

Selenium 介绍:
Selenium是一个用于Web应用程序测试的工具。
Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
支持的浏览器包括IE,Mozilla和Firefox等。这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。
测试系统功能--创建衰退测试检验软件功能和用户需求。
Selenium 安装:
首先 windows + r 输入cmd 进入黑框。
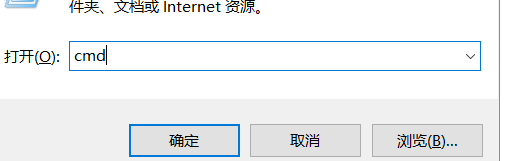
进入黑框,输入 : pip install selenium 下载包。

如果想通过chrom来实现模拟点击,那就先查看一下自己的chrom版本号。(版本号去帮助里可查)
本人的是:

然后通过 http://chromedriver.storage.googleapis.com/index.html 这个网址 , 去下载一个和你版本号 差不多的一个编辑器,然后把它解压到你的chrom文件里。
解压完之后 , 配一下环境变量。
配环境变量操作。
首先进入此电脑属性 ,
进去之后点高级设置:

点进高级设置之后,去点 环境变量。

进入环境变量之后 ,双击 path

然后新建, 将你clorm 的 路径 添加到里面 保存就可以了。
然后就是实现 模拟点击的代码 (进入的是本人的博客 网站!)
# 导包 from selenium import webdriver # 导入时间模块 import time
import requests
# 使用传统方式抓网站
# r = requests.get("http://military.cctv.com")
# html = r.content.decode('utf-8')
# with open("./cctv.html",'w',encoding='utf-8') as f: # f.write(html)
# 建立浏览器对象 browser = webdriver.Chrome()
# 使用浏览器访问网站 browser.get('https://www.baidu.com')
# 向文本框填充文本
browser.find_element_by_id('kw').send_keys('男神鹏') time.sleep(1)
# 模拟点击 browser.find_element_by_id('su').click() time.sleep(20)
# 匹配多个节点 # elist = browser.find_elements('css selector','h3') elist = browser.find_elements_by_class_name('t')
text_str = elist[0].text
print(elist[0].text)
# 点击链接 browser.find_element_by_link_text(text_str).click()
# 暂停 time.sleep(50)
# 关闭浏览器 browser.quit() 将此代码 run code 一下 , 他就会进入到本人的博客网站了。 如需补充, 请各路大神赐教!
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
