

一、使用正则表达式步骤
1、寻找规律;
2、使用正则符号表示规律;
3、提取信息,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
二、正则表达式中常见的基本符号
@H_502_17@1.点号“.” 一个点号可以代替除了换行符(\n)以外的任何一个字符,包括但不限于英文字母、数字、汉字、英文标点符号和中文标点符号。 2.星号“*” 一个星号可以表示它前面的一个子表达式(普通字符、另一个或几个正则表达式符号)0次到无限次。 3.问号“?” 问号表示它前面的子表达式0次或者1次。注意,这里的问号是英文问号。 4.反斜杠“\” 反斜杠在正则表达式里面不能单独使用,甚至在整个Python里都不能单独使用。反斜杠需要和其他的字符配合使用来把特殊符号变成普通符号,把普通符号变成特殊符号。如:“\n”。 5.数字“\d” 正则表达式里面使用“\d”来表示一位数字。再次强调一下,“\d”虽然是由反斜杠和字母d构成的,但是要把“\d”看成一个正则表达式符号整体。 6.小括号“()” 小括号可以把括号里面的内容提取出来。
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块来操作,名字为re
import re在re模块中,通常使用三种方法,match,search和findall,下面对这三种方法进行简单的介绍:
@H_404_28@1.match方法re.match 尝试从字符串的起始位置匹配一个模式,匹配成功则返回的是一个匹配对象(这个对象包含了我们匹配的信息),如果不是起始位置匹配成功的话,match()返回的是空,
注意:match只能匹配到一个**
下面来看代码理解
s = 'python123python666python888'
result = re.match('python',s)
print(result) # <re.Match object; span=(0,6),match='python'>
print(result.span()) # (0,6)
print(result.group()) # python1.通过span()提取匹配到的字符下标
2.通过group()提取匹配到的内容
而s字符串中有3个python的存在,match只能匹配到一个
下面我们改变一下s,得到不一样的结果
s = '1python123python666python888'
result = re.match('python',s)
print(result) #None因为match从字符串的起始位置开始匹配,这里起始的第一个字符为1,所以匹配失败返回None.
那么我们要如何才能匹配到字符串中间我们想要的部分呢,这个时候就用到了search函数
re.search 扫描整个字符串,匹配成功则返回的是一个匹配对象(这个对象包含了我们匹配的信息)
注意:search也只能匹配到一个,找到符合规则的就返回,不会一直往后找
同样的,search也只能匹配到一个.
代码如下
s = '1python123python666python888'
result = re.search('python',s)
print(result) # <re.Match object; span=(1,7),match='python'>
print(result.span()) # (1,7)
print(result.group()) # python当然,若是都找不到则返回None值
s = '1python123python666python888'
result = re.search('python98',s)
print(result) # None*search方法虽然解决了match的从头匹配的弊端,但它也只能匹配到一个,这个时候我们就可以使用findall方法了 *
@H_404_28@3.findall方法:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表
s = '1python123python666python888'
result = re.findall('python',s)
print(result) # ['python','python','python']上面的三种方法看上去只能匹配到简单的字符串,也许我们觉得用一般的方法也可以办到:
比如字符串的index方法(也可以用循序)
print(s.index('python')) # 1
print(s.index('python',2)) # 10
print(s.index('python',11)) # 19那么正则表达式应该用在什么地方呢:
四、元字符匹配规则
元字符:本身具有特殊含义的字符
先看几张常用的图片
单字符匹配: 如下
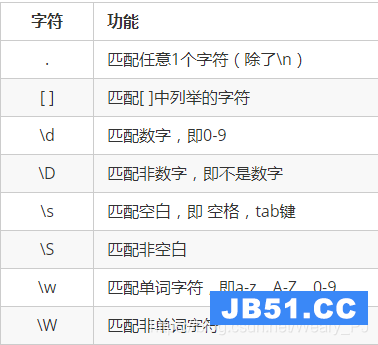
代表数量的元字符

表示边界的元字符

分组匹配

举例
下面我们来举一些例子
1.匹配账号:只能由字母和数字组成,长度为10位
import re
s = '1587022xzq'
result = re.match('[0-9a-zA-z]{10}',10),match='1587022xzq'>因为账号是从头到尾的,只需要匹配一次就行,所以我们可以使用match方法,但是上面的代码明显存在问题,比如将长度增加三位,它将依然能匹配到
s = '1587022xzqty'
result = re.match('[0-9a-zA-z]{10}',match='1587022xzq'>这是因为我们没有加上控制边界的元字符,下面是修改后正确的代码
s = '1587022xzqty'
result = re.match('^[0-9a-zA-z]{10}$',s)
print(result) # None解析:
- (因为对于match来说,从头开始匹配,所以这里的^可以不加)
- $的意思是匹配到字符串的结尾,
- 账号的长度为10位是通过代表数量的元字符{10}来控制的
2.匹配qq号:长度为5-11位,纯数字组成,第一位不为0
s = '10086111222'
# 5 - 11 位
result = re.match('[1-9][0-9]{4,10}$',11),match='10086111222'>解析:
我们可以简化一下[0-9]的写法,\d就可以代表纯数字
s = '10086111222'
# 5 - 11 位
result = re.match(r'[1-9]\d{4,match='10086111222'>tip:这里在字符串前面加上r是为了取消转义,不然就需要写成 \d(虽然这里的\d实际上没有影响)
3.检索文件名 格式为 xxx.py
s = '1.py 2.png ssx.csv qaq.txt xzq.py'
#文件名格式: (数字字母_).py
result = re.findall(r'\w+\.py\b',s)
print(result) # ['1.py','xzq.py']解析:
- \w代表 word,及字母数字或下划线
- +为控制数量 >=1
- \b代表边界,这里如果前面不加上r的话\b就应该写成\b
- 注意点.文件的格式为xxx.py 这里的.需要特别注意,因为在单字符匹配中

所以我们需要使用 \ . 来表示我们所需要的.
4.匹配1-100的数字
s = '89'
result = re.match(r'[1-9]?\d?$',s)
print(result) # <re.Match object; span=(0,2),match='89'>这是第一步的思路,但是当我们把s改为100时就发现了错误
s = '100'
result = re.match(r'[1-9]?\d?$',s)
print(result) # None改进之后的代码
s = '100'
r = '98'
z = '9'
q = '0'
result = re.match(r'[1-9]?\d?$|100$',s)
print(result)
print(re.match(r'[1-9]?\d?$|100$',r))
print(re.match(r'[1-9]?\d?$|100$',z))
print(re.match(r'[1-9]?\d?$|100$',q))
''' <re.Match object; span=(0,3),match='100'> <re.Match object; span=(0,match='98'> <re.Match object; span=(0,1),match='9'> <re.Match object; span=(0,match='0'> '''5.验证输入的邮箱
# 验证输入的邮箱 163 126 qq 前面至少五位,至多11位
email = '[email protected]'
result = re.match(r'\w{5,11}@(163|126|qq)\.(com|cn)$',email)
print(result) # <re.Match object; span=(0,16),match='[email protected]'>注意:括号和方括号的区别
(qq|163|126)代表的是qq或163或126
[qq|163|126]代表的是q1236这几个符号
6.分组提取匹配爬虫电话号码
比如我们用爬虫爬到了一组数据
里面有一组数据是xxxx-xxxxxxxx
前面包含3/4个数字,后面包含8个数字
下面将他们取出,这里我们用到了分组,(小括号)
# 爬虫
phone = '010-12345678'
result = re.match(r'(\d{3}|\d{4})-(\d{8})$',phone)
print(result) # <re.Match object; span=(0,12),match='010-12345678'>
print(result.group()) # 010-12345678
print(result.group(1)) # 010
print(result.group(2)) # 12345678# 爬虫
html标签的格式形如 <xxx>y</xxx> y为我们要提取的内容
s = '<h1>hello</h1>'
result = re.match('<[0-9A-z]+>(.+)</[0-9A-z]+>$',14),match='<h1>hello</h1>'>
print(result.group(1)) # hello表面上看这样没什么问题,但如果更改s如下就出现了问题
# 爬虫
s = '<html>hello</h1>'
result = re.match('<[0-9A-z]+>(.+)</[0-9A-z]+>$',match='<html>hello</h1>'>
print(result.group(1)) # hello所以改进,利用分组来判断
# 爬虫
s = '<html>hello</h1>'
s2 = '<html>hello</html>'
result = re.match(r'<([0-9A-z]+)>(.+)</\1>$',s)
print(result) # None
result = re.match(r'<([0-9A-z]+)>(.+)</\1>$',s2)
print(result) # <re.Match object; span=(0,18),match='<html>hello</html>'>
print(result.group(1)) # html
print(result.group(2)) # hello解析:这里使用\1代表与第一个分组相同
拓展:起名字
# 取名字 (?P<名字>正则) (?P=名字)
看似繁琐了一点,但是在遇到复杂的情况,比如多重标签嵌套,或者其他情况下的时候通过取名分组的方法十分实用,不容易出错
# 取名字 (?P<名字>正则) (?P=名字)
s = '<html>hello</h1>'
s2 = '<html>hello</html>'
result = re.match(r'<(?P<name1>\w+)>(.+)</(?P=name1)>$',s)
print(result) # None
result = re.match(r'<(?P<name1>\w+)>(?P<msg>.+)</(?P=name1)>$',match='<html>hello</html>'>
print(result.group('name1')) # html
print(result.group('msg')) # hello类似于replace替换方法rre.sub(正则表达式,替换成什么,要替换的字符串)
s1 = 'java:90 python:95 html:89'
result = re.sub(r'\d+','90',s1)
print(result) # java:90 python:90 html:90不过第二个参数位置可以放函数
比如把取出来的数字都加一,函数可以理解为找到一个匹配的值就执行一次函数
def func(num):
a = num.group()
b = int(a) + 1
return str(b)
s1 = 'java:90 python:95 html:89'
result = re.sub(r'\d+',func,s1)
print(result) # java:91 python:96 html:90split切割,根字符串的spilt类似,但是更加灵活
s1 = 'java:90,python:95,html:89'
result = re.split(r'[,:]',s1)
print(result) # ['java','95','html','89']正则默认都是用贪婪模式去匹配数据的,就是尽可能多的匹配符合要求的数据
非贪婪模式下,始终找最短匹配

加上?之后就变成非贪婪模式
s1 = 'abc1123avc'
result = re.findall(r'[A-z]+\d+',s1)
print(result) # ['abc1123']s1 = 'abc1123avc'
result = re.findall(r'[A-z]+\d+?',s1)
print(result) # ['abc1']版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 [email protected] 举报,一经查实,本站将立刻删除。
