReadOnlyCollection<IWebElement> sky = driver.FindElements(By.XPath("//*[@id='7d']/ul/li"));
#endregion
#region 打印结果
Console.Out.WriteLineAsync("\n********************************************************");
Console.Out.WriteLineAsync("\t\t近七天天气");
foreach (var item in sky)
{
//天气信息中的日期
string date = item.FindElement(By.TagName("h1")).Text;
//天气信息中的天气描述
string wea = item.FindElement(By.CssSelector("p[class='wea']")).Text;
//天气信息中的气温
string tem = item.FindElement(By.CssSelector("p[class='tem']")).Text;
//天气信息中的风向
string win = item.FindElement(By.CssSelector("p[class='win']>em>span:nth-child(1)")).GetAttribute("title");
//天气信息中的风力
var wins = item.FindElement(By.CssSelector("p[class='win']>i")).Text;
Console.Out.WriteLineAsync($"\n{date}天气信息:\n描述:{wea}\n气温:{tem}\n风向:{win}\n风力:{wins}");
}
Console.Out.WriteLineAsync("********************************************************");
#endregion
}
#endregion
总结
好了,以上就是今天要讲的内容,本文仅仅介绍了Selenium用于爬虫的简单使用,而Selenium提供了很多其他强大功能,想要继续深入学习Selenium的同学可以前往官网学习:selenium。
后面我也会陆续更新其他的爬虫小项目,感谢大家支持!
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
