
0、实战问题

老师有个问题想请教一下,我们项目中有个需求是查询出数据集根据某个字段去重后的全部结果,用 collapse 发现很多数据都没查询到,后面发现是去重的这个字段的值太长了,ignore _above默认的是256,而这个字段的值有的有十几万甚至几十万个字符,像这种情况,还有什么比较好的查询去重方法吗?
——来自:死磕Elasticsearch知识星球
https://t.zsxq.com/15t8cCz6s
1、之前有讲述logstash fingerprint filter 去重
参见:fingerprint filter 插件——Elasticsearch 去重必备利器
那么有没有其他的实现方式呢?
2、 fingerprint processor 实现去重
2.1.1 fingerprint processor定义
在 Elasticsearch 中,Fingerprint(指纹)通常指的是一种机制,用于为数据生成一个唯一的标识符或指纹。这个指纹是基于数据内容的一个哈希值,可用于识别和区分数据项。

2.1.2 fingerprint processor产生背景
在处理大量数据时,尤其是在日志聚合或数据索引的场景中,去重变得非常重要。
Fingerprint 可以帮助识别重复的数据。通过对数据生成指纹,可以确保数据在传输或处理过程中的完整性。
2.1.3 fingerprint processor 用途
唯一标识: 用于给数据生成一个唯一标识,以便跟踪和管理。
数据对比: 通过比较不同数据的指纹,可以快速判断它们是否相同。
安全性和合规: 在安全性和合规性要求高的场景下,用于确保数据的一致性和完整性。
2.1.4 fingerprint processor使用详解
### 定义finger_print processor
PUT _ingest/pipeline/fp_processor
{
"processors": [
{
"fingerprint": {
"fields": [
"content"
]
}
}
]
}
### 创建索引
DELETE news_index
PUT news_index
{
"settings": {
"default_pipeline": "fp_processor"
}, "mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}
### 批量写入数据
PUT news_index/_bulk
{"index":{"_id":1}}
{"content":"雷军:小米汽车正在试产爬坡阶段,定价“有理由的贵”"}
{"index":{"_id":2}}
{"content":"雷军剧透小米汽车发布会:对标保时捷、特斯拉 定价有点贵身"}
{"index":{"_id":3}}
{"content":"雷军:小米汽车正在试产爬坡阶段,定价“有理由的贵”"}
### 执行检索
POST news_index/_search召回结果如下:
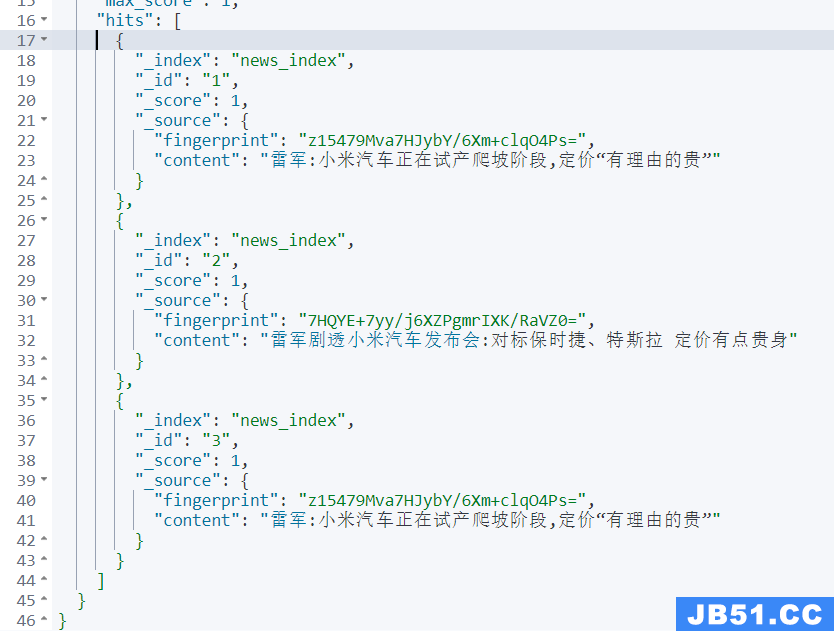
注意:
由于_id为1和_id 为3 的两个 content 一致,所以它们的 fingerprint 也是一致的。
这样就可以再基于 fingerprint 字段实现 collapse 操作就可以很好的实现去重了。
3、关于 fingerprint,还有分词器
关于 Elasticsearch 中的 Fingerprint 分析器(或者称为分词器),一个常见且易于理解的应用场景是在数据清洗过程中用于识别和合并重复的记录。
例如,考虑一个包含用户信息的数据集,其中由于录入错误或不一致的格式,同一用户的多个记录可能以略微不同的方式出现。使用 Fingerprint 分析器,我们可以生成每条记录的唯一指纹,从而轻松识别和合并这些重复的记录。
参见下面的真实举例,在地址或人名数据的去重中,Fingerprint 分析器可以帮助识别本质上相同但表述略有差异的记录。
3.1 fingerprint 分词器使用场景示例
假设我们有一个包含人名的数据集,由于不同的输入习惯,同一个人名可能有不同的表述方式,比如:
"John Smith"
"smith, john"
"John Smith" (多个空格)虽然这些记录代表同一个人,但由于格式和空格的差异,它们可能被视为不同的记录。
扩展场景:
数据聚类: 通过创建文本的“指纹”,可以更容易地识别和聚集相似或重复的条目。
数据清洗和去重: 在大型数据集中识别和合并重复或相似的记录。
文本分析: 提供一种标准化和简化的文本表示,有助于后续的文本分析和处理。
3.2 使用 Fingerprint 分析器详解

为了标准化并识别这些记录,我们可以在 Elasticsearch 中定义一个使用 Fingerprint 分析器的索引。
以下是完整的 DSL 示例:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_fingerprint_analyzer": {
"type": "fingerprint", "stopwords": "_english_"
}
}
}
}, "mappings": {
"properties": {
"name": {
"type": "text", "analyzer": "my_fingerprint_analyzer"
}
}
}
}
POST my_index/_bulk
{"index":{"_id":1}}
{"name": "John Smith"}
{"index":{"_id":2}}
{"name": "smith, john"}
{"index":{"_id":3}}
{"name": "John Smith"}如上DSL 解读如下:在 settings 下定义了一个自定义的分析器 my_fingerprint_analyzer,它使用 Elasticsearch 的 Fingerprint 分析器类型,并配置了英语停用词列表。
"stopwords": "english" 是指在使用某些文本分析器(比如 Fingerprint 分析器)时,应用预定义的英语停用词列表。
停用词是在文本处理中通常被排除的词汇,因为它们过于常见而且通常不携带重要的含义或信息,比如 "the","is","at","which" 等。
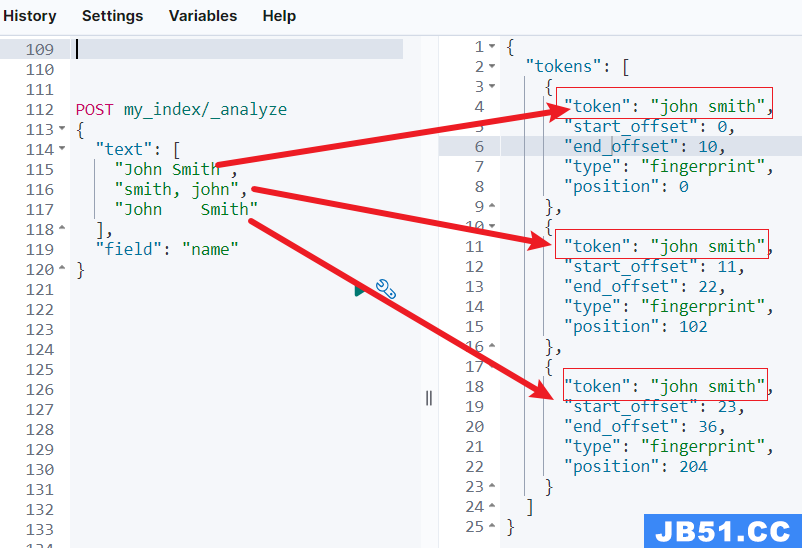
POST my_index/_search
POST my_index/_analyze
{
"text": [
"John Smith", "smith, john", "John Smith"
], "field": "name"
}执行结果如下:
3.3 Fingerprint 分析器工作原理
从上面的结果不难看出,即使上述三条记录在某些细节上不同,它们也会生成相同的指纹,从而可以被识别为代表同一用户的记录。
尤其:"smith,john" 也会做字母排序处理,变成“john smith”。
通过这种方式,Fingerprint 分析器帮助我们识别和合并数据集中的重复记录,从而提高数据的一致性和准确性。
Fingerprint 分析器可实现功能列表如下:
转换为小写(Lowercased):
将输入文本中的所有字符都被转换为小写,这有助于确保文本处理不受字母大小写的影响,提高数据的一致性。比如,前文中的“john smith”就是例证。
标准化移除扩展字符(Normalized to Remove Extended Characters):
文本中的扩展字符(如重音符号或其他非标准ASCII字符)被转换或移除。这一步骤有助于统一不同格式或编码方式的文本。
排序(Sorted):
文本中的单词(或标记)被按字典顺序排序。排序后,相同的单词组合(无论原始顺序如何)将被视为相同,有助于数据聚类和去重。
去重(Deduplicated):
重复的单词或标记在排序后被移除。这减少了数据的冗余性,使每个文本的表示更加紧凑和唯一。
合并成单个标记(Concatenated into a Single Token):
经过上述处理后的单词或标记被合并成一个单一的长字符串标记。这样做的目的是创建一个独特的“指纹”,用于表示原始文本。
停用词移除(Stop Words Removal,如果配置了停用词列表):
如果配置了停用词列表,那么常见的停用词(如“the”,“is”,“at”等)将从文本中移除。停用词通常在文本分析中被忽略,因为它们过于常见且不携带特定信息。——比如咱们前面用到的"stopwords": "english"。
继续举例子看一下:
POST my_index/_analyze
{
"text": [
"the the skiing center of the U.S.; If you're going to work hard, now is the time."
], "field": "name"
}执行结果如下:
{
"tokens": [
{
"token": "center going hard now skiing time u.s work you're", "start_offset": 0, "end_offset": 81, "type": "fingerprint", "position": 0
}
]
}
去掉了:“the”、“to”、“is”等停用词;
大写转成小写;
按照字母顺序排序。
4、fingerprint 那么多,如何选型?
一句话:
如果目的是改进搜索和索引,选择 Fingerprint 分词器,在创建索引的 settting 阶段指定。
如果是数据预处理和清洗,选择 Fingerprint Processor。在创建索引的 default_pipeline 指定为上策。
如果在 Logstash 管道中处理日志和事件数据,选择 Fingerprint Logstash 过滤处理器。
还有,如果涉及大文本去重、聚合相关操作,推荐将 fingerprint 用起来!
推荐阅读

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
原文地址:https://blog.csdn.net/laoyang360/article/details/135259692
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。