
文章目录
1、缓存模型和思路
标准的操作方式就是查询数据库之前先查询缓存,如果缓存数据存在,则直接从缓存中返回,如果缓存数据不存在,再查询数据库,然后将数据存入redis。
缓存作用模型
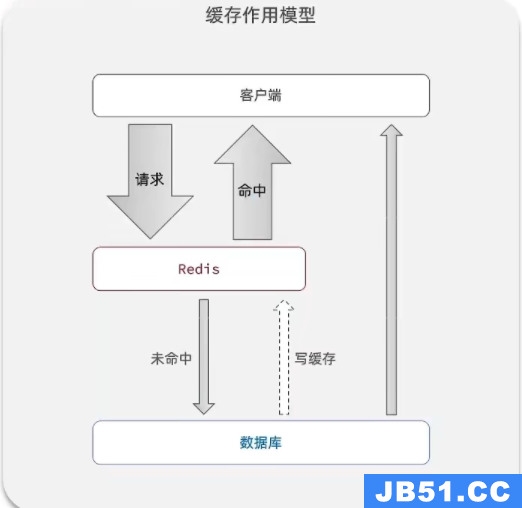
在项目中我们经常这样用缓存来缓解数据库的压力:
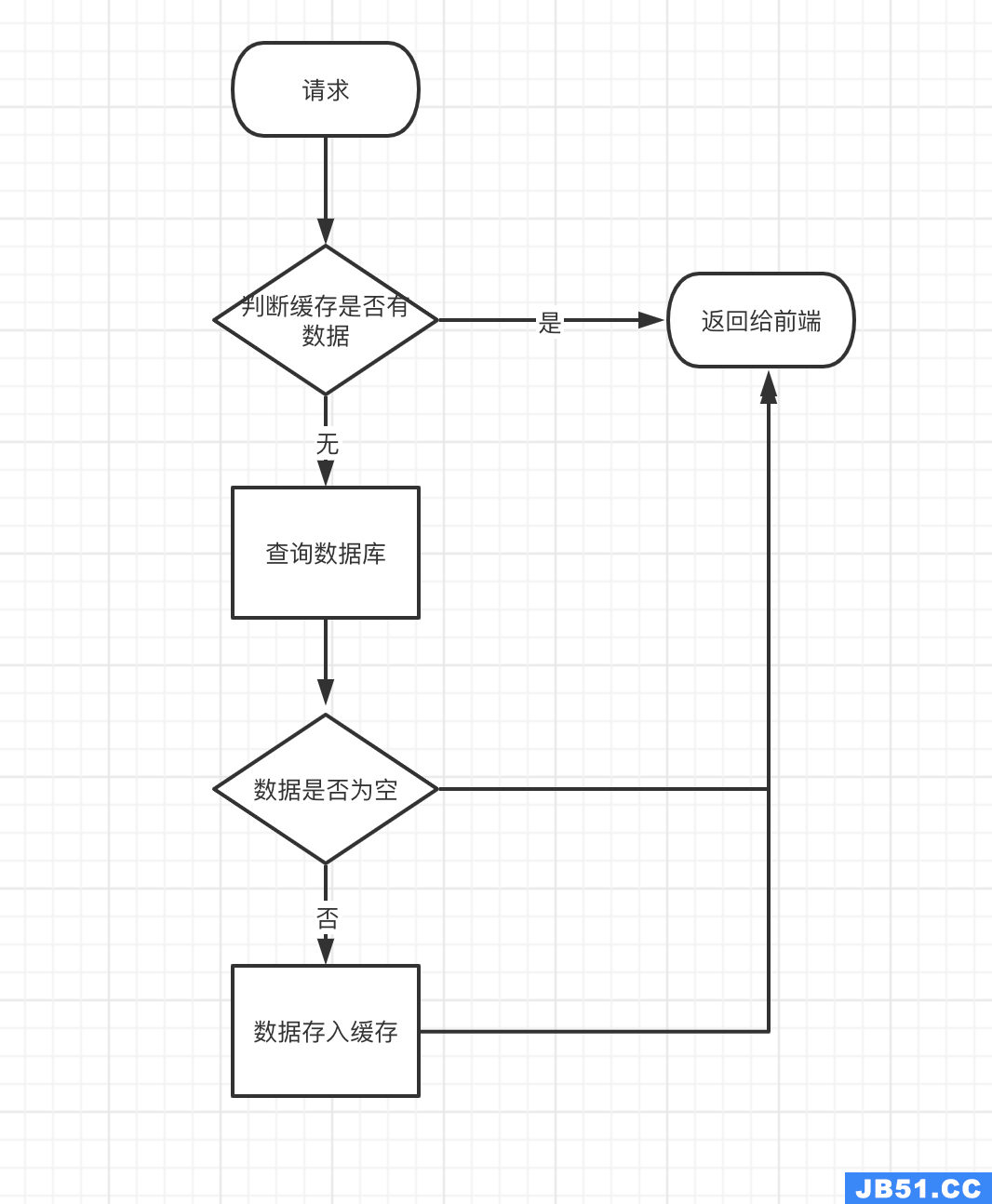
2、缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行更新,或者把他叫为淘汰更合适。
内存淘汰:redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题
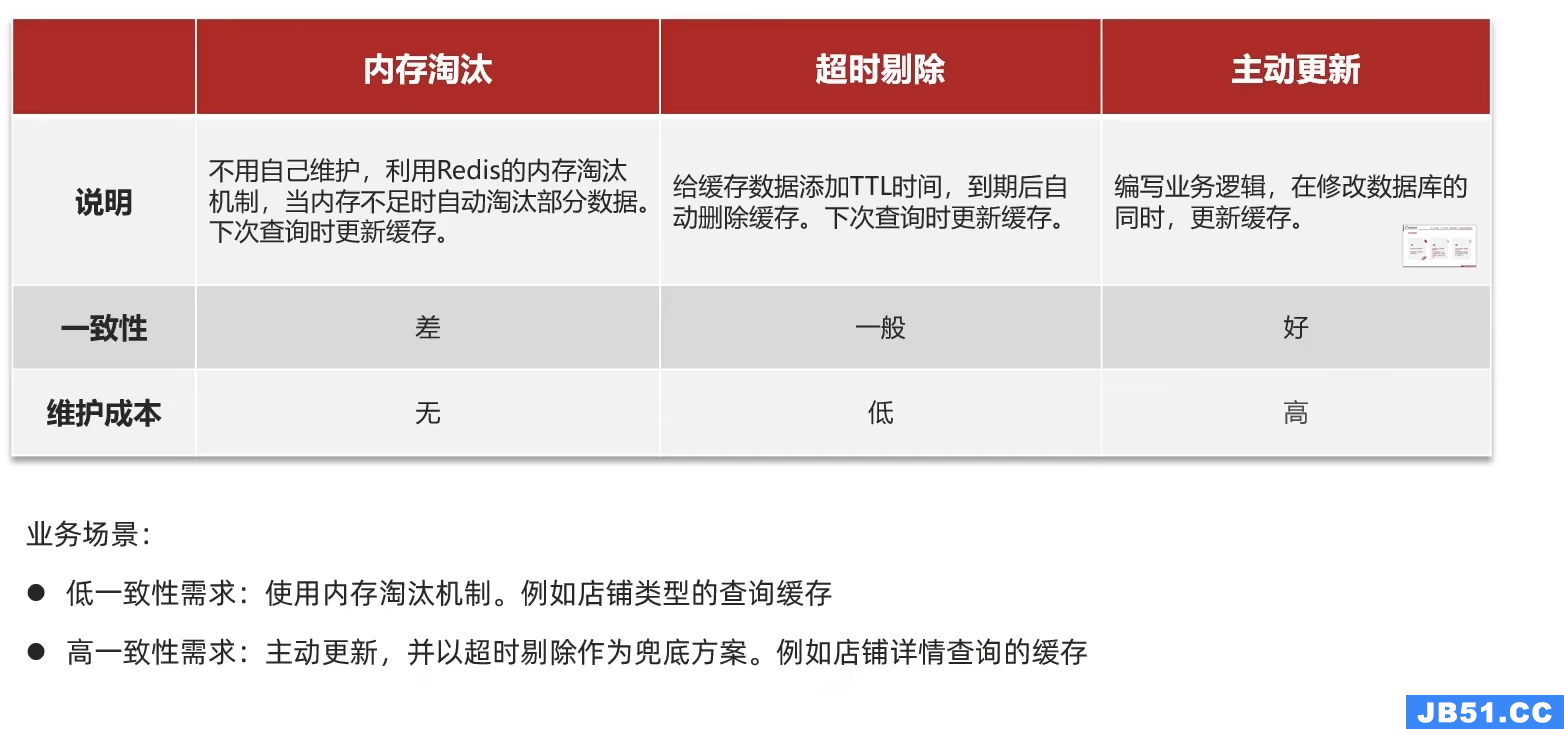
主动更新
-
删除缓存还是更新缓存?
-
更新缓存:每次更新数据库都更新缓存,无效写操作较多
-
删除缓存:更新数据库时让缓存失效,查询时再更新缓存==(选择这个)==
-
举个例子:如果数据库1小时内更新了1000次,那么缓存也要更新1000次,但是这个缓存可能只在最后一次更新后被读取了1次,那么前999次的更新有必要吗?
反过来,如果是删除的话,就算数据库更新了1000次,那么也只是做了1次缓存删除(删除前判断key是否存在),只有当缓存真正被读取的时候才去数据库加载
-
-
-
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
-
先操作缓存还是先操作数据库?
- 先删除缓存,再操作数据库
- 先操作数据库,再删除缓存选择这个
3、两种解决方案
3.1、先删除缓存,再更新数据库
先删除缓存,数据库还没有更新成功,此时如果读取缓存,缓存不存在,去数据库中读取到的是旧值,然后更新缓存,缓存不一致发生。如图:
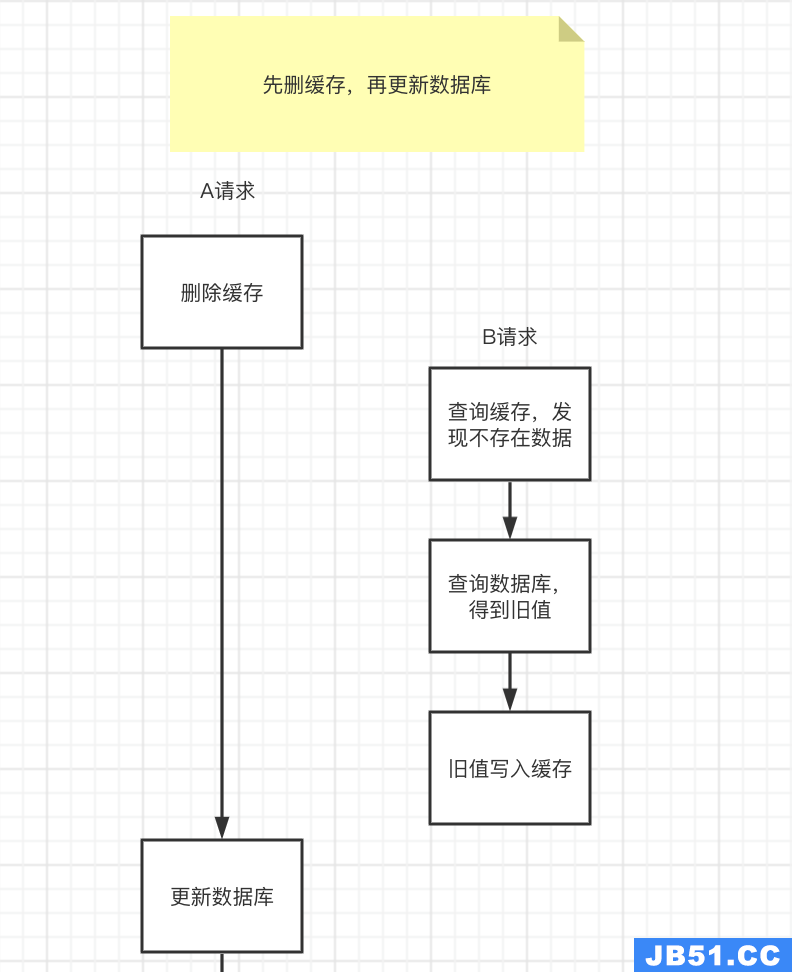
极端情况下会出现缓存不一致问题
- 请求A先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及更新数据库。
- 这时请求B过来了,先查询缓存发现没数据,再查数据库,有数据,但是旧值。
- 请求B将数据库中的旧值,更新到缓存中。
- 此时,请求A卡顿结束,把新值写入数据库。
3.1.1延时双删(解决先删除缓存,再更新数据库产生的缓存不一致问题)
上面的问题可以用延时双删的方案来解决,思路是,更新完数据库之后,再sleep一段时间,然后再次删除缓存。
sleep的时间要对业务读写缓存的时间做出评估,sleep时间大于读写缓存的时间即可。
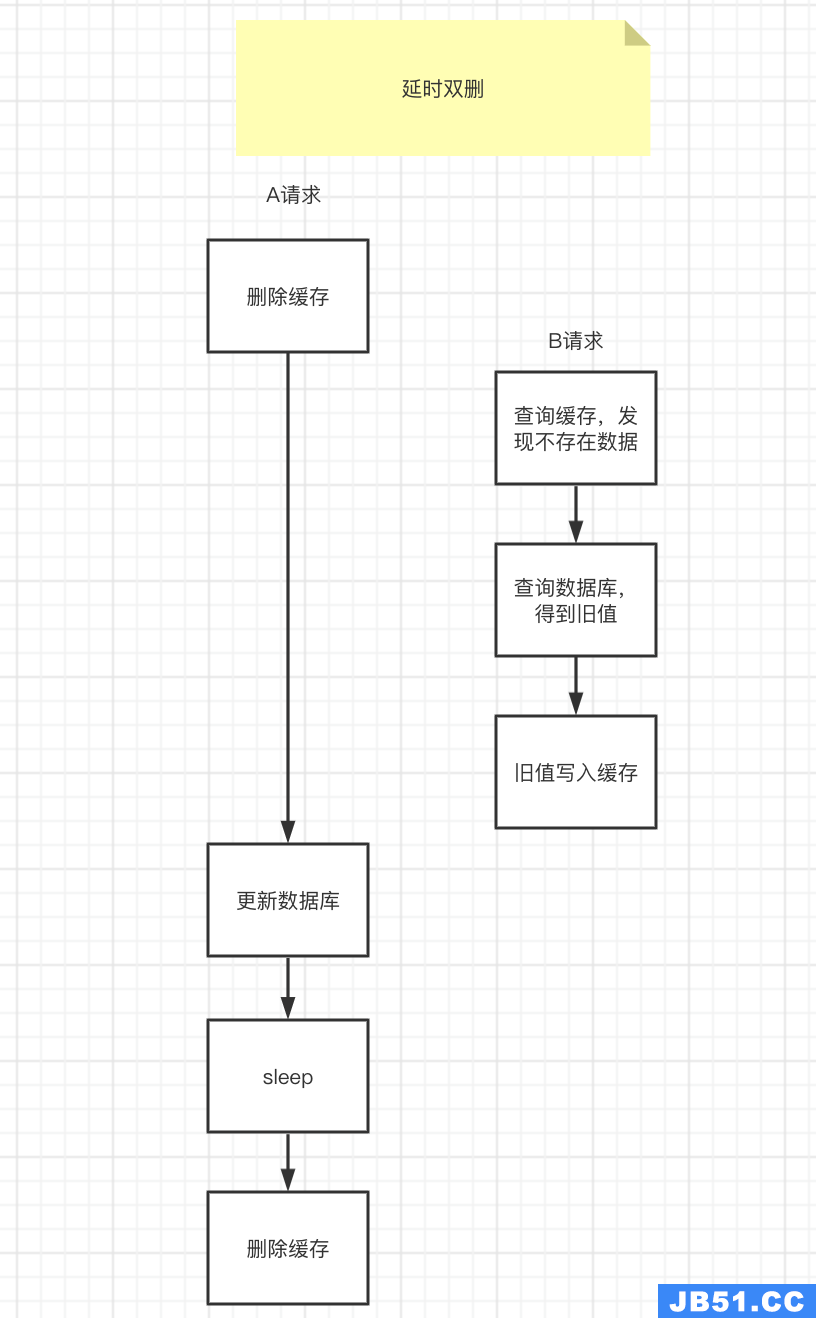
- 线程1删除缓存,然后去更新数据库
- 线程2来读缓存,发现缓存已经被删除,所以直接从数据库中读取,这时候由于线程1还没有更新完成,所以读到的是旧值,然后把旧值写入缓存
- 线程1,根据估算的时间,sleep,由于sleep的时间大于线程2读数据+写缓存的时间,所以缓存被再次删除
- 如果还有其他线程来读取缓存的话,就会再次从数据库中读取到最新值
1、什么是延时双删
延迟双删策略是分布式中数据库存储和缓存数据保持一致性的常用策略,但它不是强一致。其实不管哪种方案,都避免不了Redis存在脏数据的问题,只能减轻这个问题,要想彻底解决,得要用到同步锁和对应的业务逻辑层面解决。
2、为什么要进行延迟双删?
一般我们在更新数据库数据时,需要同步redis中缓存的数据,所以存在两种方法:
第一种方案:先执行update操作,再执行缓存清除。
第二种方案:先执行缓存清除,再执行update操作。
这两种方案的弊端是当存在并发请求时,很容易出现以下问题:
第一种方案:当请求1执行update操作后,还未来得及进行缓存清除,此时请求2查询到并使用了redis中的旧数据。
第二种方案:当请求1执行清除缓存后,还未进行update操作,此时请求2进行查询到了旧数据并写入了redis。
3、如何实现延迟双删?
延时双删方案执行步骤
1.删除redis
2.更新数据库
3.延时N秒(N秒的时间要大于一次写操作的时间,一般为3-5秒)
4.删除redis
- 问题一:为何要延时N秒?
这是为了我们在第二次删除redis之前能完成数据库的更新操作。
假象一下,如果没有第三步操作时,有很大概率,在两次删除redis操作执行完毕之后,数据库的数据还没有更新,此时若有请求访问数据,便会出现我们一开始提到的那个问题。 - 问题二: 为何要两次删除redis?
如果我们没有第二次删除操作,此时有请求访问数据,有可能是访问的之前未做修改的redis数据,删除操作执行后,redis为空,有请求进来时,便会去访问数据库,此时数据库中的数据已是更新后的数据,保证了数据的一致性。
4、小结
- 延迟双删用比较简洁的方式实现 mysql 和 redis 数据最终一致性,但它不是强一致。
- 延迟,是因为 mysql 和 redis 主从节点数据同步不是实时的,所以需要等待一段时间,去增强它们的数据一致性。
- 延迟是指当前请求逻辑处理延时,而不是当前线程或进程睡眠延迟。
- mysql 和 redis 数据一致性是一个复杂的课题,通常是多种策略同时使用,例如:延迟双删、redis 过期淘汰、通过路由策略串行处理同类型数据、分布式锁等等。
3.2、先更新数据库,再删除缓存
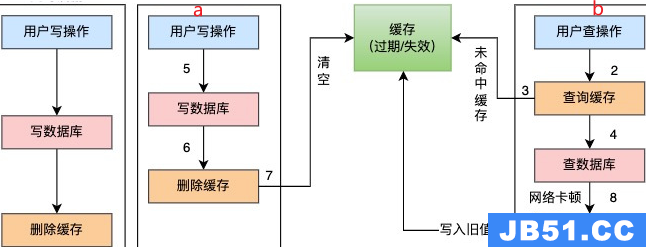
第一种情况
- 请求a先写数据库,由于网络原因卡顿了一下,没有来得及删除缓存。
- 请求b查询缓存,发现缓存中有数据,直接返回该数据。
- 请求a删除缓存。
第二种情况
但如果是读数据请求先过来呢?
- 请求b查询缓存,发现缓存中有数据,直接返回该数据。
- 请求a先写数据库。
- 请求a删除缓存。
这种情况看起来也没问题。
第三种情况
但就怕一种情况:缓存失效。
- 缓存自动失效。
- 请求a查询缓存,发缓存中没有数据,查询数据库的旧值,但由于网络原因卡顿了,没有来得及更新缓存。
- 请求b先写数据库,接着删除了缓存。
- 请求a更新旧值到缓存中。
如图所示:
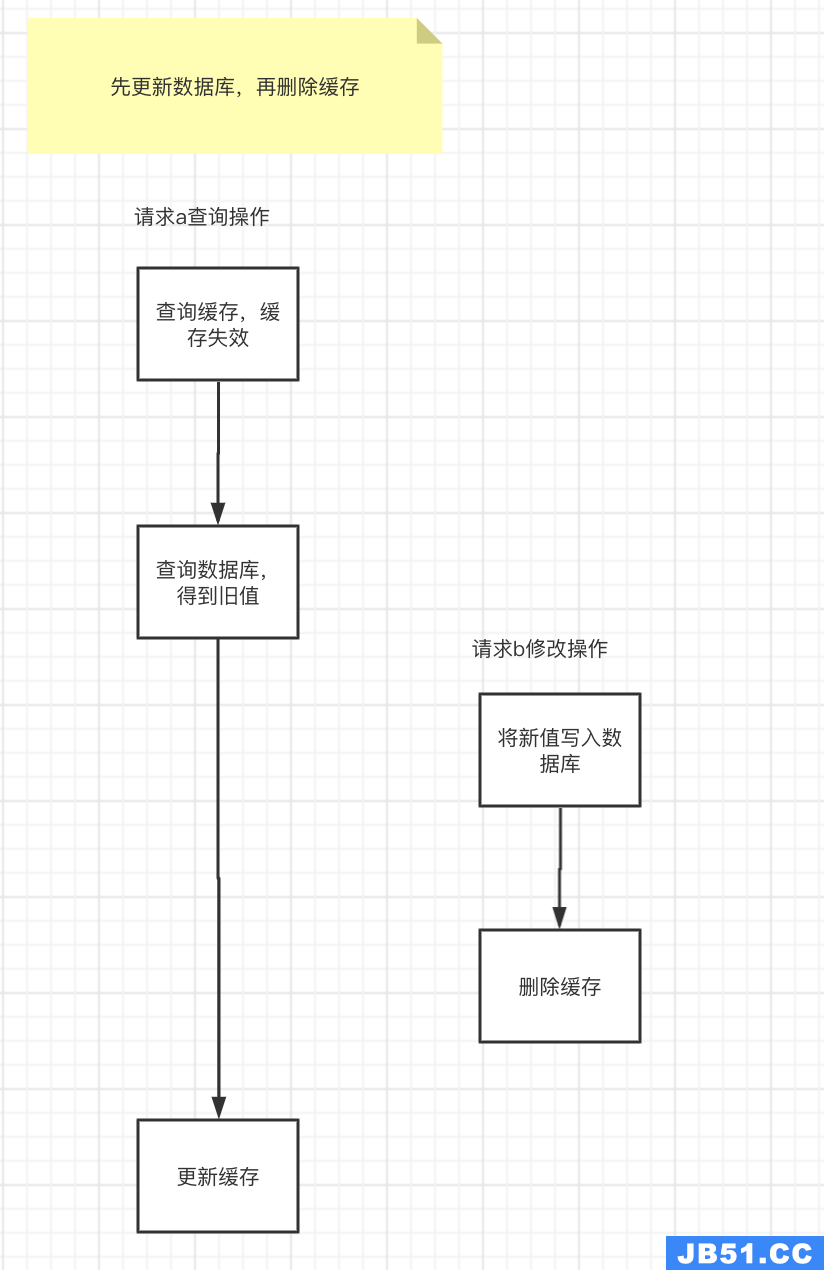
这时,缓存和数据库的数据同样出现不一致的情况了。但这种情况还是比较少的,需要同时满足以下条件:
-
缓存刚好自动失效。
-
请求a从数据库查出旧值,更新缓存的耗时,比请求b写数据库,并且删除缓存的耗时还长。
删除缓存失败怎么办?
其实先写数据库,再删缓存的方案,跟缓存双删的方案一样,有一个共同的风险点,即:如果缓存删除失败了怎么办?
方案一:设置过期时间
缓存设置一个过期时间,比如5分钟。当然这种方案只适合数据更新不是太频繁的业务。
方案二:同步重试
在接口中判断是否删除成功,如果失败就重试,直到成功或超过最大重试次数为止,返回数据。当然,这种方案的缺点就是可能影响接口性能。
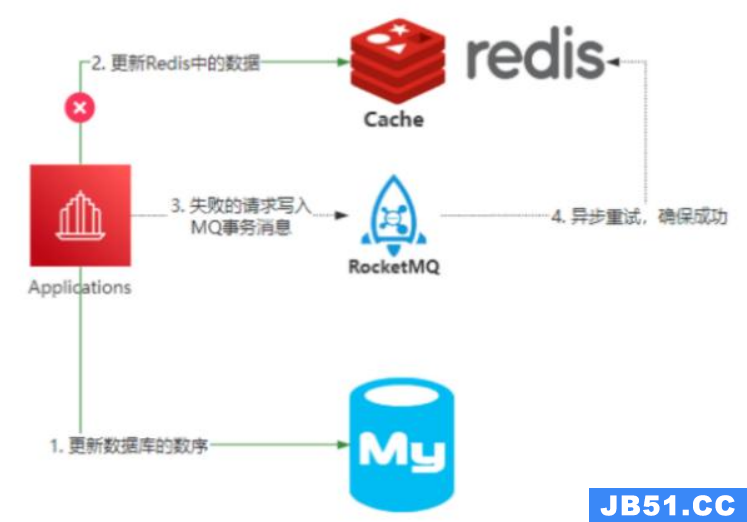
方案三:消息队列
将删除缓存任务写入mq等消息中间件中,在mq的consumer中处理。但问题也很多:
- 引入消息中间件之后,问题更复杂了,对业务代码有一定侵入性、消息丢失怎么办
- 消息本身的延迟也会带来短暂的不一致性,不过这个延迟相对来说还是可以接受的
比如基于 RocketMQ 的可靠性消息通信,来实现最终一致性。
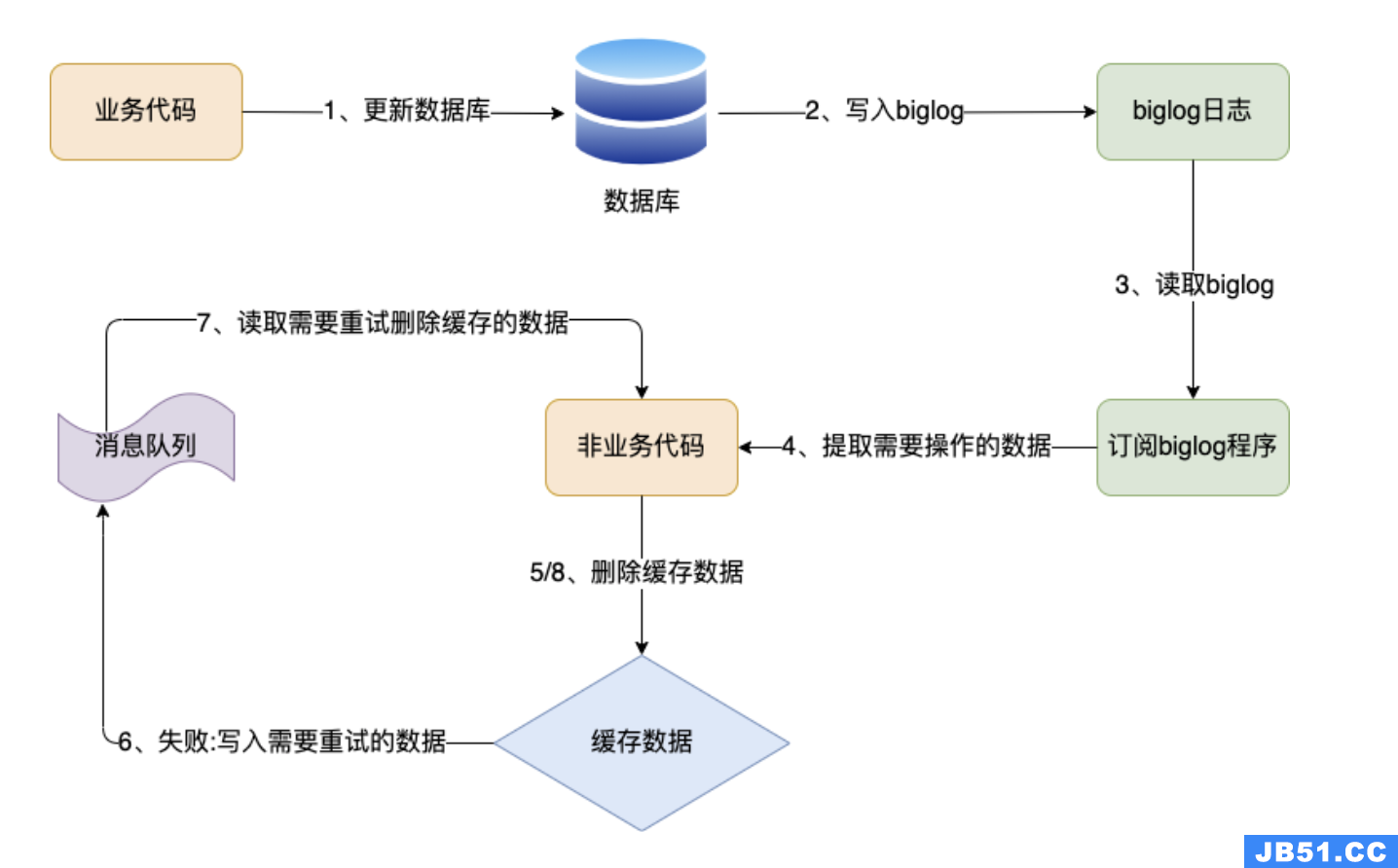
方案四:订阅mysql的binlog
我们可以借助监听binlog的消息队列来做删除缓存的操作。这样做的好处是,删除动作无需侵入到业务代码,消息中间件帮你做了解耦,同时,中间件的这个东西本身就保证了高可用。
4、总结
删除缓存有两种方式
-
先删除缓存,再更新数据库。解决方案是使用延迟双删。
-
先更新数据库,再删除缓存。解决方案是消息队列或者监听binlog同步,引入消息队列会带来更多的问题,对业务代码有一定侵入性,并不推荐直接使用。
针对缓存一致性要求不是很高的场景,那么只通过设置超时时间就可以了。
原文地址:https://blog.csdn.net/weixin_54040016/article/details/128656269
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。