
当我们谈论Redis集群的数据一致性问题时,实际上我们是在探讨一个复杂且多维度的主题。

Redis作为一个高性能的键值存储数据库,在分布式环境下如何保证数据的一致性,是设计和使用Redis集群时需要重点考虑的问题。
下面,我将从多个角度对如何确保Redis集群数据一致性问题进行分析,并提供一些解决方案和最佳实践,希望能够帮到大家。
1、理解Redis数据一致性的基础概念
Redis的数据一致性需要从两个角度来理解:一是Redis节点内部数据的一致性,即持久化文件与内存数据的一致性;二是在集群环境下,不同节点间数据的一致性。对于第一个角度,需要正确配置和使用RDB和AOF来保证;对于第二个角度,则涉及到主从复制和集群状态维护等复杂问题。
2、Redis集群的工作机制
Redis集群通过将数据分片来实现分布式存储,每个键通过CRC16算法计算出一个哈希值,然后根据这个值将键分配到不同的分片。这样,每个节点只需要处理一部分数据请求,从而提高整个集群的性能。
3、主从复制机制
在Redis中,主从复制是通过发送复制命令来实现的。一个简单的复制命令示例如下:
// 假定我们已经有了一个Redis连接
Jedis master = new Jedis("master_host", 6379);
Jedis slave = new Jedis("slave_host", 6379);
// 在从节点上执行复制操作
slave.slaveof("master_host", 6379);
这段代码将会使得名为slave的节点成为master的从节点,从而复制master的数据。
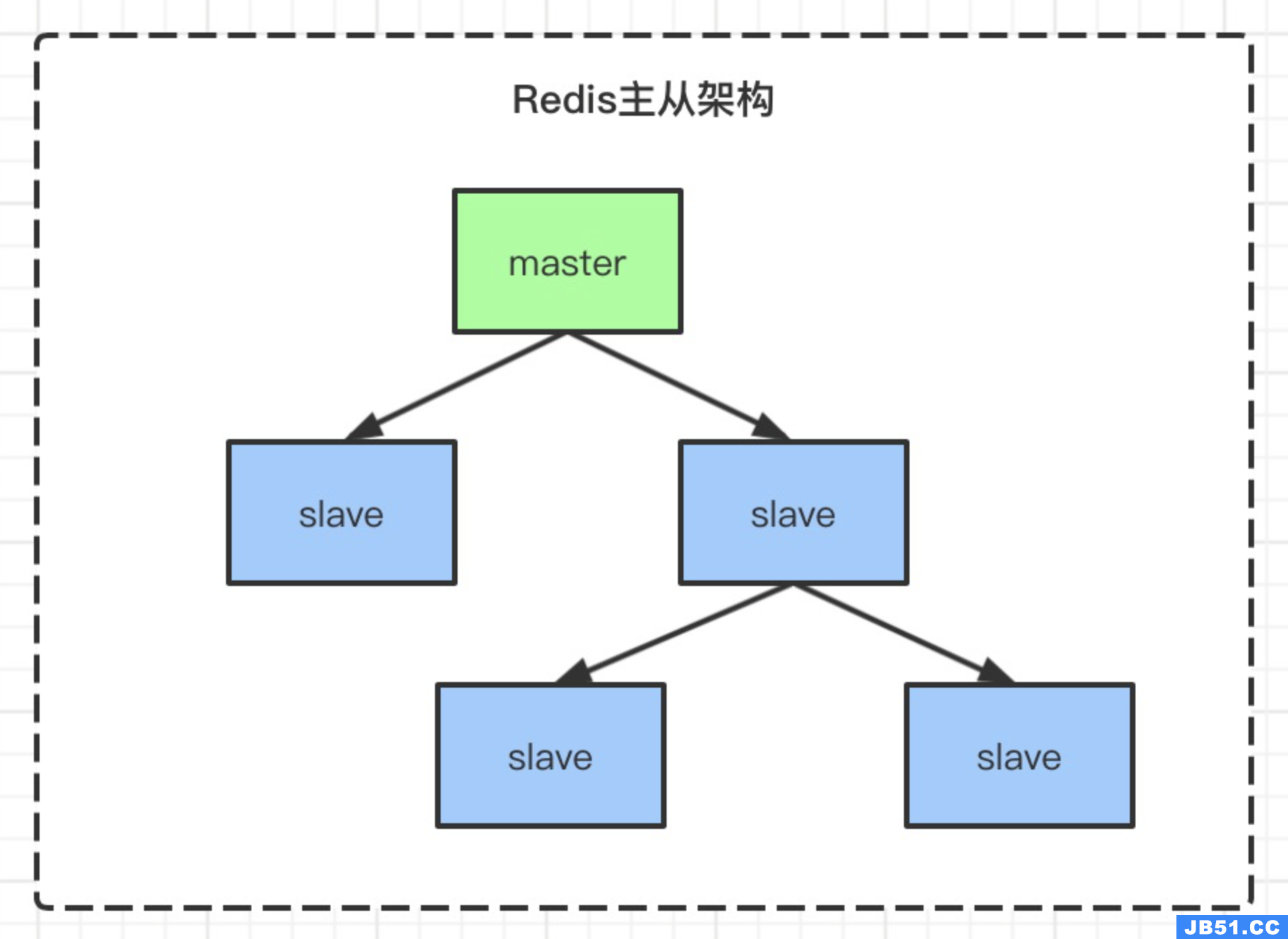
主从复制的基本原理
Redis的主从复制机制包含三个主要步骤:
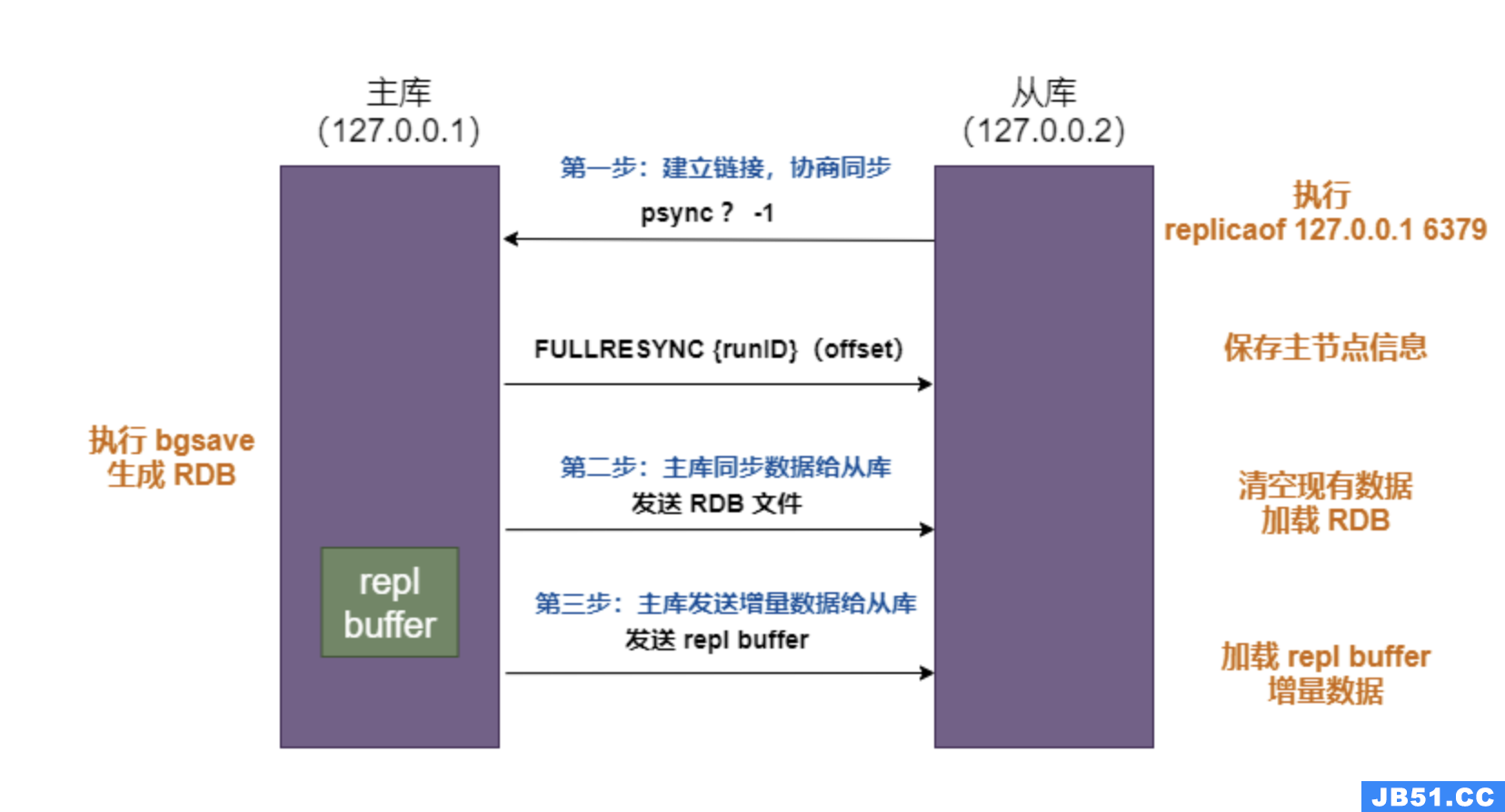
1、同步(Synchronization)
在这个阶段,从服务器连接到主服务器,并请求同步数据。首次同步时,主服务器会执行一个BGSAVE操作来创建一个当前数据的快照,并将这个快照文件发送给从服务器。从服务器收到这个文件后,会加载到自己的数据库中。
2、命令传播(Command Propagation)
完成了初始的数据快照同步之后,主服务器会继续将所有接收到的写命令发送给所有从服务器,从服务器执行相同的写命令,这样就能保证主从服务器的数据状态是一致的。
3、断线后重连(Reconnection after Disconnect)
如果从服务器与主服务器之间的连接因为某些原因断开,当它们重新连接时,Redis的复制机制可以自动恢复同步状态。从服务器将基于主服务器的复制偏移量和自己的偏移量来请求缺失的数据。
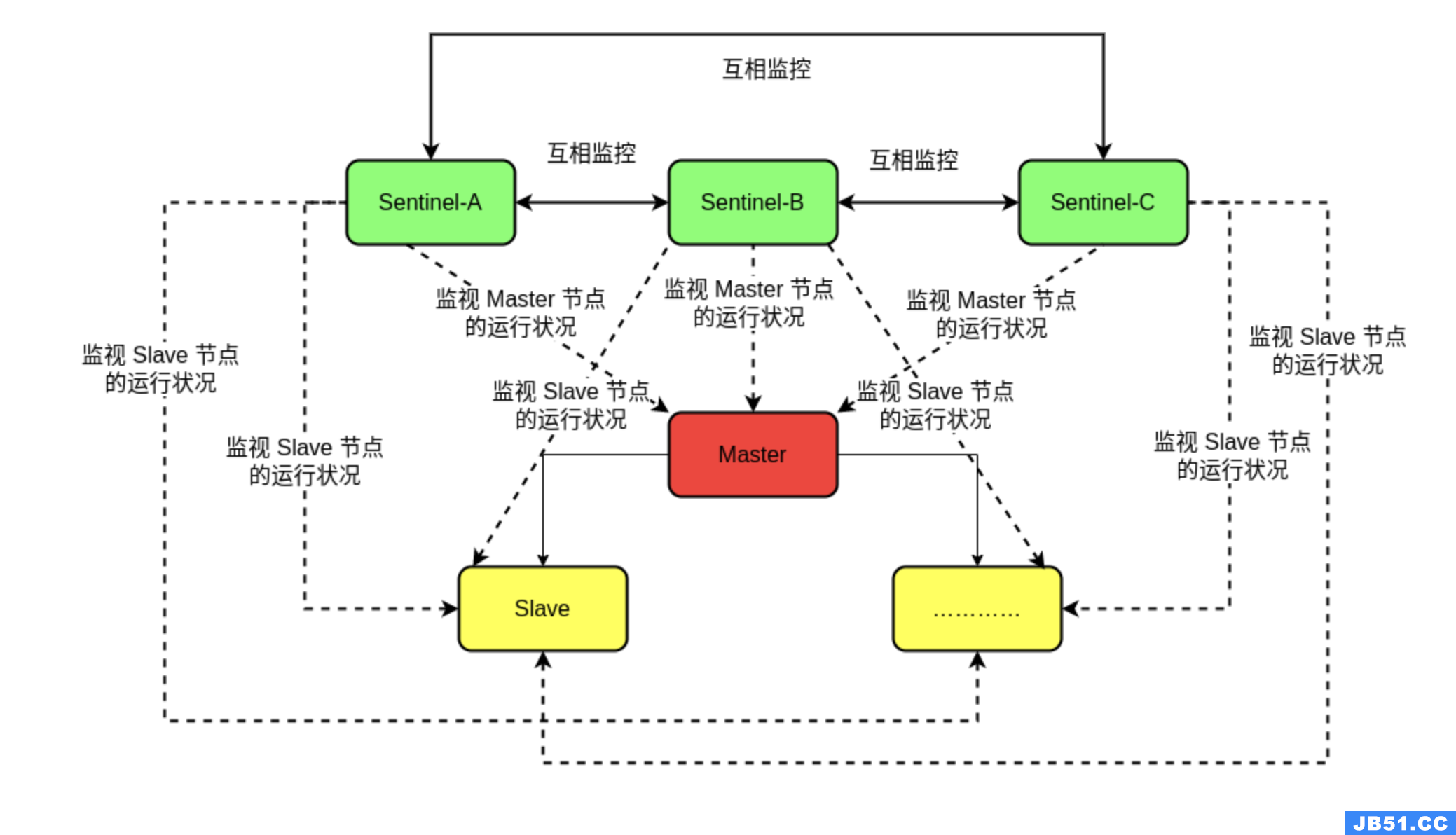
主从复制的实现
在Redis中配置主从复制非常简单,只需要几个步骤:
步骤1:配置主服务器
主服务器不需要特别的配置。只要它运行着,你可以将任何Redis服务器配置成它的从服务器。
步骤2:配置从服务器
从服务器需要知道主服务器的位置,可以在配置文件中设置或者使用命令行。
# 在从服务器的配置文件中设置主服务器
slaveof <masterip> <masterport>
# 或者使用Redis命令动态设置从服务器
SLAVEOF <masterip> <masterport>
步骤3:处理网络断开和自动重连
Redis复制是具备断开自动重连的,一旦网络恢复,从服务器会尝试连接主服务器并同步任何丢失的数据。
步骤4:处理故障转移
如果主服务器宕机,需要人工或借助Redis Sentinel等工具来升级一个从服务器为新的主服务器。
主从复制的高级特性
-
部分重同步(PSYNC)
Redis 2.8版本引入了PSYNC命令,它允许从服务器在断开后只同步部分丢失的数据而不是全部数据,这大大减少了数据同步的时间和网络带宽的使用。 -
无盘复制(Diskless Replication)
从Redis 2.8.18版本开始,可以配置主服务器直接通过网络发送RDB文件给从服务器,而不是先写入磁盘再发送,这样可以减少磁盘I/O以及复制延迟。 -
复制积压缓冲区(Replication Backlog)
为了支持PSYNC,主服务器会维护一个复制积压缓冲区,这是一个固定大小的缓冲区,用来保存最近发送的写命令,从服务器可以从这个缓冲区中读取自己断线后丢失的数据。
举个例子,使用命令行来配置主从关系:
# 在主服务器上不需要特别配置
# 在从服务器执行
redis-cli -h <主服务器IP> -p <主服务器端口> SLAVEOF <主服务器IP> <主服务器端口>
当主从复制配置完成后,从服务器将自动开始同步主服务器的数据。这个过程是由Redis内部自动管理的,通常对用户来说是透明的。
4、哨兵模式与数据一致性
哨兵模式的配置较为复杂,涉及到多个哨兵实例的协作。以下是哨兵模式的配置文件示例:
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
这段配置定义了监控名为mymaster的Redis主节点,指定了两个哨兵实例、主节点宕机的判断时间、故障转移的超时时间以及并行同步的数量。
5、持久化策略
为了保证数据一致性,可以同时使用RDB和AOF。一个推荐的持久化配置如下:
save 900 1
save 300 10
save 60 10000
appendonly yes
appendfsync everysec
这段配置意味着Redis会在以下条件下进行持久化:900秒内至少有1个键被改变、300秒内至少有10个键被改变、60秒内至少有10000个键被改变;开启AOF,并且每秒进行一次同步。
6、避免脑裂问题
为了避免脑裂,需要设置恰当的超时时间和选举策略,Redis的配置文件中相关部分如下:
cluster-node-timeout 15000
这里设置了节点超时时间为15000毫秒,在这个时间内如果节点无法通信,会被认为是失效的。
7、数据同步策略
在故障修复后,可以使用以下命令来手动触发从节点与新主节点的数据同步:
// 假定slave是从节点的Jedis连接
slave.slaveofNoOne();
slave.slaveof("new_master_host", 6379);
这段代码首先会取消从节点的复制状态,然后将其设定为新的主节点的从节点。
8、避免写操作丢失
使用Redis事务可以避免写操作丢失,事务的示例代码如下:
Jedis jedis = new Jedis("localhost");
Transaction t = jedis.multi();
t.set("foo", "bar");
t.exec();
这个例子中,我们将"foo"设置为"bar",并且这个操作被放入一个事务中,确保要么全部执行,要么全部不执行。
9、监控和告警
可以使用Redis自带的INFO命令来检查集群状态,或者使用专门的监控工具如Redisson。简单的监控脚本示例如下:
Jedis jedis = new Jedis("localhost");
String info = jedis.info();
System.out.println(info); // 打印出Redis服务器的状态信息。
10、测试与模拟故障
在进行集群配置前,可以使用Jedis等客户端库来编写测试脚本,模拟各种故障并测试数据一致性的恢复策略。
11、使用先进的集群管理工具
对于需要更高级功能的用户,可以选择使用Redis Enterprise等商业解决方案,它们提供了更完善的集群管理工具。
推荐几个学习 Redis 教程文章
12、适应性写一致性策略
在Java中,可以使用JedisCluster提供的接口来设置不同的一致性级别,例如:
JedisCluster jedisCluster = new JedisCluster(nodes, poolConfig);
// 使用同步写操作
jedisCluster.set("foo", "bar");
通过使用JedisCluster,可以很容易地执行分布式环境下的操作,并且可以根据需要调整一致性级别。
以上就是确保Redis集群数据一致性的一些基本方法和策略。
需要注意的是,并没有一成不变的解决方案,只有根据实际业务需求和集群环境来制定适当的策略。
数据一致性问题的解决需要全方位考虑,包括硬件、网络、软件配置以及应用层面的多个维度。
希望以上分析能够帮助你更好的理解并应对Redis集群中的数据一致性问题。
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记和面经,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的阿里大佬写的刷题笔记,让我offer拿到手软
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!@小郑说编程
原文地址:https://blog.csdn.net/Wyxl990/article/details/135889523
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。