

案例描述
- https://www.healthsmart.com.hk/hs-home/#!/link/home
- 这个网页你手工打开的时候你会发现一直处于加载中,一定时间后才好。
- 我们的需求是点击会员,弹出菜单,进行下一步操作,如果没有加载好是点不了的(业务特点)。
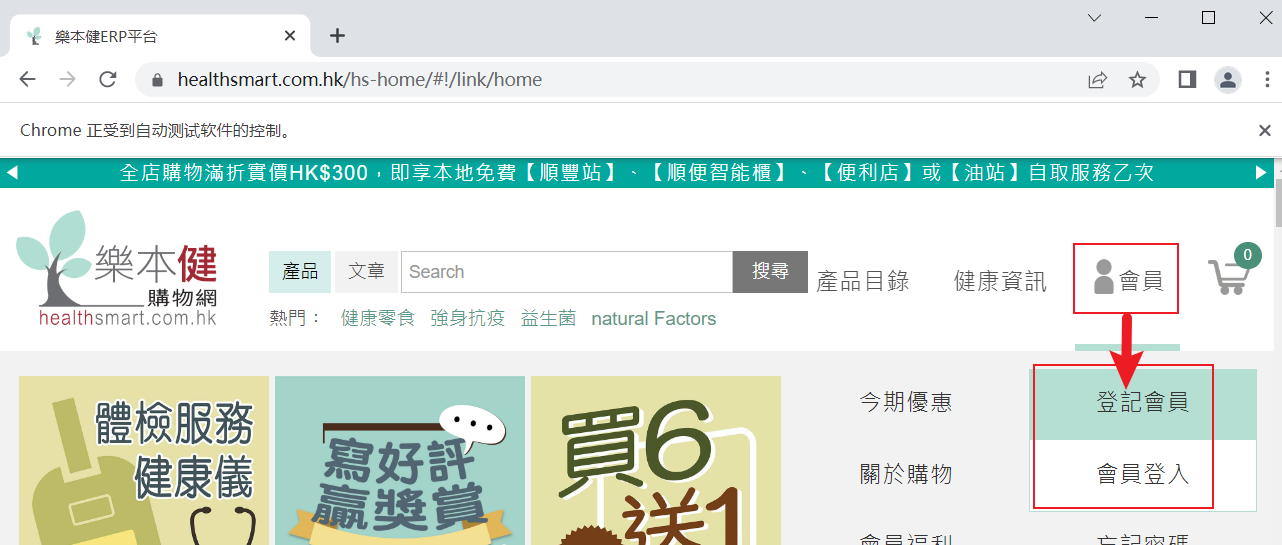
- 我们来看看代码怎么写
示例代码1:时间去哪里了
from selenium import webdriver
driver = webdriver.Chrome()
from time import ctime
print(ctime())
driver.get('https://www.healthsmart.com.hk/hs-home/#!/link/home')
print(ctime())
-
执行结果:实际等待了22秒
Tue Aug 23 10:16:33 2022 Tue Aug 23 10:16:55 2022 -
这里有个细节:selenium的get是会等待网页加载完毕的。以下在console可以看到
# 加载过程中 document.readyState 'interactive' # 网页上的X变成圈,加载完毕 document.readyState 'complete'
示例代码2:如何有效点击
直接点
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.healthsmart.com.hk/hs-home/#!/link/home')
driver.find_element('id','NavMember').click() #NavMember 是会员的li的id的值,可以点击的
- 执行效果是:没有任何效果
- 这就很奇怪,你已经知道了上面的get是会等待页面加载完毕的,click发生在加载完毕后应该没问题
- 事实却是不可以的。
- 通常这个时候你会想到显式等待,但显式等待的那么多已有的方法,你可以去试试,可能没有一个是适合的(你要深入去理解显式等待),为何呢?因为这个元素它就是存在的,你如果点击它要产生新的菜单,需要底层的代码配合(底层的js实现,但为何不算在加载中,要前端来解释了)。
- 所以单纯的显式等待无法解决这个问题。
显式等待点
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.healthsmart.com.hk/hs-home/#!/link/home')
ele_huiyuan = 'id','NavMember'
WebDriverWait(driver,5,0.5).until(EC.visibility_of_element_located(ele_huiyuan)).click()
- 一样的没有任何效果
强制等待点
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.healthsmart.com.hk/hs-home/#!/link/home')
ele_huiyuan = 'id','NavMember'
from time import sleep
sleep(1)
WebDriverWait(driver,5,0.5).until(EC.visibility_of_element_located(ele_huiyuan)).click()
- 很有意思的事发生了,点击出来了。
- 好像是加载了之后,那个底层的代码没有立即生效(就绪),你等会再点击就可以了。
- 但是,sleep总是不太可靠的,万一它2秒后才就绪呢?
轮询等待原始实现
- 现在我们大概知道,这个登记会员元素的元素在点击会员后会产生,那就意味着,如果没有它,我每隔1s就点会员,就可以达到我要的效果

from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.healthsmart.com.hk/hs-home/#!/link/home')
from time import time,sleep
start_time = time() # 定义开始时间
timeout = 5 # 定义超时时间
poll_frequency = 0.5 # 定义轮询时间
end_time = start_time + timeout # 定义结束时间
while True:
driver.find_element('id','NavMember').click() # 点击
try:
if driver.find_element('link text','登記會員'): #看有无这个元素,如果有,跳出循环 ,如果没有,异常了
driver.find_element('link text', '登記會員').click()
print('找到了登记会员')
break
except:
sleep(poll_frequency) # 等待 轮询时间
if time()>=end_time: # 如果超过了结束时间
print('超时了')
break # 也终止
- 这样做是可以的,但是如果熟悉显式等待的同学就知道,这部分其实几乎就是显式的源码实现
- 那我们依样画葫芦来实现下。
自定义显式等待条件的实现方式
- 下面的写法你要对显式等待比较了解方可
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.get('https://www.healthsmart.com.hk/hs-home/#!/link/home')
def find_huiyuan():
def _predicate(driver):
try:
driver.find_element('id','NavMember').click()
return driver.find_element('link text','登記會員')
except :
return False
return _predicate
WebDriverWait(driver,5,0.5).until(find_huiyuan()).click()
- 当然我在这里也没有过度封装,find_huiyuan可以再做好一点,这个就留给大家了。
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
