
又看了一遍操作符的东西,感觉之前对操作符的理解还停留在很浅的认知上(仅仅会用哈哈),所以做一下笔记来加深一下印象。
一、为什么会有操作符重载?
如果要回答这个问题,我们其实应该仔细想一下如果没有操作符重载会怎样呢?这其实很容易就联想到了C语言,因为他就没有操作符重载这一说。虽然C语言中没有类class这一概念,但是他有着和类及其相似的结构体struct,那么如果我们构建两个结构体进行相加的话,我们会怎么做呢?我们会创建类似于下面的函数:
#include<stdio.h>
struct vector
{
//vector的构造函数
vector():x(0),y(0){}
vector(double a,double b):x(a),y(b){}
double x,y;
};
vector add(const vector& a,const vector& b);
int main()
{
vector a,b(2,3),c;
a.x=1;
a.y=2;
c=add(a,b);
printf("c为:%f %f\n",c.x,c.y);
return 0;
}
vector add(const vector& a,const vector& b)
{
return vector(a.x+b.x,a.y+b.y); //利用构造函数构造一个临时的vector对象
}
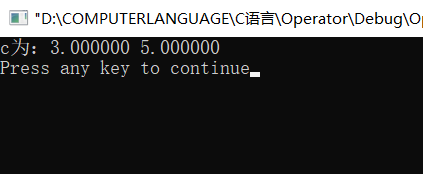
在C语言中我们会通过构建add这个函数来实现了两个结构体的相加操作,但是这种方式不仅代码不够简洁精炼,而且也会给我们增加阅读的难度,因为这不符合我们生活中"+"的用法。所以才有了后面C++的操作符重载。
二、操作符重载作用的对象
在任何语言中操作符所作用的对象都是某种数据结构,就好像C++中的int、double等等,这些数据结构从C++语言诞生起就遵循着某种运算法则,就如我们常用到的int+int=int,int+double=double等。而这些C++内置的运算法则是不允许我们去更改的,这就好像你要把1+1=2修改成1+1=3,不是不能改,而是改了之后这会打破大家共有的认知。就好像数学上总是有公理和定理之分,没人能解释的了公理是怎么回事,但是定理却总是能用公理来进行解释。而C++中的这些内置的运算法则就像高悬在C++世界的天道法则一样,生活在C++世界中的诸多的变量和对象都按这这法则工作着,所以C++的创造者们为了避免打破这法则而带来的麻烦,那么诸如像下面的这种行为都是不允许的。
double operator +(int a, int b)
{
}
既然动不了“天道法则”,那总要让我们自己修仙创建自己的规则吧,在这一点上C++还是很通情理的。使用操作符重载就可以实现我们自定义类型的加减乘除等等运算,所以也就是说操作符重载只能作用于我们自定义的数据类型,如下所示:
#include<iostream>
#include<vector>
using namespace std;
vector<int> operator + (const vector<int> a, const vector<int> b) //非成员函数
{
return vector<int>{a[0] + b[0], a[1] + b[1]};
}
int main()
{
vector<int> a(2, 1), b(2, 2),c;
//cout << a[0]<<" "<<a[1]<<endl;
c = a + b;
cout << c[0] << " " << c[1] << endl;
system("pause");
return 0;
}
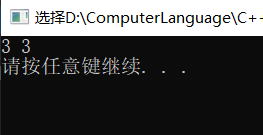
其实我刚开始学的时候还有点迷惑,vector也是C++内置的数据类型啊,为啥他不会被禁止呢?所以我又到书上找了找vector的定义,找到了这一句话。

也就是说C++只有vector的类型模板而并没有vector《double》这个数据类型,因此C++就将它认定为我们自定义的数据类型。
除了上述的将操作符重载为非成员函数之外,我们还经常将它作为成员函数,如下所示:
#include<iostream>
#include<vector>
using namespace std;
class point
{
public:
double x, y;
point(double,double);
point& operator +(const point& other); //成员函数
~point();
private:
};
point::point(double a=0, double b=0)
:x(a),y(b)
{
}
point & point::operator+(const point& other)
{
return point(x + other.x, y + other.y);
}
point::~point()
{
}
int main()
{
point a(1, 3), c;
c = a + b;
cout << c.x << " " << c.y<< endl;
system("pause");
return 0;
}
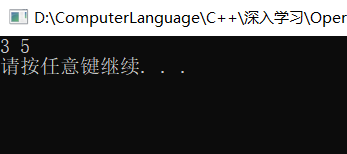
在这个函数中值得人注意的就是重载操作符“+”的时候,参数列表中只能有一个参数,因为在类中其拥有默认隐式的一个参数:this指针,这样它就拥有了两个参数。因此这也就导致了该重载函数不允许再添加参数,否则会报错“参数太多”。
无论是作为成员函数还是非成员函数,操作符重载其本质上和C语言中的“add”函数是一样的,也是一个函数,只不过是用“+”代替了“add”函数而已,并且其作用的对象只能是我们自定义的数据类型(class或struct等)。
参考书籍:《C++ primer》
原文地址:https://blog.csdn.net/dayuhaitang1/article/details/104587425
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。