
因为自己对决策树的机制非常的好奇,所以就研究了一下决策树的ID3算法,在这也做一篇笔记记录一下过程。
一、什么是决策树?
这个问题是我从一开始就有的疑问,什么是决策树?在看了一些资料之后,因为没有看到书上给出具体定义,所以按照我自己的理解决策树就是通过一个个“决策”而构建的一种树状结构,而且决策树的整个处理机制非常类似于我们人类在面临决策问题时的处理机制,这也可能就是其名字的由来。
决策树的概念相对简单,即使没有接触过决策树也可以从下面的图中来了解其工作的原理:
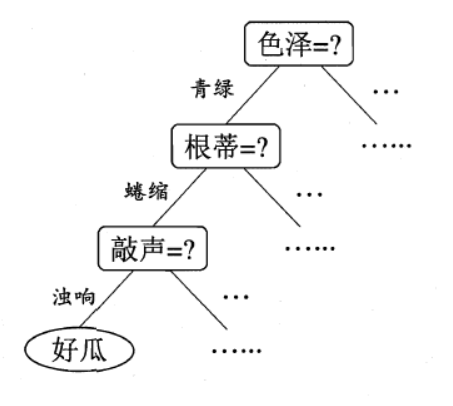
这是西瓜书中的一个简单的决策树流程图,我们人类从色泽、根蒂、敲声这三个方面可以得出结论:这是一个好瓜,那么决策树就可以模仿我们人类做出“决策”的流程从而得出与我们相同的结论:这是一个好瓜。而计算机在构建决策树的过程,其实也就是我们经常说的计算机在学习的过程(机器学习),在这里也就是决策树学习。那么我就产生疑问了,学习的目的是什么呢?类比一下我们人类,其实很容易就可以知道决策树学习的目的是为了产生一棵泛化能力强,即处理未见实例能力强的决策树,也就是我们希望机器可以自己去判断所有西瓜的好坏。
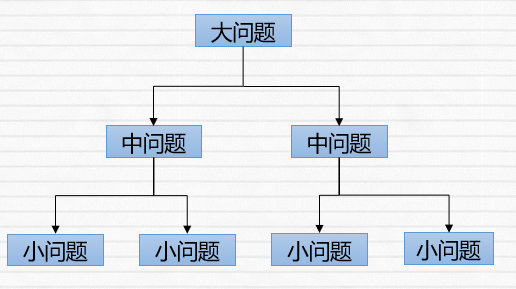
总的来说,决策树的本质就是一个分类器,我们可以使用它来将一些事物进行分类处理。而它的处理策略遵循着简单而且直观的“分而治之”的策略,即将大问题分解成若干个中问题,再将中问题分解成若干个小问题,这也是我们人类每次遇到棘手的问题时都会采用的策略*~*。
二、信息增益
2.1信息熵
紧接着上面的内容,既然我们已经知道了决策树的工作机制,那么我们直接开始构建决策树不就得了,但是当我们真正要开始构建决策树的时候,我们遇到的第一个问题出现了:“决策”从哪里来。
总的来说有两个来源:经验或是数据,我们人类的经验本身就是经过无数次验证之后的宝贵财富,所以说它是很适合作为“决策”的。但是经验的致命伤就在于我们人类的主观性,也就是我们整天口头上所说的“感觉”两个字,就像上文提到的决策树流程图一样,我们可能感觉先划分谁都无所谓啊(色泽、根蒂、敲声)反正最后肯定会生成一棵决策树的。而这就会导致我们构建出来的决策树不够“优良”,可能会导致决策树在对事物进行分类之后的结果精度欠佳或是分类效率过慢等问题。所以决策树中的“决策”不能仅仅只依靠经验,还要来自于数据之中,这样我们才可能得到较为“优良”的决策树。那么我们的第二个问题也就紧跟着来了:怎样利用数据来选择最优的划分属性呢?,就像上文提到的决策树流程图一样,我们是先从色泽开始划分,还是先从根蒂、敲声开始划分,那么这就需要信息熵这种指标的帮忙了。
2.1.1定义
信息熵是用来描述信源的不确定度。(来源于百度)
2.1.2演变
那么面对一个陌生的概念,我的第一个想法就是这东西是有什么用呢?要想知道他有什么用处,那么我们可以看一看他是怎么演变而来的。
1865年,热力学奠基人之一、德国物理学家和数学家鲁道夫 • 克劳修斯第一次使用了“熵(entropy) ” 作为热力学的专用名词,并赋予其数学形式。
1866年,24岁的玻尔兹曼在他关于气体动力学的奠基性论文中,给出了熵的另一形式,其“把熵看成是无序分子运动紊乱程度的一种度量”。
1948年,克劳德 • 香农,信息论之父,他将“熵”的概念引入信息领域并创造了举足轻重的的“信息熵”这一概念:香农在数学上量化了通讯过程中“信息漏失”的统计本质,具有划时代的意义。其中香农认为熵是指“当一件事情有多种可能情况时,这件事情发生某种情况的不确定性”;信息是指能够消除人们对这件事情不确定性的事物。
那么在了解信息熵之前,我对香农在数学上量化“信息”仍然不甚理解,因为信息要怎样量化呢?而“熵”又是怎样被用到信息上的呢?我从书上找到了其对信息的定义:如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为:
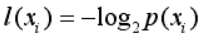
怎样去理解这个公式呢?知乎上有一个视频举的例子非常好:我们生活中遇到的物理量都有单位,如米、千克、斤等等,那么我们是怎么来使用这些单位的呢?我们经常说自己130斤、120斤是怎么计算得出的呢?那是我们将自己的重量与1斤重的东西相比较而得出的,类似于曹冲称象这样的原理,说白了就是要有一个参照物,这样才能使得某项事物进行量化。那么信息的参照物是什么呢?答案是“抛硬币”(这当然是开玩笑,但是很形象),通常我们抛一次硬币可能会有两种不确定情况发生:正面或反面(不确定度),那么我们抛两次就可能有四种不确定情况(正反,正正,反正,反反),以此类推抛三次就是八种不确定情况…,那么就可以将抛硬币这个事件作为衡量信息的参照物,这就很好的解释了公式中的log_2是怎么来的。
让我们举一个例子来更好的理解什么是信息:1、假设我们去考数学考试,碰到了一个完全不会的选择题,这个选择题有4个选项,那么此时这道选择题中的每个选项给我们提供的信息量是多少呢?因为每个选项被选中概率都是1/4,如果我们换一种思路将C选项的概率看做成是从4种不确定情况中选出一种情况,那么ABCD选项各自的信息量是log_2 4=2(也就是-log_2 1/4),也就是相当于抛硬币这一事件发生两次。但是我们总不能每次都这样描述信息吧,总要有个单位啊,香农就很巧妙的借鉴了计算机中的bit(0和1)这一概念,所以结果就可以写成2bits。(概率均匀分布)
2、还是上面那个例子,但是此时突然旁边有人告诉你这道题选C选项的概率是1/2,那么自然而然的其他选项的概率就变为了1/6,那么就很容易得出C选项的信息为log_2 2=1bits,同理ABD选项则为log_2 6=2.58bits。(一般概率分布)
到这里我们已经了解了信息是怎样量化的,但是上面那个例子存在着一个问题,那就是我们并不能使用这道题的总信息量(指简单的将ABCD选项的信息量相加)来衡量这道题的不确定性啊,就好像你不能使用一个班级里的总分来衡量一个班级的成绩好坏一样,毕竟你还不知道这个班级的人数是多少啊。那么我们通常用什么来衡量一个班级的成绩呢?平均分啊*~*,也就是成绩的期望。那么信息的期望值是什么呢?就是信息熵。
但是我们也不能像计算平均分那样直接除以人数就行了,因此也就有了下面的这个信息熵的公式:
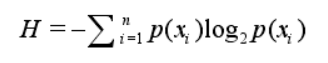
此时我们再来计算上述的两个例子:他们的信息熵分别是2bits和1.79bits,感觉自己类比平均分这个例子有些不恰当但是一时之间又想不到其他的例子。主要是信息熵它与平均分并无很大的相似之处,这是因为信息熵本身是指发生某种情况的不确定性,另一方面反过来想就是指我们要解决这个问题至少所需要的信息量,是一种最坏情况的估计值。
2.2信息增益
之所以花了很大的篇幅去说一下信息熵,是因为它是ID3算法的核心,我们是无法绕开它而直接谈信息增益的。在了解一些信息熵的概念之后,我再来看信息增益的公式就要轻松很多了。
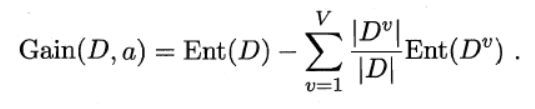
其中:Ent指的是集合的信息熵,D是样本集合,a是指某个属性集合{a1,a2,…,av},Dv是指样本D中所有在属性a上取值为av的样本,|D|,|Dv|是样本数量。
为了方便理解,我们可以再举一个例子,怎样才能成为一个篮球运动员(数据纯属编造*~*):
| 编号 | 身高(是否>=190cm) | 体重(是否>=95kg) | 弹跳(是否>=90cm) | 技巧 | 是否为篮球运动员 |
|---|---|---|---|---|---|
| 1 | 180(否) | 88(否) | 88(否) | 优 | 否 |
| 2 | 190(是) | 95(是) | 85(否) | 良 | 是 |
| 3 | 200(是) | 110(是) | 80(否) | 良 | 否 |
| 4 | 203(是) | 120(是) | 82(否) | 差 | 是 |
| 5 | 206(是) | 100(是) | 90 (是) | 良 | 否 |
| 6 | 193(是) | 98(是) | 100(是) | 优 | 是 |
| 7 | 170(否) | 88(否) | 88(否) | 优 | 否 |
| 8 | 175(否) | 85(否) | 90(是) | 优 | 否 |
如上面这个表格所示,此时样本集合D正例(是篮球运动员)是3/8,反例为5/8,所以集合D的信息熵为:Ent(D)=-(3/8 × log_2 (3/8) +5/8 ×log_2 (5/8))=0.9544。
因为决策树对于属性划分使用的是贪心策略,所以我们只能一个一个的去算出样本集合D与属性a={身高,体重,弹跳,技巧}之间的信息增益值:
身高:在D1(>=190cm)中的正例为3,反例为2;在D2(<190cm)中的正例为0,反例为3。因此公式的后半部分为(因为我实在有点受不了在markdown中编辑算式*~*,所以就用图片代替一下):
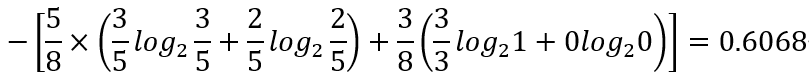
则样本集合D与身高的信息增益为Gain(D,身高)=0.9544-0.6068=0.3476bits(约等于)。
同理可以求出Gain(D,体重)=0.9544-0.6068=0.3476bits,Gain(D,弹跳)=0.9544-0.9512=0.0032,Gain(D,技巧)=0.9544-0.75=0.2044。
因为Gain(D,身高)和Gain(D,体重)的增益值最高,所以身高或是体重即是本次划分的最优属性选择。以此类推一直按照这种规则来进行划分,直到所有的分类集合的信息熵为0则停止划分。
经过这个例子之后,现在再来理解信息增益可能会更清楚一点,信息增益其实就是在指按照某种属性划分前后样本集合D的信息熵之差,其单位为信息的单位bits。因为在香农的理论里“熵是指某件事情的不确定性,而能消除这些不确定性的事物恰恰就是信息”,所以按照我自己的理解,信息增益所计算出的结果应该是指样本集合不确定性的减少量,也就是指样本集合的不确定性下降了多少。
最后小结一下,按照信息增益来划分属性,其实质就是要找到一条最快使样本集合的信息熵降为0的方法,也就是以最快的方式将样本集合从无序变为有序,以此来创建最优决策树。
三、ID3算法实现
算法步骤:

训练数据集为:

代码如下:
#include<vector>
#include<string>
#include<iostream>
#include<map>
#include<set>
#include<cmath>
#include<queue>
using namespace std;
class Node
{
public:
int attrIndex; //属性索引方便后续的查询
string attributeValue; //属性值
string label; //该节点的标签
bool isLeaf; //是否为叶结点
vector<Node*> children; //子女节点
//map<string,vector<string>> dataset; //记录数据集
Node() { isLeaf = false; }
};
//数据表
class DataSet
{
public:
vector<string> attribute; //属性集合
vector<vector<string>> data; //数据集合
map< string, vector<string>> table; //属性+数据集合
void ConnectAttributeValue() { //将属性与数据列进行关联
vector< vector<string>> attributeValueList; //属性值列表
vector<string> tempAttr = attribute;
tempAttr.push_back("classList"); //添加一个类别列属性
attributeValueList.resize(tempAttr.size());
for (size_t i = 0; i < tempAttr.size(); i++)
{
for (size_t j = 0; j < data.size(); j++)
{
attributeValueList[i].push_back(data[j][i]); //类似于将data进行转置
}
table.emplace(tempAttr[i], attributeValueList[i]); //将转置过的一行数据值与相应属性像连接
}
}
DataSet(const vector<vector<string>>& data, const vector<string>& attribute)
:data(data), attribute(attribute){
ConnectAttributeValue();
}
};
//决策树
class DecisionTree
{
public:
DecisionTree(const DataSet& dataSet)
:dataSet(dataSet){
for (size_t i = 0; i < dataSet.attribute.size(); i++)
{
attrIndex.insert({ dataSet.attribute[i],i });
}
CreateTree(this->dataSet, &root);
}
void print() {
levelPrint(root);
}
string Classify(const vector<string>& testVec) {
return RecursionQuery(root, testVec);
}
~DecisionTree()
{
DestoryDecisionTree(root);
}
private:
DataSet dataSet; //数据集
Node* root = nullptr; //创建根节点
map<string, int> attrIndex; //记录属性的索引
void CreateTree(DataSet& dataSet, Node** treeNode) { //传递指针的地址**
vector<string> classList = dataSet.table["classList"]; //类别列表
set<string> classCount;
for (size_t i = 0; i < classList.size(); i++)
{
classCount.insert(classList[i]);
}
if (classCount.size() == 1) //判断是否所有成员都属同一类
{
(*treeNode) = new Node(); //实例化指针
(*treeNode)->isLeaf = true;
//node.attributeValue =;
(*treeNode)->label = classList[0];
return;
}
if (dataSet.attribute.empty() || dataSet.table.size() == 1) //也就是集合内只有一列元素或者是属性集合为空
{
(*treeNode) = new Node();
(*treeNode)->isLeaf = true;
(*treeNode)->label = majorityCnt(classList); //返回类型出现最多的类别标签
return;
}
int bestFeat = chooseBestFeatureToSplit(dataSet);
string bestFeatLabel = dataSet.attribute[bestFeat];
(*treeNode) = new Node();
(*treeNode)->label = bestFeatLabel;
(*treeNode)->attrIndex = attrIndex[bestFeatLabel];
vector<string> featValue = dataSet.table[bestFeatLabel]; //获取所有最优属性的属性值
set<string> uniqueVal;
for (size_t i = 0; i < featValue.size(); i++)
{
uniqueVal.insert(featValue[i]);
}
for (auto item : uniqueVal)
{
Node* node = nullptr; //创建一个节点
CreateTree(splitDataSet(dataSet, bestFeat, item), &node);
node->attributeValue = item; //赋给其属性值
(*treeNode)->children.push_back(node); //将创建好的节点与父节点相连接
}
}
//为了筛选出出现次数最多的类别(yes or no)
string majorityCnt(const vector<string>& classList) {
string majorLabel = "";
map<string, int> value;
for (size_t i = 0; i < classList.size(); i++)
{
if (!value.count(classList[i]))
{
value.insert({ classList[i],0 });
}
value[classList[i]]++;
}
int tempCount = 0;
for (auto item = value.begin(); item != value.end(); item++)
{
if (item->second>tempCount)
{
tempCount = item->second;
majorLabel = item->first;
}
}
return majorLabel;
}
//挑选出数据表中最优的属性
int chooseBestFeatureToSplit(DataSet& dataSet) {
int numFeat = dataSet.table.size() - 1; //属性的数量
double baseEntropy = calcShannonEnt(dataSet);
double bestGain = 0.0; //记录信息增益
int bestFeature = -1; //记录最优属性的索引值
for (size_t i = 0; i < numFeat; i++)
{
//获取dataSet中的第i列所有属性值
string feat = dataSet.attribute[i];
vector<string> featList = dataSet.table[feat]; //获取相应属性的数据集
set<string> uniqueVal;
for (size_t i = 0; i < featList.size(); i++)
{
uniqueVal.insert(featList[i]);
}
double newEntropy = 0.0;
for (auto item = uniqueVal.begin(); item != uniqueVal.end(); item++)
{
DataSet subDataSet = splitDataSet(dataSet, i, *item); //按照属性值(0 or 1)来划分属性
double prob = subDataSet.data.size() / (double)dataSet.data.size();
newEntropy += prob*calcShannonEnt(subDataSet);
}
double infoGain = baseEntropy - newEntropy;
//cout << "信息增益:" << infoGain<<endl;
if (infoGain>bestGain)
{
bestGain = infoGain;
bestFeature = i;
}
}
return bestFeature;
}
//计算香农熵
double calcShannonEnt(DataSet& dataSet) {
int numEntries = dataSet.data.size(); //获取数据集的行数
map<string, int> labelCount; //记录每个标签出现的次数
vector<string> classList = dataSet.table["classList"];
for (size_t i = 0; i < classList.size(); i++)
{
if (!labelCount.count(classList[i]))
{
labelCount.insert({ classList[i],0 });
}
labelCount[classList[i]]++;
}
double shannonEnt = 0.0; //记录香农熵
for (auto item = labelCount.begin(); item != labelCount.end(); item++)
{
double prob = (double)item->second / numEntries; //计算该标签的概率
shannonEnt -= prob*log(prob) / log(2);
}
return shannonEnt;
}
//划分数据集
DataSet splitDataSet(const DataSet& dataSet, int index, string value) {
vector<string> attr;
for (size_t i = 0; i < dataSet.attribute.size(); i++)
{
if (index == i)
continue;
attr.push_back(dataSet.attribute[i]); //记录属性信息
}
vector <vector<string>> data, oldData = dataSet.data;
for (size_t i = 0; i < oldData.size(); i++)
{
if (oldData[i][index] != value)
continue;
vector<string> accessAttrVec;
for (size_t j = 0; j < oldData[i].size(); j++)
{
if (index == j)
continue;
accessAttrVec.push_back(oldData[i][j]); //记录要提取的数据信息
}
data.push_back(accessAttrVec);
}
return DataSet(data, attr);
}
//递归遍历
void print(const Node* node) {
if (!node->isLeaf)
{
for (size_t i = 0; i < node->children.size(); i++)
{
print(node->children[i]);
}
}
cout << node->label << " " << node->attributeValue << endl;
}
//层次遍历
void levelPrint(Node * node) {
queue<Node*> queue;
queue.push(node);
while (!queue.empty())
{
Node* currentNode = queue.front();
queue.pop();
cout << currentNode->label << " " << currentNode->attributeValue << endl;
if (!currentNode->isLeaf)
{
for (size_t i = 0; i < currentNode->children.size(); i++)
{
queue.push(currentNode->children[i]);
}
}
}
}
//递归查询
string RecursionQuery(const Node* node, const vector<string>& testVec) {
if (node->isLeaf)
{
return node->label;
}
else
{
for (size_t i = 0; i < node->children.size(); i++)
{
Node* currentNode = node->children[i];
if (currentNode->attributeValue == testVec[node->attrIndex])
{
return RecursionQuery(node->children[i], testVec);
}
}
}
}
//释放内存
void DestoryDecisionTree(Node* node) {
if (!node->isLeaf)
{
for (size_t i = 0; i < node->children.size(); i++)
{
DestoryDecisionTree(node->children[i]);
}
}
delete node; //释放节点
node = nullptr;
}
};
int main() {
vector<vector<string>> data = { {"1","1","yes" },
{ "1","0","no" },
{"0",
{ "0","no" } };
vector< string> labels = { "no surfacing","flippers"};
/*for (size_t i = 0; i < dataSet.size(); i++)
{
for (size_t j = 0; j < dataSet[i].size(); j++)
{
cout << dataSet[i][j] << " ";
}
cout << endl;
}
for (auto item :labels )
{
cout << item << " ";
}*/
DataSet dataSet(data, labels);
/*vector<string> value = table.table["no surfacing"];
for (auto item : value)
{
cout << item << " ";
}*/
DecisionTree decisionTree(dataSet);
cout << "决策树层次遍历:" << endl;
decisionTree.print();
cout << "-------------------------" << endl;
vector<string> test1 = { "0","1"};
string result= decisionTree.Classify(test1);
cout << "测试结果(0,1):"<<result << endl;
cout << "-------------------------" << endl;
vector<string> test2 = { "1","1" };
result = decisionTree.Classify(test2);
cout << "测试结果(1,1):"<<result << endl;
system("pause");
return 0;
}
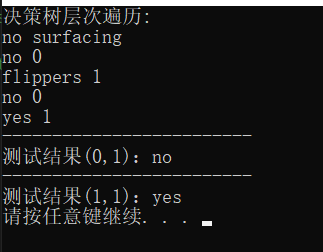
实现效果:
四、小结
总结一下整个实现ID3算法的过程,有以下几点:
1、ID3的核心是信息增益,而信息增益的核心是信息熵(在这里不得不钦佩天才数学家香农,真的奇思妙想)。
2、信息增益准则对可取值数目较多的属性有所偏好,按我的理解是对可取值数目较多的属性进行集合划分会使熵值更快的降下来,这样能更快使得数据从无序变的有序。(因此也就出现了后来的C4.5算法)。
最后要说的是博客关于决策树算法的一些看法,纯属自己的个人理解,尤其是关于数学家香农提出的信息熵概念,感觉到现在也不怎么理解,所以如果上述过程中存在错误,希望大家能及时的批评指正。
参考资料:
[1]《机器学习》
[2]《机器学习实战》
[3]《数学之美》
[4]https://www.zhihu.com/question/22178202/answer/577936758
原文地址:https://blog.csdn.net/dayuhaitang1/article/details/106067845
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。