
多级缓存的概述
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
在Java中实现多级缓存可以通过使用不同的缓存提供者或使用一个支持多级缓存的框架来实现。以下是一个基本的实现多级缓存的步骤:
- 定义缓存级别:首先,确定你希望使用多少级别的缓存。这可以是一级、二级或更多级别,具体取决于你的需求。
- 选择缓存提供者:选择一个或多个适合你的缓存解决方案。例如,你可以使用EhCache、Redis、Guava Cache或其他类似的库。
- 实现各级缓存:
○ 本地缓存(例如,使用Guava Cache):
java`LoadingCache<KeyType, ValueType> localCache = CacheBuilder.newBuilder()
.maximumSize(100)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(
new CacheLoader<KeyType, ValueType>() {
public ValueType load(KeyType key) throws AnyException {
return createExpensiveValue(key);
}
}
);`
○ 分布式缓存(例如,使用Redis):
对于Redis,你可能需要一个客户端库,如Jedis或Lettuce。你可以设置键值对的过期时间、使用哈希表结构等。
4. 同步各级缓存:根据需要同步本地缓存和分布式缓存的数据。这可以通过定期刷新、事件监听或基于变化的同步策略来实现。
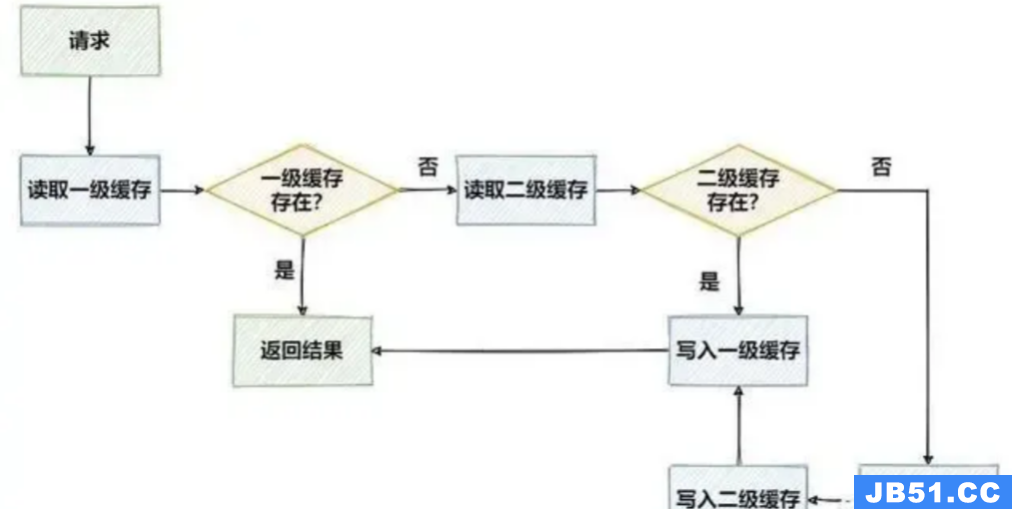
5. 使用缓存:在你的应用程序中,首先尝试从本地缓存获取数据。如果本地缓存中没有数据,则从分布式缓存中获取数据并更新本地缓存。
6. 处理缓存失效:当数据发生变化时,确保更新相关的缓存项。如果使用数据库作为数据源,可以使用数据库触发器或应用层监听来更新缓存。
7. 测试和监控:确保多级缓存正确地工作,并且性能得到提升。使用监控工具来跟踪各级缓存的命中率、延迟等指标,以便进行调整。
8. 持续优化:随着应用程序的使用和数据的增长,可能需要调整各级缓存的大小、过期时间和其他相关配置,以确保最佳性能。
9. 异常处理和日志记录:添加适当的异常处理逻辑,以便在缓存操作失败时记录日志并采取适当的行动。
10. 文档化:为你的多级缓存实现编写文档,解释各级缓存的用途、配置和最佳实践。
多级缓存的优势
那么,使用两级缓存相比单纯使用远程缓存
本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度,使用本地缓存能够减少和Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时但是在设计中,还是要考虑一些问题的,例如数据一致性问题。首先,两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
另外,如果是分布式环境下,一级缓存之间也会存在一致性问题,当一个节点下的本地缓存修改后,需要通知其他节点也刷新本地缓存中的数据,否则会出现读取到过期数据的情况,这一问题可以通过类似于Redis中的发布/订阅功能解决。
此外,缓存的过期时间、过期策略以及多线程访问的问题也都需要考虑进去,
多级缓存的优势包括:
- 提高访问速度:多级缓存可以将热点数据存储在更快速、更接近计算单元的缓存层级中,从而提高数据的访问速度。相比直接从数据库或其他远程存储获取数据,多级缓存可以大幅降低数据访问的延迟。
- 减轻后端负载:通过使用多级缓存,可以减轻后端存储系统(如数据库)的负载压力。当缓存命中时,可以避免频繁地访问后端存储系统,从而减少对存储系统的请求量,提高整个系统的并发处理能力。
- 提高系统稳定性:多级缓存可以在缓存层级之间形成冗余和备份,即使某个缓存层级发生故障或不可用,仍然可以从其他缓存层级获取数据。这样可以增加系统的容错能力,提高系统的稳定性和可靠性。
- 降低成本:多级缓存可以利用较低成本的缓存介质(如内存)来存储热点数据,而避免使用昂贵的存储介质(如固态硬盘或磁盘)。通过合理配置多级缓存,可以降低硬件和资源成本,提高系统的经济效益。
- 支持横向扩展:多级缓存可以方便地支持横向扩展。例如,可以通过增加缓存层级或者添加更多的缓存节点来扩展缓存容量和处理能力,以应对日益增长的数据访问需求。
总体来说,多级缓存可以提高系统的性能、稳定性和可扩展性,并且降低了后端存储系统的负载压力和成本。通过合理设计和配置多级缓存,可以充分利用缓存的优势,提升系统的整体性能和用户体验。
原文地址:https://blog.csdn.net/Fireworkit/article/details/135441217
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。