
一、大数据的3种数据类型
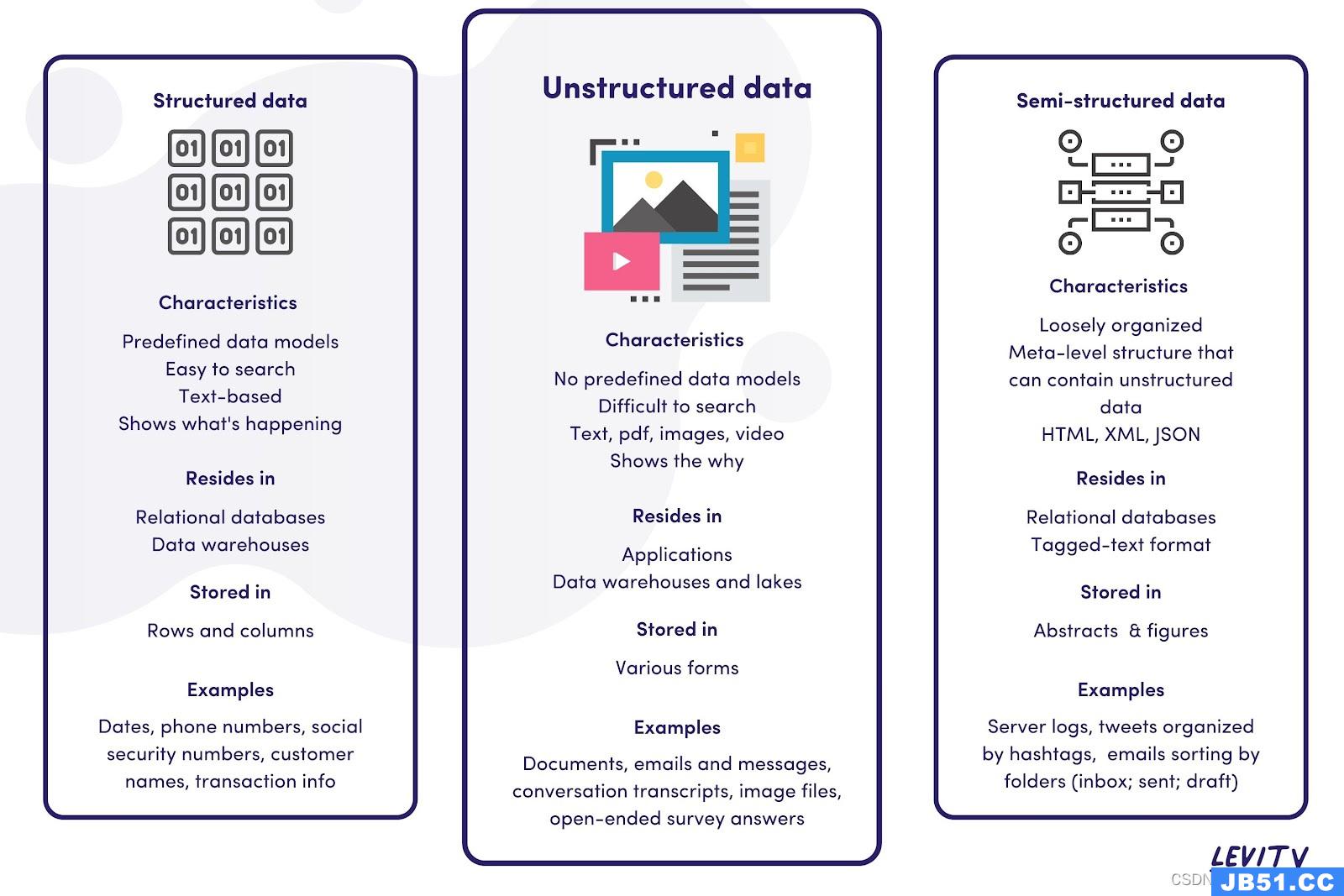
1、结构化数据
可定义,有类型、格式、结构的强制约束
如:RDBMS(关系型数据库管理系统)
2、非结构化数据
没有规律没有数据约束可言,很复杂难以解析
如:文本文件,视频,音频,PDF文件,各种类型文件,图片,邮件等

3、半结构化数据
有一定的格式约束但是不多
如: csv,xml,json,html文件,拥有开标签闭标签规定但是中间内容不确定

二、大数据4V特征
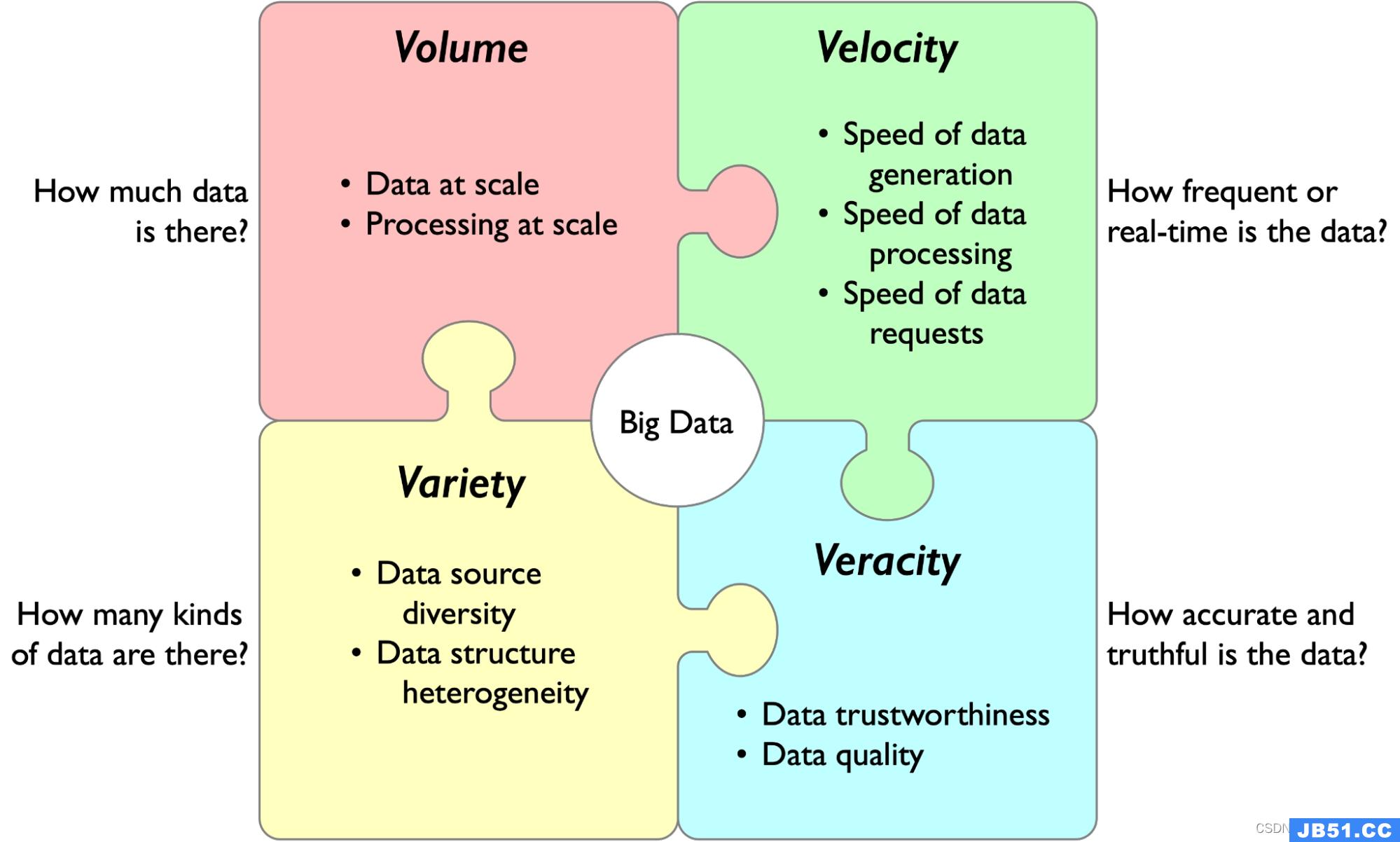
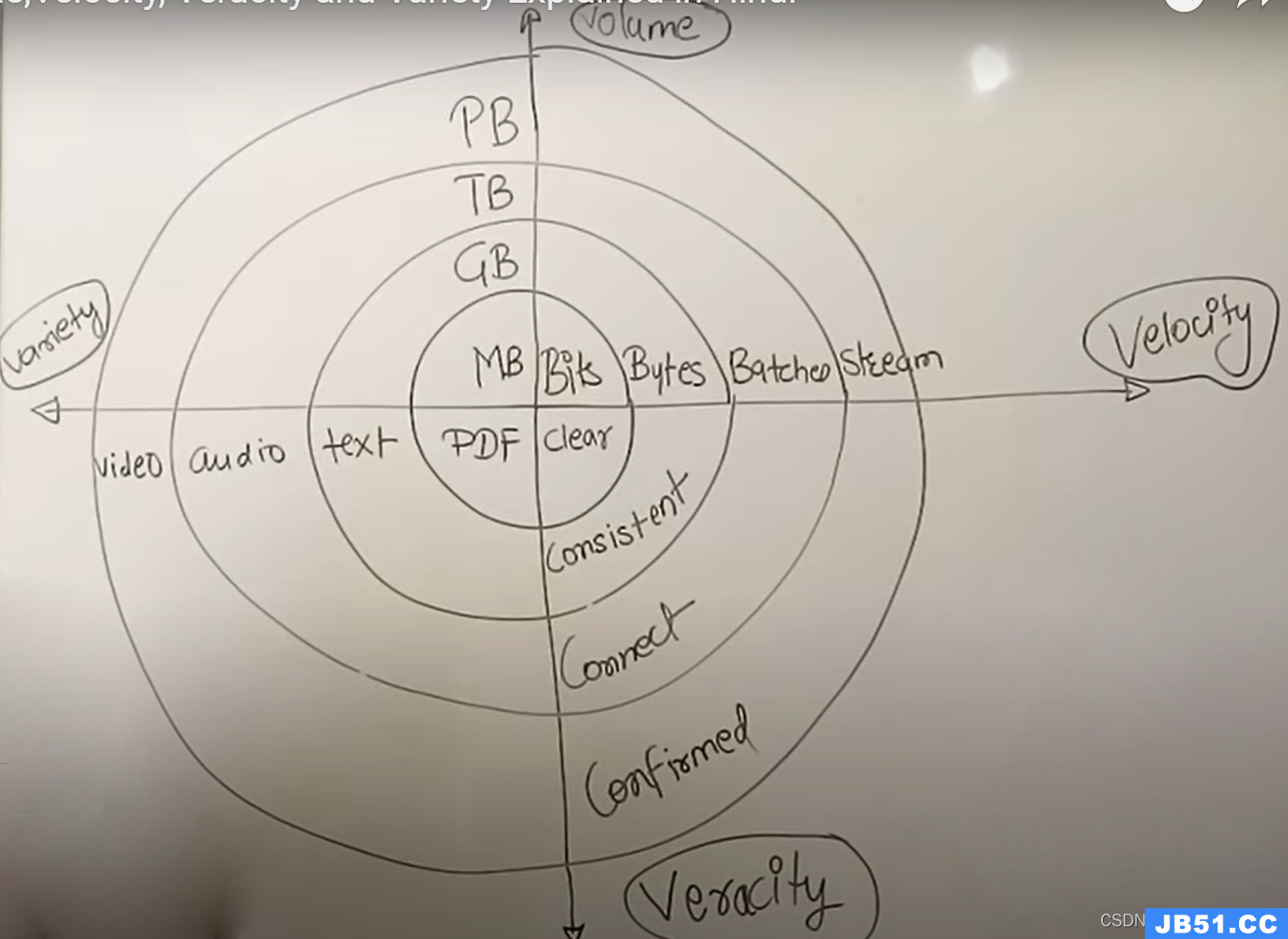
1、Volume 大量性
数据量大,包括采集、存储和计算的量都非常大。
2、Velocity高速性
数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。
3、Variety 多样性
种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
4、Veracity 真实性、精准性
数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。数据的准确性和可信赖度,即数据的质量。数据不一定完整,有一定缺陷
三、什么是Hadoop?
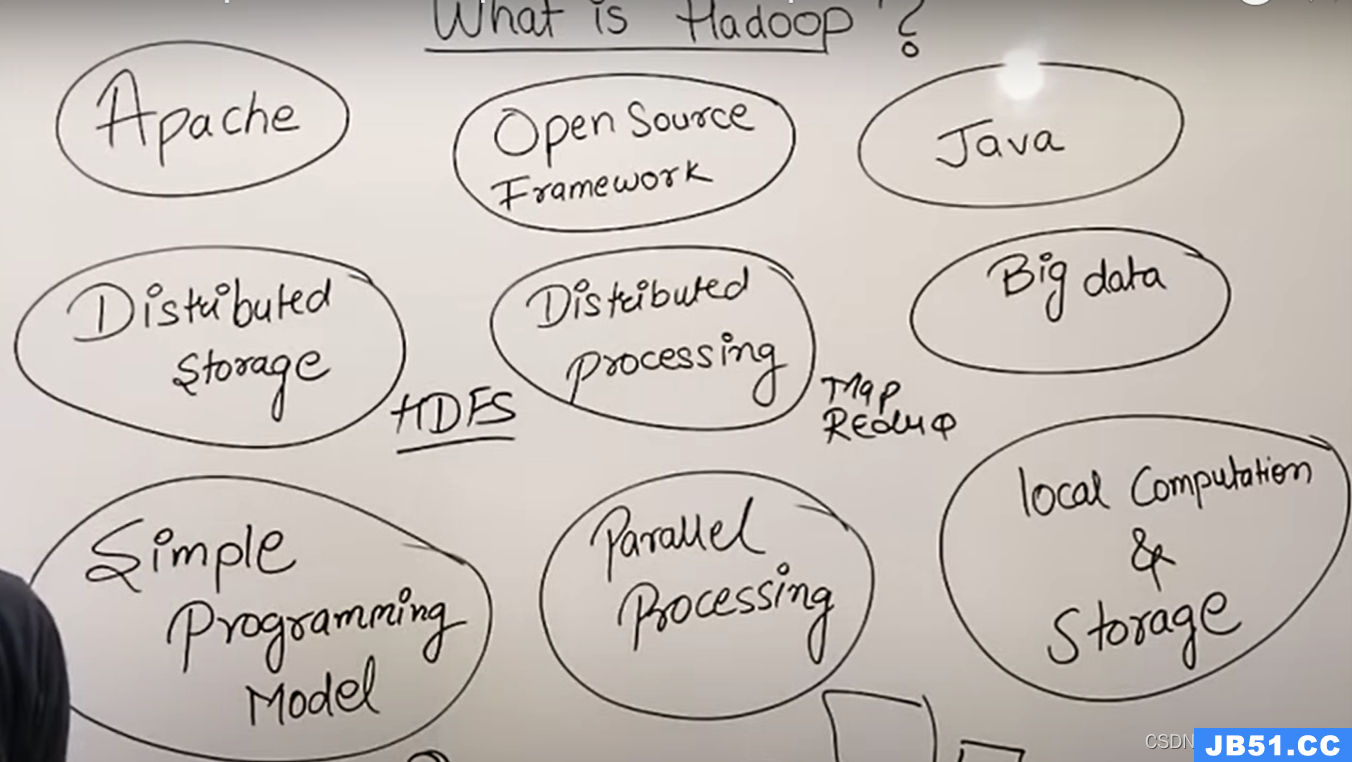
1、Apache公司用Java开发的一种开源框架
2、可以进行大数据的分布式存储(HDFS)+分布式处理(MapReduce)
3、使用自身电脑资源,进行并行化数据处理,代码处理模式简单
四、Hadoop内部框架
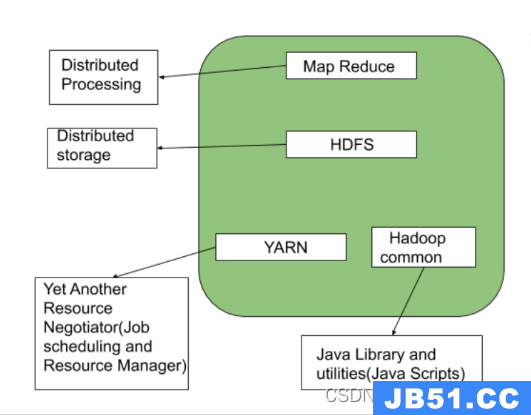
1、Hadoop Common
Hadoop的通用类,Hadoop是基于Java开发的,所以需要一些Java的库和实体类的支持
2、HDFS
HDFS 全称为Hadoop Distribute File System,中文名为Hadoop分布式文件系统,用于文件的存储
3、MapReduce
MapReduce是分布式处理框架,分为Map和Reduce两部分,用于数据处理
4、YARN
YARN全称为 Yet Another Resource Negotiate,中文名为另一个资源协调者,用于作业管理和资源调度。
五、YARN例子讲解
1、作业管理
比如,班级里需要搬凳子搬桌子擦窗子,班长可以安排1-5号同学搬凳子,安排6-10号同学搬桌子,安排11-15号同学擦窗子。这个班长(Yarn),安排不同的人(电脑)做不同的事情(作业)
2、资源调度
1-5号同学搬凳子,有男有女,男同学力气大所以每人搬10张,女生力气小所以每人搬2张,6-10号同学搬桌子,有男有女,男同学力气大所以每人搬10张,女生力气小所以每人搬2张,11-15号同学擦窗子,有男有女,男同学体力好所以每人擦3扇,女生体力差所以每人擦1扇,这个过程就是资源调度,班长(Yarn)安排男生(性能好的电脑,空闲的电脑)多干点,安排女生(性能差点的电脑,繁忙的电脑)少干点。
六、Hadoop Cluster (Hadoop集群)
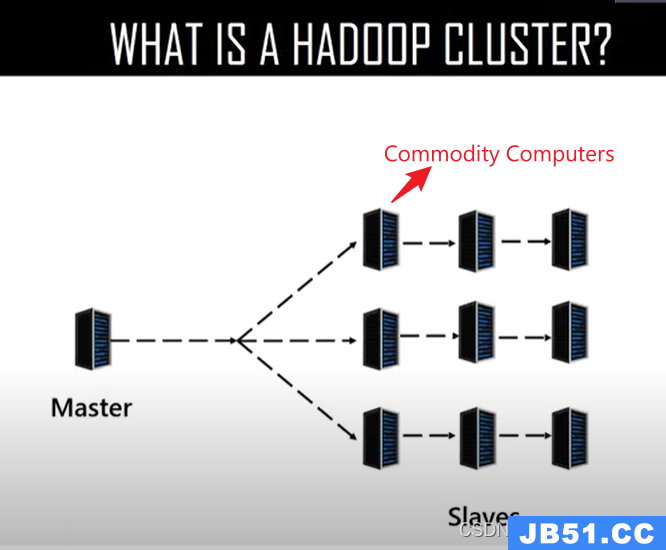
1、Hadoop集群的架构为“主”“从”架构
2、由一台电脑作为主电脑,其他多台电脑作为从电脑相互关联组成
3、主电脑的配置一般比较好性能比较高,从电脑一般是市面上的普通商品电脑,性能普通
4、在Hadoop中后续会将电脑称之为“节点”。
七、Hadoop Cluster Detail(Hadoop集群详解)
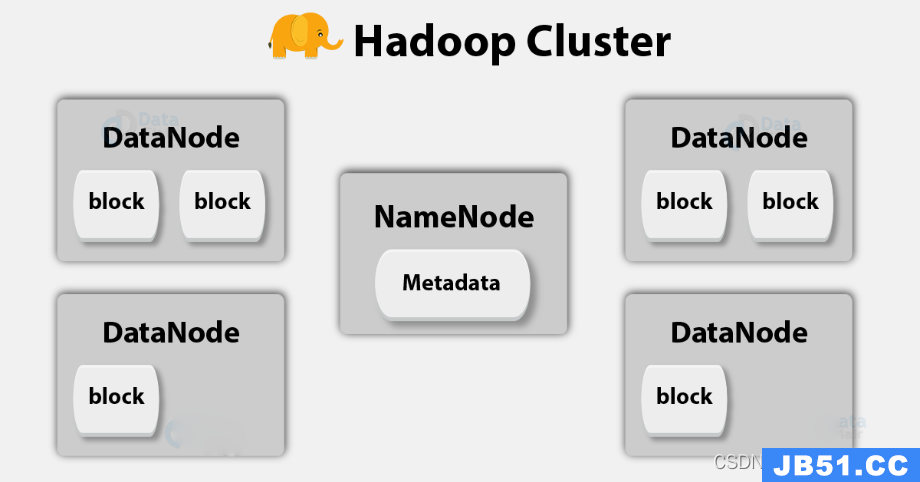
1、Hadoop集群的主从架构
主节点叫做NameNode,从节点叫做DataNode
2、从节点用于数据的实际存放
数据存放时会将文件首先进行拆块(split block),不同的块(block)文件会存放在不同的从节点中,Hadoop1.x版本中,块的默认大小为64MB,Hadoop2.xHadoop3.x中,默认块大小为128MB。
3、主节点用于记录数据,不用于存放数据
主节点中有一个MetaData文件,叫做元数据文件,也被称为记录数据的数据文件,一般记录分块文件信息,块名字信息,块大小信息,块路径信息,等等。
八、Hadoop 历史
1、Hadoop创始人叫Doug Cutting,2006年Hadoop问世
2、Hadoop的图标是他儿子的大象玩具
九、Hadoop 4种安装模式
1、Local runtime mode 单机模式
一般用于测试和debug,无进程
2、Pseudo-distributed operating mode 伪分布模式
一般用于学习,一台机器上有一个主节点一个从节点和其他环境
3、Fully distributed operating mode 全分布模式
多台机器,一台作为主节点,其他作为从节点,完全符合Hadoop集群架构
4、High availability(HA) operating mode 高可用模式
保证Hadoop的一切运行顺利,有两个主节点其中一个是备份
原文地址:https://blog.csdn.net/agatha_aggie/article/details/133634410
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。