
前言
身逢乱世,未雨绸缪
一.什么是缓存击穿
说直白点,就是一个被非常频繁使用的key突然失效了请求没命中缓存,而因此造成了无数的请求落到数据库上,瞬间将数据库拖垮。而这样的key也被叫做热key!
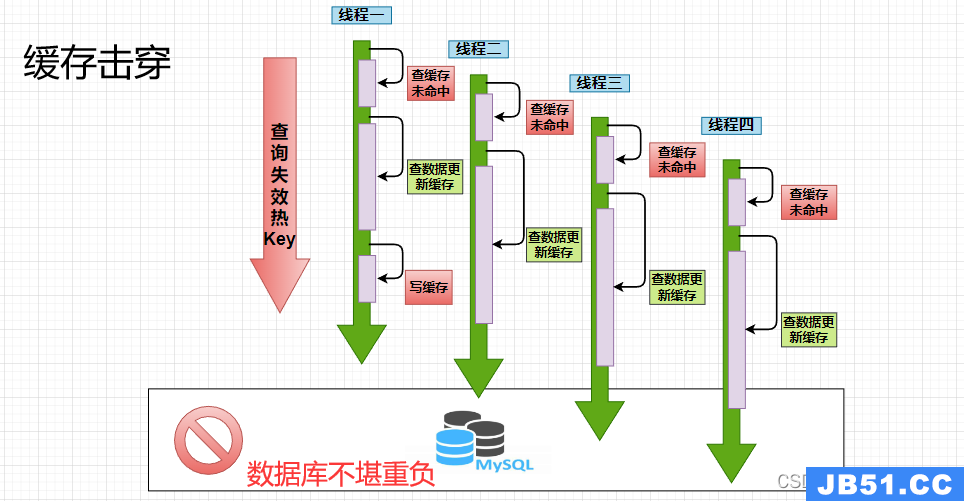
可以直观地看到,要想解决缓存击穿绝对不能让这么多线程的请求在某一时段大量去访问到数据库。
以此为基础,针对访问数据库的限制有两种解决方案:
二.基于互斥锁解决缓存击穿
对于一个访问频繁的id查询接口,可能会发生缓存击穿问题,下面通过互斥锁的方式来解决

在以前,id查询信息的接口里一般将查询的信息写到缓存里,针对是否命中缓存再去做对应的处理。而在并发的情况下,对于热Key失效的情况,大量的请求则会直接打到数据库上并试图重建缓存,很有可能打停数据库,导致服务中断。对于这样的情况往往是在未命中缓存时,最佳的处理点就在于业务中判断缓存是否命中之后的那一步操作,即“多余”的请求对数据库的访问与否。
其他线程的请求能不能去访问数据库?什么时候才能去访问数据库?
其他的线程能不能去访问数据库?——加锁,有锁才能
什么时候才能去访问数据库?——等主线程释放锁
那其他线程拿不到锁的时间该干嘛?——睡吧,等会再来
为了实现在多个线程并行的情况下只能有一个线程获得锁,我们可以使用Redis自带的setnx
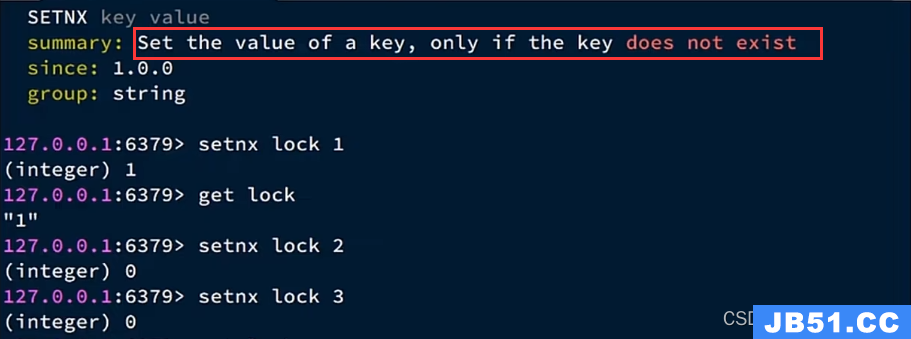
他可以保证在key不存在时可以进行写的操作,key存在时无法进行写的操作,这就完美地保证了在并发情况下只有第一个拿到锁的线程才能去写,并且他写完了之后(在不释放的前提下)别人就写不了了。
如何去获取?写个Key—Value进去
如何释放?把Key删了 del lock (通常设置一个有效期,避免长时间未释放的情况)
这样我就可以以此为条件封装两个方法,一个写key来尝试获取锁另一个删key来释放锁。就像这样:
/**
* 尝试获取锁
*
* @param key
* @return
*/
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
/**
* 释放锁
*
* @param key
*/
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
在并行情况下每当其他线程想要获取锁,来访问缓存都要通过将自己的key写到tryLock()方法里,setIfAbsent()返回false则说明有线程在在更新缓存数据,锁未释放。若返回true则说明当前线程拿到锁了可以访问缓存甚至操作缓存。
我们在下面一个热门的查询场景中用代码用代码来实现互斥锁解决缓存击穿
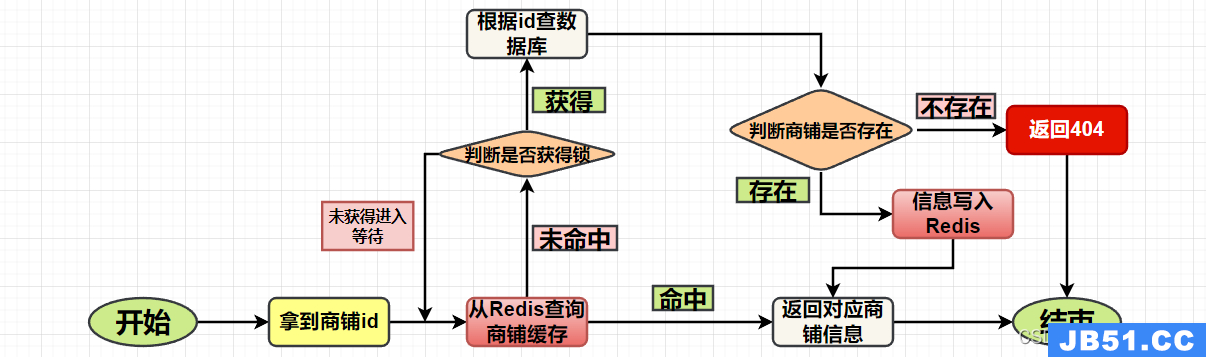
/**
* 解决缓存击穿的互斥锁
* @param id
* @return
*/
public Shop queryWithMutex(Long id) {
String key = CACHE_SHOP_KEY + id;
//1.从Redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key); //JSON格式
//2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) { //不为空就返回 此工具类API会判断""为false
//存在则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
//return Result.ok(shop);
return shop;
}
//3.判断是否为空值
if (shopJson != null) {
//返回一个空值
return null;
}
//4.缓存重建
//4.1获得互斥锁
String lockKey = "lock:shop"+id;
Shop shopById=null;
try {
boolean isLock = tryLock(lockKey);
//4.2判断是否获取成功
if (!isLock){
//4.3失败,则休眠并重试
Thread.sleep(50);
return queryWithMutex(id);
}
//4.4成功,根据id查询数据库
shopById = getById(id);
//5.不存在则返回错误
if (shopById == null) {
//将空值写入Redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
//return Result.fail("暂无该商铺信息");
return null;
}
//6.存在,写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shopById), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//7.释放互斥锁
unlock(lockKey);
}
return shopById;
}
三.基于逻辑过期解决缓存击穿
逻辑过期不是真正的过期,对于对应的Key我们并不需要去设置TTL,而是通过业务逻辑来达到一个类似于“过期”的效果。其本质还是限制落到数据库的请求数量!但前提是牺牲一致性保证可用性,还是上一个业务的接口,通过使用逻辑过期来解决缓存击穿:
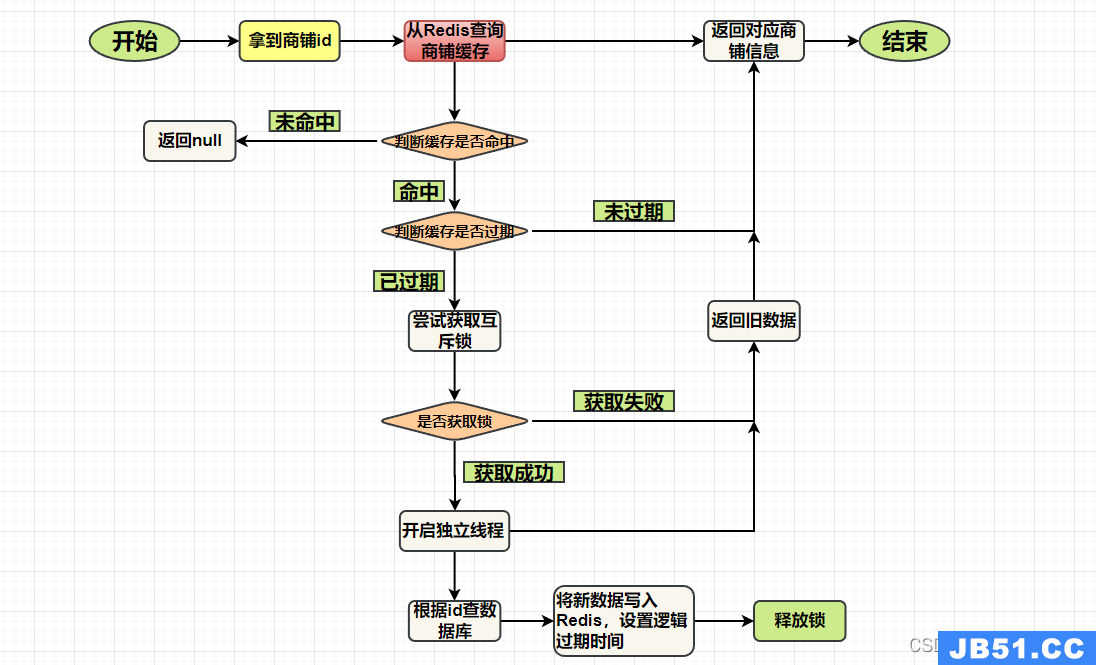
这样一来,缓存基本是会被命中的,因为我没有给缓存设置任何过期时间,并且对于Key的set都是事先选择好的,如果出现未命中的情况基本可以判断他不在选择之内,这样我就可以直接返回错误信息。那么对于命中的情况,就需要先判断逻辑时间是否过期,根据结果再来决定是否进行缓存重建。而这里的逻辑时间就是减少大量请求落到数据库的一个“关口”
看完上面这一段,相信大家还很迷惑。既然没有设置过期时间,那你为什么还要判断逻辑过期时间,怎么还存在过不过期的问题?
其实,这里所谓的逻辑过期时间只是一个类的属性字段,根本没有上升到Redis,上升到缓存的层面,是用来辅助判断查询对象的,也就是说,所谓的过期时间与缓存数据是剥离开的,所以根本不存在缓存过期的问题,自然数据库也不会有压力。
代码阶段:
为了尽可能地贴合开闭原则,不采用继承的方式来扩展原实体的属性而是通过组合的形式。
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data; //这里用Object是因为以后可能还要缓存别的数据
}
封装一个方法用来模拟更新逻辑过期时间与缓存的数据在测试类里运行起来达到数据与热的效果
/**
* 添加逻辑过期时间
*
* @param id
* @param expireTime
*/
public void saveShopRedis(Long id, Long expireTime) {
//查询店铺信息
Shop shop = getById(id);
//封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireTime));
//将封装过期时间和商铺数据的对象写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}
查询接口:
/**
* 逻辑过期解决缓存击穿
*
* @param id
* @return
*/
public Shop queryWithLogicalExpire(Long id) throws InterruptedException {
String key = CACHE_SHOP_KEY + id;
Thread.sleep(200);
//1.从Redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key); //JSON格式
//2.判断是否存在
if (StrUtil.isBlank(shopJson)) {
//不存在则直接返回
return null;
}
//3.判断是否为空值
if (shopJson != null) {
//返回一个空值
//return Result.fail("店铺不存在!");
return null;
}
//4.命中
//4.1将JSON反序列化为对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
//4.2判断是否过期
if (expireTime.isAfter(LocalDateTime.now())) {
//5.未过期则返回店铺信息
return shop;
}
//6.过期则缓存重建
//6.1获取互斥锁
String LockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(LockKey);
//6.2判断是否成功获得锁
if (isLock) {
//6.3成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
//重建缓存
this.saveShop2Redis(id, 20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//释放锁
unlock(LockKey);
}
});
}
//6.4返回商铺信息
return shop;
}
四.接口测试
可以看到通过APIfox模拟并发场景进行接口测试,平均耗时还是很短的,控制台的日志也没有频繁的去访问数据库的记录:
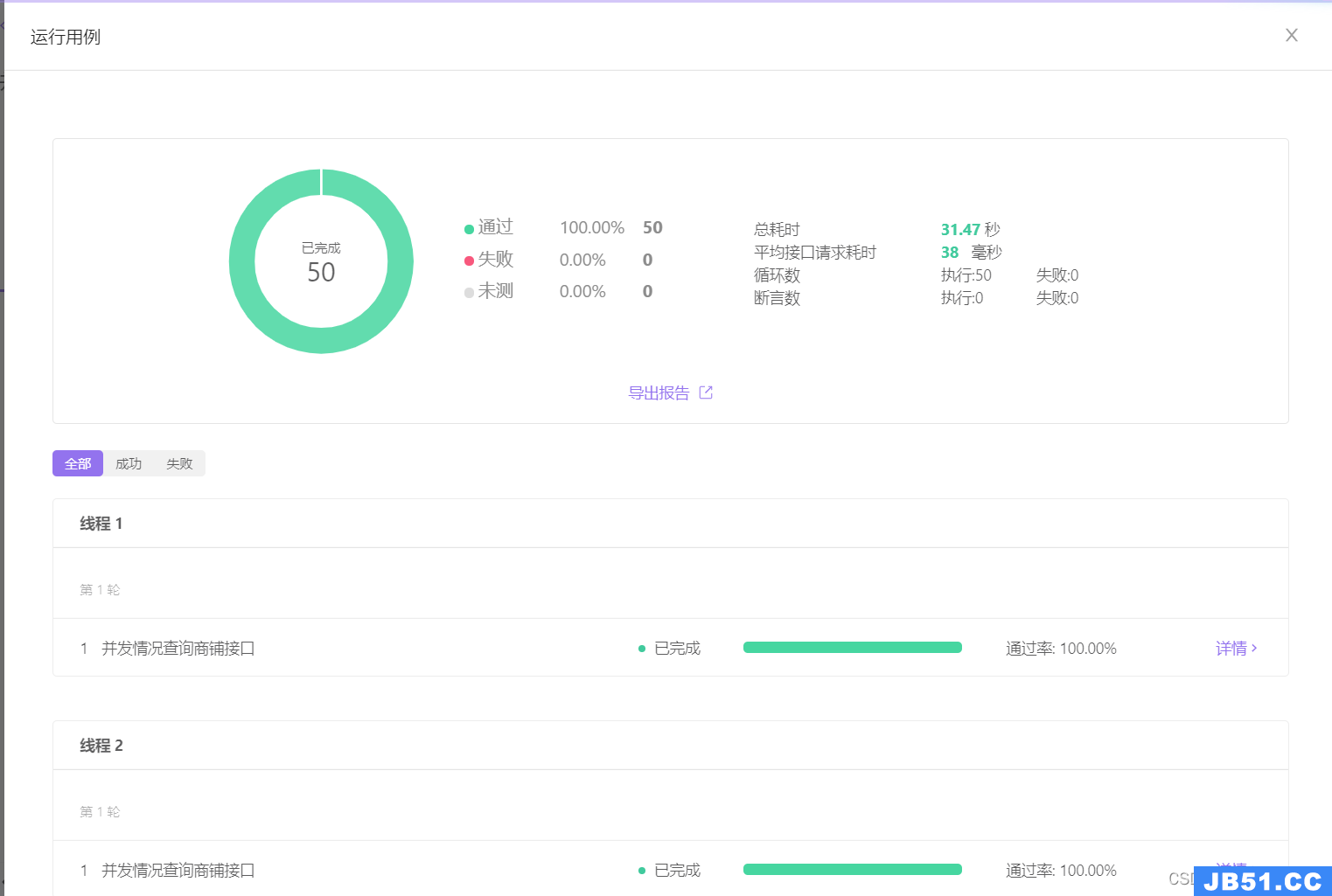
由于ApiFox不支持大量线程,我又用jmeter拿1550个线程测试了一下,接口依然都可以跑通!

看来接口在并发场景下性能还不错,QPS也挺理想
五.两者对比
可以看到,互斥锁的方式代码层面更加简单,只需要封装两个简单的方法来操作锁。而逻辑过期的方式更加复杂,需要额外增添实体类,封装方法之后还要去测试类里模拟数据预热。
相比之下,前者没有消耗额外的内存(不开新线程),数据一致性强,但是线程需要等待,性能可能不好并且有死锁的风险。后者开辟了新的线程有额外的内存消耗,牺牲一致性保证可用性,但是不要需等待性能比较好。
原文地址:https://blog.csdn.net/weixin_57535055/article/details/128572301
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。