

12月20日-21日,由中国信通院、中国通信标准化协会主办,中国通信标准化协会大数据技术标准推进委员会承办的“2023数据资产管理大会”在京召开。
在会上,第七届大数据“星河(Galaxy)”案例评选结果正式公布。中移在线服务有限公司(中移在线)与酷克数据联合申报的《基于云原生化的数据仓库平台,实现数据算力交付效率全面提升》项目,凭借全栈自主可控、敏捷高效、安全稳定的先进特性,成为业内首个容器化部署的大规模云原生数据仓库,荣膺2023大数据“星河”数据库优秀案例奖。
大数据“星河(Galaxy)”案例征集活动主要面向甲方落地单位,旨在通过实地生产案例与场景,总结和推广真实可用的大数据实践与经验,在国内大数据产业具有公认的行业标杆性和极高的认可度。
第七届大数据“星河(Galaxy)”案例征集包括数据库与其他五项大数据应用方向,覆盖电信、金融、政务、能源、制造等行业。案例征集自9月启动以来,受到了业界领先甲方单位与厂商的广泛关注。经过形式审查和专家评审,共评选出数据库优秀案例26个。

项目背景
中移在线营服数据处理平台建设初期采用了当时业界广泛运用的“Hadoop+MPP数据库”混搭架构作为数据仓库。随着数据量的不断增长,平台扩容和运维漫长繁琐,无法满足高时效性、高重要性应用的发展需求。
围绕集团公司赋予的“全网集中服务的提供者、渠道运营的集中支撑者、业务的后台集中处理者”的定位,中移在线向云原生技术积极布局。经过广泛的市场调研和产品比较,最终以酷克数据的存算分离、弹性并行处理(EPP)数据库产品——HashData云数仓为核心,实施Vertica全面替换,构建统一高效、敏捷智能、湖仓一体的数据体系,提供统一、多样化、面向应用、面向主题的数据服务能力,为中移在线数字化转型提供强大的数据能力底座。
首先,在本项目中,中移在线采用HashData EPP数据仓库,与原有基础云平台、对象存储集成,采用容器化部署方式建立起云原生数据仓库。
传统MPP架构的数据仓库,由于数据量大,网络、IO吞吐量高,无法采用容器化部署,难以实现资源利用的效率最大化。中移在线和酷克数据的技术团队克服了网络、存储、调度、管理等方面遇到的诸多技术挑战,突破过往容器化仅用于无状态应用场景或开发测试环境的限制,采用K8S+HashData 的技术路线,在国内率先建成实际生产环境下的容器化部署大规模云原生数据仓库。
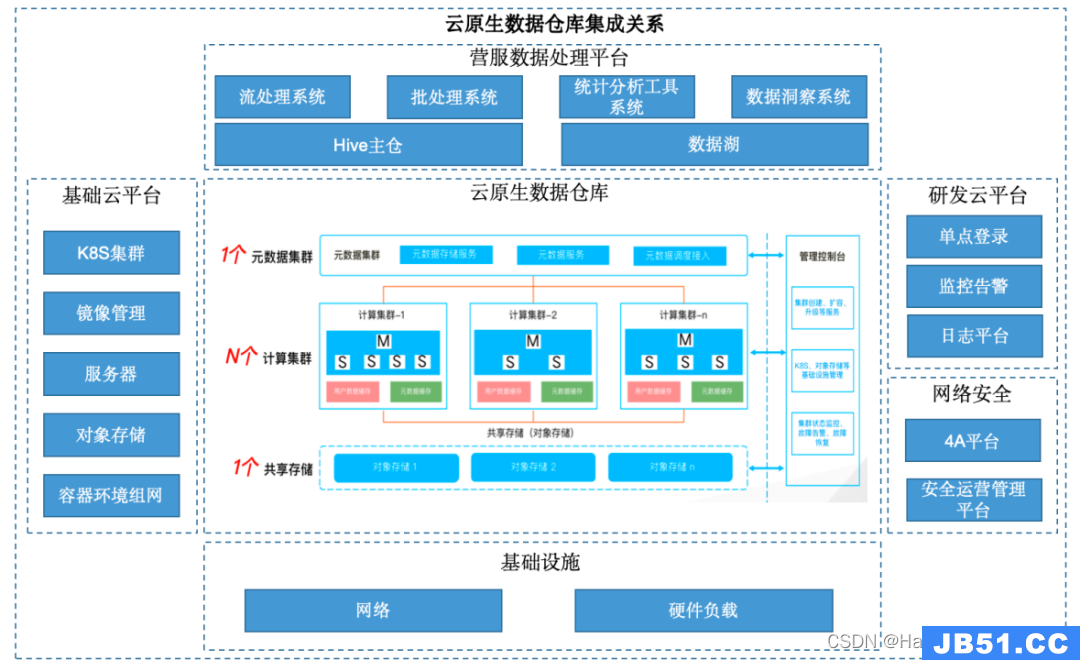
图1:基于容器化部署的云原生数据仓库解决方案
基于HashData存储、计算、元数据三者分离的架构,借助更轻量级的容器虚拟化技术,进一步扩展了云原生数据仓库平台的弹性伸缩优势,以及高可用能力、自动化运维能力和资源敏捷交付能力,大幅提升了项目交付速度,降低了数据迁移和拓展难度,实现计算资源和交付效率的全面提升。
相比原有数据处理平台,基于容器化部署的HashData云数仓,具备高可用、高并发能力,计算资源可水平无限扩展、支持秒级扩缩容等能力,并且在扩缩容期间不影响业务连续性,满足不同场景业务数据计算、查询需要,实现了计算资源快速部署、高效交付的建设目标。
同时,在项目实施过程中,中移在线在HashData云原生数据仓库平台计算引擎层构建起多种异构数据技术组件的生态兼容能力,采用融合分析技术,支持把核心仓库区的数据与大数据区的数据进行关联融合分析,减少数据搬迁,提升加工效率和数据资源利用率,满足公司业务部门日益复杂的分析场景需求。最终,通过云原生数据仓库与流处理系统、批处理系统、数据湖、对象存储的集成,实现了数据高效汇聚,以及不同存储之间数据低成本流动与透明访问,助力数据高效融通、赋能生产运营。
此外,本次项目充分发挥了HashData丰富的接口能力与各种开发语言和上下游生态软件兼容性强的特性,顺利实现了云原生数据仓库与现有报表指标工具、智能统计工具、数据洞察工具、自助分析工具、研发云平台等系统的兼容适配,面向用户提供高效的数据检索与分析能力,提升用户数据使用效率和体验。
在存量数据应用迁移方面,借助HashData云原生数据仓库引擎用户自定义函数、用户自定义数据类型的特性,保持数据库引擎间的兼容性;此外,通过HashData完善的迁移工具功能,优化迁移方案,最大程度地实现了存量数据应用的“一键式”自动迁移及验证操作,大幅缩减了迁移人力投入和整体项目周期,快速释放新平台业务价值。
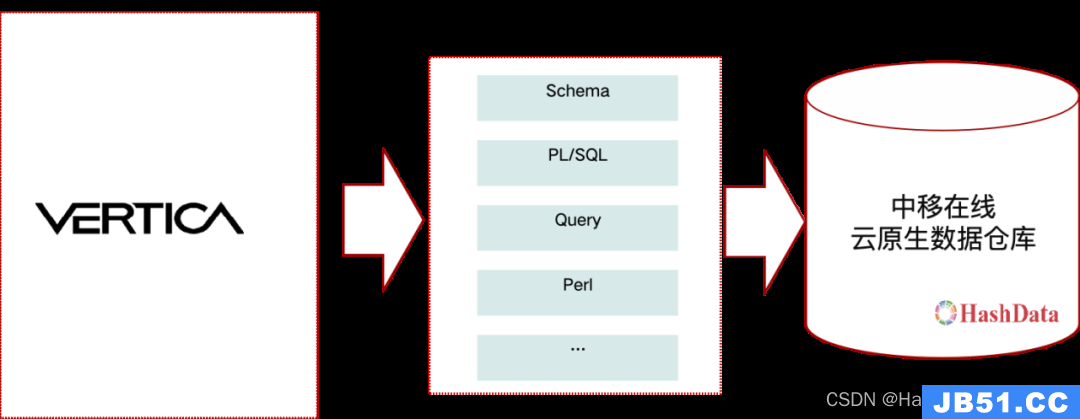
图2:Vertica存量应用工具化迁移方案
项目亮点
在本项目中,中移在线采用了HashData作为构建云原生数据仓库平台的核心引擎。依托HashData强大的数据查询分析能力和云计算弹性伸缩能力,新平台在技术架构、资源交付、业务赋能等方面实现了全方位提升:
- 数据仓库系统架构创新
HashData云数仓解决了传统数据仓库在存算耦合、弹性伸缩、元数据管理等方面的弊端,各模块之间完全解耦,并采用分布式部署,摆脱了传统MPP数据库的各种架构限制和制约,为客户提供成熟稳定的海量数据管理平台,最大限度释放数据价值。
- 数据仓库容器化部署创新
中移在线在国内率先在实际生产环境实现了云数仓容器化大规模部署和应用。通过采用K8S+HashData技术路线,新平台具备秒级快速扩缩容、读写分离、高可用、自动化运维、资源敏捷交付等能力,快速满足业务发展需要,同时也进一步提升了资源利用率,赋能企业降本增效。
- 灵活高效的资源隔离能力创新
基于存算分离的架构,项目实现了基础设施资源和应用解耦,可以根据计算集群的工作负载变化,灵活、动态调配计算集群资源。计算集群间性能相互隔离,资源和操作完全独立,不会产生相互竞争 CPU、内存和IO的情况,从容应对纷繁复杂的数据应用场景。
- 应用驱动的自动缓存能力创新
HashData缓存采用LRU算法,实现了按需、自动化的缓存管理,提升了热点数据访问效率,让底层存储更高效满足上层应用需求。
- 智能化自愈能力创新
HashData提供了管理组件实时监控整个集群的运行状态,当感知到节点故障时将自动执行不同策略下的恢复操作,实现故障自愈,保证整个数仓服务实现高可用,有效适应数仓平台从决策管理辅助系统到业务运营关键支撑平台的转变,并满足用户对平台全天候可用性的预期。
项目价值
基于容器化部署的云原生数据仓库的建成,有效支撑了中移在线打造开放式数据生态体系,推动将数据变为资产并服务于业务,以数据驱动业务增长,实现数据可见、可用、可经营,驱动业务创新和数据管理提速增效:
- 深化云原生技术应用,实现数据基础平台架构云化升级
本次云数仓平台建设,是中移在线实现整个数据基础平台架构云化升级的重要一环。利用HashData云架构的可自由伸缩、灵活调配等优势,大幅提升计算资源快速部署、高效交付能力,支撑架构创新、数据生态、相互融合的特色数据体系,赋能公司未来业务高质量发展。
- 构建OneData数据平台,实现真正意义上的企业级统一数据视图
在本次云数仓平台的建设中,将过往分散在四套独立Vertica集群中的数据统一迁移至全辖共享的对象存储,以更低成本、更高扩展性和可靠性,实现了全部数据资产的统一数据平台纳管,建立起真正意义上的企业级统一数据视图,消除了数据孤岛,避免了数据二义性对业务分析的影响,大幅降低了数据的使用与维护成本。
- 解耦数据应用与数据库集群资源,实现资源管理与运维管理新范式
基于HashData的松耦合架构,创新性实现了数据应用与数据库集群资源的解耦,建立起统一的数据分析算力资源池,实现资源细粒度的管理与调度,支持离线计算与在线计算任务混部,达到峰谷互补的效果,大幅提升服务器资源利用率。
- 建立湖仓一体数据体系,实现不同组件间数据高效融通与共享协作
本次项目建立起了以HashData云数仓为核心的湖仓一体数据体系。通过外部表和连接器这两类组件,实现了面向异构计算工作资源负载下的统一多维度查询分析服务架构,支持在多种计算引擎间共用计算和存储资源,避免了大批量数据的搬迁,有效降低了整体数据链路的成本、代价和复杂性,提升加工效率和数据资源利用率,满足公司业务部门日益复杂的分析场景需求。
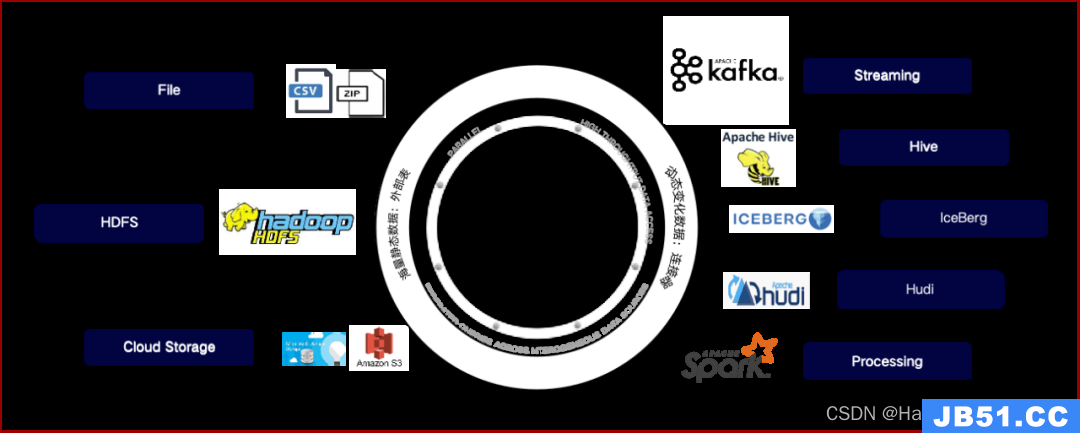
图3:中移在线云原生化数据仓库平台湖仓一体系统集成解决方案示意图
- 完善迁移工具功能,实现存量应用“一键式”快速高效平滑迁移
在存量数据应用迁移方面,通过HashData完善的迁移工具,最大程度实现了存量数据应用的“一键式”自动迁移及验证操作,在较短时间内完成了约600T存量数据、10万个表、2000多个ETL脚本迁移与转换工作,节省了大量人力成本。
同时,在经济效益方面,使用HashData云数仓比在原有Vertica平台基础上扩容升级节省超过千万元;采用存算分离架构以及容器化部署技术方案,硬件资源节省达到30%。
本次项目中,中移在线不仅完成了对传统技术栈的替代,更重要的是在数据仓库平台架构方面实现了技术创新。基于容器化的云原生数据仓库平台,采用全栈信创架构技术栈,支持一云多芯(X86/C86/ARM)、一库双栈(通用/信创),在实现公司数字资产管理和运营全栈自主可控的同时,也实现了数据线全面技术升级。
云原生数据仓库平台从硬件、操作系统、数据库三个维度以信创供应链为基础搭建技术架构,具备高可用、易拓展等特点,结合容器化技术,构建基础算力与存储资源可统一管理、动态调配、敏捷交付,且无对外服务故障“断点”的大数据服务体系。
本次项目全栈自主可控,兼顾安全稳定与敏捷高效,实现了数据算力交付效率全面提升,为中移在线全面提升业务处理的数智化水平奠定了坚实基础,为业务效率与技术融合创新提供了有力支撑。
未来,中移在线和酷克数据将积极响应国家和行业号召,围绕“数字经济、信创工程、创新驱动”的发展战略,积极推进技术架构转型升级,赋能数据高效融通,为提升线上营服能力、营销转化能力构筑强大数据融通计算底座。
公司简介
酷克数据是中国领先具备自主可控研发能力的数据仓库软件厂商,核心团队主要由来自Pivotal、Teradata、IBM、Yahoo!、Oracle和华为等公司资深的云计算、分布式数据库和大数据专家组成。凭借深厚的技术积累以及极具前瞻性的产品理念,HashData数据仓库已广泛应用于金融、电信运营商、能源、政府、交通物流和互联网等多个行业领先客户。
中移在线服务有限公司是中国移动在数字化时代全新设立的全资专业子公司,致力于以更高的服务效能,更优的服务质量,做数字服务的提供者和创新者,成为客户满意、社会信赖的卓越服务品质创造者。
原文地址:https://blog.csdn.net/m0_54979897/article/details/135204041
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。