
Background
很早就开始做检索增强的大语言模型Agent了,通过外接知识库为LLM提供外部知识能增强它回答的准确性。这里我们使用ElasticSearch作为数据库存储相关知识,使用百度文心千帆的embedding API提供向量嵌入;借助langchain搭建LLM Agent.
需要安装的环境有:
Python,ElasticSearch,langchain,qianfan;后两个直接pip install langchain,pip install qianfan
检索原理
这里可以参考我之前的博客:document-question-answering-bot(文档问答机器人)-CSDN博客
使用里面提到的双塔模型原理完成检索功能。
如何检索?我们抛弃了ElasticSearch中古老的TF-IDF检索方式,也放弃了使用BERT进行文档嵌入;而是全面向大语言模型时代看齐,使用新的模型构建基于语义的搜索引擎。
文本嵌入
现有的很多开源项目使用OpenAI提供的embedding API进行,但是考虑到翻墙,我们放弃了这个做法;也有人使用Huggingface上的模型进行API嵌入,考虑到可能需要本地部署LLM的算力消耗,我们仍没有考虑;出于类似的原因,我们放弃了本地部署LLaMa,Baichuan2等LLM模型进行词嵌入。
本文最后使用百度文心千帆提供的Embedding-V1文本嵌入模型进行,步骤是:
- 使用该模型需要现在文心千帆控制台注册账户:百度智能云控制台 (baidu.com)
- 注册账户后,左侧千帆大模型平台-应用接入-创建应用;记住API-KEY和SECRET-KEY。
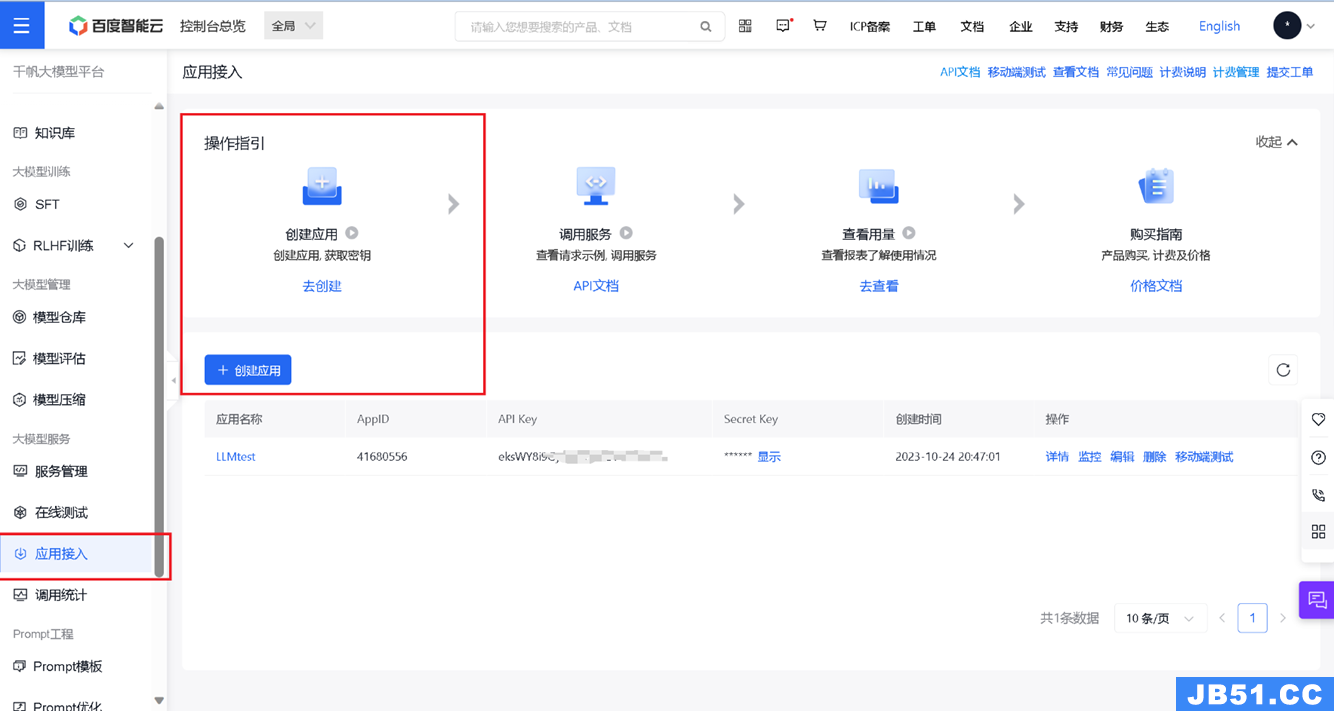
数据库
需要先安装并启动ElasticSearch数据库,具体教程略
LangChain搜索引擎
langchain是一个大语言模型Agent开发框架,我们在这里使用它读取数据内容并建立索引,完成对前述文本嵌入模型和数据库的调用,搜索引擎构建:
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import QianfanEmbeddingsEndpoint
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import ElasticVectorSearch
from langchain.chains import RetrievalQA
import os
os.environ['QIANFAN_AK'] = ""
os.environ['QIANFAN_SK'] = ""
loader = PyPDFLoader("2307.10569.pdf")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200,chunk_overlap=0)
documents = text_splitter.split_documents(data)
print(len(documents),documents[0])这里loader中是需要检索的外部知识库,我这里以一个PDF文档为例。如果嵌入的是HTML、TXT等其他类型,只需要调用langchain.documents_loaders里的其他读取方式即可。
使用RecursiveCharacterTextSplitter对文本进行分割;这里设置每200个词语截断成一段话,搜索引擎会为这每一段建立索引。像这里我们把PDF文件分成了98块,显示了第一块的内容,并为此建立了源。

下面这段代码定义了一个嵌入模型及数据库,这一段执行结束之后数据库中就已经存储了相关信息了;程序会输出下面的内容:
embeddings = QianfanEmbeddingsEndpoint()
db = ElasticVectorSearch.from_documents(
documents,embeddings,elasticsearch_url="http://localhost:9200",index_name="elastic-index",)
print(db.client.info())
接下来只需要查询:
db = ElasticVectorSearch(
elasticsearch_url="http://localhost:9200",embedding=embeddings,)
docs_and_scores = db.similarity_search_with_score("What it Aligning?",k=10)
print(docs_and_scores)"What is Aligning"是我们提出的问题,K=10是搜索引擎按照相似度返回的前10个文档:
可以看到文档内容,文档源等等。在此可以说我们的搜索引擎已经构建完成啦!
Langchain构建检索增强LLM Agent
如果你的目标只是构建一个搜索引擎,那这一部分可以跳过。
如果你是想让一个LLM的机器人能根据检索出的文档内容回答,只需要调用LLM机器人,并把之前返回的文档内容写入prompt中即可完成。这方面可以自己调用API完成,也可以继续使用Langchain框架完成。具体如何调用LLM就不详细介绍啦。
一些参考文档:
同济子豪兄-基于文心大模型的金融知识库问答AI实战 - 飞桨AI Studio星河社区 (baidu.com)
基于langchain+千帆sdk的一个基于文档的QA问答Demo - 百度智能云千帆社区 (baidu.com)
使用 Elasticsearch、OpenAI 和 LangChain 进行语义搜索_Elastic 中国社区官方博客的博客-CSDN博客
原文地址:https://blog.csdn.net/weixin_61255639/article/details/134219124
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。