
1、一般后台会报primary shard is not active Timeout: …
出现这种问题表示该索引是只读了,没办法进行shard及存储操作,优先排除是系统存储盘满了
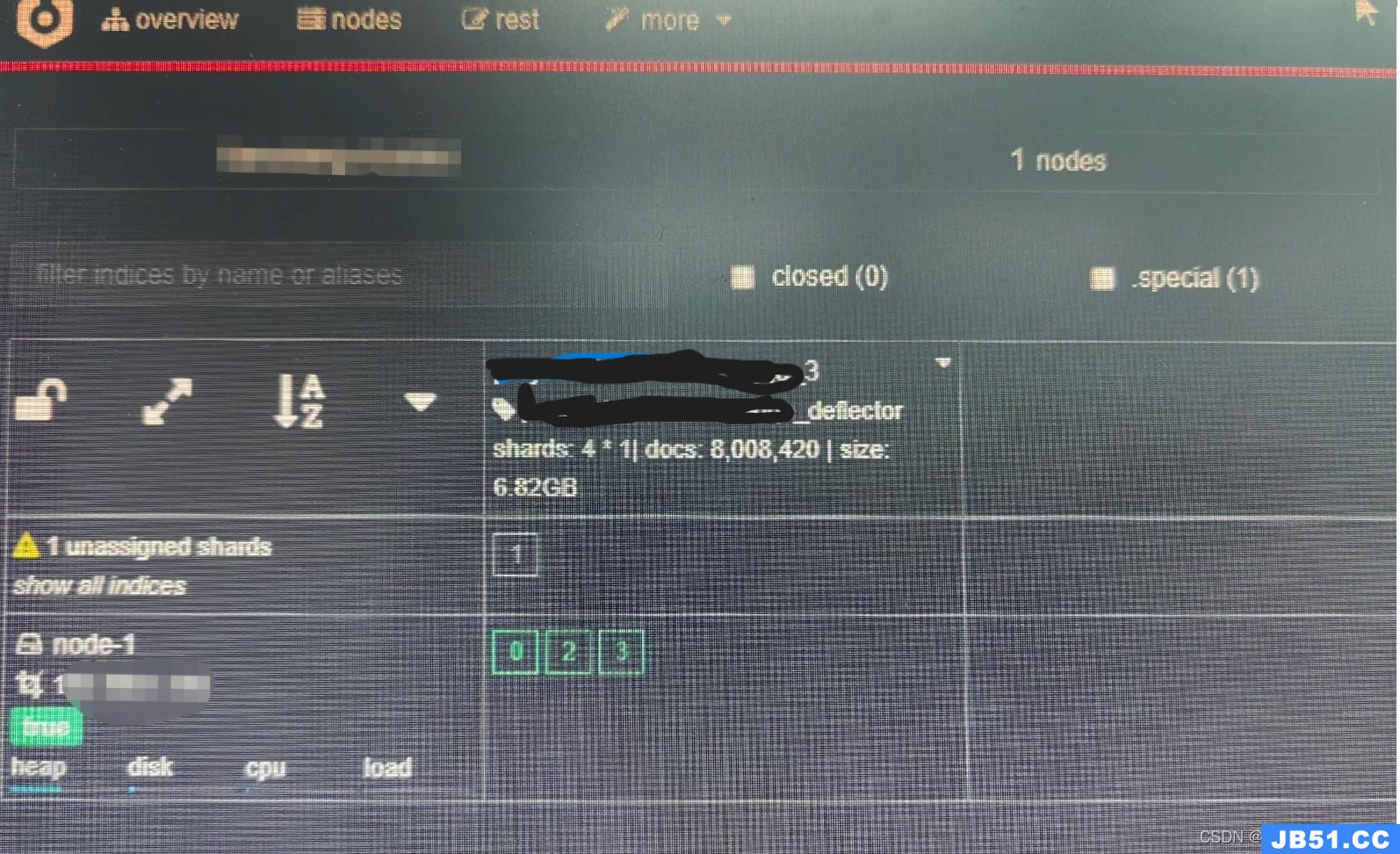
2、通过监控工具查看(cerebro)
发现该索引shard 1 损坏
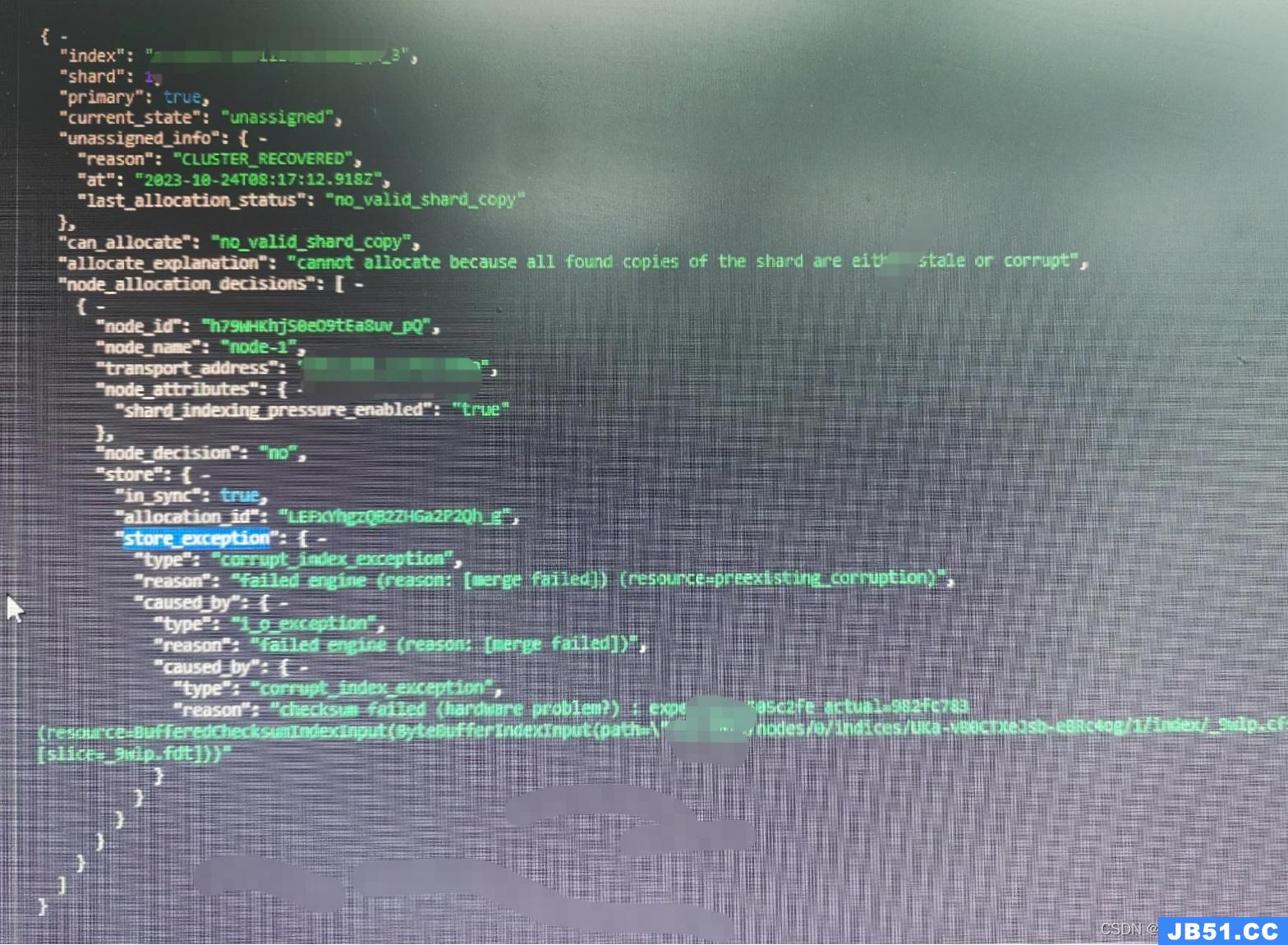
也可以通过命令进行查看
GET _cluster/allocation/explain?pretty
3、问题原因
1. Shard allocation 过程中的延迟机制
2. nodes 数小于分片副本数
3. 检查是否开启 cluster.routing.allocation.enable 参数
4. 分片的历史数据丢失了
5. 磁盘不够用了
6. es 的版本问题
4、 问题解决
4.1、 简单粗暴方式解决(删索引)
如果该索引数据是日志记录,非必要数据可进行删除该索引即可解决,如:监控数据,丢了就丢了,因为你只关注当前的
4.2、Shard allocation 过程中的延迟机制
当一个 点从集群中下线了, es 有一个延迟拷贝机制, 默认是等一分钟之后再开始处理 unassigned 的分片, 该做 rebalance的去 rebalance,只所以这样, 是因为es担心如果一个点只是中断了片刻, 或者临时下线某台机器,就立马大动干戈,就尴尬了,比如下面这种情形
Node(节点) 19 在网络中失联了(某个家伙踢到了电源线)
Master 立即注意到了这个节点的离线,它决定在集群内提拔其他拥有 Node 19 上面的主分片对应的副本分片为主分片
在副本被提拔为主分片以后,master 节点开始执行恢复操作来重建缺失的副本。集群中的节点之间互相拷贝分片数据,网卡压力剧增,集群状态尝试变绿。
由于目前集群处于非平衡状态,这个过程还有可能会触发小规模的分片移动。其他不相关的分片将在节点间迁移来达到一个最佳的平衡状态
与此同时,那个踢到电源线的倒霉管理员,把服务器插好电源线进行了重启,现在节点 Node 19 又重新加入到了集群。不幸的是,这个节点被告知当前的数据已经没有用了, 数据已经在其他节点上重新分配了。所以 Node 19 把本地的数据进行删除,然后重新开始恢复集群的其他分片(然后这又导致了一个新的再平衡)
如果这一切听起来是不必要的且开销极大,那就对了。是的,不过前提是你知道这个节点会很快回来。如果节点 Node 19 真的丢了,上面的流程确实正是我们想要发生的。
这个默认的延迟分配分片的实际是1分钟, 当然你可以设置这个时间
curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d '
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "30s"
}
}'
4.3、nodes 数小于分片副本数
当一个nodes 被下掉之后, master 节点会重新 reassigns 这台nodes上的所有分片, 尽可能的把同一个分片的不同副本分片和主分片分配到不同的node上,但是如果你设置的一个分片的 副本数目太多, 导致根本没法一个 node上分配一个,就会出现问题, 会导致 es 没法进行 reassign, 这样就会出现 unassigned 的分片。
从一开始创建index 的时候就要保证N >= R + 1这里 N 代表 node的个数, R代表你index 的副本数目。
这种情况要么增加 nodes 个数要么减少副本数
curl -XPUT 'localhost:9200/<INDEX_NAME>/_settings' -d '{"number_of_replicas": 2}'
我们上个例子中,就把 副本数目减少到 2个, 问题解决。
注释:目前我就是属于单节点,但没办法调整分片数与节点数关系达到平衡,所以我这里直接删了索引
4.4检查是否开启 cluster.routing.allocation.enable 参数
Shard allocation 功能默认都是开启的, 但是如果你在某个时刻关闭了,这个功能(比如滚动重启的情形, https://www.elastic.co/guide/en/elasticsearch/guide/current/_rolling_restarts.html ), 后面忘了开启了,也会导致问题, 你可以使用下面这个命令开开启下
curl -XPUT 'localhost:9200/_cluster/settings' -d
'{ "transient":
{ "cluster.routing.allocation.enable" : "all"
}
}'
恢复之后, 你可以从监控上,看到 unassigned shards 逐渐恢复
看监控中,几个index都恢复了,好像还有constant-updates这个index 没有好,我们看下是否还有其他原因
分片的历史数据丢失了
我们现在的问题是这样, constant-updates 这个index 的第 0个分片处于 unassigned 状态, 创建这个index 的时候 每个分片只有 一个 主分片,没有其他副本, 数据没有副本, 集群检测到这个分片的 全局状态文件,但是没有找到原始数据, 就没法进行恢复。
还有一种可能是这样, 当一个node 重启的时候, 会重新连接集群, 然后把自己的 disk 文件信息汇报上去, 这时候进行恢复,如果这个过程出现了问题,比如存储坏掉了,那么当前分片还是没法恢复正常。
这个时候,你可以考虑下,是继续等待原来的那台机器恢复然后加入集群,还是重新强制分配 这些 unassigned 的分片, 重新分配的时候也可以使用备份数据。
如果你打算重新强制分配主分片,可以使用下面的命令,记得带上"allow_primary": “true”
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{ "commands" :
[ { "allocate" :
{ "index" : "constant-updates", "shard" : 0, "node": "<NODE_NAME>", "allow_primary": "true" }
}]
}'
如果你没有带上"allow_primary": “true”,就会报错
{"error":{"root_cause":[{"type":"remote_transport_exception","reason":"[NODE_NAME][127.0.0.1:9301][cluster:admin/reroute]"}],
"type":"illegal_argument_exception","reason":"[allocate] trying to allocate a primary shard [constant-updates][0],which is disabled"},
"status":400}
因为没有当前分配的分片是没有主分片了。
当然你在重新强制分配主分片的时候,可以创建一个 empty 的主分片,也就是老数据我不要了, 这个时候,如果失联的 node 重新加入集群后, 就把自己降级了, 分片的数据也会使用 这个 empty 的主分片覆盖, 因为它已经变成过时的版本了。
POST _cluster/reroute
{
"commands" : [ {
"allocate_empty_primary" :
{
"index" : "constant-updates", "node" : "<NODE_NAME>", "accept_data_loss" : true
}
}
]
}
这个命令就可以创建一个 empty 的主分片。
4.5、磁盘不够情况解决
4.5.1、先进行查询
curl -s 'localhost:9200/_cat/allocation?v'
4.5.2、如果磁盘空间比较有剩余可以调整low disk watermark的磁盘使用比例也是可以设置的
curl -XPUT 'localhost:9200/_cluster/settings' -d
'{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "90%"
}
}'
4.5.3、可通过扩容物理磁盘并更改es配置
可以修改配置文件opensearch.yml或elasticsearch.yml进行配置在新的磁盘用逗号隔开,重启es
path.data:/test/data1,/test/data2
4.6、es 的版本问题
还有一种极端情况, 就是你升级了某个node的版本, master node 会不认这个跟它版本不同的的node, 也不会在上面分配分片。
如果你手动强制往上面分配分片,会报错。
[NO(target node version [XXX] is older than source node version [XXX])]
大体就这几种情况,你可以根据自己的观察到的现象去判断。
总结
针对不同情况需要进行不同的处理,能不删数据尽量不删数据,如果有更好的解决方案,或者没有解决你的问题欢迎留言一起讨论
原文链接:
https://www.cnblogs.com/lvzhenjiang/p/14196973.html
https://blog.csdn.net/syc000666/article/details/94910375
原文地址:https://blog.csdn.net/weixin_40436144/article/details/134157135
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。