
前言
Elasticsearch 是一种流行的开源搜索和分析引擎,它提供了强大的全文搜索和实时数据分析功能,被广泛应用于各种领域,包括大数据分析、日志处理、企业搜索等。在本篇博客中,我们将详细介绍在 Windows 环境下安装 Elasticsearch 的步骤和注意事项,以帮助您快速搭建 Elasticsearch 环境并开始使用其强大的功能。
接下来,我们将逐步指导您完成准备工作、下载安装包、安装 Elasticsearch,并验证其正常运行。我们还将提供一些常见问题和故障排除的解决方案,以帮助您克服可能遇到的挑战。
让我们一起开始吧,一步步探索在 Windows 下安装 Elasticsearch 的过程,为您的应用程序和数据分析带来更高效、可靠的搜索和分析能力。
Elasticsearch介绍
Elasticsearch 是一个开源的分布式搜索和分析引擎,构建在 Apache Lucene 基础之上。它提供了强大的全文搜索、实时数据分析和分布式性能的能力,成为当今最受欢迎的搜索引擎之一。Elasticsearch 的设计目标是简单、可扩展和高效的搜索和分析解决方案。
Elasticsearch 在许多应用场景中都能发挥重要作用,包括但不限于以下领域:
- 全文搜索:Elasticsearch 提供了高效而全面的全文搜索功能,可以快速索引和搜索大量文本数据。它支持各种查询类型、模糊搜索、过滤器、聚合等功能,能够满足复杂的搜索需求。
- 日志和事件分析:对于日志和事件数据的分析和监控,Elasticsearch 提供了实时的索引和分析能力。它可以处理大规模的日志数据流,帮助快速发现问题、进行故障排除和监控。
- 企业搜索:对于企业内部的搜索需求,如文档搜索、知识库搜索等,Elasticsearch 提供了快速、准确的搜索结果,并支持高级搜索和语义分析。
- 大数据分析:Elasticsearch 可以处理海量的结构化和非结构化数据,并提供丰富的聚合功能,用于数据挖掘、可视化和洞察力分析。
- 实时数据分析:Elasticsearch 提供了实时的数据索引和查询能力,适用于监控、实时指标分析和实时报表等场景。
准备工作
在安装 Elasticsearch 之前,需要进行一些准备工作,包括确定适用于 Windows 的 Elasticsearch 版本、确保系统满足 Elasticsearch 的要求,并安装和配置 Java Development Kit (JDK),其中最主要的就是JDK的安装与配置;
- JDK安装与配置
JDK环境安装配置可参看
https://blog.csdn.net/chen15369337607/article/details/125247930 - 系统要求
操作系统:Elasticsearch 支持多个操作系统,包括 Windows、Linux、Mac 等。确保您的系统是支持的操作系统版本。
内存要求:推荐系统具有至少 4GB 的可用内存。对于大型数据集和高并发访问,可能需要更多内存。
存储空间:Elasticsearch 需要一定的磁盘空间用于存储数据和索引。确保您的系统具有足够的可用存储空间。
下载Elasticsearch
前往 Elasticsearch 官方网站(https://www.elastic.co/downloads/elasticsearch)下载适用于 Windows 的 Elasticsearch 版本。确保选择与您的操作系统和需求相匹配的版本。
一般而言,您可以选择稳定版本(stable release)或预览版本(pre-release)中的一个。稳定版本是经过测试和验证的,适用于生产环境;而预览版本包含最新的功能和改进,但可能不够稳定。

在下载页面,可以看到选择操作系统,选择系统后点击下载。(我这里下载的Windows版本)
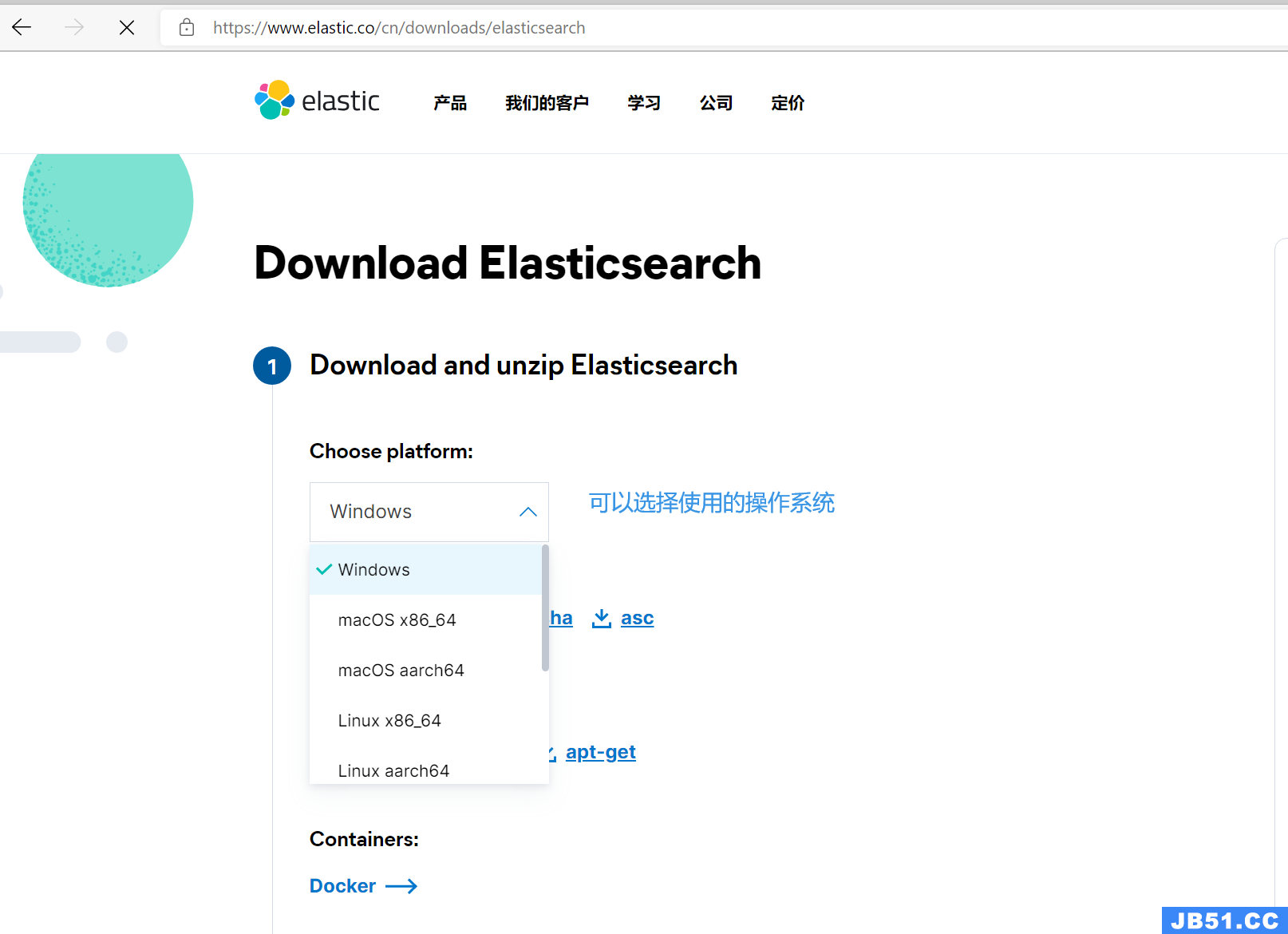
安装 Elasticsearch
在下载 Elasticsearch 安装包之后,我们可以进行安装过程。请按照以下步骤进行操作:
- 解压缩安装包
找到您下载的 Elasticsearch 安装包(通常是一个压缩文件),将其解压缩到您选择的目录中。您可以使用压缩工具(如7-Zip、WinRAR等)来执行此操作。
解压缩后,您将看到 Elasticsearch 的安装文件和目录结构。
- 配置 Elasticsearch 的相关设置
在安装 Elasticsearch 之前,您可以根据需要进行一些配置。以下是一些常见的配置项:
- 集群名称(Cluster Name):为 Elasticsearch 集群指定一个唯一的名称,用于在集群中标识节点。
- 节点名称(Node Name):为单个节点指定一个名称,以便在集群中标识该节点。
- 网络绑定地址(Network Bind Address):指定 Elasticsearch 监听的网络地址。默认情况下,它监听在本地地址(localhost),如果您想让 Elasticsearch 在其他 IP 地址上可访问,可以进行相应的配置。
- 配置文件路径(Configuration File Path):Elasticsearch 有一个默认的配置文件
elasticsearch.yml,您可以根据需要修改该文件中的配置项。
找到 Elasticsearch 安装目录中的 config 目录,并打开 elasticsearch.yml 文件(如果不存在,请复制一份 elasticsearch.yml.example 并将其命名为 elasticsearch.yml)。
使用文本编辑器打开 elasticsearch.yml 文件,并根据需要进行配置。您可以设置集群名称、节点名称、网络绑定地址等,保存并关闭文件。请注意,如果您不需要进行额外的配置,可以直接使用默认的配置项,无需修改 elasticsearch.yml 文件。一个自定义的示例elasticsearch.yml配置文件如下:
# 换个集群的名字,免得跟别人的集群混在一起
cluster.name: el-m
# 换个节点名字
node.name: el_node_m1
# 修改一下ES的监听地址,这样别的机器也可以访问
network.host: 0.0.0.0
#设置对外服务的http端口,默认为9200
http.port: 9200
#设置索引数据的存储路径
path.data: E:\elasticsearch-8.1.2\data #换成自己的路径
#设置日志文件的存储路径
path.logs: E:\elasticsearch-8.1.2\logs #换成自己的路径
# 关闭http访问限制
xpack.security.enabled: false
# 增加新的参数,head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
#----------------------- BEGIN SECURITY AUTO CONFIGURATION -----------------------
# Enable security features
#xpack.security.enabled: false
xpack.security.enrollment.enabled: true
# Enable encryption for HTTP API client connections,such as Kibana,Logstash,and Agents
xpack.security.http.ssl:
enabled: false
keystore.path: certs/http.p12
# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:
enabled: true
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
# Create a new cluster with the current node only
# Additional nodes can still join the cluster later
cluster.initial_master_nodes: ["el_node_m1"] #注意,这个要与node.name填写一致
#----------------------- END SECURITY AUTO CONFIGURATION -------------------------
- 配置环境变量
- 打开文件,选择此电脑,右键属性打开属性,选择高级系统设置打开,选择环境变量。
- 找到系统变量,选择新建,输入以下信息,单击确认。
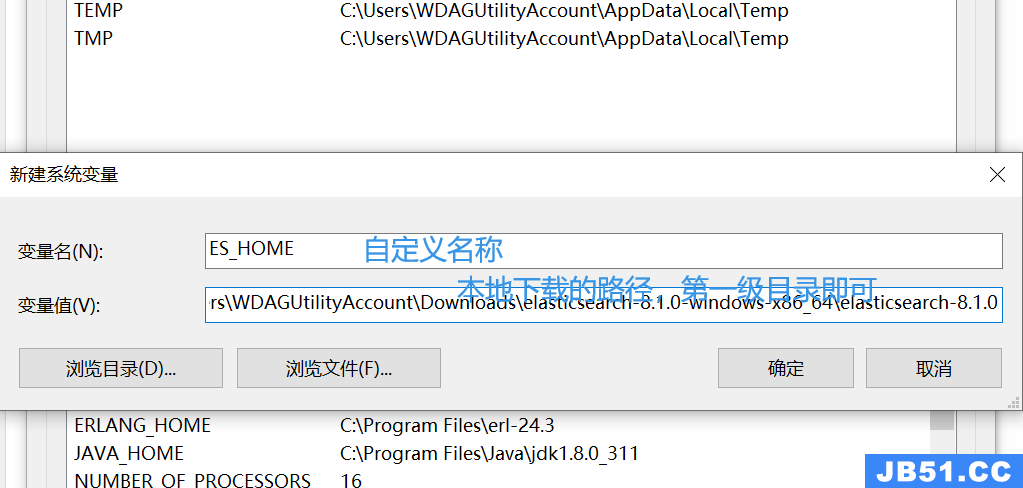
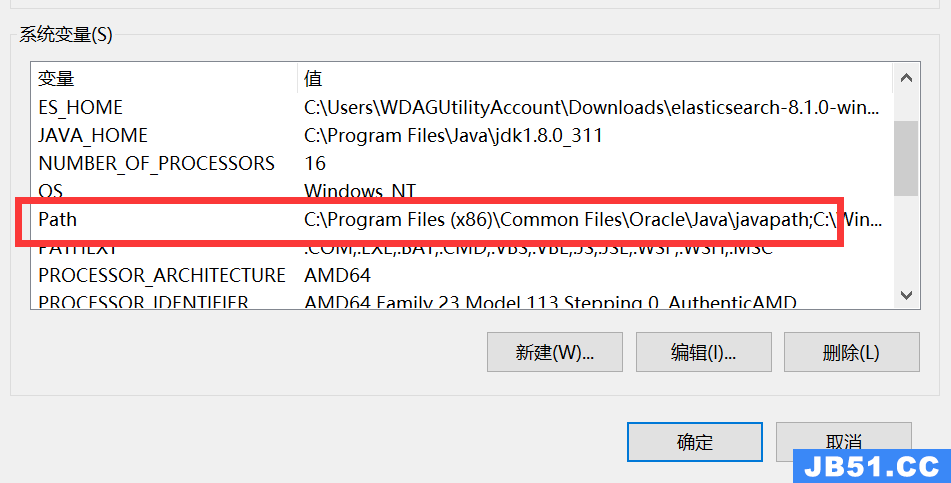
- 在系统变量里找到Path,将ES_HOME添加进去,然后选择确定。
运行验证 Elasticsearch
在安装和配置 Elasticsearch 后,我们可以启动 Elasticsearch 服务。操作步骤如下:
- 在命令行中启动 Elasticsearch 服务
在启动 Elasticsearch 之前,请确保已关闭任何已运行的 Elasticsearch 实例。
在 Windows 中,按下 Win + R 键打开运行对话框,输入 cmd 并按下回车键,以打开命令提示符窗口。
导航到您的 Elasticsearch 安装目录中的 bin 目录。例如:
cd C:\elasticsearch\bin
运行以下命令来启动 Elasticsearch 服务:
elasticsearch.bat
执行命令后,您将在命令行窗口中看到一系列的日志输出,表示 Elasticsearch 正在启动。
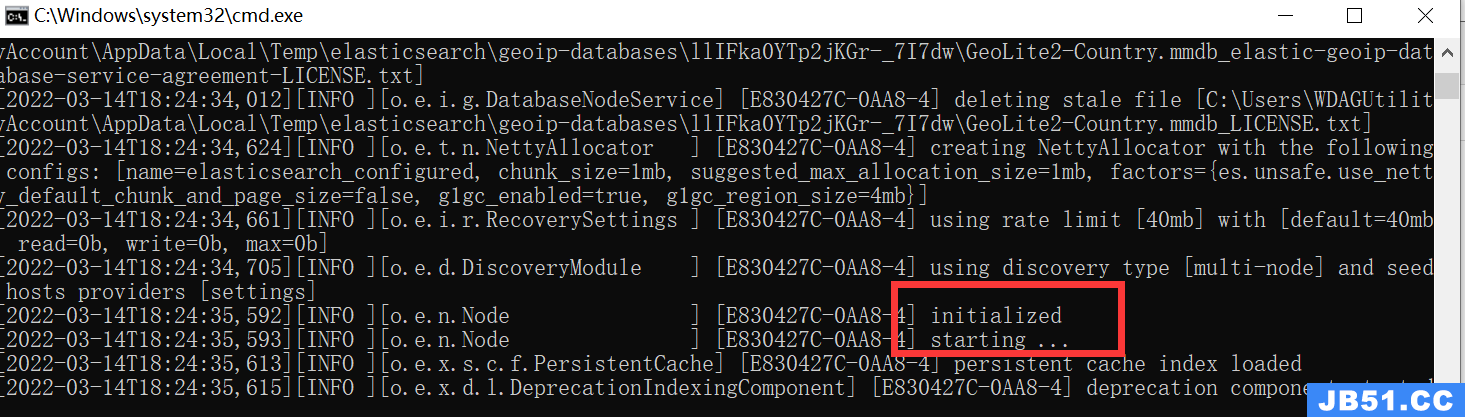
- 验证 Elasticsearch 是否成功启动
在 Elasticsearch 启动后,您可以进行以下验证步骤,以确保安装成功并正常运行:
-
打开您的浏览器,并访问
http://localhost:9200。 -
如果您看到类似以下的 JSON 响应,表示 Elasticsearch 已成功启动:
jsonCopy code { "name" : "your_node_name","cluster_name" : "your_cluster_name","cluster_uuid" : "your_cluster_uuid","version" : { "number" : "your_elasticsearch_version","build_flavor" : "your_build_flavor","build_type" : "your_build_type","build_hash" : "your_build_hash","build_date" : "your_build_date","build_snapshot" : "your_build_snapshot","lucene_version" : "your_lucene_version","minimum_wire_compatibility_version" : "your_minimum_wire_compatibility_version","minimum_index_compatibility_version" : "your_minimum_index_compatibility_version" },"tagline" : "your_elasticsearch_tagline" }这是 Elasticsearch 的基本信息和状态响应。您可以从中获取有关节点名称、集群名称、Elasticsearch 版本等的信息。

恭喜!您已经成功启动了 Elasticsearch。现在,您可以开始使用 Elasticsearch 的强大功能进行搜索、索引和分析操作。
请注意,在生产环境中,您可能需要进行更多的配置和安全设置,以满足您的需求和安全性要求。同时,还应将 Elasticsearch 设置为以服务形式在后台运行,以确保持久性和稳定性。
常见问题和故障排除
在安装和配置 Elasticsearch 的过程中,您可能会遇到一些常见的问题和错误。以下是一些常见的问题以及对应的解决方法和技巧:
- 端口冲突错误
问题:在启动 Elasticsearch 时,可能会遇到端口冲突错误,表示 9200 或 9300 端口已被占用。
解决方法:
- 检查是否有其他应用程序正在使用这些端口。您可以使用命令
netstat -ano来查看端口的占用情况,并找到对应的进程 ID。 - 如果发现有其他应用程序占用了这些端口,可以尝试停止或更改该应用程序的配置,以避免冲突。
- 在 Elasticsearch 的配置文件
elasticsearch.yml中,您可以修改http.port和transport.tcp.port选项,将它们设置为其他可用的端口。
- 内存不足错误
问题:在启动 Elasticsearch 时,可能会遇到内存不足的错误,表示系统的可用内存不足以支持 Elasticsearch 的运行。
解决方法:
- 检查系统的可用内存。确保系统有足够的可用内存来运行 Elasticsearch。推荐至少 4GB 的可用内存。
- 如果系统内存不足,您可以尝试增加系统的内存或关闭其他占用大量内存的应用程序。
- 日志文件错误
问题:在 Elasticsearch 的日志文件中,可能会出现错误或异常的记录。
解决方法:
- 查看日志文件中的错误信息,并尝试理解错误的原因。
- 可以使用搜索引擎或 Elasticsearch 官方文档来查找相关的错误信息,并找到相应的解决方案。
- 确保配置文件
elasticsearch.yml中的配置项正确设置,并与实际环境相匹配。
- 集群连接问题
问题:在建立 Elasticsearch 集群时,可能会遇到节点无法连接的问题,导致集群无法正常工作。
解决方法:
- 确保集群中的所有节点都处于运行状态,并且配置文件中的节点名称、网络地址等设置正确。
- 检查网络连接是否正常,并确保集群节点之间可以相互通信。
- 检查防火墙和网络安全组等设置,确保允许 Elasticsearch 节点之间的通信。
- 其他常见问题
问题:其他可能的问题包括版本不兼容、插件冲突、索引和数据损坏等。
解决方法:
- 确保您使用的 Elasticsearch 版本与其他组件和插件兼容。检查组件和插件的版本要求,并进行相应的升级或降级。
- 在 Elasticsearch 官方文档中查找有关插件安装、索引管理和数据恢复等方面的详细信息,并按照指南进行操作。
如果您遇到其他问题或错误,请参考 Elasticsearch 官方文档、社区论坛或搜索引擎上的相关资源,以获取更多的帮助和解决方案。记住,不断学习和探索是解决问题和提高技能的关键!
总结
在现代应用开发中,数据的搜索和分析变得越来越重要。Elasticsearch 作为一个开源、高性能的搜索和分析引擎,被广泛应用于各种应用场景。
它具有以下重要性:
- 强大的搜索功能:Elasticsearch 提供了全文搜索、模糊搜索、多字段搜索、排序、过滤器等功能,可以满足复杂的搜索需求。
- 实时性能:Elasticsearch 的分布式架构和基于倒排索引的搜索引擎设计,使得它具有快速的响应和高吞吐量的能力,能够在大规模数据集上实现实时的搜索和分析。
- 可扩展性:Elasticsearch 可以轻松地扩展到多个节点,形成一个分布式集群,以处理海量数据和高并发的请求。它提供了自动的数据分片和负载均衡机制,确保系统的可靠性和性能。
- 生态系统支持:Elasticsearch 拥有丰富的生态系统,包括插件、集成工具和第三方库,可以与其他流行的技术(如Logstash、Kibana、Beats等)集成,构建完整的日志管理和数据分析平台。
总而言之,Elasticsearch 在现代应用开发中的重要性越来越突出。它为开发人员提供了快速、准确的搜索和实时数据分析能力,帮助构建高性能、可扩展的应用程序和数据平台。
如果您对 Elasticsearch 感兴趣并希望进一步学习和研究,以下是一些学习资源和指引,供您参考:
- Elasticsearch 官方文档:Elasticsearch 提供了详细的官方文档,其中包含了广泛的主题,从基础知识到高级用法都有涉及。您可以访问 Elasticsearch 官方网站并查阅文档(https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)。
- Elasticsearch 学习路径:Elasticsearch 官方网站提供了学习路径,从入门到进阶,逐步引导您掌握 Elasticsearch 的核心概念和技术。您可以按照这个学习路径来学习和实践(https://www.elastic.co/training/learning-path-elastic-stack)。
- 社区论坛和问答网站:Elasticsearch 社区非常活跃,有许多用户在社区论坛和问答网站上分享和讨论 Elasticsearch 相关的问题和经验。您可以加入 Elasticsearch 的社区,提问、回答问题,并与其他用户交流(如 Elastic Discuss: https://discuss.elastic.co/)。
- 博客和教程:许多技术博客和在线教程提供了关于 Elasticsearch 的教程和指南,包括搜索、索引、聚合等方面的深入讲解。您可以搜索相关的博客和教程,根据自己的需求和兴趣进行阅读和学习。
- 实践项目:通过实际的项目和练习,您可以更深入地了解 Elasticsearch 的应用和实际场景。尝试在自己的项目中使用 Elasticsearch,探索其强大的搜索和分析功能,并不断实践和改进。
通过不断学习和实践,您将逐渐掌握 Elasticsearch 的技术和应用,为您的搜索和分析需求提供高效、可扩展的解决方案。祝您在使用 Elasticsearch 的过程中取得成功!如有任何问题或需要进一步的帮助,请随时提问。
声明
内容引用 https://blog.csdn.net/zm_960911
本文首发于香菜喵,打开微信随时随地读,获取更多资源文章下方 ↓ ↓ ↓
原文地址:https://blog.csdn.net/chen15369337607/article/details/131783783
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。