
## 基于大数据的K-means广告效果分析
项目运行效果:
毕业设计 基于大数据的K-means广告效果分析
项目获取:
https://gitee.com/sinonfin/algorithm-sharing
一、分析背景和目的
在大数据时代的背景下,广告主可以购买媒介变成直接购买用户,广告的精准投放对广告主、服务平台与潜在用户而言,在提升效率与商业效益方面,有了更迫切的需求,然而网络广告形式多样,很多广告投放系统相对缺乏针对性,使得网络广告精准度不够高,因此,对推广数据的研究是十分必要的。所有本次项目将从用户特征,投放时间,投放位置以及高点击率广告的特征等方面多维度进行数据分析,以提高用户点击率,实现淘宝展示广告精准投放,实现广告投放效果最大。
注意:本文是博主自主探索数据分析的记录和总结,有些方法和结论会存在错误,希望对你学习有帮助的话我很高兴,但是有问题的话希望给小弟批评和指正。
本文使用的数据工具为mysql 和 tableau
二、数据集
数据来源阿里天池,数据集
| 数据名称 | 说明 | 属性 |
|---|---|---|
| raw_sample | 原始样本骨架 | 用户id,广告id,时间,资源位,是否点击 |
| ad_feature | 广告的基本信息 | 广告id,广告计划id,类目id,品牌id |
| user_profile | 用户的基本信息 | 用户id,年龄层,性别等 |
| raw_behavior | 用户的行为日志 | 用户id,行为类型,时间,商品类目id,品牌id |
具体字段如图:
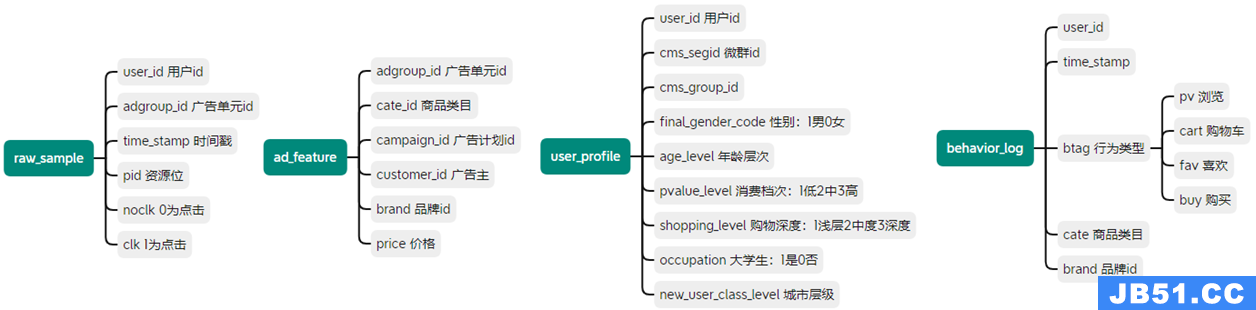
三、分析框架和思路
对于衡量广告投放效果有三种模式:

对于cpc模式,点击率 = 点击量 / 展示量,可以使用点击量衡量投放效果,对于品牌来说,是根据点击量来进行付费的,点击率则可以体现广告的吸引力。
对于cpa模式,可以构建两个漏斗,即浏览—收藏—购买,浏览—加入购物车—购买,观察转换率可以衡量投放效果。
四、数据预处理
- 原数据集太大,为了方便分析,在raw_sample数据集中截取300w条数据
- 数据缺失值处理,如果出现缺失,将缺失的行删除即可(简单方法)
select count(user_id),count(adgroup_id),count(time_stamp),count(pid),count(noclk),count(clk)
from raw_sample;
在 user_profile 数据中 pvalue_level 字段缺失率高达53.1%,这里可以使用knn算法进行预测填充
(我比较菜,先直接忽略,后续学习python之后进行补充),而 new_user_class_level 字段的缺失率也有27.4%,可以使用众数进行补充。
- 数据重复值处理
select user_id,adgroup_id,time_stamp,pid,noclk,clk
from raw_sample
group by user_id,nonclk,clk
having count(user_id) >1;
- 数据异常值,比如有无超出时间范围
- 时间处理,将时间戳分解为日期和时间
alter table raw_sample add time_date varchar(20);
alter table raw_sample add time_hour varchar(20);
update raw_sample set time_date = left(from_unixtime(time_stamp),10);
update raw_sample set time_hour = right(from_unixtime(time_stamp),8);
五、数据分析
1. 广告投放渠道分析
select pid '资源位',(select COUNT(*) from raw_sample) '展示量',sum(clk) '点击量',sum(clk) / (select COUNT(*) from raw_sample) '点击率'
from raw_sample
group by pid;

结论:4300548_1007的广告投放效果会更好,而且广告吸引力也更大。
2. 广告投放时间分析
2.1 24h的投放效果
select left(time_hour,2) '小时',COUNT(*) '展示量',sum(clk) '点击量',sum(clk) / COUNT(*) '点击率'
from raw_sample
group by left(time_hour,2)
order by left(time_hour,2) ;
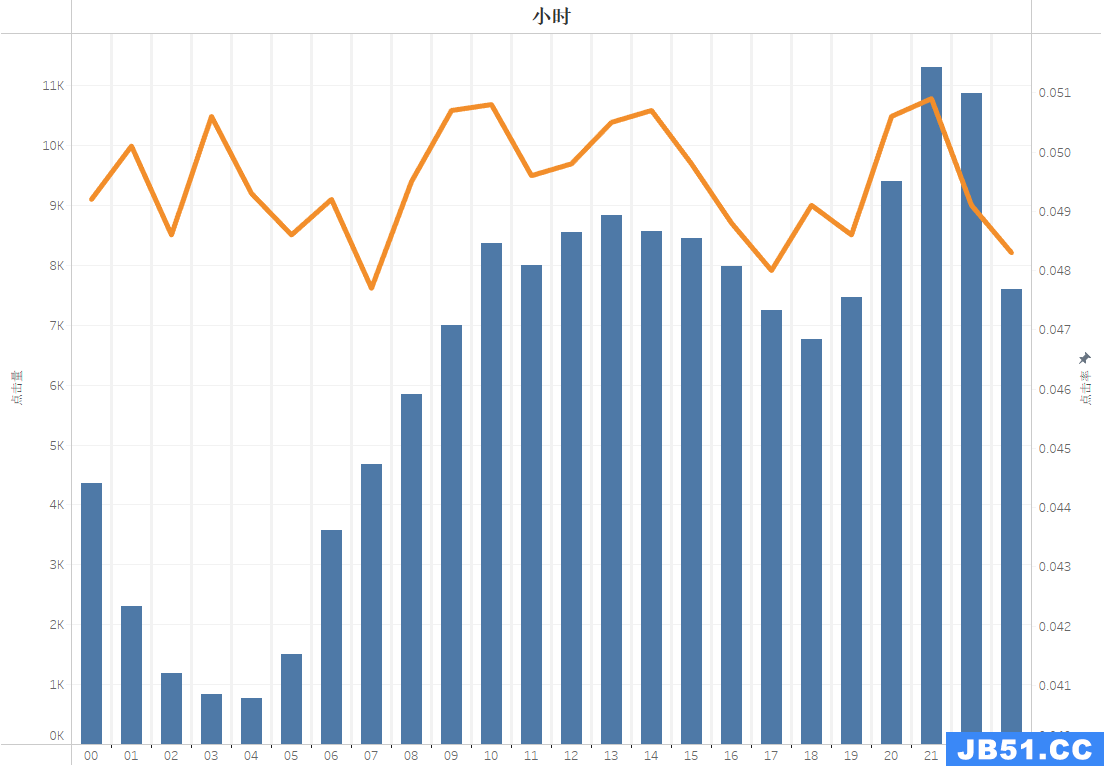
结论:
- 点击量基本符合人们的作息规律,而点击率在9-10点、13-14点和20-21点都比较高,这些时间基本就是人们工作前、中
- 奇怪的是在半夜1点和3点的时候点击率居然比较高,问题可能是展现量较低但点击量高,夜猫子刷淘宝的时候不容易被其他事情分散注意力,我觉得可以探索一下哪个品类的东西深得夜猫子浏览和点击,适当的进行实验性营销。
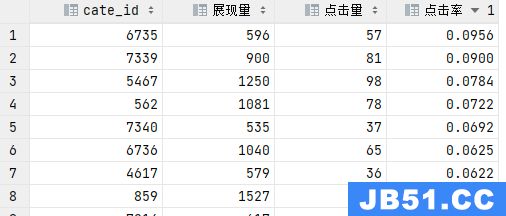
说干就干,首先查看整体展现量分布,发现将近90%的展现量在1000以内,所以我截取了时间在0-4点并且展现量大于500的商品类目,如下图确实有几个点击率很高的类目,不过他们的投入产出是否合理,这个还是看具体情况吧。
2.2 一周(8天)的投放效果
select right(time_date,2) '日期',COUNT(*) '展示量',sum(clk) '点击量',sum(clk) / COUNT(*) '点击率'
from raw_sample
group by right(time_date,2)
order by right(time_date,2) ;
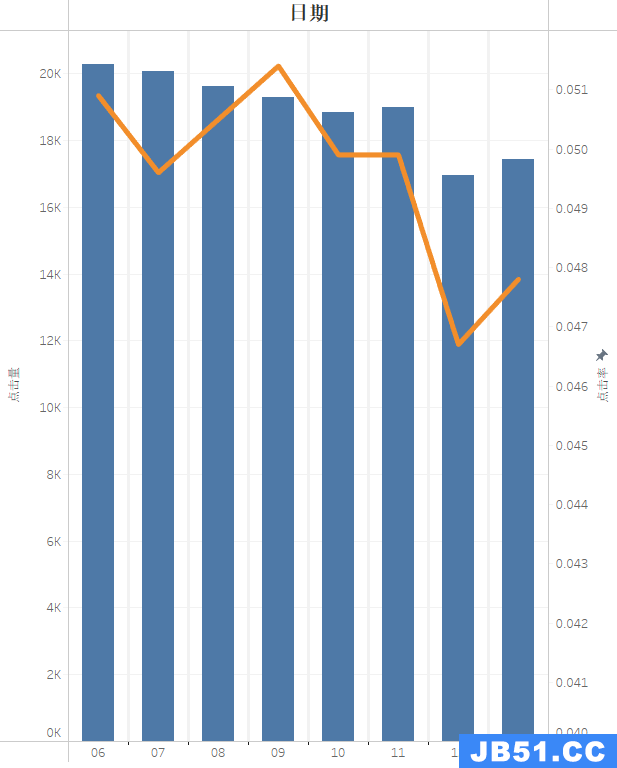
结论:2017年5月6号是星期六,周末的展现量较高比较符合作息规律,周二的点击率比较高,但是周末点击率为什么比较低?因为展现量高?周五的点击率最低,是什么原因造成,这些可能需要具体分析,可以进行与其他日期进行对比分析,对比不同日期24小时效果分析。
3、广告投放人群分析
3.1 用户性别分析
select if(final_gender_code = 1,'男','女') '性别',sum(clk) / (select COUNT(*) from raw_sample) '点击率'
from raw_sample,user_profile
where raw_sample.user_id = user_profile.userid
group by final_gender_code
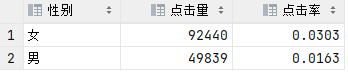
结论:相比于男性,女性更容易被广告吸引,点击量更高。
3.2 用户消费档次分析
select case when pvalue_level =1 then '1'
when pvalue_level =2 then '2'
when pvalue_level =3 then '3'
end '消费档次',user_profile
where raw_sample.user_id = user_profile.userid and
pvalue_level is not null -- 缺失值未处理,直接排除
group by pvalue_level
order by pvalue_level;
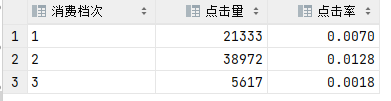
结论:由于缺失值未处理,所以结论有问题,但不影响本文分析,消费档次为2的用户更容易被吸引。
3.3 用户购物深度分析
select case when shopping_level =1 then '浅层'
when shopping_level =2 then '中层'
when shopping_level =3 then '深层'
end '购物深度',user_profile
where raw_sample.user_id = user_profile.userid
group by shopping_level
order by shopping_level;
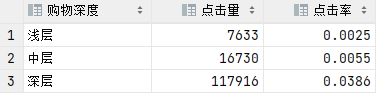
结论:深度使用的用户更容易被广告吸引。
3.4 用户人群分析
select case when occupation =1 then '大学生'
when occupation =0 then '非大学生'
end '用户人群',user_profile
where raw_sample.user_id = user_profile.userid
group by occupation;

结论:非大学生群体更容易被广告吸引。
3.5 用户年龄分析
select age_level '年龄层次',user_profile
where raw_sample.user_id = user_profile.userid
group by age_level;
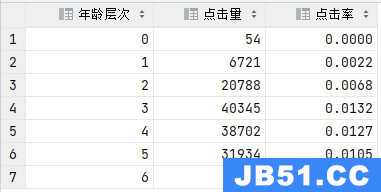
结论:年龄在3层的用户更容易被吸引
3.6 用户城市层次分析
select new_class_level '城市层次',user_profile
where raw_sample.user_id = user_profile.userid
group by new_class_level;
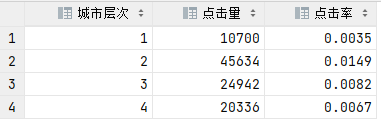
结论:在城市层次2的用户更容易被广告吸引。
4、用户行为指标衡量广告投放效果(CPA)
select btag,count(btag)
from behavior_log
group by btag
order by count(btag);
浏览—加入购物车—购买的漏斗模型:
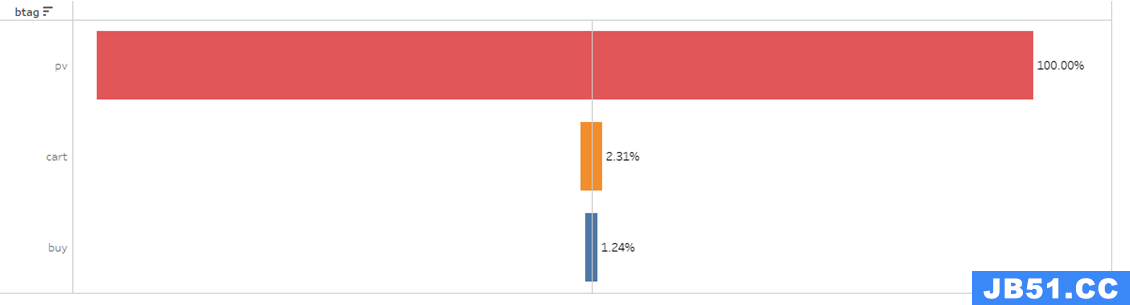
六、结论和建议
- 渠道:4300548_1007资源位的广告投放效果会更好;
- 时间:在9-10点、13-14点和20-21点的时候点击率会更高,周二的点击率更高;
- 用户:女性、中档消费、深度购物、非大学生、年龄3档、城市层级2层的用户投放效果会更好。
本文只分析了全体的投放效果,正常需要结合品牌、商品类目和价格等进行分析,也可以结合转化率一起分析。
项目运行效果:
毕业设计 基于大数据的K-means广告效果分析
项目获取:
https://gitee.com/sinonfin/algorithm-sharing
原文地址:https://blog.csdn.net/mabile123444/article/details/135951204
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。