
1. 引言
Elasticsearch是在数据处理生态系统中担任一个开源的分布式搜索和分析引擎的角色,专为存储、检索和分析大量的数据而打造。与此相伴的是Kibana,一个开源数据可视化平台,用于以优雅的方式展示Elasticsearch中的数据,并赋予用户创建仪表盘、图表和报告的能力。然而,实现完整的数据流并不仅止于此。Logstash担任数据处理的角色,使得数据处理的整个过程更加完整。这三大组件就构成了我们平时所说的ELK。下面就开始对Logstash进行详细的介绍。
1.1 什么是Logstash?
Logstash作为一个具备实时流水线功能的开源数据收集引擎,拥有强大的能力。它能够从不同来源收集数据,并将其动态地汇聚,进而根据我们定义的规范进行转换或者输出到我们定义的目标地址。
1.2 Logstash的主要特点
Logstash通过清洗和使数据多样化,Logstash使数据变得适用于各种高级下游分析和可视化用例。此外,Logstash提供广泛的输入、过滤器和输出插件,而且许多本地编解码器进一步简化了数据摄取的过程。无论是数据整理还是提供给下游应用,Logstash都是一个强大且灵活的解决方案。
引用自Logstash官网的图片,更能说明他的角色和功能:
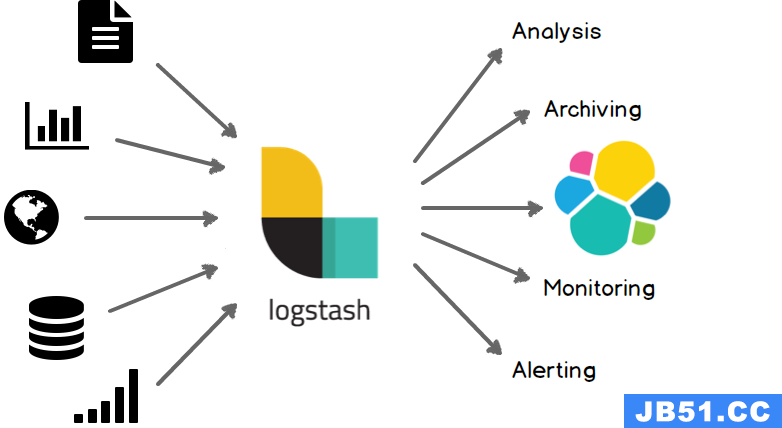
2. 下载与配置
本文使用的是7.17最新的版本7.17.12,7.x版本也是最后支持jdk8的版本,后续8.0默认jdk11起.
2.1 下载
登陆到elastic下载地址,选择产品 Logstash 和版本号 7.17.12
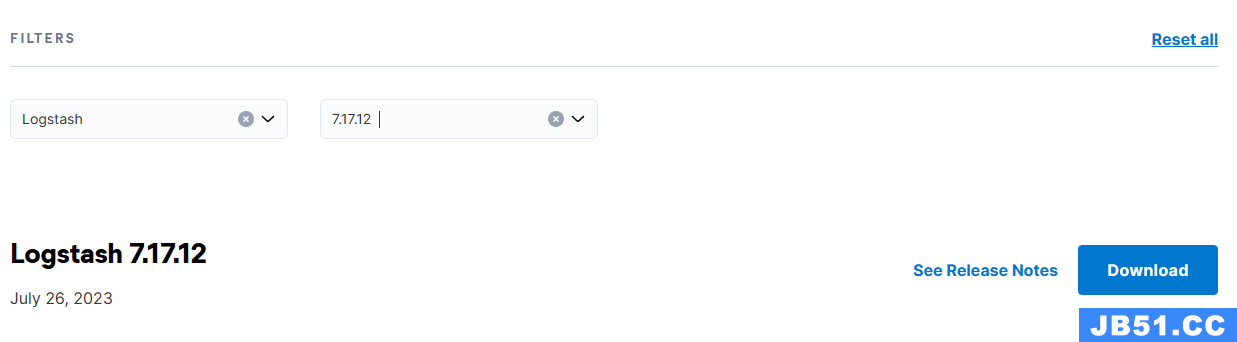
关于系统选择,如果是行x86架构的linux的选择下载LINUX X86_64,如果是windows的就选择WINDOWS,这两个系统没有什么区别,启动和配置都差不多,建议学习测试可以使用windows版本的。
2.2 文件结构
解压后的文件目录如下:
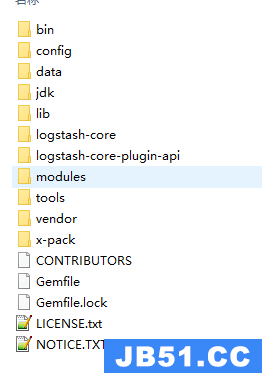
-
bin: 这个目录包含了用于启动Logstash的可执行脚本。例如启动脚本,通过运行这脚本,可以启动Logstash。
-
config: 存放Logstash的配置文件。
-
data: 数据目录用于存储Logstash的持久化数据,如内部状态信息、临时文件等。
-
jdk: 包含Logstash所需的Java Development Kit(JDK)版本。它是Logstash自带的特定JDK版本,以确保Logstash在运行时有所需的Java环境。
-
lib: 该目录通常包含Logstash的依赖库和插件。
-
logstash-core 和 logstash-core-plugin-api: 这些目录包含Logstash核心功能和插件API的代码。Logstash核心实现了数据处理流水线的核心逻辑,而插件API允许开发者创建自定义插件来扩展Logstash的功能。
-
modules: 模块目录包含一些预定义的Logstash模块,用于处理特定类型的数据,如日志、网络流量等。这些模块可以简化配置并提供一些默认设置。
-
tools: 这个目录包含一些用于Logstash的工具,例如性能分析工具等,可用于诊断和优化Logstash的性能。
-
vendor: 该目录包含Logstash所需的依赖库和插件,以及一些其他工具。
-
x-pack: 是Elasticsearch、Kibana、Logstash和Beats的一个扩展功能套件,它提供了一系列的安全性、监控、警报、机器学习和其他高级功能,旨在增强Elastic Stack的功能。
2.3 环境配置
Logstash 推荐在环境变量配置 LS_JAVA_HOME 变量指向jdk目录来使用jdk。配置jdk目录时,我们可以直接使用Logstash 中的jdk目录,省去了另外下载和有可能引起版本不能用的问题。(7.17.12支持的jdk版本只有 jdk8,jdk11和jdk15)
在7.17.12以及之前的版本中还兼容使用我们配置的JAVA_HOME环境变量,后续会取消对该变量的支持。
3. Logstash三大核心组件
Logstash 管道有两个必需元素input(收集源数据)和output(输出数据),以及一个可选元素filter(格式化数据) 。三个插件在源数据和Elasticsearch中的关系如下:
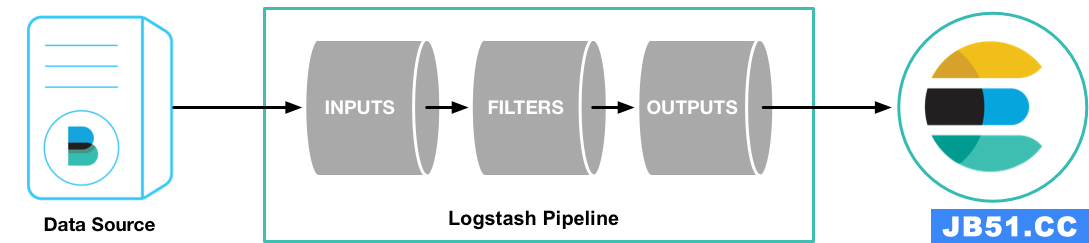
3.1 Input
input是用于从不同数据源收集数据的插件或配置部分。input插件允许您定义数据输入的来源,并将数据发送到Logstash进行后续处理。Logstash支持多种类型的输入插件,每种插件适用于不同的数据源类型。常用的有:
- file:从文件读取源数据
- github:从github提供的网络读取源数据
- http: 通过http/https接收数据
- jdbc: 通过jdbc驱动读取数据
详细的插件可以查看Logstash官网
3.2 Filter
filter是用于对输入的数据进行处理、转换和过滤的部分。filter插件允许在数据进入 Logstash 后(经过input处理),再次对其进行各种操作,以满足特定需求,例如数据清洗、解析、标准化等。Logstash 支持多种类型的 “filter” 插件,每种插件适用于不同的数据处理需求。以下是一些常见的 Logstash “filter” 插件:
- csv:将逗号分隔值数据解析为单个字段
- clone:重复事件
- date:分析字段中的日期以用作事件的 Logstash 时间戳
-
grok:将非结构化事件数据解析为字段
详细的插件可以查看Logstash官网
3.3 Output
output是用于将处理过的数据发送到不同目标的插件或配置部分。output插件允许定义数据输出的目标,并将经过 Logstash 处理后的数据传输到这些目标。Logstash 支持多种类型的输出插件,每种插件适用于不同的数据存储、传输或处理需求。以下是一些常见的 Logstash “output” 插件:
- elasticsearch:存储到elasticsearch
- email:收到输出时将电子邮件发送到指定地址
- file:存储到文件
-
mongodb:将数据写到mongodb中
详细的插件可以查看Logstash官网
4. 动手实践:Hello World例子
4.1 如何启动Logstash
启动logstash比较简单,只需要执行bin目录下的 logstash(linxu)或者logstash.bat(windows)。
# linux启动命令
./bin/logstash
# windows启动命令
.\bin\logstash.bat
4.2 常用的配置文件详解
在编写示例前,需要先了解一下重要的配置文件
- logstash.yml:是 Logstash 的主要配置文件,它包含了 Logstash 的全局设置和选项。在这个文件中,您可以配置各种全局参数,如网络设置、路径、日志设置等。这个文件可以影响 Logstash 的整体行为。
一些常见的配置项包括:
pipeline.batch.size:指定每个批次处理的事件数量。
pipeline.batch.delay:指定每个批次之间的延迟时间。
path.data:指定 Logstash 数据的存储路径。
http.host:指定 HTTP 监听的主机名。
http.port:指定 HTTP 监听的端口号。
pipeline.workers:指定并行处理事件的工作线程数量。
queue.type: 指定队列的存储类型,可选memory(内存)和persisted(持久)
- pipelines.yml:用于配置和管理 Logstash 数据处理流水线的配置文件。Logstash 可以同时运行多个数据处理流水线,每个流水线都有自己的输入、过滤器和输出配置。
- jvm.options:是用于配置 Logstash JVM(Java Virtual Machine)选项的文件。这个文件影响 Logstash 的性能和资源分配。可以在这个文件中配置堆内存大小、垃圾回收选项等。
一些常见的配置项包括:
-Xmx:指定 Java 堆内存的最大值。
-Xms:指定 Java 堆内存的初始值。
-XX:+UseConcMarkSweepGC:指定使用 CMS(Concurrent Mark-Sweep)垃圾回收器。
-Djava.io.tmpdir:指定临时文件的存储路径。
- logstash-sample.conf:是一个示例的 Logstash 配置文件,用于演示如何配置数据的输入、过滤和输出。这个文件包含了各种插件的配置示例,帮助我们了解如何构建一个完整的 Logstash 数据处理流水线。
4.3 编写并运行"Hello World"示例
在logstash根目录下执行
# windows执行
.\bin\logstash.bat -e "input { stdin { } } output { stdout {} }"
#linux执行
bin/logstash -e 'input { stdin { } } output { stdout {} }'
启动 Logstash 后,请等待,直到看到][main] Pipeline started {"pipeline.id"=>"main"},然后在命令提示符下输入:hello world
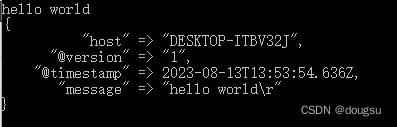
4.4 使用 -f 参数指定配置文件启动
上面的例子我们直接采用参数 -e后跟随管道配置方式启动,我们还可以使用-f参数指定我们的配置文件方式启动。在跟目录下创建hello.conf文件,文件内容:
input { stdin { } }
output { stdout { } }
然后执行启动命令
# windows执行
.\bin\logstash.bat -f hello.conf
#linux执行
bin/logstash -f hello.conf
4.5 在pipeline中配置启动
打开config目录下的pipelines.yml文件,输入
- pipeline.id: hello
pipeline.workers: 1
pipeline.batch.size: 1
config.string: "input { stdin { } } output { stdout {} }"
除了直接配置管道处理规则,我们还可以指向刚刚编写的hello.conf文件
- pipeline.id: hello
pipeline.workers: 1
pipeline.batch.size: 1
path.config: "/usr/local/logstash/hello.conf"
保存文件后执行:
# windows执行
.\bin\logstash.bat
#linux执行
bin/logstash
5. 实战:定时滚动同步MySQL数据
5.1 环境与数据准备
5.1.1 数据库准备
需要提前准备好mysql的表结构和测试数据:
# 建表语句
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`content` varchar(255) DEFAULT NULL,
`status` int(11) DEFAULT NULL,
`update_time` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
# 插入数据
insert into test (content,status,update_time) VALUES ("aaa",1,UNIX_TIMESTAMP());
insert into test (content,update_time) VALUES ("bbb",update_time) VALUES ("ccc",2,update_time) VALUES ("ddd",UNIX_TIMESTAMP());
5.1.2 启动elasticsearch和kibana
需要启动好elasticsearch和kibana,并且elasticsearch需要开启允许自动创建索引,如果没有开启需要事先创建好索引
5.1.3 导入mysql的jar
在logstash根目录下创建一个mylib的目录,用于存放java连接mysql的jar文件,例如:mysql-connector-java-8.0.27.jar
5.2 编写脚本
5.2.1 根据id滚动同步数据
需求:每分钟执行根据test表的id从小到大并且status等于1保存elasticsearch中,每次执行的数量是2条
在logstash跟目录下创建 mysql-by-id-to-es.conf 文件,文件内容:
input {
jdbc {
jdbc_driver_library => "./mylib/mysql-connector-java-8.0.27.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/test"
jdbc_user => "root"
jdbc_password => "123456"
parameters => { "myStatus" => 1 }
schedule => "* * * * *"
statement => "SELECT id,content,status,update_time FROM test WHERE status = :myStatus AND id > :sql_last_value ORDER BY id ASC LIMIT 2"
last_run_metadata_path => "mysql-by-id-to-es.index"
tracking_column => "id"
use_column_value => true
tracking_column_type => "numeric"
}
}
filter {
mutate { add_field => { "from" => "logstash" } }
}
output {
elasticsearch {
index => "test-by-id-%{+YYYY.MM}"
}
stdout {
}
}
保存好文件内容,在logstash根目录下执行-f启动命令
# windows执行
.\bin\logstash.bat -f mysql-by-id-to-es.conf
# linux执行
./bin/logstash.bat -f mysql-by-id-to-es.conf
控制台打印信息:
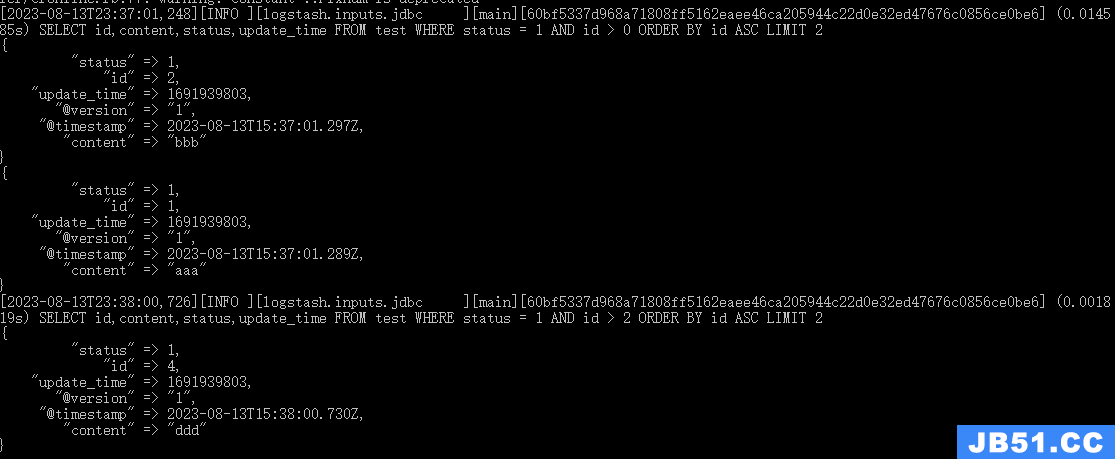
到kibana执行查看数据:
1.先执行GET _cat/indices?v 查看是否存储以test-by-id开头的索引

2.如果索引存在,执行查看数据的语句GET test-by-id-2023.08/_search{ "query": {"match_all": {}}},可以发现status等于2的记录不会被录入
{
"_index" : "test-by-id-2023.08",
"_type" : "_doc",
"_id" : "FsWU74kBjZ5FwUtCTy7a",
"_score" : 1.0,
"_source" : {
"update_time" : 1691939803,
"@version" : "1",
"content" : "aaa",
"@timestamp" : "2023-08-13T15:47:01.008Z",
"status" : 1,
"id" : 1,
"from" : "logstash"
}
},
{
"_index" : "test-by-id-2023.08",
"_id" : "FcWU74kBjZ5FwUtCTy7a",
"content" : "bbb",
"@timestamp" : "2023-08-13T15:47:01.020Z",
"id" : 2,
"_id" : "F8WV74kBjZ5FwUtCNS6W",
"content" : "ddd",
"@timestamp" : "2023-08-13T15:48:00.413Z",
"id" : 4,
"from" : "logstash"
}
}
5.2.2 根据更新时间滚动同步数据
如果希望通过数据的更新时间录入,新建**mysql-by-uptime-to-es.conf文件,文件内容:
input {
jdbc {
jdbc_driver_library => ",/mylib/mysql-connector-java-8.0.27.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/test"
jdbc_user => "root"
jdbc_password => "123456"
parameters => { "myStatus" => 1 }
schedule => "* * * * *"
statement => "SELECT id,update_time FROM test WHERE status = :myStatus AND update_time > :sql_last_value"
last_run_metadata_path => "mysql-by-uptime-to-es.index"
}
}
filter {
mutate { add_field => { "from" => "logstash" } }
}
output {
elasticsearch {
index => "test-by-uptime-%{+YYYY.MM}"
}
stdout {
}
}
保存文件,启动和查看数据请参考前面的5.2.1
5.3 配置参数详解
- jdbc_driver_library: 指定 JDBC 驱动程序的路径。JDBC 驱动程序是用于与特定类型的数据库进行通信的库。您需要提供 JDBC 驱动程序的路径,以便 Logstash 能够加载并使用它。
- jdbc_driver_class: 指定 JDBC 驱动程序的 Java 类名称。这个类名告诉 Logstash 使用哪个具体的 JDBC 驱动程序来连接到数据库。
- jdbc_connection_string: 指定与数据库建立连接的连接字符串。这个字符串包括数据库的位置、端口、数据库名称等信息。
- jdbc_user: 指定连接数据库所需的用户名。
- jdbc_password: 指定连接数据库所需的密码。
- parameters: 这个配置允许您指定自定义的 JDBC 连接参数,以便传递到连接字符串中。这可以包括诸如 SSL 配置、字符集等选项。
- schedule: 指定从数据库中提取数据的调度时间表。使用 cron 表达式来定义数据抽取的时间间隔。
例子:
- 5 * 1-3 * 将在 5 月至 <> 月的每一天凌晨 <> 点执行一次。
0 * * * * 将在每天每小时的第 0 分钟执行。
0 6 * * * America/Chicago 将在每天上午 6:00 (UTC/GMT -5) 执行。
- statement: 这个配置定义从数据库中抽取数据的 SQL 查询语句。可以在这里编写自定义的 SQL 查询来选择需要的数据。
- last_run_metadata_path: 指定一个文件路径,用于存储上次运行的元数据。这可以帮助 Logstash 跟踪上一次数据抽取的时间,以便从上次抽取的位置继续。
-
tracking_column和 use_column_value: 这两个配置一起使用,用于标识一个列,以便进行增量抽取。
tracking_column指定增量抽取时用来跟踪的列名,而use_column_value指示是否使用列的值作为跟踪标记。 -
tracking_column_type: 指定跟踪列的数据类型。这是用于支持不同数据类型的跟踪列,如日期时间、数字等。目前仅支持
numeric和timestamp,默认是timestamp。 - add_field:增加一个属性并且指定默认的值。
- elasticsearch:输出到elasticsearch中,常用的配置如下:
elasticsearch {
# 配置es地址,有多个使用逗号隔开,不填默认就是 localhost:9200
hosts => ["localhost:9200"]
# 配置索引
index => "test-by-uptime-%{+YYYY.MM}"
# 配置账号和密码,默认不填
user => "elastic"
password => "123456"
}
6.总结
本文通过详细介绍Logstash的核心组件和功能,涵盖如何从下载安装到编写第一个Hello World示例,再到定时同步MySQL数据到Elasticsearch的完整过程。希望此教程能成为您学习和掌握Logstash的重要参考。
原文地址:https://blog.csdn.net/dougsu/article/details/132261486
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。