
redis介绍
Redis全称为Remote Dictionary Server(远程数据服务),是一款开源的基于内存的键值对存储系统,其主要被用作高性能缓存服务器使用,当然也可以作为消息中间件和Session共享等。Redis独特的键值对模型使之支持丰富的数据结构类型,即它的值可以是字符串、哈希、列表、集合、有序集合,而不像Memcached要求的键和值都是字符串。同时由于Redis是基于内存的方式,免去了磁盘I/O速度的影响,因此其读写性能极高。
redis的数据类型
redis有八种数据类型,分别有不同的用法
- String(字符串)
- List(列表)
- Set(集合)
- Zset(有序集合)
- Hash(哈希)
- Bitmaps(位图)
- HyperLogLog(基数估计)
- Geospatial(地理空间)
注意:
本文较长,如果你想快速查看某个命令或者快速定位到某个数据类型可以在以下的目录中点击如果你在阅读中发现有什么问题欢迎随时与我交流或者在评论区中留言
索引
- redis介绍
- redis的数据类型
- 1.String(字符串)
- 结构图
- 相关命令
- SET key value
- GET key
- GETRANGE key start end
- SETBIT key offset value
- GETBIT key offset
- MSET key value [key value ...]
- MGET key1 [key2..]
- GETSET key value
- SETEX key seconds value
- SETNX key value
- SETRANGE key offset value
- STRLEN key
- MSETNX key value [key value ...]
- PSETEX key milliseconds value
- INCR key
- INCRBY key increment
- INCRBYFLOAT key increment
- DECR key
- DECRBY key decrement
- APPEND key value
- 2.List(列表)
- 3. Set(集合)
- 4.Zset(有序集合)
- 结构图
- 相关命令
- ZADD:向有序集合添加成员
- ZCARD:获取有序集合的成员数
- ZCOUNT:计算指定分数范围内的成员数
- ZINCRBY:增加成员的分数
- ZLEXCOUNT:计算指定字典区间内的成员数
- ZRANGE:获取指定索引范围内的成员
- ZRANGEBYLEX:获取指定字典区间内的成员
- ZRANGEBYSCORE:获取指定分数范围内的成员
- ZRANK:获取成员的排名
- ZREM:移除成员
- ZREMRANGEBYLEX:移除指定字典区间内的成员
- ZREMRANGEBYRANK:移除指定排名范围内的成员
- ZREMRANGEBYSCORE:移除指定分数范围内的成员
- ZREVRANGE:获取指定索引范围内的成员(按分数从高到低)
- ZREVRANGEBYSCORE:获取指定分数范围内的成员(按分数从高到低)
- ZREVRANK:获取成员的排名(按分数从高到低)
- ZSCORE:获取成员的分数
- ZINTERSTORE:计算多个有序集合的交集并存储结果
- ZUNIONSTORE:计算多个有序集合的并集并存储结果
- ZSCAN:迭代有序集合中的元素
- 5.Hash(哈希)
- 6.Bitmaps(位图)
- 7.HyperLogLog(基数统计)
- 8.Geospatial(地理空间)
1.String(字符串)
String 类型是 Redis 最基本的数据类型,String 类型的值最大能存储 512MB。
String类型一般用于缓存、限流、计数器、分布式锁、分布式Session。
结构图

相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | SET key value | 设置指定 key 的值 |
| 2 | GET key | 获取指定 key 的值 |
| 3 | GETRANGE key start end | 返回 key 中字符串值的子字符,end=-1时表示全部 |
| 4 | SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit) |
| 5 | GETBIT key offset | 对 key 所储存的字符串值,获取指定偏移量上的位(bit) |
| 6 | MSET key value [key value …] | 同时设置一个或多个 key-value 对 |
| 7 | MGET key1 [key2…] | 获取所有(一个或多个)给定 key 的值 |
| 8 | GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| 9 | SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| 10 | SETNX key value | 只有在 key 不存在时设置 key 的值 |
| 11 | SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 |
| 12 | STRLEN key | 返回 key 所储存的字符串值的长度 |
| 13 | MSETNX key value [key value …] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
| 14 | PSETEX key milliseconds value | 与 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间 |
| 15 | INCR key | 将 key 中储存的数字值增一 |
| 16 | INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) |
| 17 | INCRBYFLOAT key increment | 将 key 所储存的值加上给定的浮点增量值(increment) |
| 18 | DECR key | 将 key 中储存的数字值减一 |
| 19 | DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) |
| 20 | APPEND key value | 如果 key 已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到该 key 原来值 value 的末尾 |
SET key value
设置指定 key 的值。
SET mykey1 helloIamYourFather
GET key
获取指定 key 的值。
GET mykey1

GETRANGE key start end
返回 key 中字符串值的子字符,从下标为0开始,到end结束,end=-1 时表示全部。
GETRANGE mykey1 5 16

SETBIT key offset value
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
SETBIT mykey 2 1
GETBIT key offset
对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
GETBIT mykey1 3

MSET key value [key value …]
同时设置一个或多个 key-value 对。
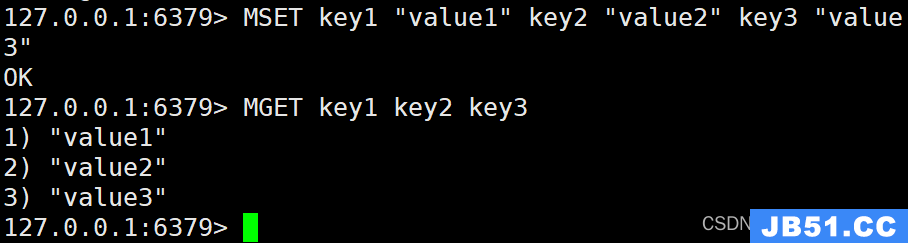
MSET key1 "value1" key2 "value2" key3 "value3"
MGET key1 [key2…]
获取所有(一个或多个)给定 key 的值。
MGET key1 key2 key3
GETSET key value
将给定 key 的值设为 value,并返回 key 的旧值(old value)。
GETSET mykey1 iloveyou

SETEX key seconds value
将值 value 关联到 key,并将 key 的过期时间设为 seconds(以秒为单位)。
SETEX mykey1 10 sb

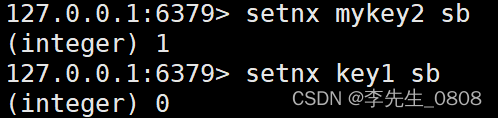
SETNX key value
只有在 key 不存在时设置 key 的值。
SETNX mykey1 sb
先设置一个不存在的key
在设置一个存在的key
结果如下
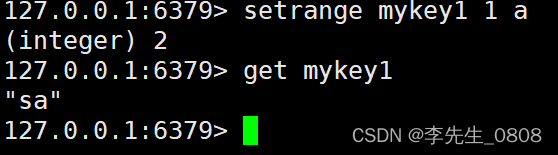
SETRANGE key offset value
用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。
SETRANGE mykey1 1 a
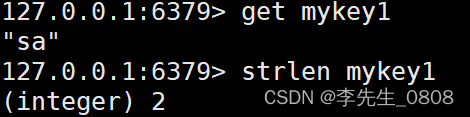
STRLEN key
返回 key 所储存的字符串值的长度。
STRLEN mykey1
MSETNX key value [key value …]
同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
MSETNX key4 "value1" key5 "value2" key6 "value3"

PSETEX key milliseconds value
与 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间。
PSETEX mykey1 1000 "Hello Redis"

INCR key
将 key 中储存的数字值增一。
INCR key3
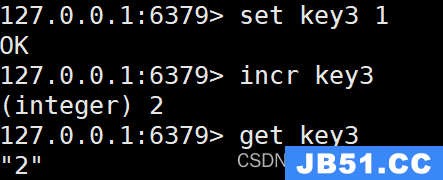
INCRBY key increment
将 key 所储存的值加上给定的增量值(increment)。
INCRBY key3 5

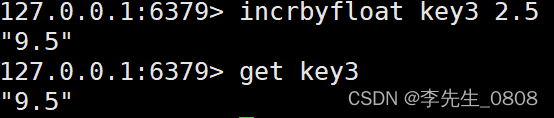
INCRBYFLOAT key increment
将 key 所储存的值加上给定的浮点增量值(increment)。
INCRBYFLOAT key3 2.5
DECR key
将 key 中储存的数字值减一。
如果值是带小数点的数这个就无法使用了

DECR key4

DECRBY key decrement
key 所储存的值减去给定的减量值(decrement)。
DECRBY key4 3

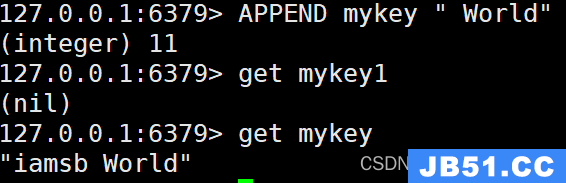
APPEND key value
如果 key 已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到该 key 原来值 value 的末尾。
APPEND mykey " World"
2.List(列表)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 232 - 1 个元素 (4294967295,每个列表超过40亿个元素)。
List类型一般用于关注人、简单队列等。
结构图
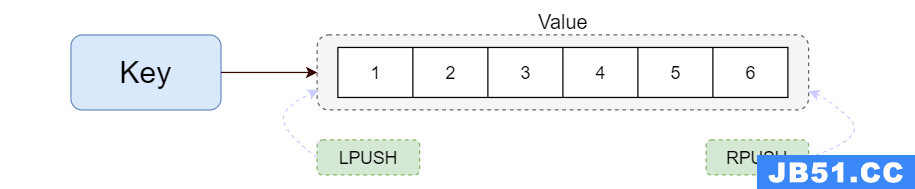
相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | LPUSH key value1 [value2] | 将一个或多个值插入到列表头部 |
| 2 | LPOP key | 移出并获取列表的第一个元素 |
| 3 | LRANGE key start stop | 获取列表指定范围内的元素 |
| 4 | LPUSHX key value | 将一个值插入到已存在的列表头部 |
| 5 | RPUSH key value1 [value2] | 在列表中添加一个或多个值 |
| 6 | RPOP key | 移除列表的最后一个元素,返回值为移除的元素 |
| 7 | RPUSHX key value | 为已存在的列表添加值 |
| 8 | LLEN key | 获取列表长度 |
| 9 | LINSERT key BEFORE|AFTER pivot value | 在列表的元素前或者后插入元素 |
| 10 | LINDEX key index | 通过索引获取列表中的元素 |
| 11 | LSET key index value | 通过索引设置列表元素的值 |
| 12 | LREM key count value | 移除列表元素 |
| 13 | LTRIM key start stop | 对一个列表进行修剪,就是让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
| 14 | BLPOP key1 [key2 ] timeout | 移出并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 15 | BRPOP key1 [key2 ] timeout | 移出并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| 16 | BRPOPLPUSH source destination timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它;如果列表没有元素会阻塞列表直到等待超时或发现可lpu弹出元素为止 |
| 17 | RPOPLPUSH source destination | 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
1. LPUSH和RPUSH命令
LPUSH和RPUSH命令用于将一个或多个元素分别从列表的左侧和右侧插入。以下是它们的使用示例:
LPUSH mylist "apple"
LPUSH mylist "banana"
RPUSH mylist "orange"
执行上述命令后,列表"mylist"的元素顺序为:“banana”、“apple”、“orange”。
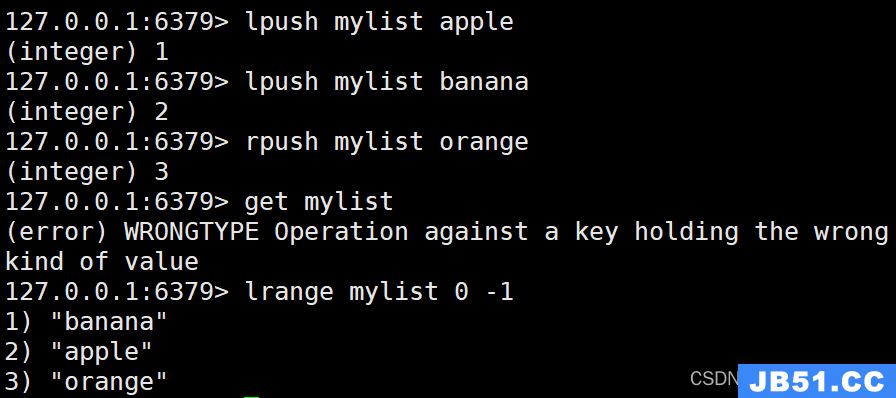
2. LPOP和RPOP命令
LPOP和RPOP命令用于从列表的左侧和右侧移除并返回一个元素。以下是它们的使用示例:
LPOP mylist
RPOP mylist
执行上述命令后,列表"mylist"的元素顺序为:“apple”。
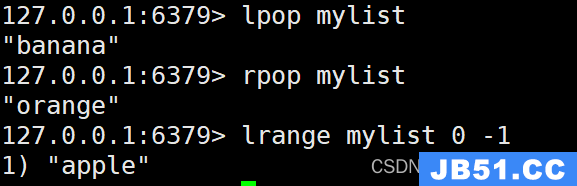
3. LLEN命令
LLEN命令用于获取列表的长度(即元素的个数)。以下是它的使用示例:
LLEN mylist
执行上述命令后,返回列表"mylist"的长度。

4. LRANGE命令
LRANGE命令用于获取列表中指定范围的元素。以下是它的使用示例:
LRANGE mylist 0 1
执行上述命令后,返回列表"mylist"中索引从0到1的元素。

如果想显示所有可以将最后一位数字换成-1
LRANGE mylist 0 -1
5. LINDEX命令
LINDEX命令用于获取列表中指定索引位置的元素(从0开始)。以下是它的使用示例:
LINDEX mylist 2
执行上述命令后,返回列表"mylist"中索引为2的元素。
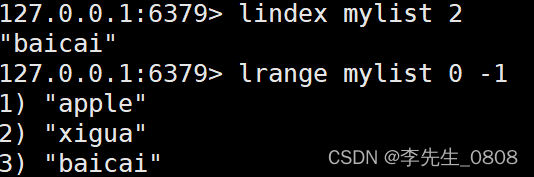
6. LSET命令
LSET命令用于设置列表中指定索引位置的元素的值。以下是它的使用示例:
LSET mylist 0 pingguo
执行上述命令后,将列表"mylist"中索引为0的元素设置为"pingguo"。
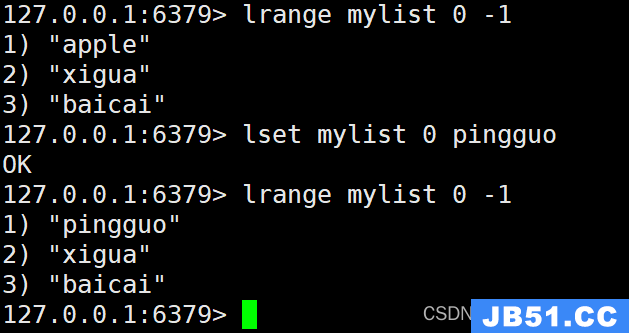
7. LREM命令
LREM命令用于从列表中移除指定数量的匹配元素。以下是它的使用示例:
LREM mylist 2 pingguo
执行上述命令后,将列表"mylist"中前两个匹配元素"pingguo"移除。
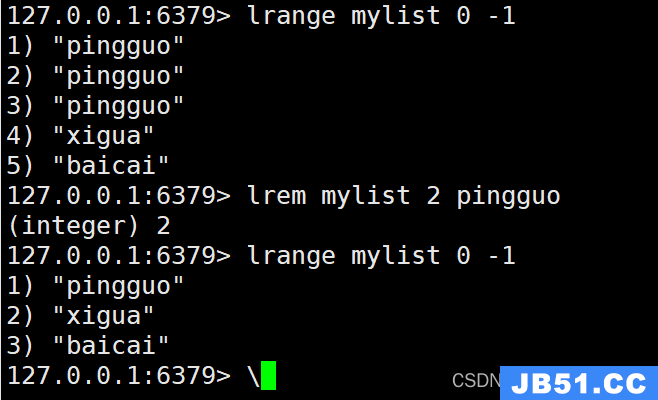
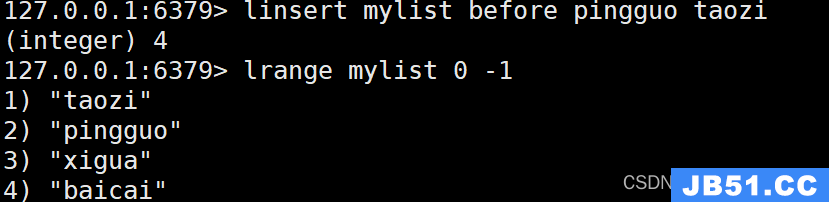
8. LINSERT命令
LINSERT key BEFORE|AFTER pivot value
LINSERT命令用于在列表的指定元素之前或之后插入一个新元素。以下是它的使用示例:
LINSERT mylist BEFORE "pingguo" "taozi"
执行上述命令后,将在列表"mylist"中"apple"元素之前插入新元素"taozi"。
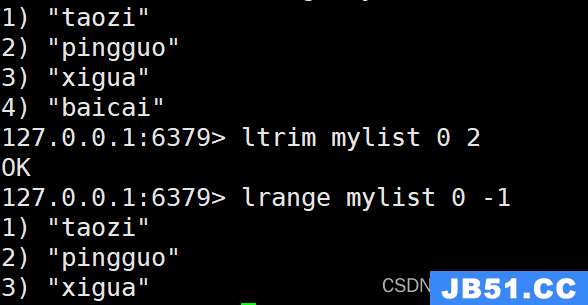
9. LTRIM命令
LTRIM命令用于修剪列表,只保留指定范围内的元素。以下是它的使用示例:
LTRIM mylist 0 2
执行上述命令后,将列表"mylist"中只保留索引从0到1的元素。
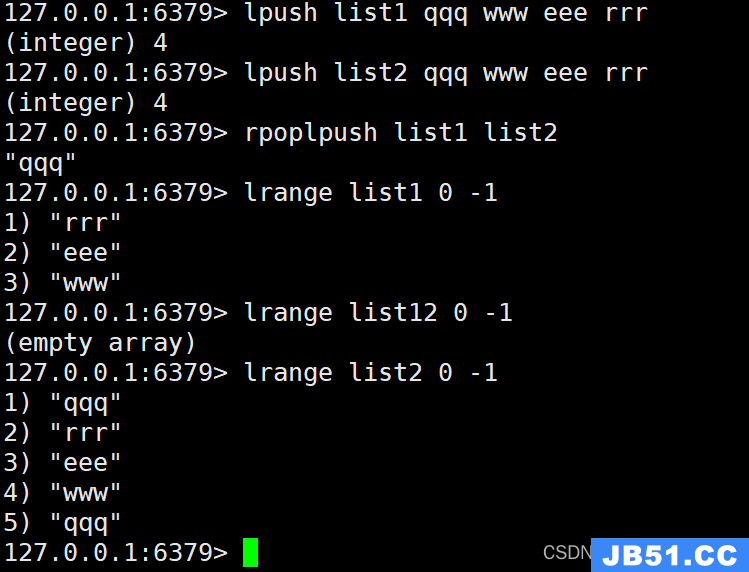
10. RPOPLPUSH命令
RPOPLPUSH命令用于从一个列表的右侧移除一个元素,并将其添加到另一个列表的左侧。以下是它的使用示例:
RPOPLPUSH list1 list2
执行上述命令后,将列表"list1"的最右侧元素移除,并将其添加到列表"list2"的最左侧。
11. BLPOP和BRPOP命令
BLPOP和BRPOP命令用于阻塞地从左侧或右侧弹出一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。以下是它们的使用示例:
BLPOP mylist 10
BRPOP mylist 10
执行上述命令后,将阻塞地从列表"mylist"的左侧或右侧弹出一个元素,最长等待时间为10秒。

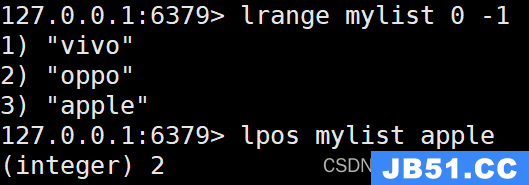
12. LPOS命令
LPOS命令用于获取列表中指定元素的索引位置。以下是它的使用示例:
LPOS mylist "apple"
执行上述命令后,返回列表"mylist"中元素"apple"的索引位置。
3. Set(集合)
Redis 的 Set 是 String 类型的无序集合。集合中成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 232 - 1 (4294967295,每个集合可存储40多亿个成员)。
Set类型一般用于赞、踩、标签、好友关系等。
结构图

相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | SADD key member1 [member2] | 向集合添加一个或多个成员 |
| 2 | SMEMBERS key | 返回集合中的所有成员 |
| 3 | SCARD key | 获取集合的成员数 |
| 4 | SRANDMEMBER key [count] | 返回集合中一个或多个随机数 |
| 5 | SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| 6 | SREM key member1 [member2] | 移除集合中一个或多个成员 |
| 7 | SDIFF key1 [key2] | 返回给定所有集合的差集 |
| 8 | SDIFFSTORE destination key1 [key2] | 返回给定所有集合的差集并存储在 destination 中 |
| 9 | SINTER key1 [key2] | 返回给定所有集合的交集 |
| 10 | SINTERSTORE destination key1 [key2] | 返回给定所有集合的交集并存储在 destination 中 |
| 11 | SUNION key1 [key2] | 返回所有给定集合的并集 |
| 12 | SUNIONSTORE destination key1 [key2] | 所有给定集合的并集存储在 destination 集合中 |
| 13 | SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 |
| 14 | SPOP key | 移除并返回集合中的一个随机元素 |
| 15 | SSCAN key cursor [MATCH pattern] [COUNT count] | 迭代集合中的元素 |
SADD 命令
SADD 命令用于向集合中添加一个或多个成员。
命令语法:
SADD key member1 [member2]
示例:
SADD myset "banana" "orange"
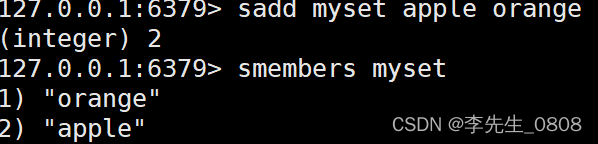
SMEMBERS 命令
SMEMBERS 命令用于返回集合中的所有成员。
命令语法:
SMEMBERS key
示例:
SMEMBERS myset
SCARD 命令
SCARD 命令用于获取集合的成员数。
命令语法:
SCARD key
示例:
SCARD myset

SRANDMEMBER 命令
SRANDMEMBER 命令用于返回集合中一个或多个随机成员。
命令语法:
SRANDMEMBER key [count]
示例:
SRANDMEMBER myset

SISMEMBER 命令
SISMEMBER 命令用于判断 member 元素是否是集合 key 的成员。
命令语法:
SISMEMBER key member
示例:
SISMEMBER myset "apple"
SISMEMBER myset taozi

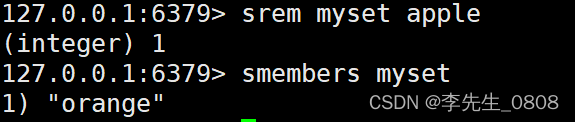
SREM 命令
SREM 命令用于移除集合中一个或多个成员。
命令语法:
SREM key member1 [member2]
示例:
SREM myset apple
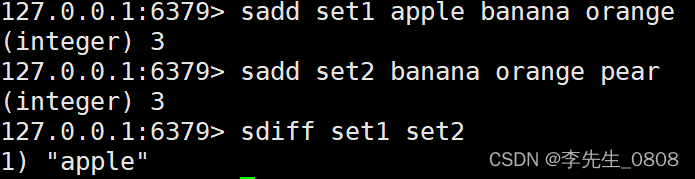
SDIFF 命令
SDIFF 命令用于返回给定所有集合的差集。
命令语法:
SDIFF key1 [key2]
示例:
SADD set1 "apple" "banana" "orange"
SADD set2 "banana" "orange" "pear"
SDIFF set1 set2
输出:
1) "apple"
SDIFFSTORE 命令
SDIFFSTORE 命令用于返回给定所有集合的差集并存储在 destination 中。
命令语法:
SDIFFSTORE destination key1 [key2]
示例:
SADD set1 "apple" "banana" "orange"
SADD set2 "banana" "orange" "pear"
SDIFFSTORE diffset set1 set2
SINTER 命令
SINTER 命令用于返回给定所有集合的交集。
命令语法:
SINTER key1 [key2]
示例:
SADD set1 "apple" "banana" "orange"
SADD set2 "banana" "orange" "pear"
SINTER set1 set2
输出:
1) "banana"
2) "orange"

SINTERSTORE 命令
SINTERSTORE 命令用于返回给定所有集合的交集并存储在 destination 中。
命令语法:
SINTERSTORE destination key1 [key2]
示例:
SADD set1 "apple" "banana" "orange"
SADD set2 "banana" "orange" "pear"
SINTERSTORE set1set2 set1 set2

SUNION 命令
SUNION 命令用于返回所有给定集合的并集。
命令语法:
SUNION key1 [key2]
示例:
SADD set1 "apple" "banana" "orange"
SADD set2 "banana" "orange" "pear"
SUNION set1 set2
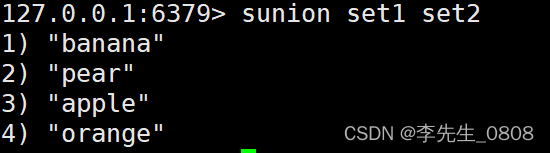
SUNIONSTORE 命令
SUNIONSTORE 命令用于将所有给定集合的并集存储在 destination 集合中。
命令语法:
SUNIONSTORE destination key1 [key2]
示例:
SADD set1 "apple" "banana" "orange"
SADD set2 "banana" "orange" "pear"
SUNIONSTORE unions1s2 set1 set2

SMOVE 命令
SMOVE 命令用于将 member 元素从 source 集合移动到 destination 集合。
命令语法:
SMOVE source destination member
示例:
SADD set1 "apple" "banana"
SADD set2 "orange"
SMOVE set1 set2 "banana"
SPOP 命令
SPOP 命令用于移除并返回集合中的一个随机元素。
命令语法:
SPOP key
示例:
SADD myset "apple" "banana" "orange"
SPOP myset
输出:
"banana"
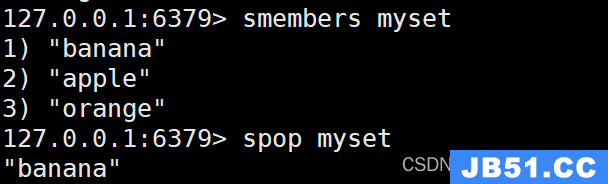
SSCAN 命令
SSCAN 命令用于迭代集合中的元素。
它可以逐批地返回集合中的元素,以便在大型集合中进行分批处理或分页浏览。
- SSCAN命令的语法如下:
SSCAN key cursor [MATCH pattern] [COUNT count]
key:要进行遍历的集合的键名。cursor:游标,用于迭代遍历集合。初始值通常为0,之后的每次迭代都会返回一个新的游标。MATCH pattern(可选):用于匹配集合中的元素的模式。只有与模式匹配的元素才会被返回。COUNT count(可选):每次迭代返回的元素数量。默认情况下,Redis会根据实际情况返回一个合适的数量。
- 返回值:
SSCAN命令的返回值是一个包含两个元素的数组。第一个元素是下一次迭代的新游标,你可以将其用作下一次调用SSCAN命令时的游标参数。第二个元素是一个数组,包含当前迭代批次返回的元素。
- 举个例子:
假设你有一个包含100个元素的集合,你想要遍历这个集合并对每个元素进行处理。由于集合很大,一次性返回所有元素可能会对性能产生负面影响,而且可能会占用大量的内存。
使用SSCAN命令,你可以通过设置合适的COUNT参数来控制每次迭代返回的元素数量。然后,你可以使用返回的游标值作为下一次调用SSCAN命令的游标参数,以继续从上一次迭代结束的位置开始遍历集合。
例如:假设你的集合名为"myset",初始游标为0,并且每次迭代返回10个元素。你可以执行以下步骤进行遍历:
- 执行SSCAN命令:
SSCAN myset 0 COUNT 10,它将返回游标为10的新游标和前10个元素。 - 使用返回的新游标
10继续调用SSCAN命令:SSCAN myset 10 COUNT 10,它将返回游标为20的新游标和接下来的10个元素。 - 重复上述步骤,直到返回的新游标为0,表示遍历结束。
当然,我可以为每个命令提供一个简单的使用示例。以下是 Redis 有序集合操作命令的使用示例:
4.Zset(有序集合)
Redis 有序集合和集合一样也是string类型元素的集合且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数 。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295,每个集合可存储40多亿个成员)。
Zset类型一般用于排行榜等。
结构图

相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key | 获取有序集合的成员数 |
| 3 | ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| 4 | ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
| 5 | ZLEXCOUNT key min max | 在有序集合中计算指定字典区间内成员数量 |
| 6 | ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合指定区间内的成员 |
| 7 | ZRANGEBYLEX key min max [LIMIT offset count] | 通过字典区间返回有序集合的成员 |
| 8 | ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数返回有序集合指定区间内的成员 |
| 9 | ZRANK key member | 返回有序集合中指定成员的索引 |
| 10 | ZREM key member [member …] | 移除有序集合中的一个或多个成员 |
| 11 | ZREMRANGEBYLEX key min max | 移除有序集合中给定的字典区间的所有成员 |
| 12 | ZREMRANGEBYRANK key start stop | 移除有序集合中给定的排名区间的所有成员 |
| 13 | ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
| 14 | ZREVRANGE key start stop [WITHSCORES] | 返回有序集中指定区间内的成员,通过索引,分数从高到低 |
| 15 | ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集中指定分数区间内的成员,分数从高到低排序 |
| 16 | ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| 17 | ZSCORE key member | 返回有序集中,成员的分数值 |
| 18 | ZINTERSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中 |
| 19 | ZUNIONSTORE destination numkeys key [key …] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
| 20 | ZSCAN key cursor [MATCH pattern] [COUNT count] | 迭代有序集合中的元素(包括元素成员和元素分值) |
ZADD:向有序集合添加成员
命令模板:
ZADD key score1 member1 [score2 member2]
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZCARD:获取有序集合的成员数
命令模板:
ZCARD key
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZCARD myset
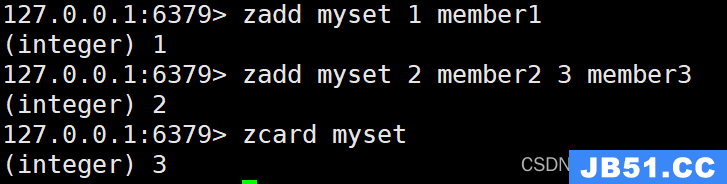
ZCOUNT:计算指定分数范围内的成员数
命令模板:
ZCOUNT key min max
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZCOUNT myset 1 2

ZINCRBY:增加成员的分数
命令模板:
ZINCRBY key increment member
示例:
ZADD myset 1 member1
ZINCRBY myset 5 member1

ZLEXCOUNT:计算指定字典区间内的成员数
命令模板:
ZLEXCOUNT key min max
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZLEXCOUNT myset [member1 [member3

ZRANGE:获取指定索引范围内的成员
命令模板:
ZRANGE key start stop [WITHSCORES]
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZRANGE myset 0 1

ZRANGEBYLEX:获取指定字典区间内的成员
命令模板:
ZRANGEBYLEX key min max [LIMIT offset count]
示例:
ZADD myset1 1 a 2 b 3 c 4 d
ZRANGEBYLEX myset1 [a [c

ZRANGEBYSCORE:获取指定分数范围内的成员
命令模板:
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT]
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZRANGEBYSCORE myset 1 2

ZRANK:获取成员的排名
命令模板:
ZRANK key member
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZRANK myset member2

ZREM:移除成员
命令模板:
ZREM key member [member …]
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZREM myset member1

ZREMRANGEBYLEX:移除指定字典区间内的成员
命令模板:
ZREMRANGEBYLEX key min max
示例:
ZADD myset2 1 a 2 b 3 c 4 d
ZREMRANGEBYLEX myset2 [a [c
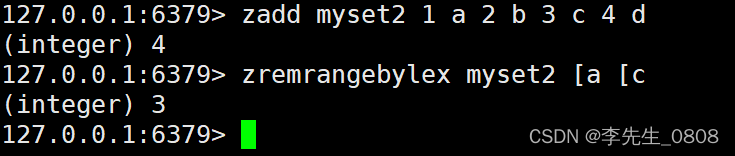
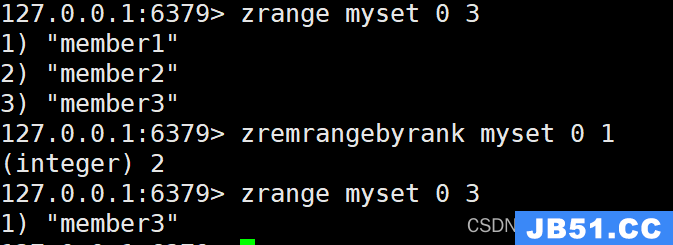
ZREMRANGEBYRANK:移除指定排名范围内的成员
命令模板:
ZREMRANGEBYRANK key start stop
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZREMRANGEBYRANK myset 0 1
ZREMRANGEBYSCORE:移除指定分数范围内的成员
命令模板:
ZREMRANGEBYSCORE key min max
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZREMRANGEBYSCORE myset 1 2

ZREVRANGE:获取指定索引范围内的成员(按分数从高到低)
命令模板:
ZREVRANGE key start stop [WITHSCORES]
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZREVRANGE myset 0 1

ZREVRANGEBYSCORE:获取指定分数范围内的成员(按分数从高到低)
命令模板:
ZREVRANGEBYSCORE key max min [WITHSCORES]
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZREVRANGEBYSCORE myset 3 1

ZREVRANK:获取成员的排名(按分数从高到低)
命令模板:
ZREVRANK key member
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZREVRANK myset member2

ZSCORE:获取成员的分数
命令模板:
ZSCORE key member
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZSCORE myset member1

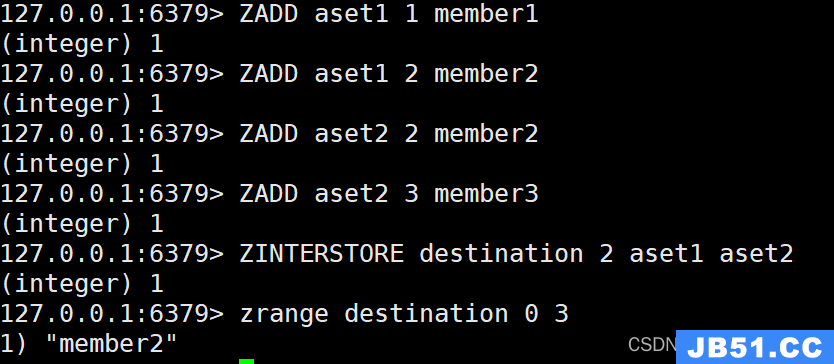
ZINTERSTORE:计算多个有序集合的交集并存储结果
命令模板:
ZINTERSTORE destination numkeys key [key …]
示例:
ZADD aset1 1 member1
ZADD aset1 2 member2
ZADD aset2 2 member2
ZADD aset2 3 member3
ZINTERSTORE destination 2 aset1 aset2
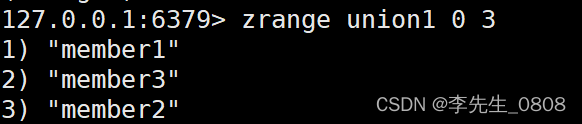
ZUNIONSTORE:计算多个有序集合的并集并存储结果
命令模板:
ZUNIONSTORE destination numkeys key [key …]
示例:
ZADD aset1 1 member1
ZADD aset1 2 member2
ZADD aset2 2 member2
ZADD aset2 3 member3
ZUNIONSTORE union1 2 aset1 aset2
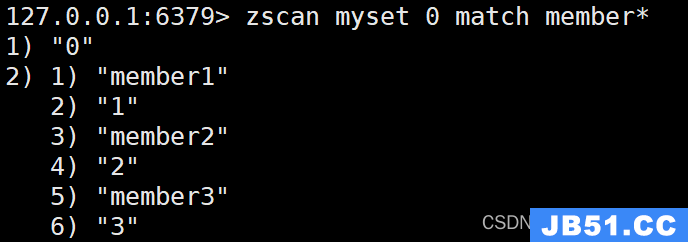
ZSCAN:迭代有序集合中的元素
命令模板:
ZSCAN key cursor [MATCH pattern] [COUNT count]key:指定要迭代的有序集合的键名。cursor:迭代的起始游标。在第一次调用时,你可以将其设置为0,后续调用会返回新的游标,你需要使用返回的游标来进行下一次迭代。MATCH pattern(可选):用于匹配元素的模式。只有与模式匹配的元素才会被返回。模式可以包含通配符和?,其中匹配零个或多个字符,?匹配一个字符。COUNT count(可选):指定每次迭代返回的最大元素数量。这可以帮助你控制每次迭代的负载。
- 命令的返回值
是一个包含两个元素的数组,形式为[cursor,[element1,element2,…]]。其中:
cursor:下一次迭代的游标,你需要将其作为参数传递给下一次调用。element1,...:当前迭代批次中的元素数组。
迭代的意思在上一个set数据类型中已经解释过,可以在上个set数据类型的最后一个方法中查看他的意义和用法
示例:
ZADD myset 1 member1
ZADD myset 2 member2 3 member3
ZSCAN myset 0 MATCH member*
5.Hash(哈希)
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
Hash类型一般用于存储用户信息、用户主页访问量、组合查询等。
结构图
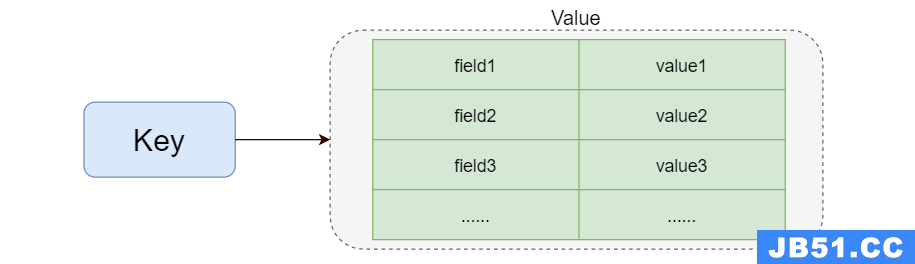
相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| 2 | HGET key field | 获取存储在哈希表中指定字段的值 |
| 3 | HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| 4 | HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| 5 | HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
| 6 | HKEYS key | 获取所有哈希表中的字段 |
| 7 | HVALS key | 获取哈希表中所有值 |
| 8 | HLEN key | 获取哈希表中字段的数量 |
| 9 | HMGET key field1 [field2] | 获取所有给定字段的值 |
| 10 | HMSET key field1 value1 [field2 value2] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| 11 | HINCRBY key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment |
| 12 | HINCRBYFLOAT key field increment | 为哈希表 key 中的指定字段的浮点数值加上增量 increment |
| 13 | HDEL key field1 [field2] | 删除一个或多个哈希表字段 |
| 14 | HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对 |
HSET:设置哈希表字段的值
命令模板:
HSET key field value
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HGET:获取哈希表字段的值
命令模板:
HGET key field
示例:
HSET myhash field1 value1
HGET myhash field1

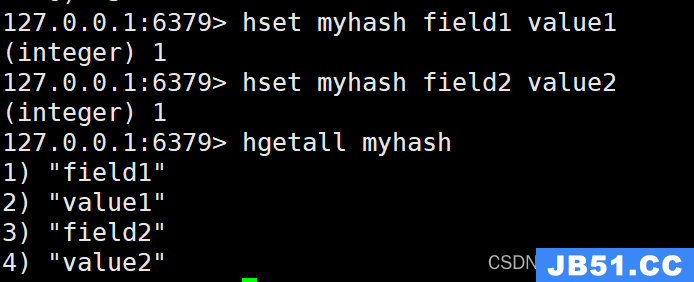
HGETALL:获取哈希表的所有字段和值
命令模板:
HGETALL key
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HGETALL myhash
HEXISTS:检查哈希表字段是否存在
命令模板:
HEXISTS key field
示例:
HSET myhash field1 value1
HEXISTS myhash field1

HSETNX:设置哈希表字段的值(仅当字段不存在时)
命令模板:
HSETNX key field value
示例:
HSETNX myhash field1 value1
HSETNX myhash field1 value2
存在

不存在

HKEYS:获取哈希表的所有字段
命令模板:
HKEYS key
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HKEYS myhash

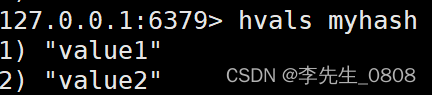
HVALS:获取哈希表的所有值
命令模板:
HVALS key
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HVALS myhash
HLEN:获取哈希表字段的数量
命令模板:
HLEN key
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HLEN myhash

HMGET:获取哈希表指定字段的值
命令模板:
HMGET key field1 [field2]
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HMGET myhash field1 field2

HMSET:设置哈希表多个字段的值
命令模板:
HMSET key field1 value1 [field2 value2]
示例:
HMSET myhash5 field1 value1 field2 value2

HINCRBY:增加哈希表指定字段的整数值
命令模板:
HINCRBY key field increment
示例:
HSET myhash6 field1 10
HINCRBY myhash6 field1 5

HINCRBYFLOAT:增加哈希表指定字段的浮点数值
命令模板:
HINCRBYFLOAT key field increment
示例:
HINCRBYFLOAT myhash6 field1 1.4

HDEL:删除哈希表中的一个或多个字段
命令模板:
HDEL key field1 [field2]
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HDEL myhash field1

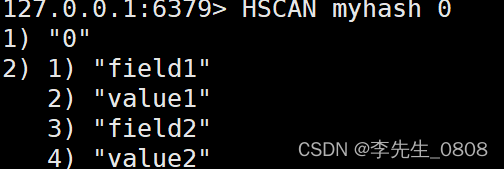
HSCAN:迭代哈希表中的键值对
命令模板:
HSCAN key cursor [MATCH pattern] [COUNT count]
key:指定要迭代的哈希表的键名。
cursor:迭代的起始游标。在第一次调用时,你可以将其设置为0,后续调用会返回新的游标,你需要使用返回的游标来进行下一次迭代。MATCH pattern(可选):用于匹配字段的模式。只有与模式匹配的字段才会被返回。模式可以包含通配符和?,其中匹配零个或多个字符,?匹配一个字符。COUNT count(可选):指定每次迭代返回的最大字段-值对数量。这可以帮助你控制每次迭代的负载。
具体使用方法上一数据类型的最后一个方法有说明
示例:
HSET myhash field1 value1
HSET myhash field2 value2
HSCAN myhash 0
6.Bitmaps(位图)
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图:

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis 6 中提供了 Bitmaps 这个“数据类型”可以实现对位的操作:
-
Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。
-
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

1、setbit
这个命令用于设置Bitmaps中某个偏移量的值(0或1),offset偏移量从0开始。格式如下:
setbit <key> <offset> <value>
例如,把每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图:
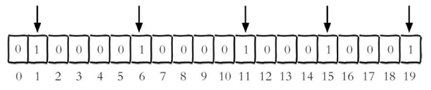
下面示例是代表 2022-07-18 这天的独立访问用户的Bitmaps:
setbit unique:users:20220718 1 1
setbit unique:users:20220718 6 1
setbit unique:users:20220718 11 1
setbit unique:users:20220718 15 1
setbit unique:users:20220718 19 1
注意:
很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
2、getbit
这个命令用于获取Bitmaps中某个偏移量的值。格式为:
getbit <key> <offset>
获取键的第offset位的值(从0开始算)。例如获取id=6的用户是否在2022-07-18这天访问过, 返回0说明没有访问过:
getbit unique:users:20220718 6
getbit unique:users:20220718 7

3、bitcount
这个命令用于统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。格式如下:
bitcount <key> [start end]
用于统计字符串从start字节到end字节比特值为1的数量。例如,统计id在第1个字节到第3个字节之间的独立访问用户数, 对应的用户id是11, 15, 19。
127.0.0.1:6379> bitcount unique:users:20220718 1 3

4、bitop
这个命令是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。格式如下:
bitop and(or/not/xor) <destkey> [key…]
例如:2020-11-04 日访问网站的userid=1,2,5,9。
setbit unique:users:20201104 1 1
setbit unique:users:20201104 2 1
setbit unique:users:20201104 5 1
setbit unique:users:20201104 9 1
2020-11-03 日访问网站的userid=0,1,4,9。
setbit unique:users:20201103 0 1
setbit unique:users:20201103 1 1
setbit unique:users:20201103 4 1
setbit unique:users:20201103 9 1
计算出两天都访问过网站的用户数量存到unique:users:and:20201104_03
bitop and unique:users:and:20201104_03 unique:users:20201103 unique:users:20201104
显示unique:users:and:20201104_03内位图被设置为1的数量
bitcount unique:users:and:20201104_03

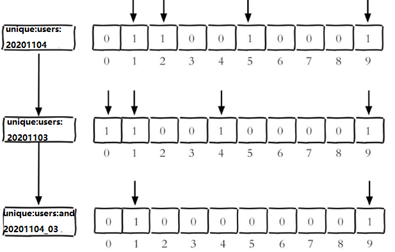
计算出任意一天都访问过网站的用户数量(例如月活跃就是类似这种) , 可以使用or求并集
对源位图unique:users:20201103和unique:users:20201104进行逐位的逻辑或操作,并将结果保存在目标位图unique:users:or:20201104_03中
bitop or unique:users:or:20201104_03 unique:users:20201103 unique:users:20201104
使用bitcount unique:users:or:20201104_03命令。返回目标位图中被设置为1的位的数量
bitcount unique:users:or:20201104_03

7.HyperLogLog(基数统计)
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
-
数据存储在MySQL表中,使用distinct count计算不重复个数
-
使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。为了能够降低一定的精度来平衡存储空间,Redis推出了HyperLogLog。HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1,3,7,8},那么这个数据集的基数集为 {1,8},基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | PFADD key element [element …] | 添加指定元素到 HyperLogLog 中 |
| 2 | PFCOUNT key [key …] | 返回给定 HyperLogLog 的基数估算值 |
| 3 | PFMERGE destkey sourcekey [sourcekey …] | 将多个 HyperLogLog 合并为一个 HyperLogLog |
以下是PFADD、PFCOUNT 和 PFMERGE 命令的使用方法和示例:
PFADD:添加指定元素到 HyperLogLog 中
命令模板:PFADD key element [element …]
示例:
PFADD hllset element1 element2 element3
我们创建了一个名为 “hllset” 的 HyperLogLog,并向其中添加了三个元素。
PFCOUNT:返回给定 HyperLogLog 的基数估算值
命令模板:PFCOUNT key [key …]
示例:
PFADD hllset element1 element2 element3
PFCOUNT hllset

PFMERGE:将多个 HyperLogLog 合并为一个 HyperLogLog
命令模板:PFMERGE destkey sourcekey [sourcekey …]
示例:
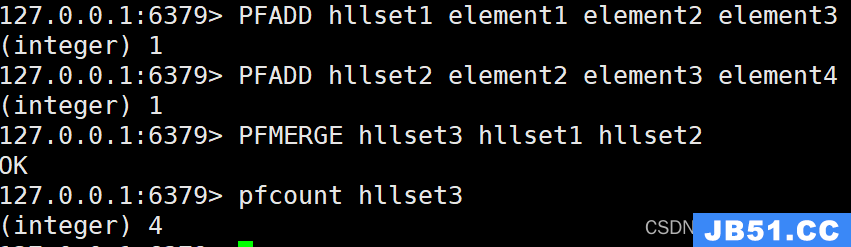
PFADD hllset1 element1 element2 element3
PFADD hllset2 element2 element3 element4
PFMERGE hllset3 hllset1 hllset2
我们创建了两个 HyperLogLog “hllset1” 和 “hllset2”,并向它们分别添加了元素。然后,我们使用 PFMERGE 命令将这两个 HyperLogLog 合并为一个新的 HyperLogLog “hllset3”。
8.Geospatial(地理空间)
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | geoadd key longitude latitude member [longitude latitude member…] | 添加地理位置(经度,纬度,名称) |
| 2 | geopos key member [member…] | 获得指定地区的坐标值 |
| 3 | geodist key member1 member2 [m|km|ft|mi] | 获取两个位置之间的直线距离 |
| 4 | georadius key longitude latitude radius [m|km|ft|mi] | 以给定的经纬度为中心,找出某一半径内的元素 |
好的,以下是使用 Redis 的地理位置(Geospatial)功能的教程,包括 GEOADD、GEOPOS、GEODIST 和 GEORADIUS 命令的使用方法和示例:
GEOADD:添加地理位置(经度,纬度,名称)
命令模板:GEOADD key longitude latitude member [longitude latitude member…]
示例:
GEOADD locations 13.361389 38.115556 "Paris"
GEOADD locations 15.087269 37.502669 "Rome"
GEOADD locations -74.005973 40.712776 "New York"
我们创建了一个名为 “locations” 的地理位置集合,并向其中添加了三个地点,每个地点都有对应的经度、纬度和名称。
GEOPOS:获得指定地区的坐标值
命令模板:GEOPOS key member [member…]
示例:
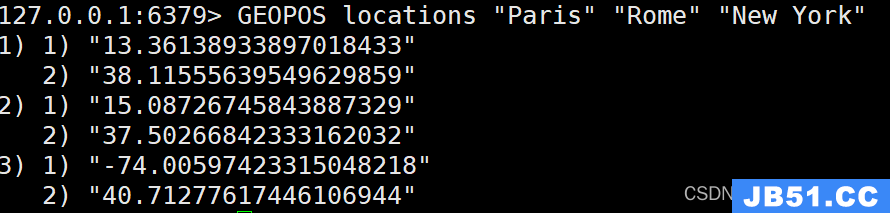
GEOPOS locations "Paris" "Rome" "New York"
我们使用 GEOPOS 命令获取了 “locations” 集合中 “Paris”、“Rome” 和 “New York” 这三个地点的坐标值(经度和纬度)。
GEODIST:获取两个位置之间的直线距离
命令模板:GEODIST key member1 member2 [m|km|ft|mi]
示例:
GEODIST locations "Paris" "Rome" km
我们使用 GEODIST 命令获取了 “locations” 集合中 “Paris” 和 “Rome” 之间的直线距离,并将距离单位设置为千米。

巴黎 罗马距离166.2742km;
GEORADIUS:以给定的经纬度为中心,找出某一半径内的元素
命令模板:GEORADIUS key longitude latitude radius [m|km|ft|mi]
示例:
GEORADIUS locations 13.361389 38.115556 100 km
在上述示例中,我们使用 GEORADIUS 命令以经度 13.361389、纬度 38.115556 为中心,找出 “locations” 集合中距离中心点 100 公里以内的元素。

找到了100公里内的巴黎;
redis的8中数据类型到这里就结束了,如果你还想获取更多reids的知识请关注我,有问题请随时在评论区留言!
原文地址:https://blog.csdn.net/weixin_62392149/article/details/132302449
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。