
前言
Kettle 是小有名气的开源ETL工具,现已改名为PDI(Pentaho Data Integration),其Web版本为:WebSpoon,本文记录了从官方Git仓库中拉取代码并成功运行的过程。
一、在本地拉取并编译项目
编译依赖项目
根据 _Build and locally publish dependent libraries _部分可知,需要预先在本地编译部分依赖项目。
pentaho-xul-swt
$ git clone -b webspoon-9.0 https://github.com/HiromuHota/pentaho-commons-xul.git
$ cd pentaho-commons-xul
$ mvn clean install -pl swt
rap
$ git clone -b webspoon-3.12.0 https://github.com/HiromuHota/rap.git
$ cd rap
$ mvn clean install
在mvn install出现报错时,可能的解决方案:
jetty-repo 版本修改为:9.4.48.v20220622
rap-extra-repo 修改为: https://download.eclipse.org/rt/rap/base-platforms/3.14/extra-dependencies/
pentaho-vfs-browser
$ git clone -b webspoon-9.0 https://github.com/HiromuHota/apache-vfs-browser.git
$ cd apache-vfs-browser
$ mvn clean install
将上述三个依赖项目编译后,在maven仓库的对应目录下会生成相应的jar文件。
编译本体项目
$ git clone -b webspoon-9.0 https://github.com/HiromuHota/pentaho-kettle.git
$ cd pentaho-kettle
$ mvn clean install -DskipTests
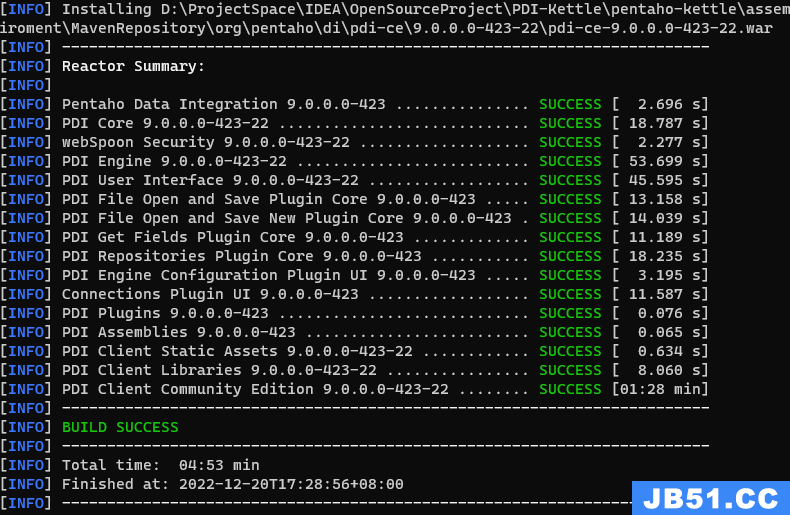
成功示例:
(在assemblies模块下的client模块中的target文件夹内生成对应的war包)
可能的报错:
- 大面积报错找不到pom文件
解决方法:根据 Kettle官方Git页面master分支的README文件 中的setting.xml文件配置maven
- 找不到某个依赖的artifact文件
下图为示例:
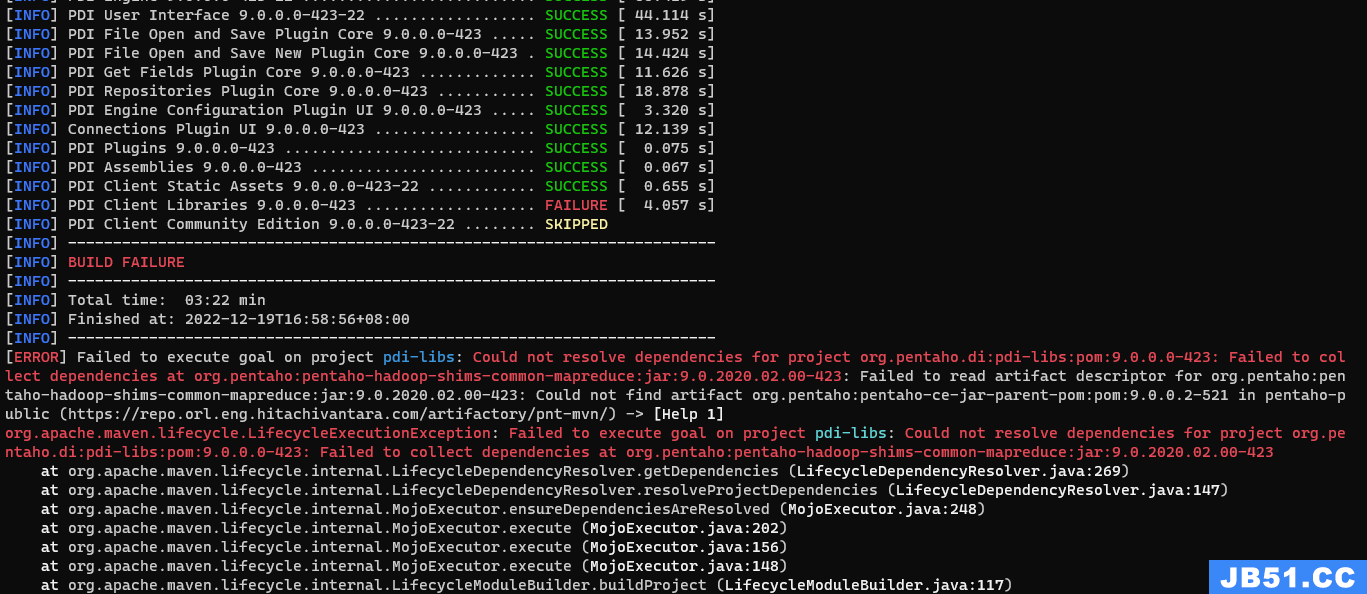
原因分析及解决方案:maven配置的pentaho-public镜像地址所在的仓库有一些依赖版本缺失,当出现此错误后分析了项目源码,并未搜索到缺失依赖版本的明文引用,但是在编译时仍有报错,所以可以认为是在编译时由于间接引用了特定版本导致了报错。通过去pentaho-public仓库中逐个查找发现确实没有报错的pom版本(恰好丢失了该版本),一个取巧的解决方法是在本地的maven仓库目录中新建该版本,并将最临近的最新一版的pom及签名文件复制进去,再按需改名后即可通过编译。如: 报错1.2版本丢失,经仓库地址查找发现确实不存在1.2版本,但是有1.3版本,就可以把1.3版本复制到本地1.2对应目录下并改成对应的名字,以实现绕过maven的检查机制。
二、在本地运行项目
-
将war包放在 \webapps 文件夹下(示例:pdi-ce-9.0.0.0-423-22.war)
-
修改tomcat主目录/conf/server.xml文件,在
<Host>标签内加入:
<Context path="/pdi" docBase="pdi-ce-9.0.0.0-423-22" reloadable="false" source="org.eclipse.jst.jee.server:tsj-spring"/>
<!-- /pdi为浏览器地址栏ip:port后的访问地址 -->
<!-- docBase中的pdi-ce-9.0.0.0-423-22为项目在webapps目录下,编译后项目文件的实际路径;配置该项是为了读取下文的驱动文件 -->
-
访问本地url:http://localhost:8080/pdi/spoon
-
完成数据库的连接工作(数据库的准备工作略去)
- 下载MySQL的jdbc驱动文件:mysql-connector-java-5.1.49.jar(因版本过高的jdbc文件目录结构改变,kettle无法支持)
- 将驱动文件放置于:tomcat主目录\webapps\pdi-ce-9.0.0.0-423-22\WEB-INF\lib
三、在服务器运行项目
- 拉取docker镜像
docker pull hiromuhota/webspoon
- 创建并运行docker容器
docker run -d -p 8080:8080 hiromuhota/webspoon --name webspoon --restart=always
#-d 后台映射
#8080:8080 服务器实际端口:映射的容器端口
#hiromuhota/webspoon 要运行的镜像名称
#--name webspoon 容器名设定为webspoon
#--restart=always 容器设定为随docker重启而自动重启
#记得打开服务器的端口防火墙
- 测试运行结果:http://服务器IP:8080/spoon/spoon
- 汉化界面(可选)
- 上传MySQL驱动文件至容器内
cd /home/upload_files/
#无此文件夹则创建,将驱动文件上传至本目录下
docker cp mysql-connector-java-5.1.49.jar webspoon:/usr/local/tomcat/webapps/spoon/WEB-INF/lib
#将MySQL驱动复制到容器webspoon的/usr/local/tomcat/webapps/spoon/WEB-INF/lib路径下面
docker restart webspoon
#重启以生效,并在浏览器进行数据库连接测试
- 挂载服务器本地路径至容器内,方便文件的生成与交换
参考文章
可能出现的问题:
- systemctl start docker启动失败
解决办法:使用systemctl status docker确认启动状态,根据报错信息修复配置文件
doker ps
cd /var/lib/docker/containers/容器id
systeamctl stop docker
#获取容器id,进入容器配置路径修改配置文件
"/home/pdi_files": {"Source": "/home/kettle/pdi_files","Destination": "/home/pdi_files","RW": true,"Name": "","Driver": "","Type": "bind","Propagation": "rprivate","Spec": {"Type": "bind","Source":"/home/kettle/pdi_files","Target": "/home/pdi_files"},"SkipMountpointCreation": false}
## 修改config.v2.json,将本地的/home/kettle/pdi_files 路径映射到容器的 /home/pdi_files
"Binds":["/home/kettle/pdi_files:/home/pdi_files"]
#修改hostconfig.json
systemctl start docker
docker start 容器名
#重启docker及容器
# 挂载失败时会无法找到并启动容器,需要二次确认配置文件是否修改正确
docker exec -it 容器名 /bin/bash
# 进入容器路径确认是否挂载成功
- 配置文件夹权限
如果没有对容器内的路径做权限配置,文件将无法读取和写入
sudo docker exec -it -u root 容器id bash
# 以root权限进入容器
cd /home/
chmod 777 ./pdi_files
#给特定目录赋权
- 自定义数据库表并测试转换任务
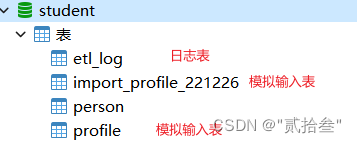
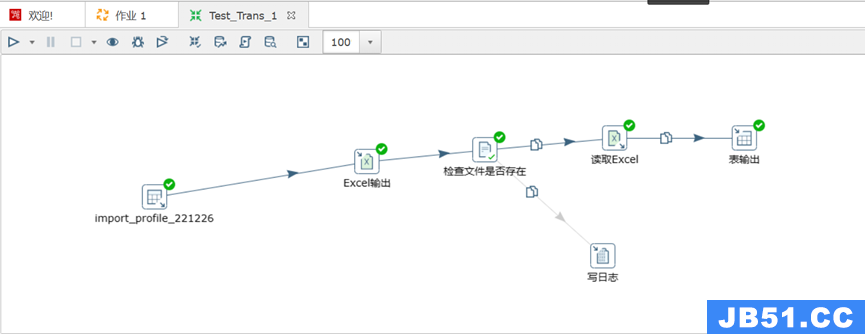
该作业涉及到表输入、文件输出、文件输入、表输出、日志记录,可以简单测试pdi是否成功工作。
- 配置资源库(可选)
-
点击主页右上角的connect按钮,填入个人的etl资源库连接信息。
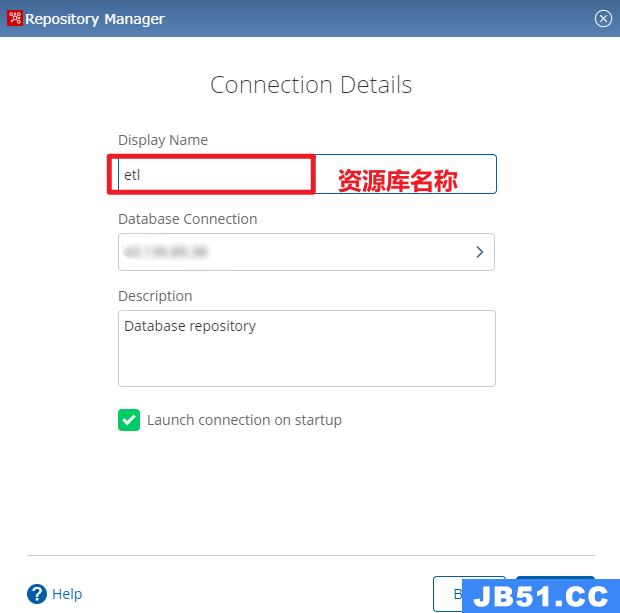
-
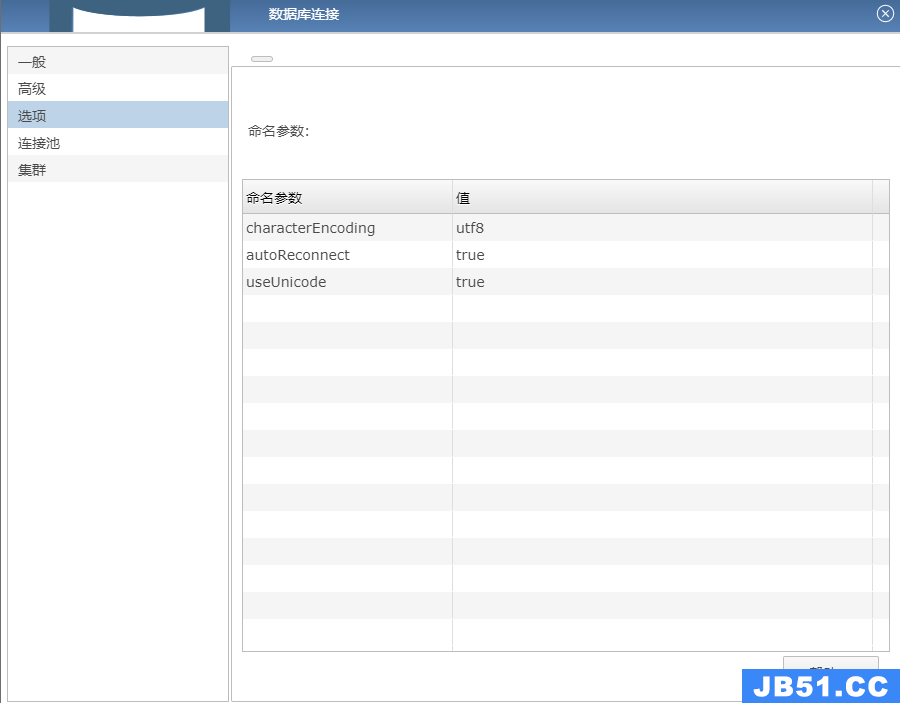
在连接资源库时需要选择数据库连接,在编辑数据库连接时修改参数以使中文正常显示:
- 修改kettle配置文件,开启api访问功能(可选)
使用官方镜像部署kettle之后,可以通过进入容器的方式修改相关文件
docker exec -it 容器ID /bin/bash
vim ./system/kettle/slave-server-config.xml
将slave-server-config.xml文件内容修改为:
<slave_config>
<max_log_lines>10000</max_log_lines>
<max_log_timeout_minutes>2880</max_log_timeout_minutes>
<object_timeout_minutes>240</object_timeout_minutes>
<repository>
<!-- 填入你自己拥有的Kettle资源库名称,与上方第九步图示中的名称一致 -->
<!-- 该名称决定了在使用api方式访问kettle时,kettle默认连接的配置资源库 -->
<name>etl</name>
<username>xxxxx</username> <!-- 填入目标资源库连接账号 -->
<password>xxxxx</password> <!-- 填入目标资源库连接密码 -->
</repository>
</slave_config>
这样就开启了kettle的内置API访问功能,功能入口有:

测试访问API效果:
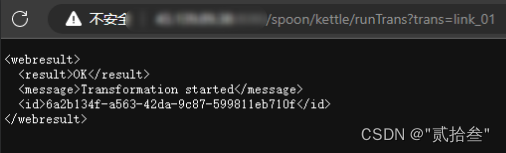
问题来了,这些api入口都是可用的吗,需要传输哪些参数?有没有文档?
我的回答是:可以去网上搜搜,没有找到答案的话最好自己看源码。
Kettle目前已经转为了商业化项目(hitachivantara公司官网),也有自己的社区(hitachivantara公司论坛),感兴趣的可自行探索。
结束语
- Git拉项目确实要多看一下README文件,该有的准备工作不可少
- PDI的C/S和B/S架构、页面都差不多,可看作是孪生项目
- 市面上支持Web端且免费的ETL工具不多,WebSpoon可作为一个选择
原文地址:https://blog.csdn.net/Ka__ze/article/details/128454956
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。