
ElasticSearch基础
1.基础
- 开箱即用,解压即可
- 在bin目录下启动ElasticSearch
- 访问localhost:9200 可以看到下面的内容

2. 安装与使用可视化插件
-
head插件,依赖于Node.Js
-
安装ElasticSearch-head,在解压的目录下运行 cmd,输入 cnpm install 等待安装完毕
-
安装完毕后,使用命令 npm run start 启动
-
由于我们的插件的端口为 9100,与ElasticSearch不同,产生了跨域的问题,要在ElasticSearch的配置文件中配置跨域
-
配置跨域
-
在ElasticSearch文件夹下的/conf/elasticsearch.yaml中配置
-
http.cors.enabled: true http.cors.allow-origin: "*" -
重启ElasticSearch
-
-
正常启动如下
-

3. 安装Kibana
-
Kibana 版本要和 ES 一致
-
解压完毕,启动测试
-
在 /bin 目录下的kibana.bat文件
-
默认端口为localhost:5601
-
访问kibana
-
-
国际化(汉化)
-
在kibana目录下的 \x-pack\plugins\translations\translations 可以看到
-

-
我们在 /conf 目录下的的kibana.yml中配置
-
i18n.locale: "zh-CN" -
重启kibana即可!
-
4. ES的核心概念
-
ES是面向文档的,一切都是 JSON (文档就是我们的数据)
-
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
- 单个节点由于物理机硬件限制,存储的文档是有限的,如果一个索引包含海量文档,则不能在单个节点存储。ES提供分片机制,同一个索引可以存储在不同分片(数据容器)中,这些分片又可以存储在集群中不同节点上
-
一个人就是一个集群,默认的集群名称就是 ElasticSearch
-
ElasticSearch是面向文档的,索引和搜索数据的最小单位是文档,文档有几个重要属性
- 自我包含: 一篇文档同时包含字段和对应的值,即同时包含 key : value
- 可以使层次型的: 一个文档中包含文档,可以用来构建复杂的逻辑实体! ==> (就是一个 JSON 对象! 使用FastJSON或者Jason进行自动转换)
- 灵活的结构: 文档不依赖预先定义的模式. 与关系型数据库的提前定义字段才能使用不同,在ElasticSearch中,对于字段是非常灵活的,有时候我们可以忽略该字段,或者动态的添加一个新的字段
-
索引就是数据库
- 索引是映射类型的容器,ES中的索引是一个非常大的文档集合,索引存储了映射类型的字段和其他设置
- 倒排索引
- 采用Lucene倒排索引作为底层
- 这种结构适用于快速的全文搜索
- 一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含他的文档列表
- 搜索时,完全过滤掉无关的所有数据,提高效率
-
重要步骤
- 创建索引 (相当于我们的数据库)
- 字段类型 (mapping 映射)
- 文档 (具体的数据)
- 底层的搜索使用的是倒排索引,采用分片的机制,可以使一个索引包含海量的数据
5. IK分词器插件
-
IK分词器对中文具有良好支持的分词器
-
IK分词器包括 ik_max_word 和 ik_smart
- ik_max_word会将文本做最细粒度的拆分
- ik_smart 会做最粗粒度的拆分(最少切分)
-
安装
- 在Github上下载,与ES版本要对应
- 解压后放到 ElasticSearch/plugins 目录即可
- 由于添加了新插件,重启 ES 即可!
- 可以看到,IK分词器被加载了
-
在Kibana中测试不同的分词器效果
-
最少切分
-
最细粒度切分,穷尽所有可能
-
-
IK分词器的字典没有一些自定义的词,需要我们自己加到我们的分词器的字典中
-
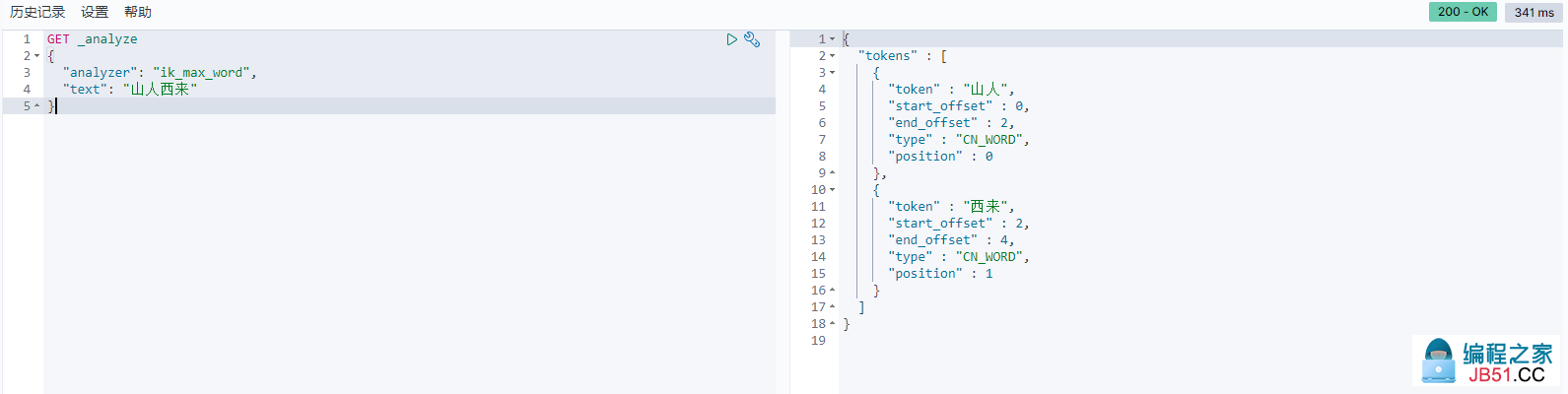
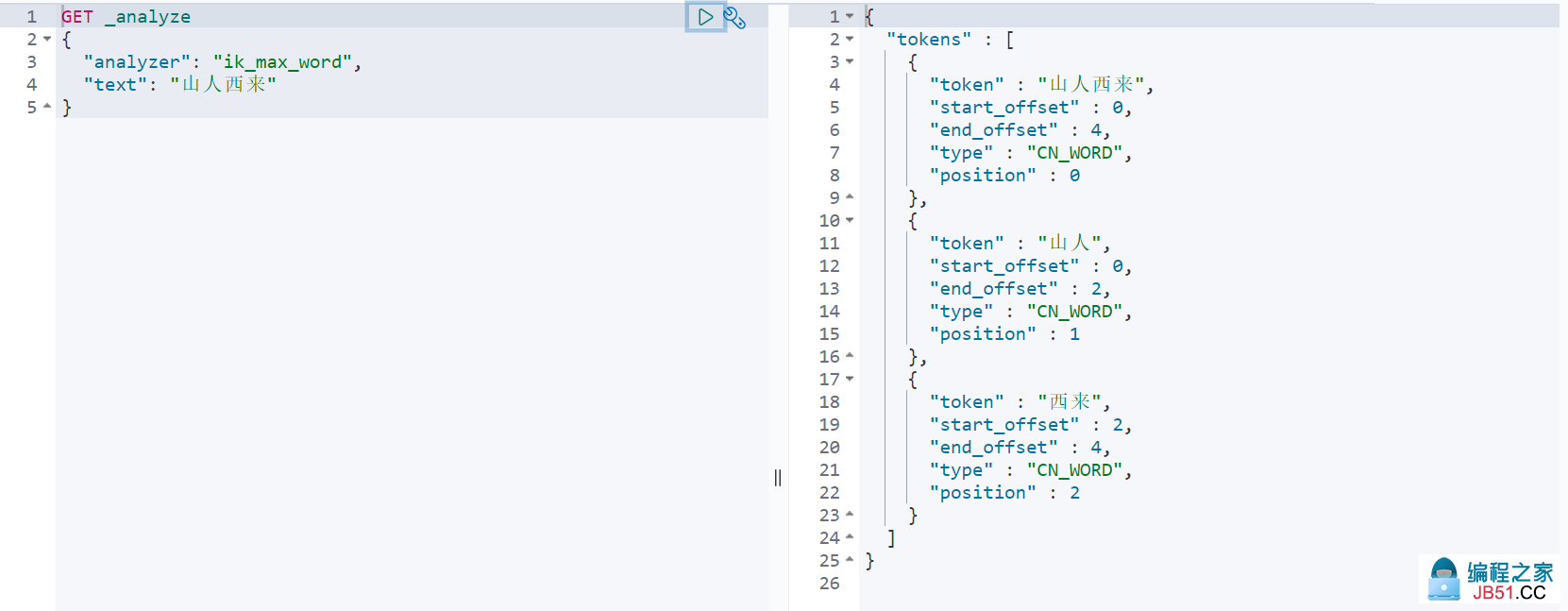
比如,我们测试 山人西来 这个词
-
-
在ik分词器的conf中找到 IKAnalyzer.ofg.xml配置
-
在conf中,我们写一个自己的字典,叫 mydic.dic,编辑,写入山人西来
-
在配置文件添加自己的字典
-
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydic.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
-
-
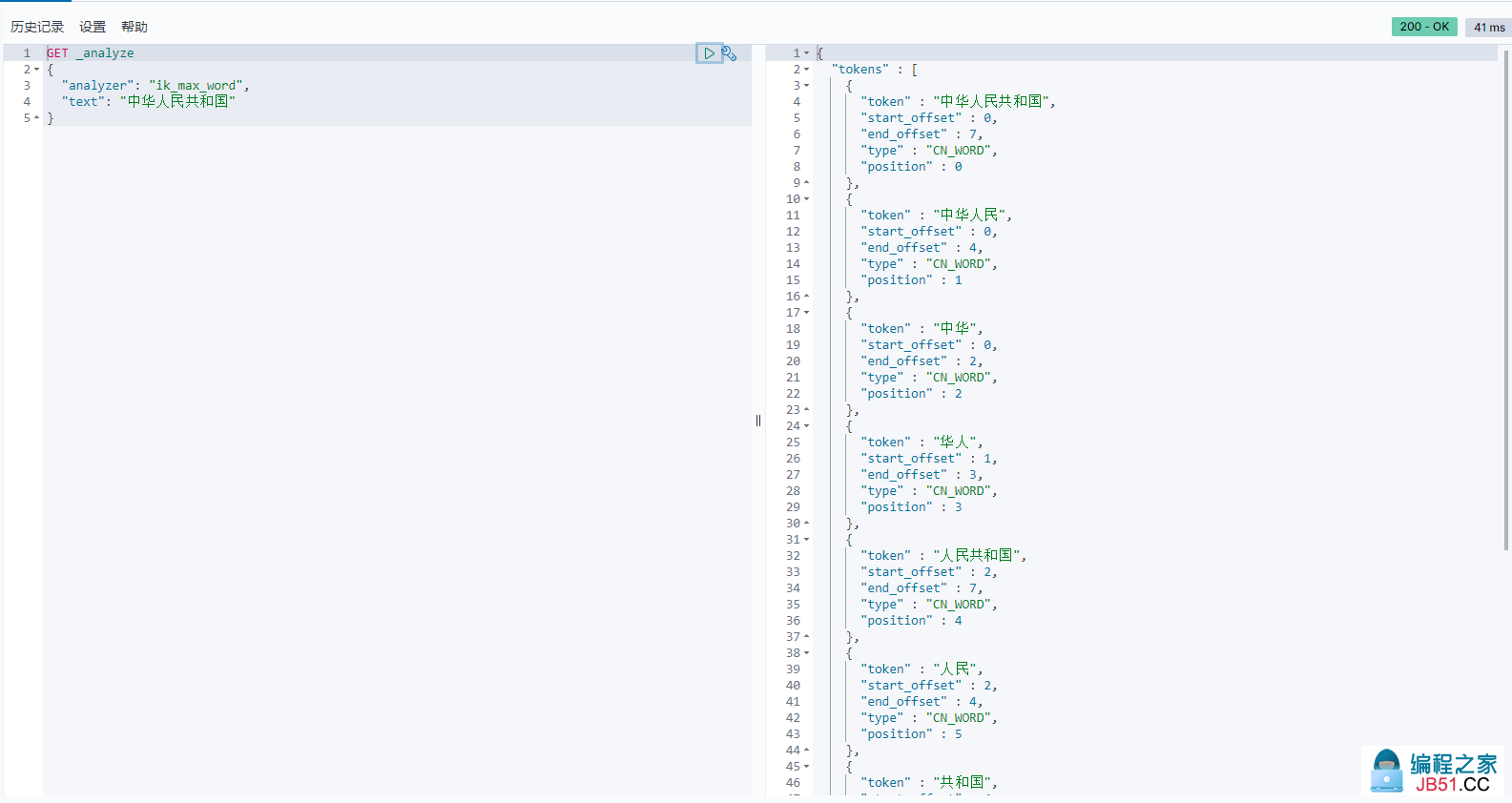
重启ES,可以看到加载了我们的自定义字典
-

-
可以看到,我们自定义的 山人西来 已经被认为是一个词了
-
以后,我们需要自己配置需要的分词,在我们自定义的dic文件中进行配置即可!

6. Rest 风格说明
-
RestFul风格是一种软件架构风格,而不是标准an,只是提供了一组设计原则和约束条件
-
method url地址 描述 PUT localhost:9200/索引名称/类型名称/文档 id 创建文档(指定文档 id) POST localhost:9200/索引名称/类型名称 创建文档(随机文档 id) POST localhost:9200/索引名称/类型名称/文档 id/_update 修改文档 DELETE localhost:9200/索引名称/类型名称/文档 id 删除文档 GET localhost:9200/索引名称/类型名称/文档 id 通过文档 id 查询文档 POST localhost:9200/索引名称/类型名称/_search 查询所有的数据
7. 关于索引的基本操作
-
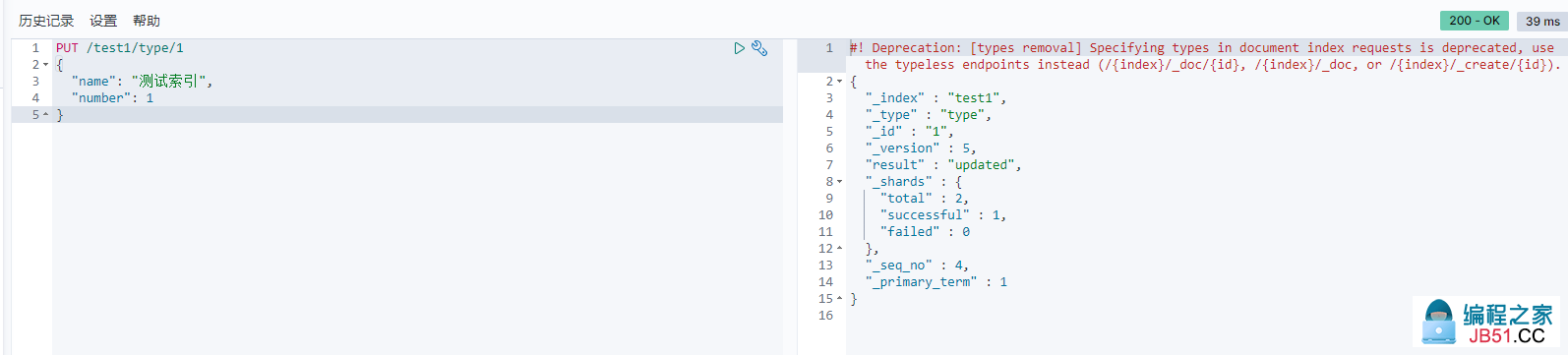
创建一个索引
-
PUT /索引名/~类型名~/文档 id { 请求体(JSON) } -
-
-
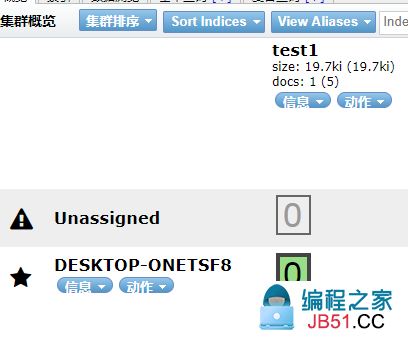
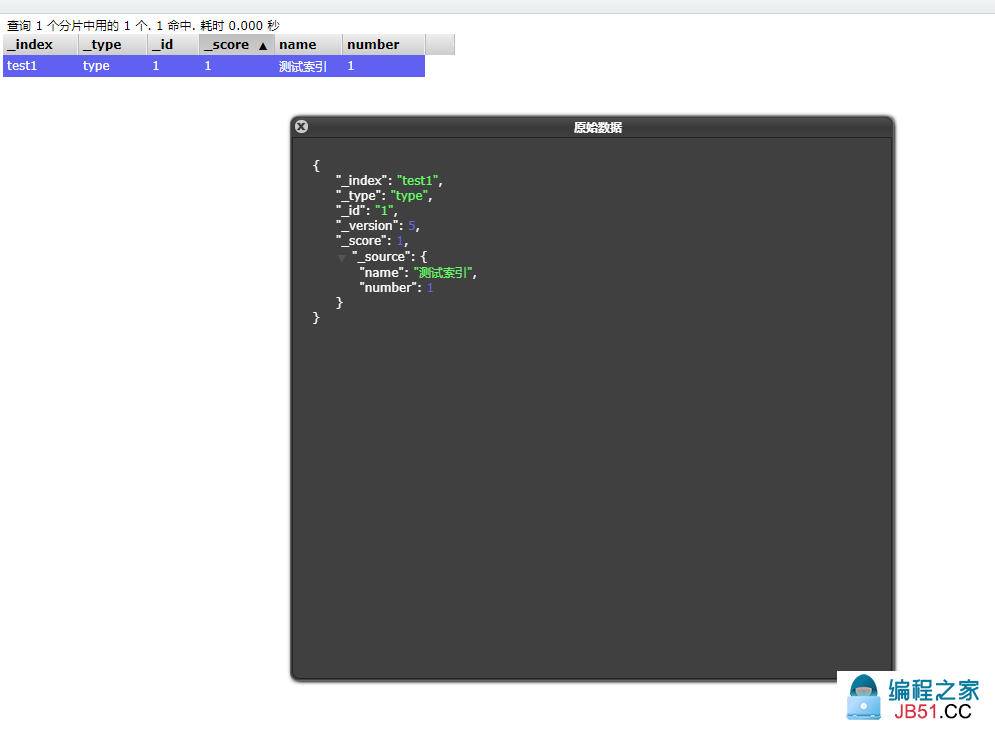
完成了自动增加了索引! 数据也成功的添加了!
-
-
-
指定自己的数据类型 (这里是配置好数据的类型)
-
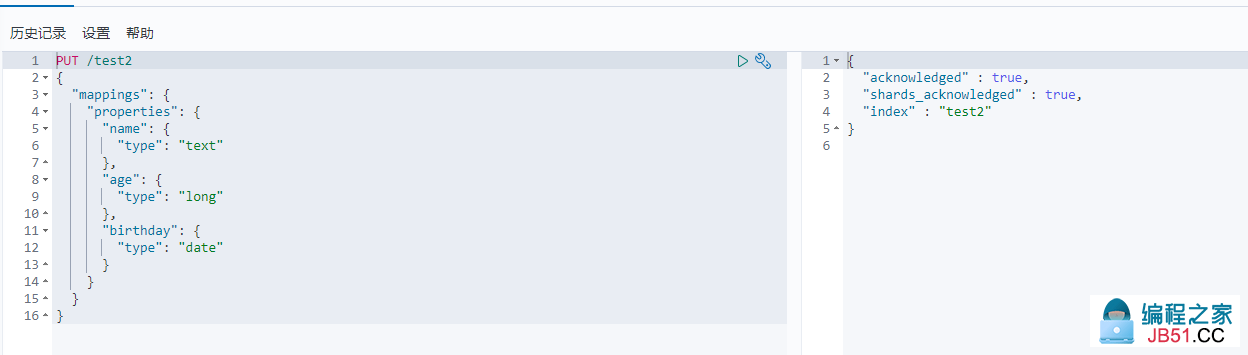
-
PUT /索引名 { "mappings": { "properties": { 字段: { "type": 指定数据类型 } } } }
-
-
可以通过GET请求得到具体的信息
-
查看默认的信息
-
注意,在 ES 8 之后,type会被启用,这里默认为_doc,可以显式的声明,也可以不写!
-

-
查看默认信息
-
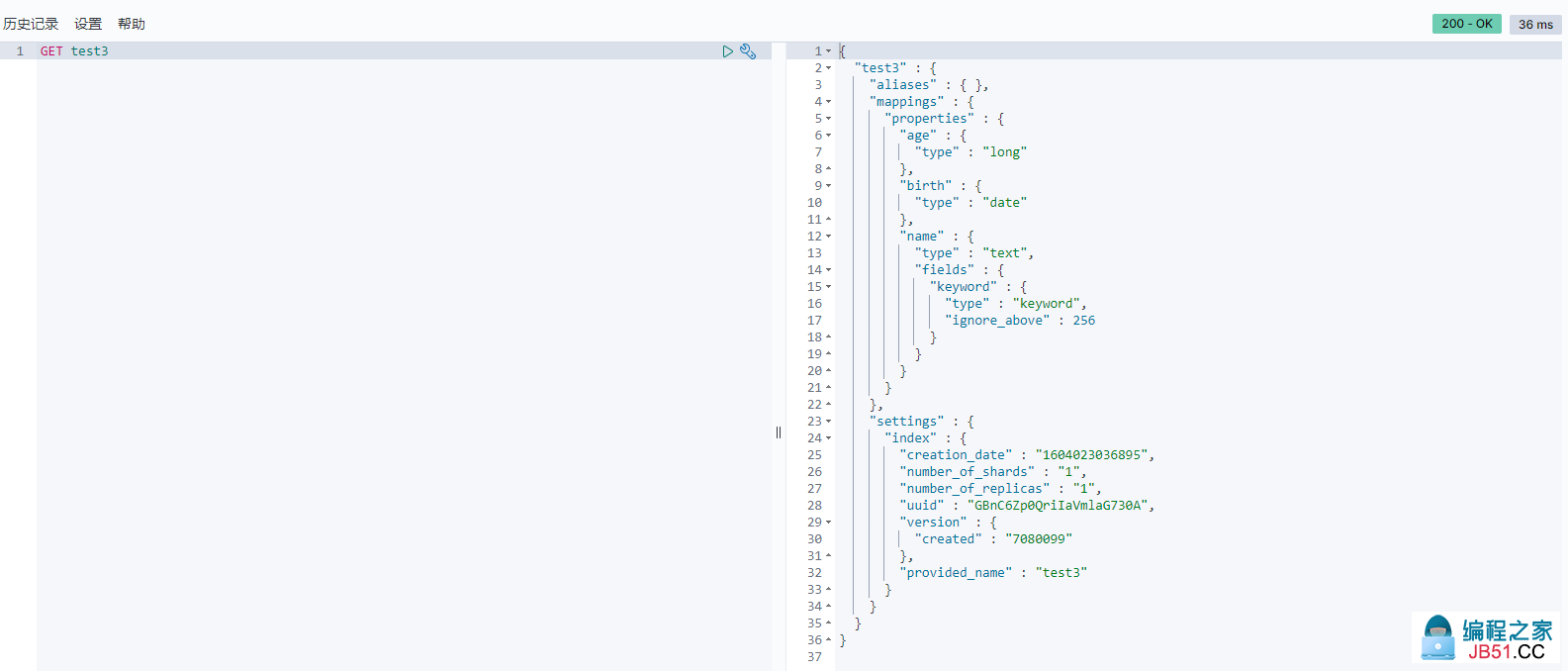
-
如果自己的文档的字段没有指定,那么ES就会给我们默认的配置字段类型
-
通过 GET _cat/ 可以查看当前的ES的很多信息
-

-
-
修改索引
-
提交还是使用PUT即可,然后覆盖 (方法1)
-
缺点: 如果漏写了字段,那么该字段会变成空!
-
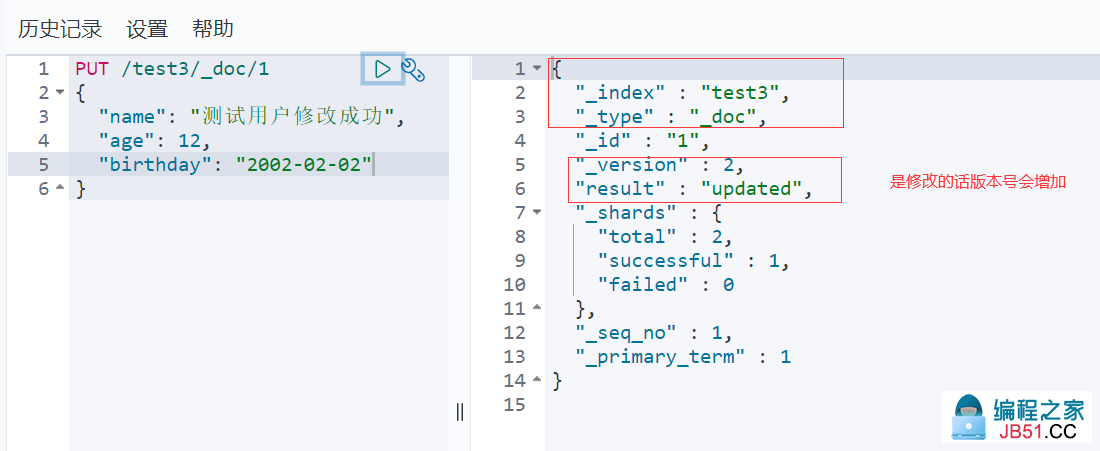
-
使用POST _update,要指定一个字段"doc" (推荐)
-
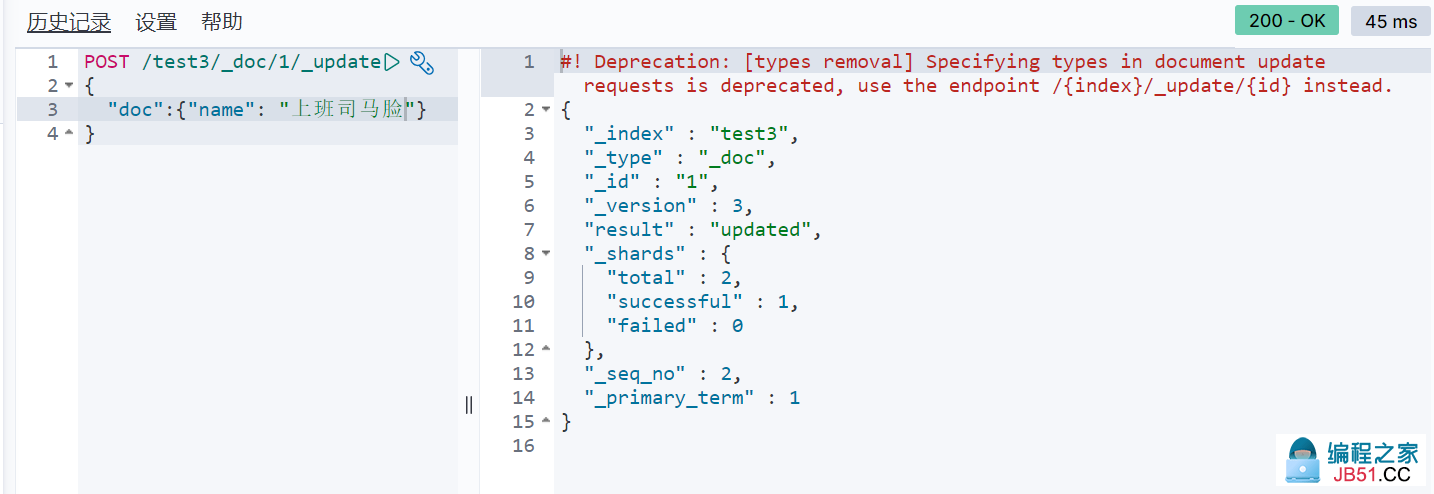
-
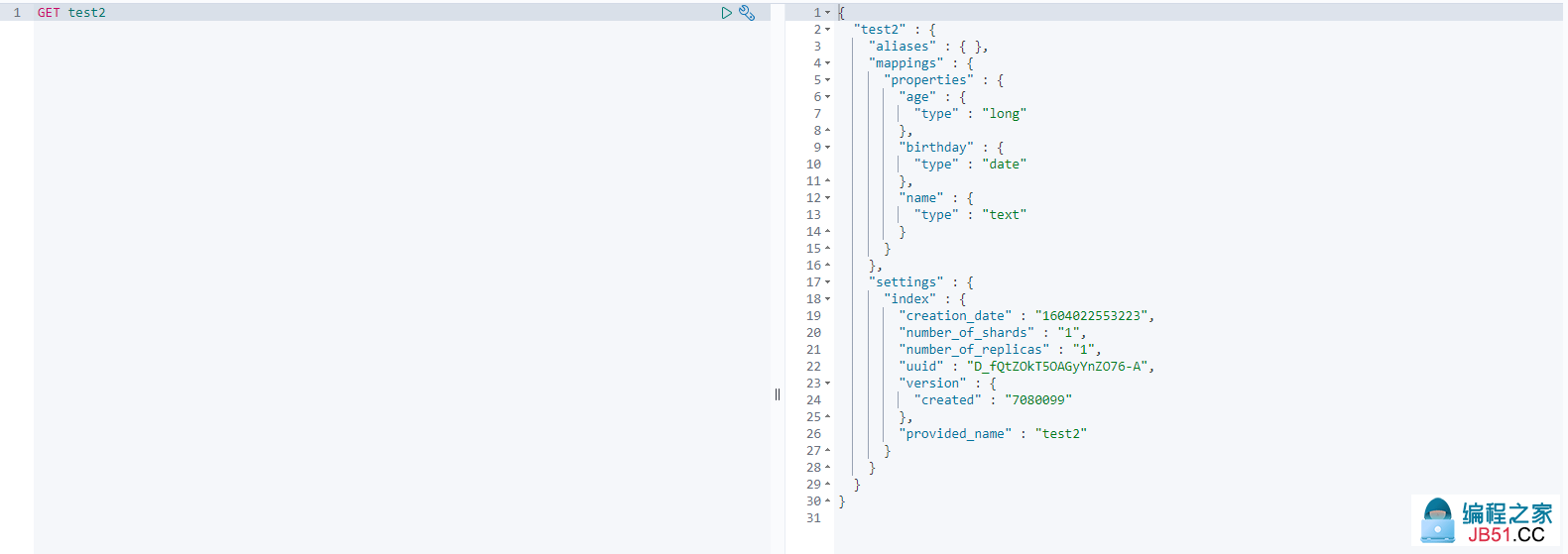
8. 关于文档的基本操作
1. 基本操作
- 简单的搜索
- 简单的条件查询 ==> 可以根据默认的映射规则产生查询结果
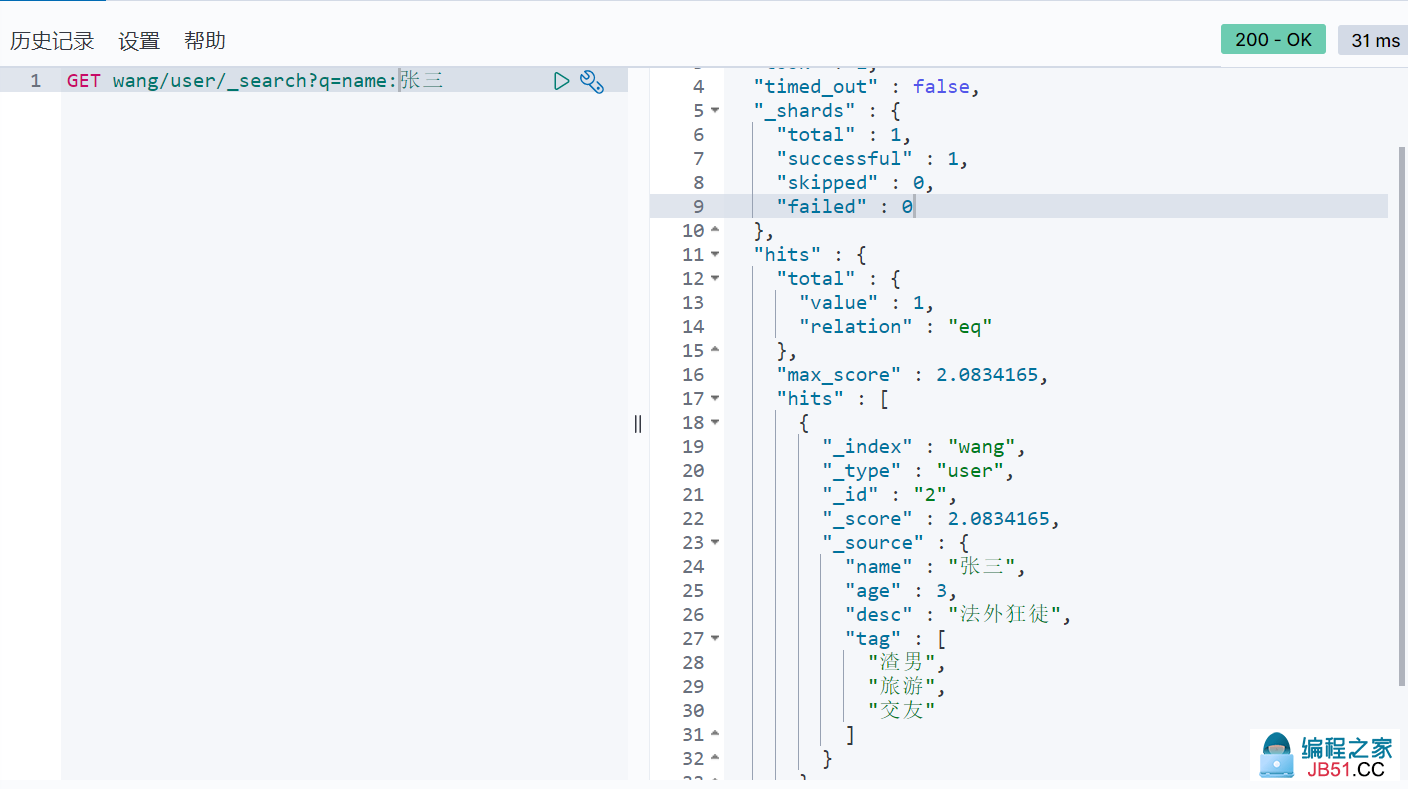
2. 进阶操作
- 复杂的搜索 (select ==> 排序,分页,高亮,模糊查询,精准查询)
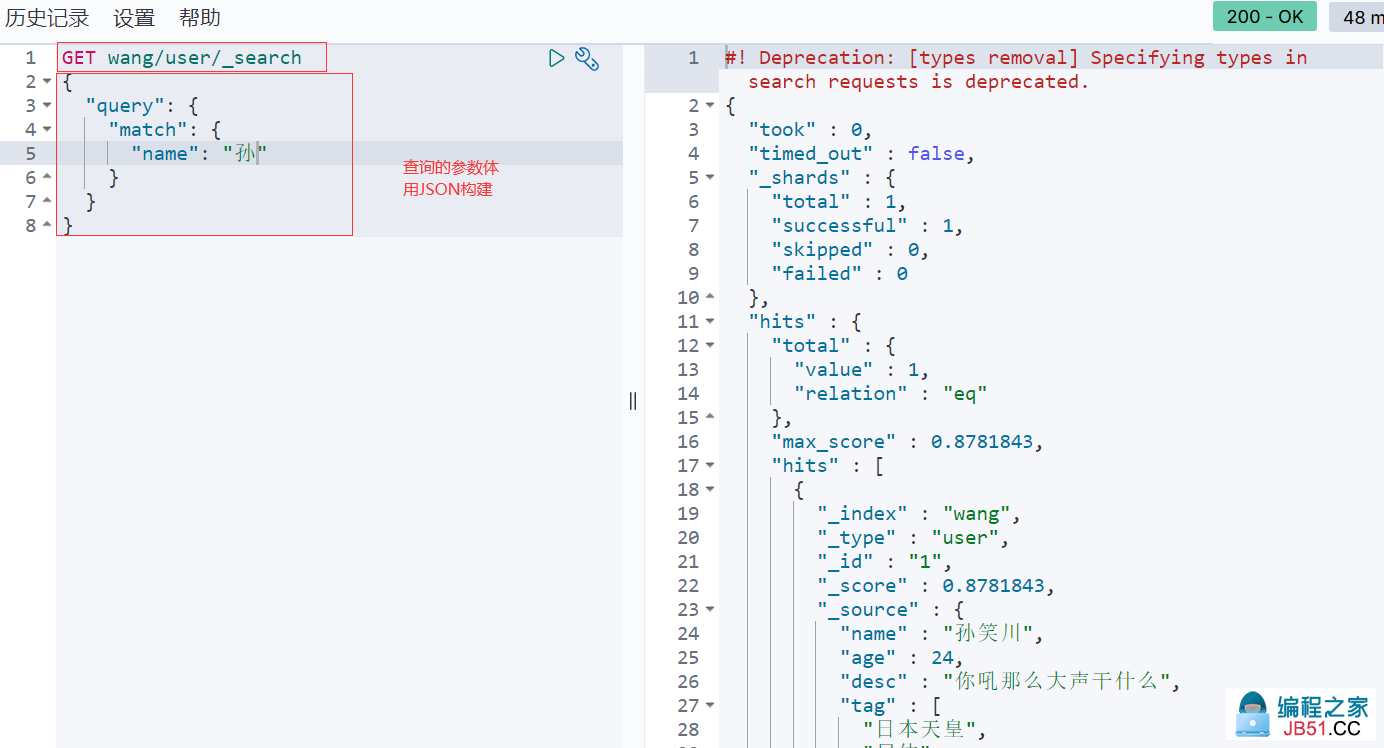
1. 构建查询
-
查询结果的 _score : 匹配度,如果存在多条查询出来的结果,匹配度越高则分值越高
-
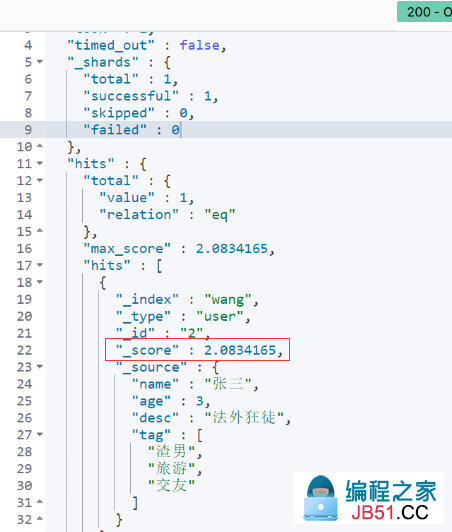
-
-
hit
-
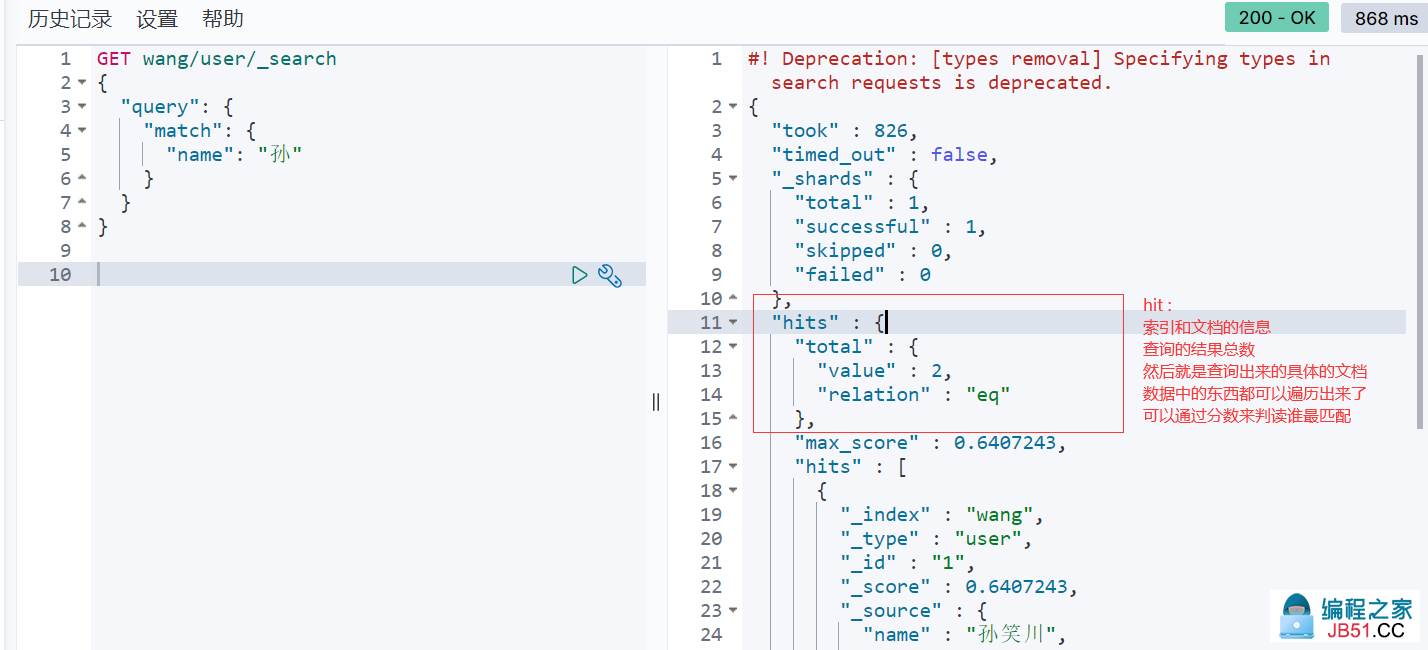
-
结果的过滤(只显示部分的字段)
-
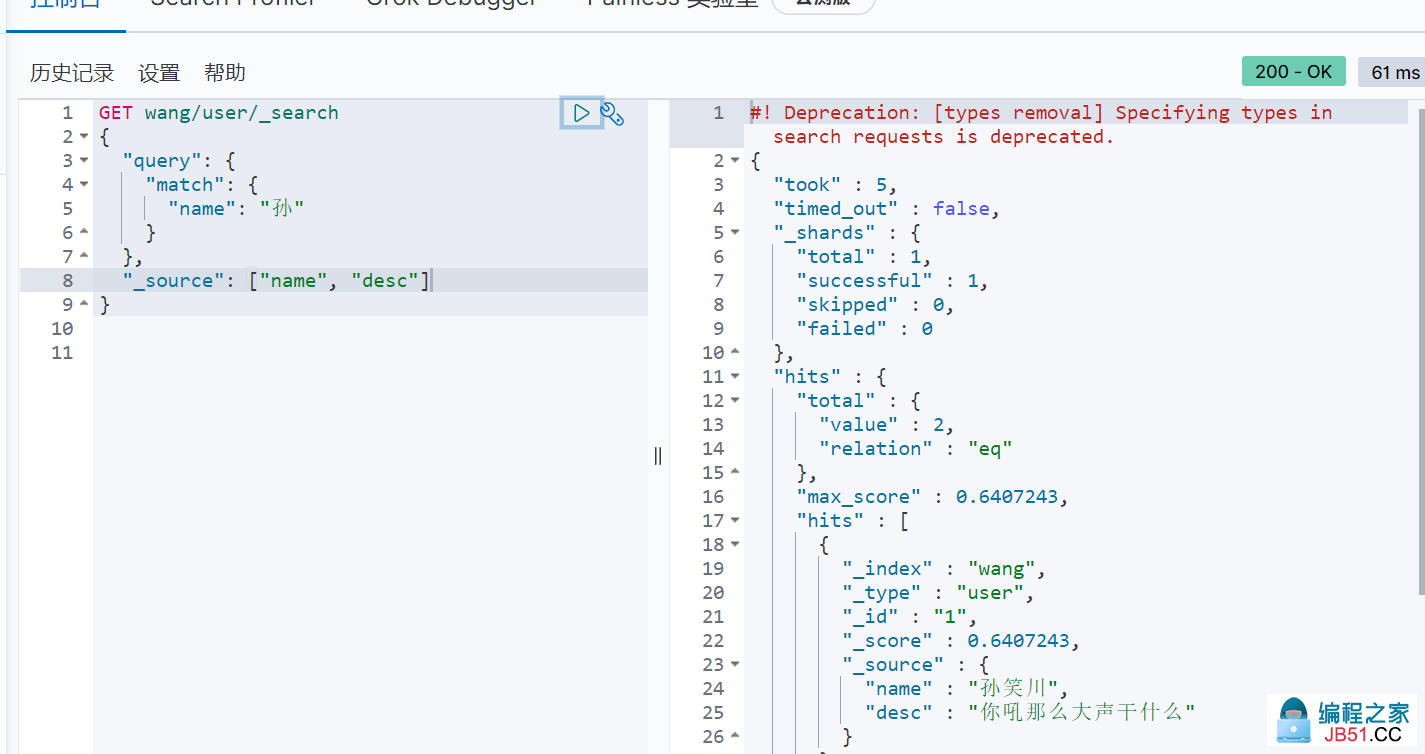
-
使用JAVA操作ES,所有的方法和对象就是这里面的 key!
2. 排序
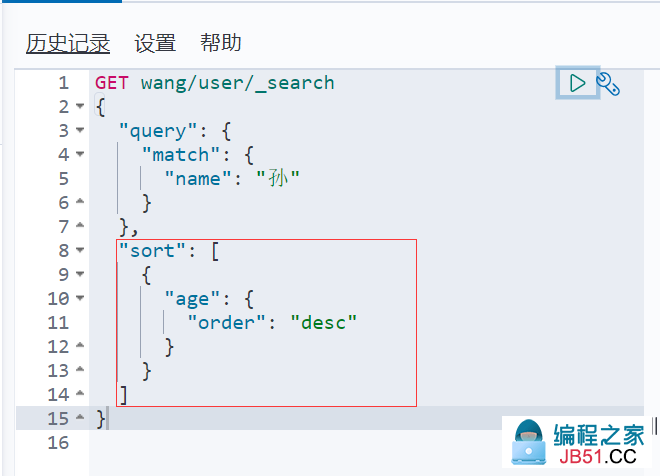
- desc 降序,asc 升序
3. 分页
单页面要显示的数据

数据索引下标还是从 0 开始的,和学的所有的数据结构是一样的!
4. 布尔值查询
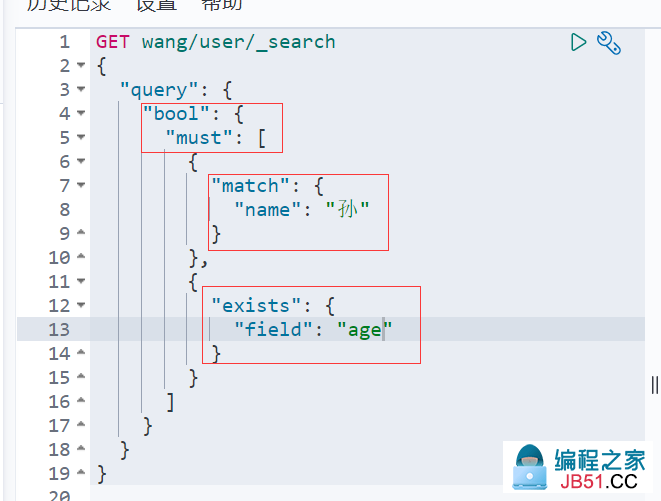
可以通过布尔值进行多条件精确查询
-
must命令 ==> 所有的条件都要符合 (and)
-
should命令 ==> 只要有一条满足即可 (or)
-
must_not命令 ==> 不符合条件才可以 (not)
5. 过滤 (区间)
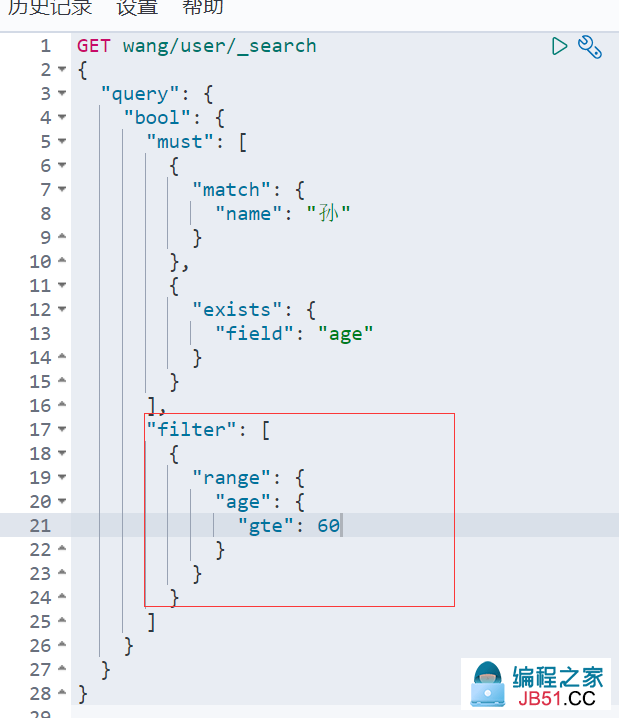
-
gte ==> 大于等于 (gt 大于)
-
lte ==> 小于等于(lt 小于)
-
eq ==> 等于
6. 匹配多个条件
多个条件之间使用空格隔开即可,只要满足其中一个结果就可以被查出,这时候可以通过分值进行基本的判断
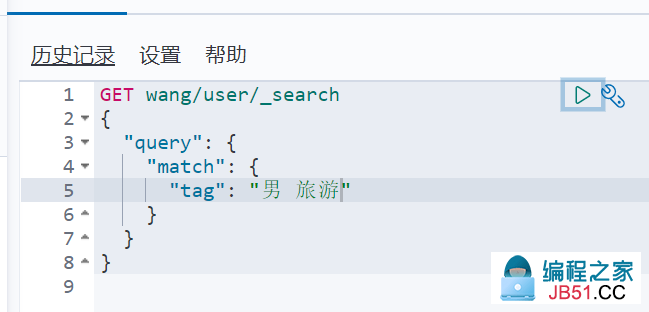
7. 精确查询
-
term 查询是直接通过倒排索引指定的词条进行精确查找的
-
关于分词
- term: 直接查询精确的
- match: 会使用分词器解析! (先分析文档,然后再通过分析的文档进行查询)
-
两个类型
- text: 会被分词器解析
- keyword: 不会被分词器解析
-
精确查询多个值: 利用布尔
8. 高亮查询
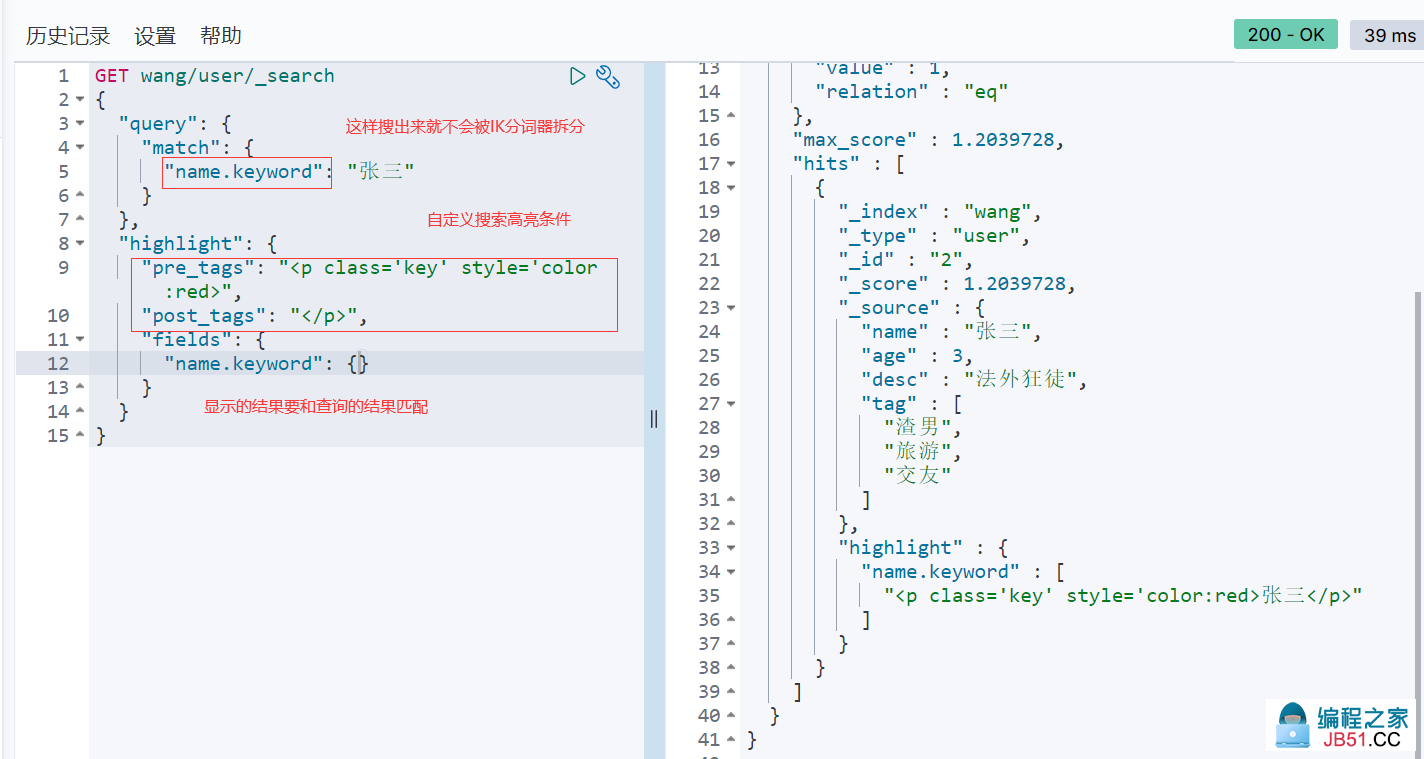
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。