
文章目录
前言
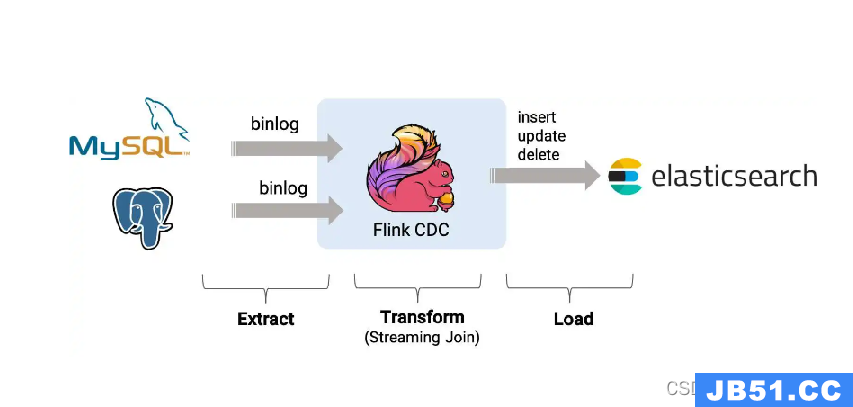
前面的博文我们分享了大数据分布式流处理计算框架Flink和其基础环境的搭建,相信各位看官都已经搭建好了自己的运行环境。那么,今天就来实战一把使用Flink CDC同步Mysql数据导Elasticsearch。
知识积累
CDC简介
CDC 的全称是 Change Data Capture(变更数据捕获技术) ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
CDC的种类
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
基于查询的 CDC:
◆离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
◆无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
◆不保障实时性,基于离线调度存在天然的延迟。
基于日志的 CDC:
◆实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
◆保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
◆保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
常见的CDC方案比较

Springboot接入Flink CDC
由于Flink官方提供了Java、Scala、Python语言接口用以开发Flink应用程序,故我们可以直接用Maven引入Flink依赖进行功能实现。
环境准备
1、SpringBoot 2.4.3
2、Flink 1.13.6
3、Scala 2.11
4、Maven 3.6.3
5、Java 8
6、mysql 8
7、es 7
Springboot、Flink、Scala版本一定要相匹配,也可以严格按照本博客进行配置。
注意:
如果只是本机测试玩玩,Maven依赖已经整合计算环境,不用额外搭建Flink环境;如果需要部署到Flink集群则需要额外搭建Flink集群。另外Scala 版本只是用于依赖选择,不用关心Scala环境。
项目搭建
1、引入Flink CDC Maven依赖
pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>flink-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>flink-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<flink.version>1.13.6</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<!-- Flink CDC connector for MySQL -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.1.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--
Flink CDC connector for ES
https://mvnrepository.com/artifact/org.apache.flink/flink-connector-elasticsearch7_2.11
-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-json -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-bridge_2.11 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner_2.11 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients_2.11 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java_2.11 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2、创建测试数据库表users
users表结构
CREATE TABLE `users` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',`name` varchar(50) NOT NULL COMMENT '名称',`birthday` timestamp NULL DEFAULT NULL COMMENT '生日',`ts` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户';
3、es索引操作
es操作命令
es索引会自动创建
#设置es分片与副本
curl -X PUT "10.10.22.174:9200/users" -u elastic:VaHcSC3mOFfovLWTqW6E -H 'Content-Type: application/json' -d'
{
"settings" : {
"number_of_shards" : 3,"number_of_replicas" : 2
}
}'
#查询index下全部数据
curl -X GET "http://10.10.22.174:9200/users/_search" -u elastic:VaHcSC3mOFfovLWTqW6E -H 'Content-Type: application/json'
#删除index
curl -X DELETE "10.10.22.174:9200/users" -u elastic:VaHcSC3mOFfovLWTqW6E
本地运行
@SpringBootTest
class FlinkDemoApplicationTests {
/**
* flinkCDC
* mysql to es
* @author senfel
* @date 2023/8/22 14:37
* @return void
*/
@Test
void flinkCDC() throws Exception{
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
//.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env,fsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
// 数据源表
String sourceDDL =
"CREATE TABLE users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = '10.10.10.202',\n" +
" 'port' = '6456',\n" +
" 'username' = 'root',\n" +
" 'password' = 'MyNewPass2021',\n" +
" 'server-time-zone' = 'Asia/Shanghai',\n" +
" 'database-name' = 'cdc',\n" +
" 'table-name' = 'users'\n" +
" )";
// 输出目标表
String sinkDDL =
"CREATE TABLE users_sink_es\n" +
"(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
") \n" +
"WITH (\n" +
" 'connector' = 'elasticsearch-7',\n" +
" 'hosts' = 'http://10.10.22.174:9200',\n" +
" 'index' = 'users',\n" +
" 'username' = 'elastic',\n" +
" 'password' = 'VaHcSC3mOFfovLWTqW6E'\n" +
")";
// 简单的聚合处理
String transformSQL = "INSERT INTO users_sink_es SELECT * FROM users";
tableEnv.executeSql(sourceDDL);
tableEnv.executeSql(sinkDDL);
TableResult result = tableEnv.executeSql(transformSQL);
result.print();
env.execute("mysql-to-es");
}
请求es用户索引发现并无数据:
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:0,“timed_out”:false,“_shards”:{“total”:3,“successful”:3,“skipped”:0,“failed”:0},“hits”:{“total”:{“value”:0,“relation”:“eq”},“max_score”:null,“hits”:[]}}
操作mysql数据库新增多条数据
5 senfel 2023-08-30 15:02:28 2023-08-30 15:02:36
6 sebfel2 2023-08-30 15:02:43 2023-08-30 15:02:47
再次获取es用户索引查看数据
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:67,“hits”:{“total”:{“value”:2,“max_score”:1.0,“hits”:[{“_index”:“users”,“_type”:“_doc”,“_id”:“5”,“_score”:1.0,“_source”:{“id”:5,“name”:“senfel”,“birthday”:“2023-08-30 15:02:28”,“ts”:“2023-08-30 15:02:36”}},{“_index”:“users”,“_id”:“6”,“_source”:{“id”:6,“name”:“sebfel2”,“birthday”:“2023-08-30 15:02:43”,“ts”:“2023-08-30 15:02:47”}}]}}
由上测试结果可知本地运行无异常。
集群运行
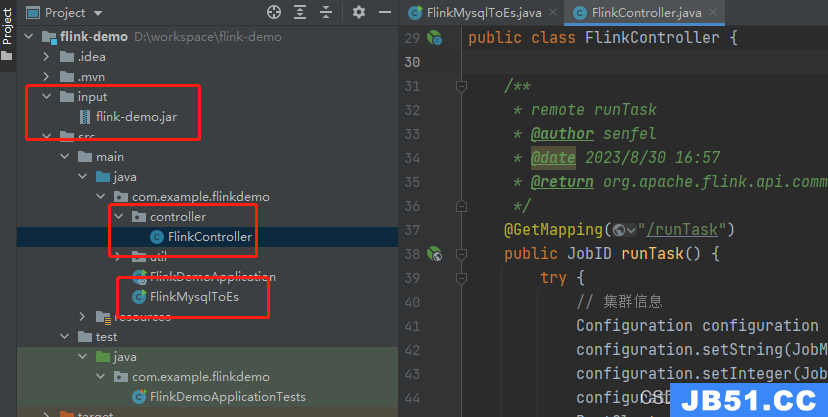
项目树:
1、创建集群运行代码逻辑
/**
* FlinkMysqlToEs
* @author senfel
* @version 1.0
* @date 2023/8/22 14:56
*/
public class FlinkMysqlToEs {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
//.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env,\n" +
" 'password' = 'VaHcSC3mOFfovLWTqW6E'\n" +
")";
// 简单的聚合处理
String transformSQL = "INSERT INTO users_sink_es SELECT * FROM users";
tableEnv.executeSql(sourceDDL);
tableEnv.executeSql(sinkDDL);
TableResult result = tableEnv.executeSql(transformSQL);
result.print();
env.execute("mysql-to-es");
}
}
2、集群运行需要将Flink程序打包,不同于普通的jar包,这里必须采用shade
<build>
<finalName>flink-demo</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>module-info.class</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
<resource>reference.conf</resource>
</transformer>
<transformer
implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.flinkdemo.FlinkMysqlToEs</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
将项目打包将包传入集群启动
1、项目打包
mvn package -Dmaven.test.skip=true
2、手动上传到服务器拷贝如集群内部运行:
/opt/flink/bin# ./flink run …/flink-demo.jar
3、测试操作mysql数据库
删除id =6只剩下id=5的用户
5 senfel000 2023-08-30 15:02:28 2023-08-30 15:02:36
4、查询es用户索引
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:931,“hits”:{“total”:{“value”:1,“ts”:“2023-08-30 15:02:36”}}]}}[
如上所示es中只剩下了id==5的数据;
经测试手动部署到集群环境成功。
远程将包部署到flink集群
1、新增controller触发接口
/**
* remote runTask
* @author senfel
* @date 2023/8/30 16:57
* @return org.apache.flink.api.common.JobID
*/
@GetMapping("/runTask")
public JobID runTask() {
try {
// 集群信息
Configuration configuration = new Configuration();
configuration.setString(JobManagerOptions.ADDRESS,"10.10.22.91");
configuration.setInteger(JobManagerOptions.PORT,6123);
configuration.setInteger(RestOptions.PORT,8081);
RestClusterClient<StandaloneClusterId> client = new RestClusterClient<>(configuration,StandaloneClusterId.getInstance());
//jar包存放路径,也可以直接调用hdfs中的jar
File jarFile = new File("input/flink-demo.jar");
SavepointRestoreSettings savepointRestoreSettings = SavepointRestoreSettings.none();
//构建提交任务参数
PackagedProgram program = PackagedProgram
.newBuilder()
.setConfiguration(configuration)
.setEntryPointClassName("com.example.flinkdemo.FlinkMysqlToEs")
.setJarFile(jarFile)
.setSavepointRestoreSettings(savepointRestoreSettings).build();
//创建任务
JobGraph jobGraph = PackagedProgramUtils.createJobGraph(program,configuration,1,false);
//提交任务
CompletableFuture<JobID> result = client.submitJob(jobGraph);
return result.get();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
2、启动Springboot项目
3、postman请求
4、查看Fink集群控制台
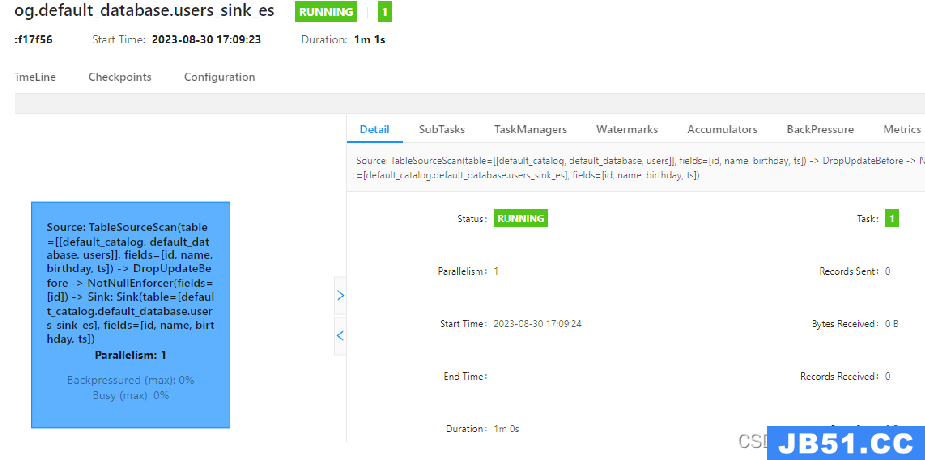
由上图所示已将远程部署完成。
5、测试操作mysql数据库
5 senfel000 2023-08-30 15:02:28 2023-08-30 15:02:36
7 eeeee 2023-08-30 17:12:00 2023-08-30 17:12:04
8 33333 2023-08-30 17:12:08 2023-08-30 17:12:11
6、查询es用户索引
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:766,“hits”:{“total”:{“value”:3,“name”:“senfel000”,“_id”:“7”,“_source”:{“id”:7,“name”:“eeeee”,“birthday”:“2023-08-30 17:12:00”,“ts”:“2023-08-30 17:12:04”}},“_id”:“8”,“_source”:{“id”:8,“name”:“33333”,“birthday”:“2023-08-30 17:12:08”,“ts”:“2023-08-30 17:12:11”}}]}}
如上所以es中新增了两条数据;
经测试远程发布Flink Task完成。
写在最后
大数据Flink CDC同步Mysql数据到ElasticSearch搭建与测试运行较为简单,对于基础的学习测试环境独立集群目前只支持单个任务部署,如果需要多个任务或者运用于生产可以采用Yarn与Job分离模式进行部署。
原文地址:https://blog.csdn.net/weixin_39970883/article/details/132707967
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。