
Golang面试题
内存管理
- new 和 make 的区别 Go分为数据类型分为值类型和引用类型,其中值类型是 int、float、string、bool、struct和array,它们直接存储值,分配栈的内存空间,它们被函数调用完之后会释放;引用类型是 slice、map、chan和值类型对应的指针 它们存储是一个地址(或者理解为指针),指针指向内存中真正存储数据的首地址,内存通常在堆分配,通过GC回收。undefined 区别 new 的参数要求传入一个类型,而不是一个值,它会申请该类型的内存大小空间,并初始化为对应的零值,返回该指向类型空间的一个指针。undefinedmake 也用于内存分配,但它只用于引用对象 slice、map、channel的内存创建,返回的类型是类型本身。
- 内存逃逸分析 Go的逃逸分析是一种确定指针动态范围的方法,可以分析程序在哪些可以访问到指针,它涉及到指针分析和状态分析。
当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它程序,或者去调用子程序。 如果使用尾递归优化(通常函数式编程是需要的),对象也可能逃逸到被调用程序中。如果一个子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中的任何一个地方都可以访问。
如果指针存储在全局变量或者其它数据结构中,它们也可能发生逃逸,这种情况就是当前程序的指针逃逸。逃逸分析需要确定指针所有可以存储的地方,保证指针的生命周期只在当前进程或线程中。
导致内存逃逸的情况比较多(有些可能官方未能够实现精确的逃逸分析情况的bug),通常来讲就是如果变量的作用域不会扩大并且行为或者大小能够在其编译时确定,一般情况下都分配栈上,否则就可能发生内存逃逸到堆上。
引用内存逃逸的典型情况: * 在函数内部返回把局部变量指针返回 局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此生命周期大于栈,则溢出
发送指针或带有指针的值到channel中 在编译时,是没办法知道哪个 goroutine 会在 channel上接受数据,所以编译器没办法知道变量什么时候释放。
在一个切片上存储指针或带指针的值 一个典型的例子就是 []*string,这会导致切片的内容逃逸,尽管其后面的数组在栈上分配,但其引用值一定是在堆上
slice 的背后数组被重新分配了 因为 append 时可能会超出其容量( cap )。 slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
在 interface 类型上调用方法 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片b 的背后存储都逃逸掉,所以会在堆上分配。
- golang内存管理 Go语言的内存分配器采用了跟 tcmalloc 库相同的多级缓存分配模型,该模型将引入了线程缓存(Thread Cache)、中心缓存(Central Cache)和页堆(Page Heap)三个组件分级管理内存。

线程缓存属于每一个独立的线程,它能够满足线程上绝大多数的内存分配需求,因为不涉及多线程,所以也不需要使用互斥锁来保护内存,这能够减少锁竞争带来的性能损耗。当线程缓存不能满足需求时,运行时会使用中心缓存作为补充解决小对象的内存分配,在遇到大对象时,内存分配器会选择页堆直接分配大内存。
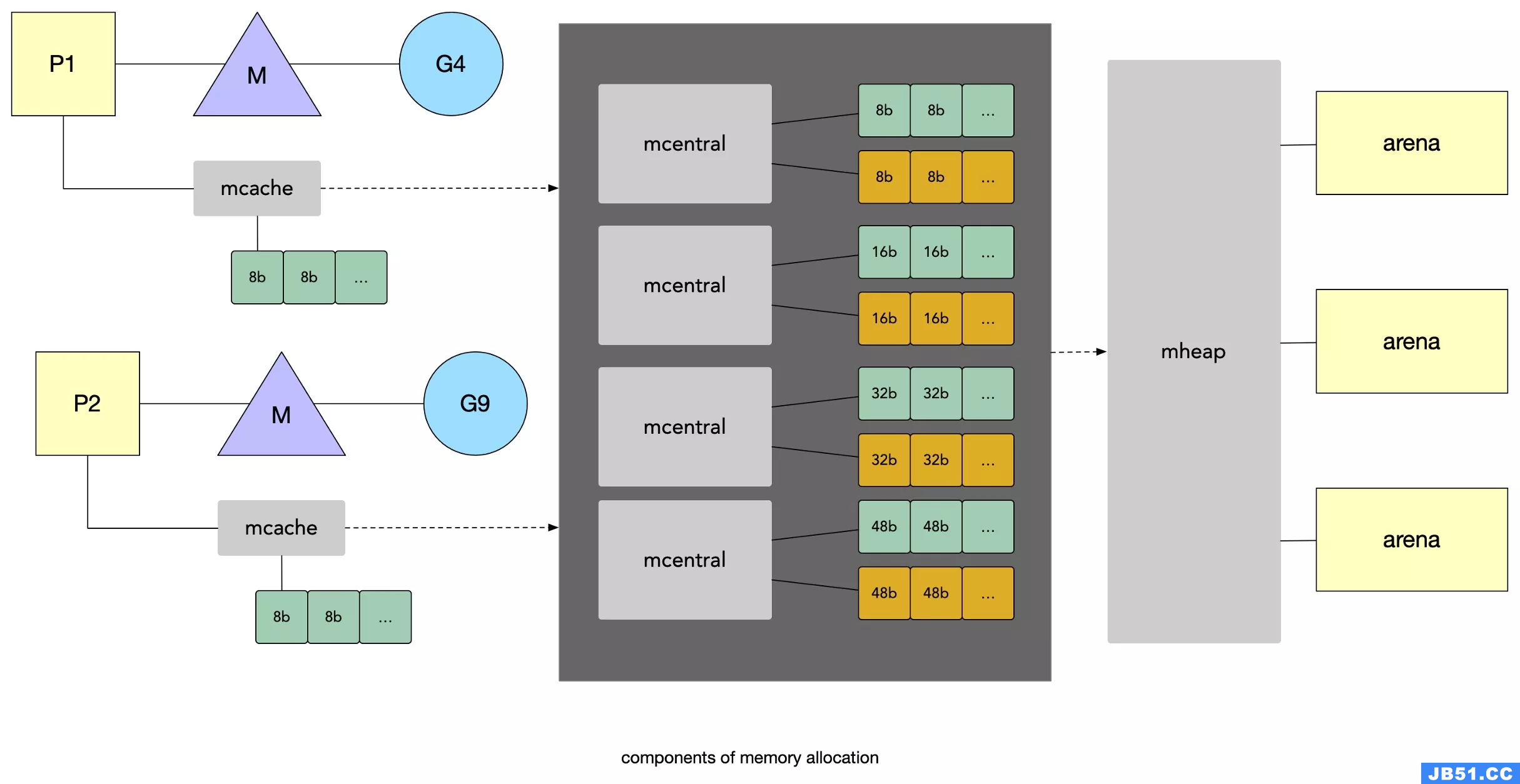
在 Golang 中, mcache , mspan , mcentral 和 mheap 是内存管理的四大组件,mspan是内管管理的基本单元,由mcache充当”线程缓存“,由mcentral充当”中心缓存“,由mheap充当“页堆”。下级组件内存不够时向上级申请一个或多个mspan。
根据对象的大小不同,内部会使用不同的内存分配机制,详细参考函数 mallocgo()。
<16KB 会使用微小对象内存分配器从 P 中的 mcache 分配,主要使用 mcache.tinyXXX 这类的字段。 16-32KB 从 P 中的 mcache 中分配。 >32KB 直接从 mheap 中分配。golang中的内存申请流程如下图所示。
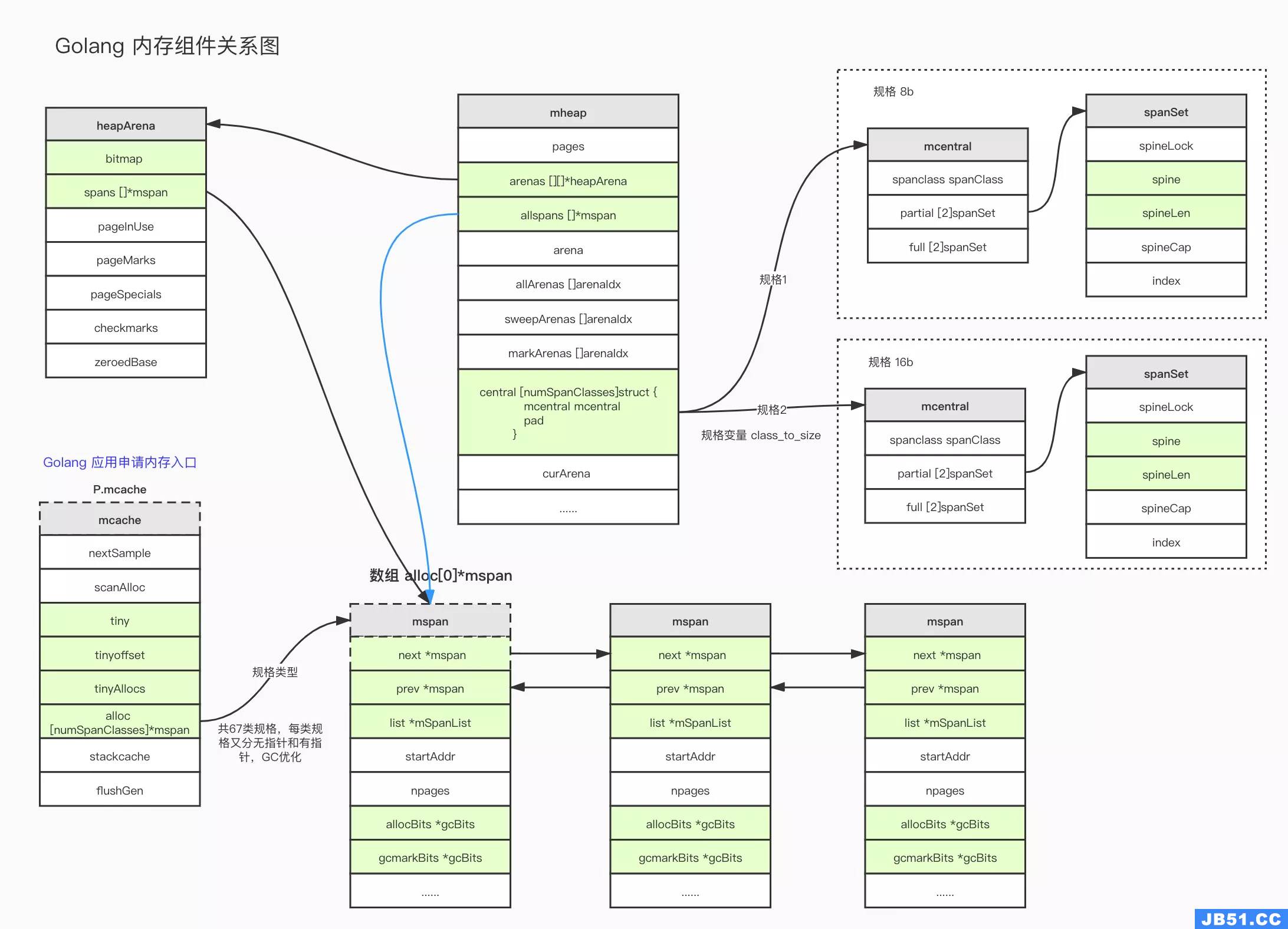
大约有 100 种内存块类别,每一个类别都有自己对象的空闲链表。小于 32KB 的内存分配被向上取整到对应的尺寸类别,从相应的空闲链表中分配。一页内存只可以被分裂成同一种尺寸类别的对象,然后由空间链表分配管理器。
GC
- 如果 goroutine 一直占用资源怎么办,GMP模型怎么解决这个问题 如果有一个goroutine一直占用资源的话,GMP模型会从正常模式转为饥饿模式,通过信号协作强制处理在最前的 goroutine 去分配使用
- 如果若干个线程发生OOM,会发生什么?Goroutine中内存泄漏的发现与排查?项目出现过OOM吗,怎么解决 线程 如果线程发生OOM,也就是内存溢出,发生OOM的线程会被kill掉,其它线程不受影响。
- Goroutine中内存泄漏的发现与排查 go中的内存泄漏一般都是goroutine泄露,就是goroutine没有被关闭,或者没有添加超时控制,让goroutine一只处于阻塞状态,不能被GC。在Go中内存泄露分为暂时性内存泄露和永久性内存泄露。
暂时性内存泄露,string相比切片少了一个容量的cap字段,可以把string当成一个只读的切片类型。获取长string或者切片中的一段内容,由于新生成的对象和老的string或者切片共用一个内存空间,会导致老的string和切片资源暂时得不到释放,造成短暂的内存泄漏。
永久性内存泄露,主要由goroutine永久阻塞而导致泄漏以及time.Ticker未关闭导致泄漏引起。
- Go的垃圾回收算法 Go 现阶段采用的是通过三色标记清除扫法与混合写屏障GC策略。其核心优化思路就是尽量使得 STW(Stop The World) 的时间越来越短。
GC 的过程一共分为四个阶段:
栈扫描(STW),所有对象开始都是白色
从 root 开始找到所有可达对象(所有可以找到的对象),标记灰色,放入待处理队列
遍历灰色对象队列,将其引用对象标记为灰色放入待处理队列,自身标记为黑色
清除(并发)循环步骤3 直到灰色队列为空为止,此时所有引用对象都被标记为黑色,所有不可达的对象依然为白色,白色的就是需要进行回收的对象。三色标记法相对于普通标记清除,减少了 STW 时间。这主要得益于标记过程是 “on-the-fly”的,在标记过程中是不需要 STW的,它与程序是并发执行的,这就大大缩短了 STW 的时间。
写屏障:
插入屏障, 在A对象引用B对象的时候,B对象被标记为灰色。(满足强三色不变性)
删除屏障,被删除的对象,如果自身为灰色或者白色,那么被标记为灰色。(满足弱三色不变性)
混合写屏障:
GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW),
GC期间,任何在栈上创建的新对象,均为黑色。
被删除的对象标记为灰色。
被添加的对象标记为灰色。
多线程
- GMP多线程模型 基于CSP并发模型开发了GMP调度器,其中undefinedG (Goroutine) : 每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数。undefinedM (Machine) : 对OS内核级线程的封装,数量对应真实的CPU数(真正干活的对象)。undefinedP (Processor): 逻辑处理器,即为G和M的调度对象,用来调度G和M之间的关联关系,其数量可通过 GOMAXPROCS()来设置,默认为核心数。undefined在单核情况下,所有Goroutine运行在同一个线程(M0)中,每一个线程维护一个上下文(P),任何时刻,一个上下文中只有一个Goroutine,其他Goroutine在runqueue中等待。
一个Goroutine运行完自己的时间片后,让出上下文,自己回到runqueue中。
当正在运行的G0阻塞的时候(可以需要IO),会再创建一个线程(M1),P转到新的线程中去运行。
当M0返回时,它会尝试从其他线程中“偷”一个上下文过来,如果没有偷到,会把Goroutine放到Global runqueue中去,然后把自己放入线程缓存中。 上下文会定时检查Global runqueue。
- goroutine的优势 上下文切换代价小:从GMP调度器可以看出,避免了用户态和内核态线程切换,所以上下文切换代价小 内存占用少:线程栈空间通常是 2M,Goroutine 栈空间最小 2K; goroutine 什么时候发生阻塞 channel 在等待网络请求或者数据操作的IO返回的时候会发生阻塞 发生一次系统调用等待返回结果的时候 goroutine进行sleep操作的时候
- goroutine的9种状态 _Gidle:刚刚被分配并且还没有被初始化undefined _Grunnable:没有执行代码,没有栈的所有权,存储在运行队列中undefined _Grunning:可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 Pundefined _Gsyscall:正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上undefined _Gwaiting:由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上undefined _Gdead:没有被使用,没有执行代码,可能有分配的栈undefined _Gcopystack:栈正在被拷贝,没有执行代码,不在运行队列上undefined _Gpreempted:由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒undefined _Gscan:GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在undefined去抢占 G 的时候,会有一个自旋和非自旋的状态
- 线程和协程堆栈的内存大小 线程一般是4M,协程一般是2K
- Go数据竞争怎么解决 Data Race 问题可以使用互斥锁解决,或者也可以通过CAS无锁并发解决
中使用同步访问共享数据或者CAS无锁并发是处理数据竞争的一种有效的方法.
golang在1.1之后引入了竞争检测机制,可以使用 go run -race 或者 go build -race来进行静态检测。
其在内部的实现是,开启多个协程执行同一个命令, 并且记录下每个变量的状态.
竞争检测器基于C/C++的ThreadSanitizer运行时库,该库在Google内部代码基地和Chromium找到许多错误。这个技术在2012年九月集成到Go中,从那时开始,它已经在标准库中检测到42个竞争条件。现在,它已经是我们持续构建过程的一部分,当竞争条件出现时,它会继续捕捉到这些错误。
竞争检测器已经完全集成到Go工具链中,仅仅添加-race标志到命令行就使用了检测器。
$ go test -race mypkg // 测试包
$ go run -race mysrc.go // 编译和运行程序
$ go build -race mycmd // 构建程序
$ go install -race mypkg // 安装程序要想解决数据竞争的问题可以使用互斥锁sync.Mutex,解决数据竞争(Data race),也可以使用管道解决,使用管道的效率要比互斥锁高.
6.chan的实现原理
go的多线程实现采用CSP模型。各个线程独立顺序执行,两个goroutine间表面上没有耦合,而是采用channel作为其通信的媒介,达到线程间同步的目的。 channel 是一个用于同步和通信的有锁FIFO队列。
写 channel 现象:
向nil channel写,会导致阻塞。
向关闭的channel写,会导致panic。
如果另一个goroutine在等待读,则通信内容直接发送给另一个goroutine,自己不阻塞。
上一种现象中如果有多个goroutine都在等待读,则发给第一个等待的,FIFO顺序。
如果没有另一个goroutine在等待读,如果缓存队列没满,那么将通信内容放入队列,自己不阻塞。
如果没有另一个goroutine在等待读,如果缓存队列满了,那么自己将阻塞,直到被其他go读取。
读 channel 现象:
从nil channel读,会导致阻塞。
从关闭的channel读,如果缓冲区有,则取出;没有则会读出0值,不阻塞。
如果存在缓冲区,则优先向缓冲区写,其次阻塞写的goroutine。因此,读channel的优先级是先从缓存队列读,再从被阻塞的写channel的goroutine读;
上面现象可以细分几种情况。如下表
- syn.Map的实现原理type Map struct { mu Mutex // 互斥量 read atomic.Value // 只读部分的数据 dirty map[interface{}]*entry // 读写部分数据 misses int }互斥量 mu 保护 read 和 dirty。
read 是 atomic.Value 类型,atomic库提供并发地读的能力,无需上锁。但如果需要更新 read,则需要加锁保护。对于 read 中存储的 entry 字段,可能会被并发地 CAS 更新。但是如果要更新一个之前已被删除的 entry,则需要先将其状态从 expunged 改为 nil,再拷贝到 dirty 中,然后再更新。
dirty 是一个非线程安全的原始 map。包含新写入的 key,并且包含 read 中的所有未被删除的 key。这样,可以快速地将 dirty 提升为 read 对外提供服务。如果 dirty 为 nil,那么下一次写入时,会新建一个新的 dirty,这个初始的 dirty 是 read 的一个拷贝,但除掉了其中已被删除的 key。
每当从 read 中读取失败,都会将 misses 的计数值加 1,当加到一定阈值以后,需要将 dirty 提升为 read,以期减少 miss 的情形。
- golang中有哪几中锁?
Mutex 互斥锁 和 RWMutex 读写锁。
互斥锁
state 是否加锁,唤醒,饥饿,WaiterShift(竞争锁失败后在堆树休眠的协程个数)
sema pv操作
得到锁就可以做业务了,别人就拿不到这把锁了
竞争Locked,得不到的会多次自旋操作(执行空语句)
Lock解开后唤醒堆树中一个协程
spin自旋
饥饿模式
当前协程等待锁时间超过1s,进入饥饿模式
该模式中,不自旋,新来的协程获取不到Lock直接sema休眠
被唤醒的协程直接获取锁
没有协程在sema中回到正常模式
用defer处理锁比较好,防止panic后锁得不到释放
// 互斥锁
type Mutex struct {
state int32 // 锁状态
sema uint32 // 锁信号
}
// 上锁过程
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
// 解锁过程
func (m *Mutex) Unlock() {
if race.Enabled {
_ = m.state
race.Release(unsafe.Pointer(m))
}
// Fast path: drop lock bit.
new := atomic.AddInt32(&m.state, -mutexLocked)
if new != 0 {
// Outlined slow path to allow inlining the fast path.
// To hide unlockSlow during tracing we skip one extra frame when tracing GoUnblock.
m.unlockSlow(new)
}
}读写锁
RWMutex
读取的过程希望加锁,只加RMutex就行
(多个协程并发只读)
读写锁原理
读锁为共享锁,可以上许多个
写锁在存在读锁的时刻是无法获取的
写协程放到等待队列中,获取后取出
已加读锁的情况下无法加写锁,读协程放到等待队列中
RWMutex底层
w 互斥锁作为写锁
读,写sema (两个协程队列)
readerCount 正值(正在读的协程)负值(加了写锁)
readerWait 写锁应该等待读协程的个数
读多写少的场景用RW锁带来的性能优势较高
// 读写锁一共有3 个 sema,分别为 1.Mutex 中的 sema 2.writerSem 3.readerSem
type RWMutex struct {
w Mutex // held if there are pending writers
writerSem uint32 // 写信号,等待读操作完成
readerSem uint32 // 读信号 等待写操作完成
readerCount int32 // 被挂起的读操作数量
readerWait int32 // 等待被唤醒的读操作的数量
}- Mutex有哪几种模式?
Mutex:正常模式和饥饿模式
在正常模式下,锁的等待者会按照先进先出的顺序获取锁。
但是刚被唤起的 Goroutine 与新创建的 Goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现,一旦 Goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式,防止部分 Goroutine 被饿死。
饥饿模式是在 Go 语言 1.9 版本引入的优化的,引入的目的是保证互斥锁的公平性(Fairness)。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。
如果一个 Goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会被切换回正常模式。
相比于饥饿模式,正常模式下的互斥锁能够提供更好地性能,饥饿模式的能避免 Goroutine 由于陷入等待无法获取锁而造成的高尾延时。
- goroutine的锁机制吗?
atomic(原子操作) + semacquire/semrelease(PV 操作)
sema锁(go锁底层),底下有个semaroot结构体
信号锁 uint类型
uint == 0 协程会加入到底层的平衡二叉树中执行gopark()挂起其他协程释放锁时会拿出执行
sema == 0 的时候会被当作普通的等待队列使用(极少当作锁来使用)
获取锁uint-1 释放锁uint+1
- goroutine 同步如何实现?// A WaitGroup waits for a collection of goroutines to finish. // The main goroutine calls Add to set the number of // goroutines to wait for. Then each of the goroutines // runs and calls Done when finished. At the same time, // Wait can be used to block until all goroutines have finished. // // A WaitGroup must not be copied after first use. // // In the terminology of the Go memory model, a call to Done // “synchronizes before” the return of any Wait call that it unblocks. type WaitGroup struct { noCopy noCopy // 64-bit value: high 32 bits are counter, low 32 bits are waiter count. // 64-bit atomic operations require 64-bit alignment, but 32-bit // compilers only guarantee that 64-bit fields are 32-bit aligned. // For this reason on 32 bit architectures we need to check in state() // if state1 is aligned or not, and dynamically "swap" the field order if // needed. state1 uint64 state2 uint32 }WG 组协程等待 底层 state3个uint成员数组(被等待协程,等待协程(放在sema中),sema队列) race调试用的信息 wait() 等待协程+1 Add,Done()被等待协程-1
- 如何检测锁异常?
go vet 查看是否存在拷贝锁
race 竞争检测
go build - race
升值加薪不会到20次的
网络
- Linux 下 epoll 多路复用技术?#include <sys/epoll.h> // 创建一个 epoll 的文件描述符,该文件会与一个内核事件表和一个就绪队列关联 // epoll_create1 可以理解为 epoll_create 的增强版(主要支持了 close-on-exec) int epoll_create(int size); int epoll_create1(int flags); // 操作内核事件标,添加、删除、更改一个 socket int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 等待 socket 被激活 int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); // 关闭 epoll 文件,清理内核事件表 int close(int fd);程序在内核空间开辟一块缓存,用来管理 epoll 红黑树,高效添加和删除undefined红黑树位于内核空间,用来直接管理 socket,减少和用户态的交互undefined使用双向链表缓存就绪的 socket,数量较少undefined只需要拷贝这个双向链表到用户空间,再遍历就行,注意这里也需要拷贝,没有共享内存
- Linux 下 golang 如何做到多路复用? Go 基于 I/O multiplexing(例如unix kqueue、linux epoll、windows iocp) 和 goroutine scheduler 构建了一个简洁而高性能的原生网络模型,一般也被称为 network poller。
以 epoll 为例简单描述一下 network poller的工作流程,golang 调用 net.Listen 时,golang 会在 goroutine 中增加 netFD 描述,并调用 epoll 函数将 netFD 写入 epoll 内核事件表中;当 findRunable 会查询 epoll 内核事件表中的就绪事件,读取 netFD 信息并唤醒与 netFD 对应的 goroutine,处理完成后 goroutine 被丢如 process 调度队列的队尾。
接下来是runtime中关于epoll wait 和 goprk 的封装:
// Finds a runnable goroutine to execute.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
// ...
// 如果这有什么逻辑上的竞争的话,此线程将在后面被 netpoll 阻塞
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}
// ...
// Poll network until next timer.
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
atomic.Store64(&sched.pollUntil, uint64(pollUntil))
if _g_.m.p != 0 {
throw("findrunnable: netpoll with p")
}
if _g_.m.spinning {
throw("findrunnable: netpoll with spinning")
}
// 刷新
now = nanotime()
delay := int64(-1)
if pollUntil != 0 {
delay = pollUntil - now
if delay < 0 {
delay = 0
}
}
if faketime != 0 {
delay = 0
}
// delay != 0 时,线程被阻塞
list := netpoll(delay)
atomic.Store64(&sched.pollUntil, 0)
atomic.Store64(&sched.lastpoll, uint64(now))
if faketime != 0 && list.empty() {
stopm()
goto top
}
// ... 省略 netpoll 无关代码
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
}其他
- Go:反射之用字符串函数名调用函数package main import ( "fmt" "reflect" ) type Animal struct { } func (m *Animal) Eat() { fmt.Println("Eat") } func main() { animal := Animal{} value := reflect.ValueOf(&animal) f := value.MethodByName("Eat") //通过反射获取它对应的函数,然后通过call来调用 f.Call([]reflect.Value{}) }
- 你知道 Go 条件编译吗?
Golang支持两种条件编译的实现方式:
编译标签(build tags):
1) 编译标签由空格分隔的编译选项(options)以”或”的逻辑关系组成
2) 每个编译选项由逗号分隔的条件项以逻辑”与”的关系组成
3) 每个条件项的名字用字母+数字表示,在前面加!表示否定的意思
4) 不同tag域之间用空格区分,他们是OR关系
5) 同一tag域之内不同的tag用都好区分,他们是AND关系
6) 每一个tag都由字母和数字构成,!开头表示条件“非”
% head headspin.go
// Copyright 2013 Way out enterprises. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// +build someos someotheros thirdos,!amd64
// Package headspin implements calculates numbers so large
// they will make your head spin.
package headspin文件后缀(file postfix):
这个方法通过改变文件名的后缀来提供条件编译,这种方案比编译标签要简单,go/build可以在不读取源文件的情况下就可以决定哪些文件不需要参与编译。
文件命名约定可以在go/build 包里找到详细的说明,简单来说如果你的源文件包含后缀:_GOOS.go,那么这个源文件只会在这个平台下编译,_GOARCH.go也是如此。这两个后缀可以结合在一起使用,但是要注意顺序:_GOOS_GOARCH.go, 不能反过来用:_GOARCH_GOOS.go. 例子如下:
mypkg_freebsd_arm.go // only builds on freebsd/arm systems
mypkg_plan9.go // only builds on plan9- 如何实现交叉编译?
我们知道golang一份代码可以编译出在不同系统和cpu架构运行的二进制文件。go也提供了很多环境变量,我们可以设置环境变量的值,来编译不同目标平台。
GOOS: 目标平台; GOARCH: 目标架构。
# 编译目标平台linux 64位
GOOS=linux GOARCH=amd64 go build main.go
# 编译目标平台windows 64位
GOOS=windows GOARCH=amd64 go build main.go常用的GOOS和GOARCH 可以使用下面命令查看
go tool dist list更多技术分享浏览我的博客:
原文地址:https://cloud.tencent.com/developer/article/2156354
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。