
背景
面试官:Redis 管道技术pipeline用过吗?为什么要用?解决什么问题?使用过程中应该注意什么?
我:一键三连,内心gg了,没听说过,也不知道用来干什么的,我只能说,没了解过
Redis大多数人都用过,说起来头头是道,但是说到redis的管道技术还是很陌生,第一次我听到的时候也是一脸懵,查询官方文档Pipeline才了解它是是什么,用来解决什么问题。说白了就是批量执行redis的命令
什么是Redis pipelining
Redis 流水线是一种通过一次发出多个命令而无需等待每个命令的响应来提高性能的技术,
通过批处理 Redis 命令来优化往返时间
往返时间
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
请求流程如图:

客户端和服务器通过网络链接连接。这样的链接可以非常快(环回接口)或非常慢(通过互联网建立的连接,在两台主机之间有很多跃点)。无论网络延迟是多少,数据包从客户端传输到服务器,以及从服务器返回客户端以携带回复都需要时间。这个时间称为RTT(往返时间)。当客户端需要连续执行许多请求时(例如,将许多元素添加到同一个列表中,或者使用许多键填充数据库),很容易看出这会如何影响性能。例如,如果 RTT 时间为 250 毫秒(在 Internet 链接速度非常慢的情况下),即使服务器每秒能够处理 100k 个请求,我们也能够每秒最多处理 4 个请求。
那有什么办法优化呢?redis的pipelining 进行批处理
流程如下:
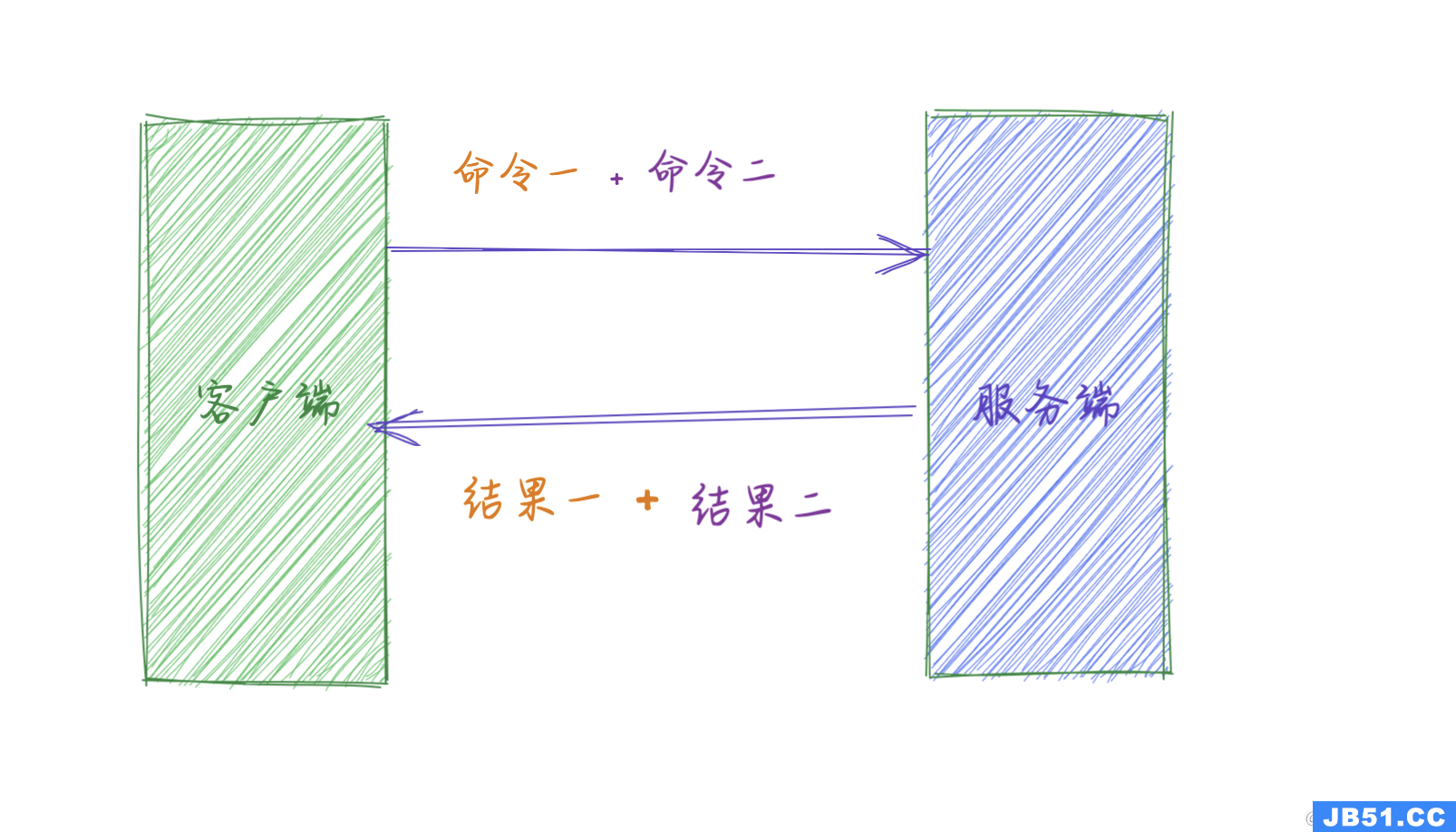
可以实现请求/响应服务器,以便即使客户端尚未读取旧响应,它也能够处理新请求。这样就可以向服务器发送多个命令,而无需等待回复,并最终一步读取回复。
这次我们不再为每次调用支付 RTT 成本,而是为三个命令支付一次 RTT 成本。
重要提示:当客户端使用管道发送命令时,服务器将被迫使用内存对回复进行排队。因此,如果您需要通过管道发送大量命令,最好将它们分批发送,每个批次包含合理的数量,例如 10k 个命令,读取回复,然后再次发送另外 10k 个命令,依此类推。速度几乎相同,但使用的额外内存最多是对这 10k 命令的回复进行排队所需的内存量
I/O开销
管道化不仅仅是减少与往返时间相关的延迟成本的一种方法,它实际上极大地提高了给定 Redis 服务器中每秒可以执行的操作数量。这是因为,如果不使用管道,从访问数据结构和生成回复的角度来看,服务每个命令的成本非常低,但从执行套接字 I/O 的角度来看,成本却非常高。这涉及到调用 read() 和 write() 系统调用,这意味着从用户态到内核态。上下文切换会带来巨大的速度损失。
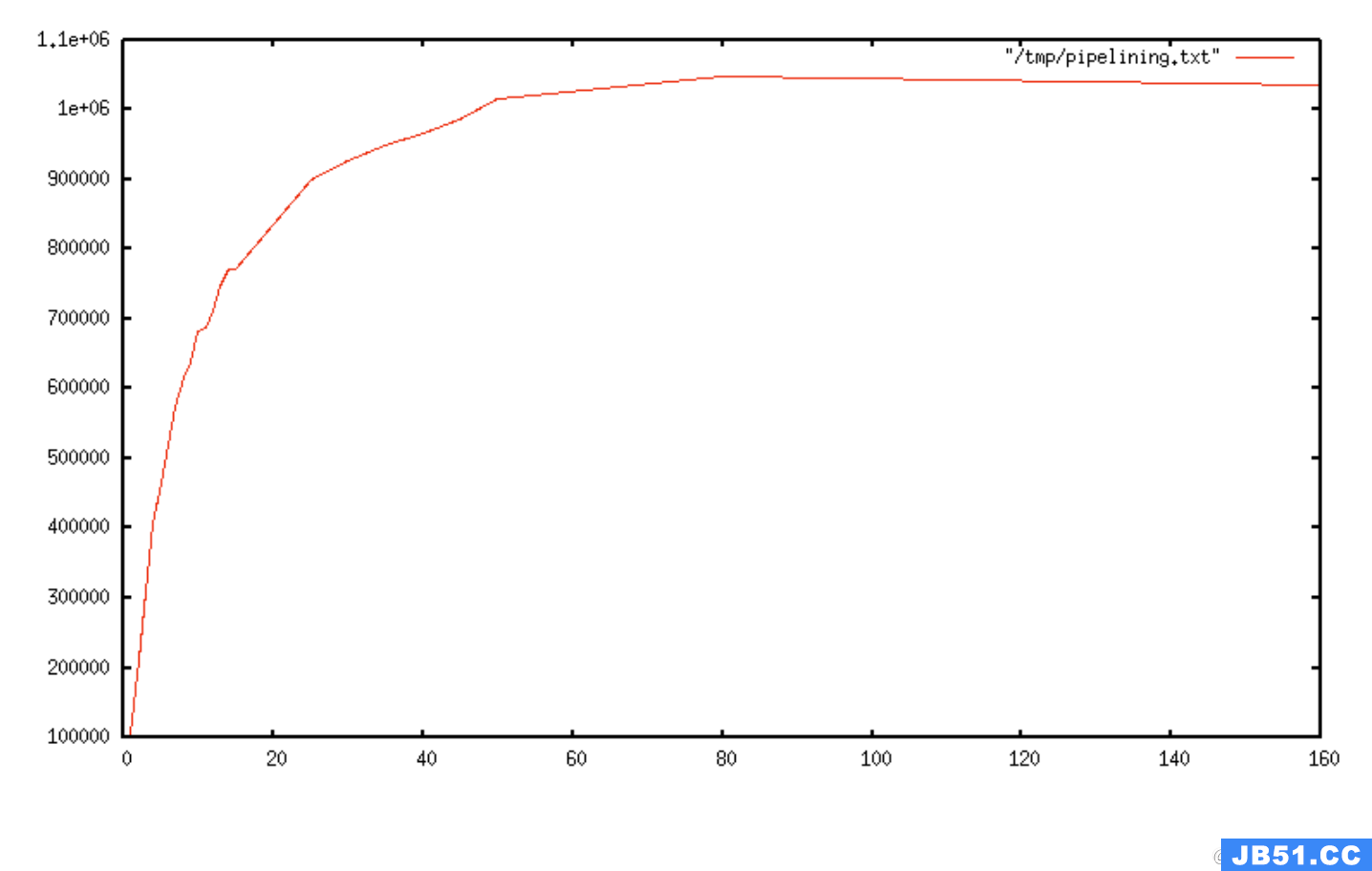
使用管道时,通常使用单个 read() 系统调用读取许多命令,并使用单个 write() 系统调用传递多个回复。因此,每秒执行的总查询数最初随着管道的延长而几乎呈线性增加,最终达到没有管道化时获得的基线的 10 倍,如图所示。
管道技术解决了什么问题?
管道技术解决了多个命令集中请求时造成网络资源浪费的问题,加快了 Redis 的响应速度,让 Redis 拥有更高的运行速度。但要注意的一点是,管道技术本质上是客户端提供的功能,而非 Redis 服务器端的功能。
管理技术的使用场景
原则上有批量执行的需求都可以用,前后执行的命令没有因果关系。我举几个我平时用到的场景:
- 项目上线后,缓存预测,如果执行的命令比较多,就可以使用管理技术
- redis优化,发现大量的key不在使用,同时没有过期时间,那我就要删掉这些key,如果使用管理技术批量删除,大大提高我的效率
管道技术需要注意的事项
管道技术虽然有它的优势,但在使用时还需注意以下几个细节:
- 发送的命令数量不会被限制,但输入缓存区也就是命令的最大存储体积为 1GB,当发送的命令超过此限制时,命令不会被执行,并且会被 Redis 服务器端断开此链接;
- 如果管道的数据过多可能会导致客户端的等待时间过长,导致网络阻塞,分批执行,不要一把梭哈,造成不必须要的事故
- 部分客户端自己本身也有缓存区大小的设置,如果管道命令没有没执行或者是执行不完整,可以排查此情况或较少管道内的命令重新尝试执行。
管道技术使用
使用 Jedis 客户端提供的 Pipeline 对象来实现管道技术。首先获取 Pipeline 对象,再为 Pipeline 对象设置需要执行的命令,最后再使用 sync() 方法或 syncAndReturnAll() 方法来统一执行这些命令
代码如下:
public static void main(String[] args) {
Jedis jedis = new Jedis("10.1.250.157",6379);
jedis.auth("google00");
// 记录执行开始时间
long beginTime = System.currentTimeMillis();
// 获取 Pipeline 对象
Pipeline pipe = jedis.pipelined();
// 设置多个 Redis 命令
for (int i = 0; i < 1000; i++) {
pipe.set("key" + i,"val" + i);
pipe.del("key" + i);
}
// 执行命令
pipe.sync();
// 记录执行结束时间
long endTime = System.currentTimeMillis();
System.out.println("执行耗时:" + (endTime - beginTime) + "毫秒");
}
执行结果:
执行耗时:102毫秒
如果要接收管道所有命令的执行结果,可使用 syncAndReturnAll() 方法,示例代码如下:
public static void main(String[] args) {
Jedis jedis = new Jedis("10.1.250.157","val" + i);
pipe.del("key" + i);
}
// 执行命令并返回结果
List<Object> res = pipe.syncAndReturnAll();
for (Object obj : res) {
// 打印结果
System.out.println(obj);
}
// 记录执行结束时间
long endTime = System.currentTimeMillis();
System.out.println("执行耗时:" + (endTime - beginTime) + "毫秒");
}
执行结果:
OK
1
OK
1
OK
1
执行耗时:103毫秒
如果不使用管理技术,效果如何?
public static void main(String[] args) {
Jedis jedis = new Jedis("10.1.250.157",6379);
jedis.auth("google00");
// 记录执行开始时间
long beginTime = System.currentTimeMillis();
// 单个 执行Redis 命令
for (int i = 0; i < 1000; i++) {
jedis.set("key" + i,"val" + i);
jedis.del("key" + i);
}
// 记录执行结束时间
long endTime = System.currentTimeMillis();
System.out.println("执行耗时:" + (endTime - beginTime) + "毫秒");
}
执行结果:
执行耗时:745毫秒
从结果看,2000个命令,管道执行需要103毫秒,普通执行需要745毫秒,70倍的速度,如果命令更多,效果更明显。
原文地址:https://blog.csdn.net/qq_33228984/article/details/135937992
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。