Airflow 使用
上文说到使用 Airflow 进行任务调度大体步骤如下:
-
创建 python 文件,根据实际需要,使用不同的 Operator
-
在 python 文件不同的 Operator 中传入具体参数,定义一系列 task
-
在 python 文件中定义 Task 之间的关系,形成 DAG
-
将 python 文件上传执行,调度 DAG,每个 task 会形成一个 Instance
-
使用命令行或者 WEBUI 进行查看和管理
以上 python 文件就是 Airflow python 脚本,使用代码方式指定 DAG 的结构
一、Airflow 调度 Shell 命令
下面我们以调度执行 shell 命令为例,来讲解 Airflow 使用。
1.首先我们需要创建一个 python 文件,导入需要的类库
# 导入 DAG 对象,后面需要实例化DAG对象from airflow import DAG# 导入BashOperator Operators,我们需要利用这个对象去执行流程from airflow.operators.bash import BashOperator
复制代码
注意:以上代码可以在开发工具中创建,但是需要在使用的 python3.7 环境中导入安装 Airflow 包。
D:\ProgramData\Anaconda3\envs\python37\Scripts>pip install apache-airflow==2.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
复制代码
2.实例化 DAG
from datetime import datetime,timedelta# default_args中定义一些参数,在实例化DAG时可以使用,使用python dic 格式定义default_args = {'owner': 'airflow',# 拥有者名称'start_date': datetime(2022,3,25),# 第一次开始执行的时间,为 UTC 时间'retries': 1,# 失败重试次数'retry_delay': timedelta(minutes=5),# 失败重试间隔}dag = DAG(dag_id = 'myairflow_execute_bash',#DAG id,必须完全由字母、数字、下划线组成default_args = default_args,#外部定义的 dic 格式的参数schedule_interval = timedelta(days=1) # 定义DAG运行的频率,可以配置天、周、小时、分钟、秒、毫秒)
复制代码
注意:
-
实例化 DAG 有三种方式
第一种方式:
with DAG("my_dag_name") as dag:op=XXOperator(task_id="task")
复制代码
第二种方式(以上采用这种方式):
my_dag = DAG("my_dag_name")op = XXOperator(task_id="task",dag=my_dag)
复制代码
第三种方式:
@dag(start_date=days_ago(2))def generate_dag():op = XXOperator(task_id="task")dag = generate_dag()
复制代码
-
baseoperator 基础参数说明:
可以参照:
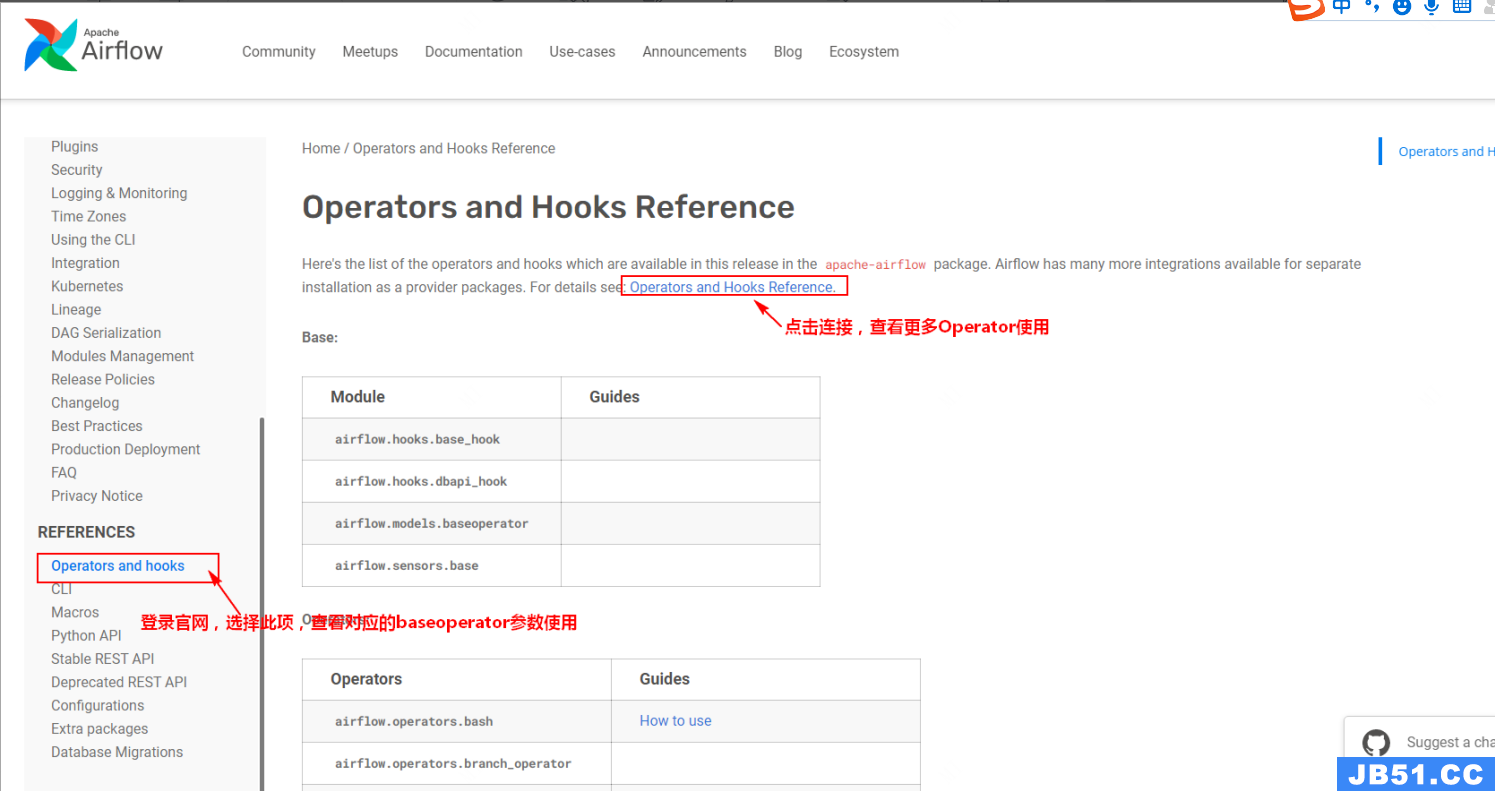
-
DAG 参数说明
可以参照:
http://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/models/dag/index.html
查看 DAG 参数说明,也可以直接在开发工具点击 DAG 进入源码看下对应参数有哪些。
3、定义 Task
当实例化 Operator 时会生成 Task 任务,从一个 Operator 中实例化出来对象的过程被称为一个构造方法,每个构造方法中都有“task_id”充当任务的唯一标识符。
下面我们定义三个 Operator,也就是三个 Task,每个 task_id 不能重复。
# operator 支持多种类型, 这里使用 BashOperatorfirst = BashOperator(task_id='first',bash_command='echo "run first task"',dag=dag)middle = BashOperator(task_id='middle',bash_command='echo "run middle task"',dag=dag)last = BashOperator(task_id='last',bash_command='echo "run last task"',dag=dag,retries=3)
复制代码
注意:
-
每个 operator 中可以传入对应的参数,覆盖 DAG 默认的参数,例如:last task 中“retries”=3 就替代了默认的 1。任务参数的优先规则如下:①.显示传递的参数 ②.default_args 字典中存在的值③.operator 的默认值(如果存在)。
-
BashOperator 使用方式参照:http://airflow.apache.org/docs/apache-airflow/stable/howto/operator/bash.html#howto-operator-bashoperator
4、设置 task 依赖关系
#使用 set_upstream、set_downstream 设置依赖关系,不能出现环形链路,否则报错# middle.set_upstream(first) # middle会在first执行完成之后执行# last.set_upstream(middle) # last 会在 middle执行完成之后执行#也可以使用位移符来设置依赖关系first >> middle >>last # first 首先执行,middle次之,last最后# first >> [middle,last] # first首先执行,middle,last并行执行
复制代码
注意:当执行脚本时,如果在 DAG 中找到一条环形链路(例如:A->B->C-A)会引发异常。更多 DAG task 依赖关系可参照官网:http://airflow.apache.org/docs/apache-airflow/stable/concepts/dags.html#task-dependencies
5、上传 python 配置脚本
到目前为止,python 配置如下:
# 导入 DAG 对象,后面需要实例化DAG对象from airflow import DAG# 导入BashOperator Operators,我们需要利用这个对象去执行流程from airflow.example_dags.example_bash_operator import dagfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,# 拥有者名称'start_date': datetime(2021,9,4),可以配置天、周、小时、分钟、秒、毫秒)# operator 支持多种类型, 这里使用 BashOperatorfirst = BashOperator(task_id='first',retries=3)#使用 set_upstream、set_downstream 设置依赖关系,last并行执行
复制代码
将以上 python 配置文件上传到 AIRFLOWHOME/dags 目录下,默认 AIRFLOW_HOME 为安装节点的“/root/airflow”目录,当前目录下的 dags 目录需要手动创建。
6、重启 Airflow
“ps aux|grep webserver”和“ps aux|grep scheduler”找到对应的 airflow 进程杀掉,重新启动 Airflow。重启之后,可以在 airflow webui 看到对应的 DAG ID ”myairflow_execute_bash”。
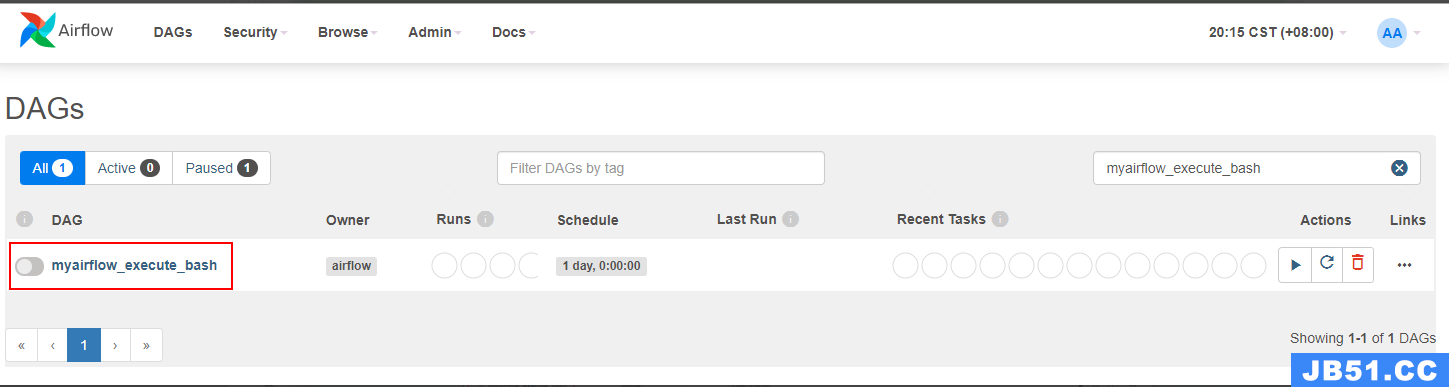
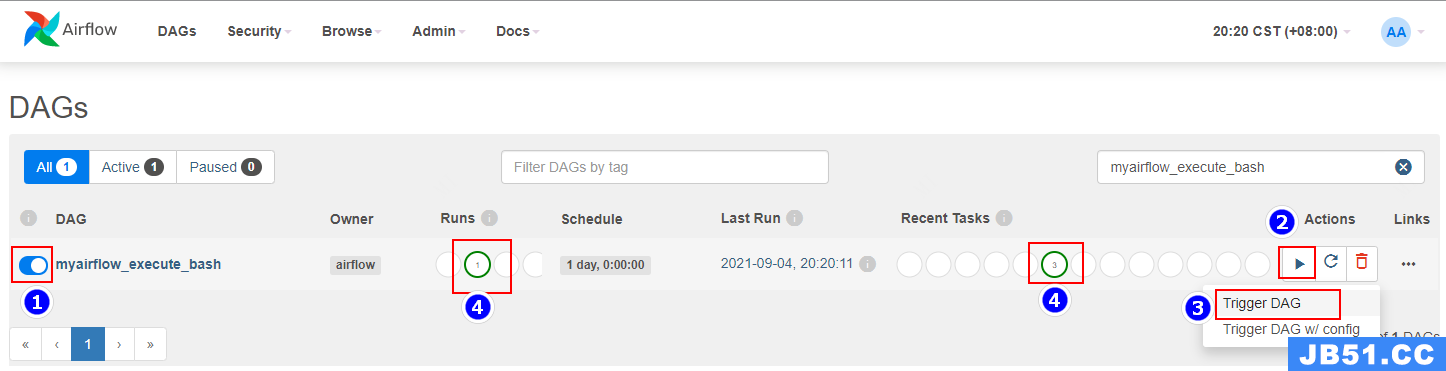
7、执行 airflow
按照如下步骤执行 DAG,首先打开工作流,然后“Trigger DAG”执行,随后可以看到任务执行成功。
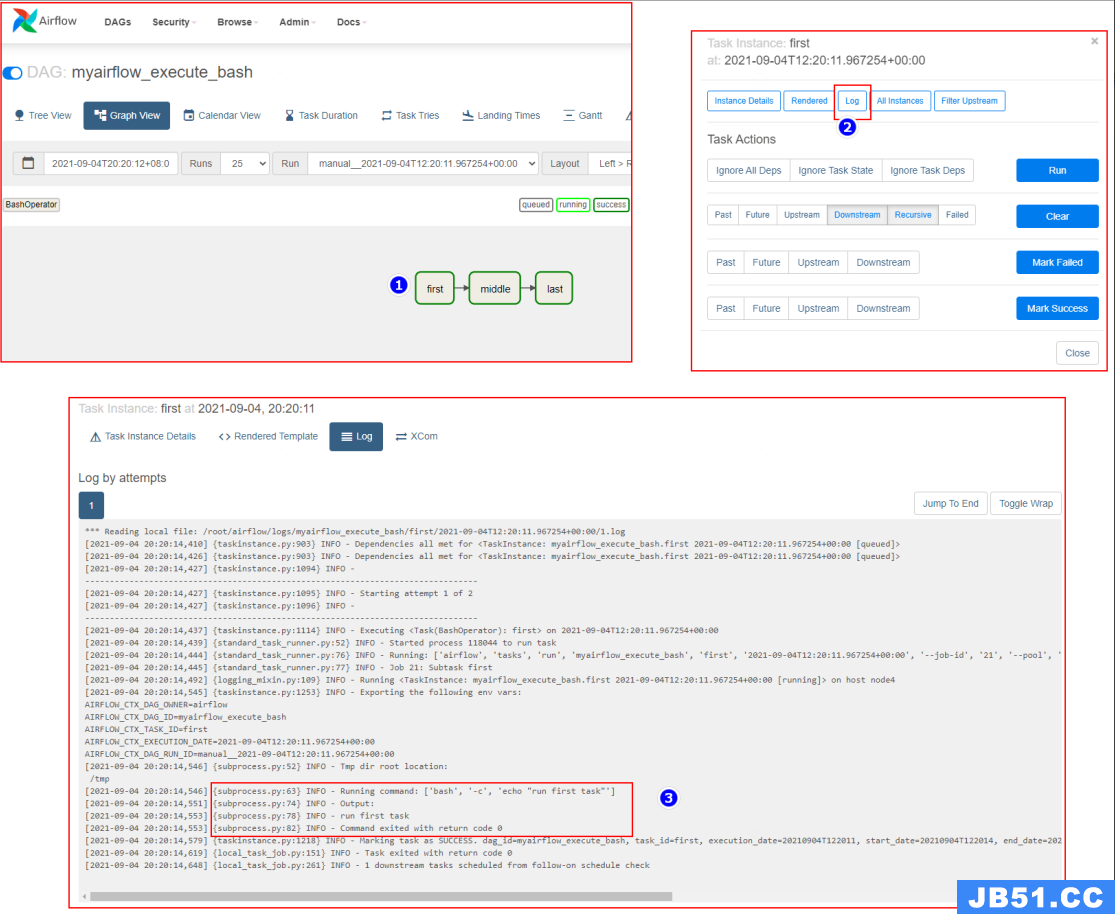
查看 task 执行日志:
二、DAG 调度触发时间
在 Airflow 中,调度程序会根据 DAG 文件中指定的“start_date”和“schedule_interval”来运行 DAG。特别需要注意的是 Airflow 计划程序在计划时间段的末尾触发执行 DAG,而不是在开始时刻触发 DAG,例如:
default_args = {'owner': 'airflow',可以配置天、周、小时、分钟、秒、毫秒)
复制代码
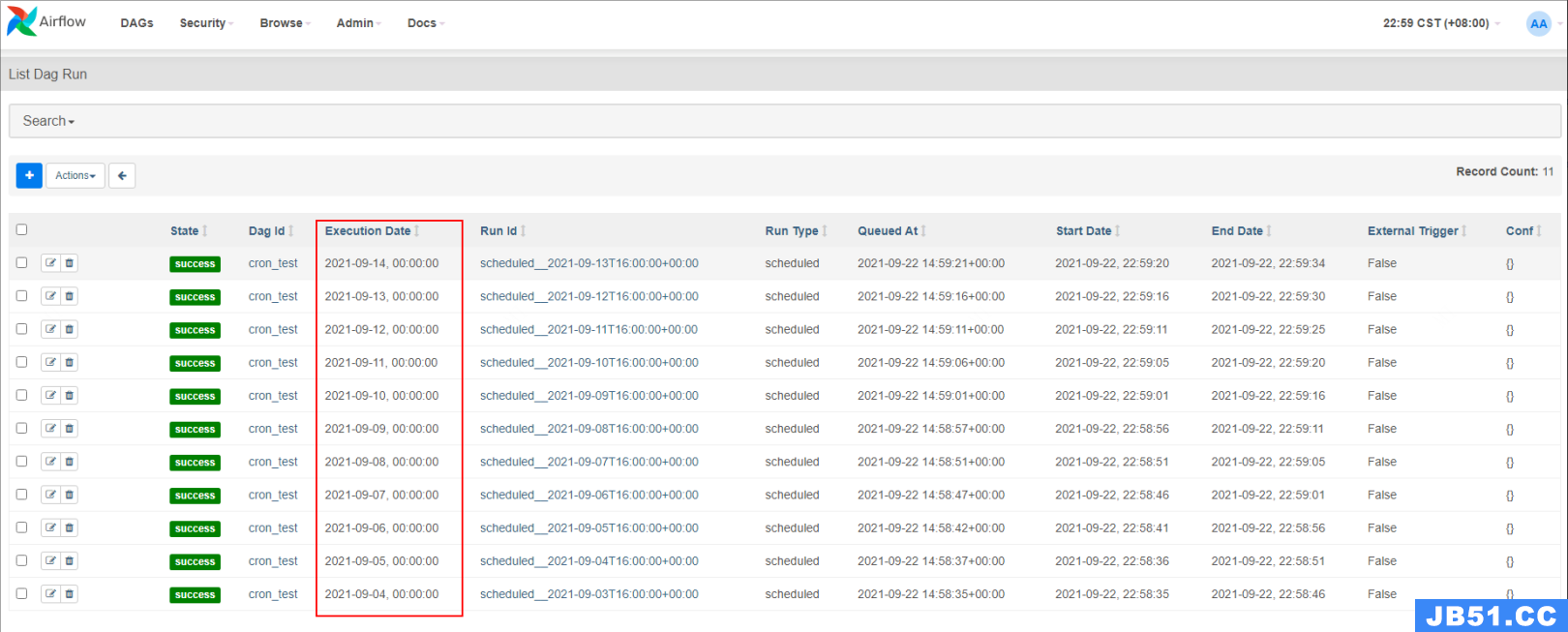
以上配置的 DAG 是从世界标准时间 2022 年 3 月 24 号开始调度,每隔 1 天执行一次,这个 DAG 的具体运行时间如下图:
以上表格中以第一条数据为例解释,Airflow 正常调度是每天 00:00:00 ,假设当天日期为 2022-03-24,正常我们认为只要时间到了 2022-03-24 00:00:00 就会执行,改调度时间所处于的调度周期为 2022-03-24 00:00:00 ~ 2022-03-25 00:00:00 ,在 Airflow 中实际上是在调度周期末端触发执行,也就是说 2022-03-24 00:00:00 自动触发执行时刻为 2022-03-25 00:00:00。
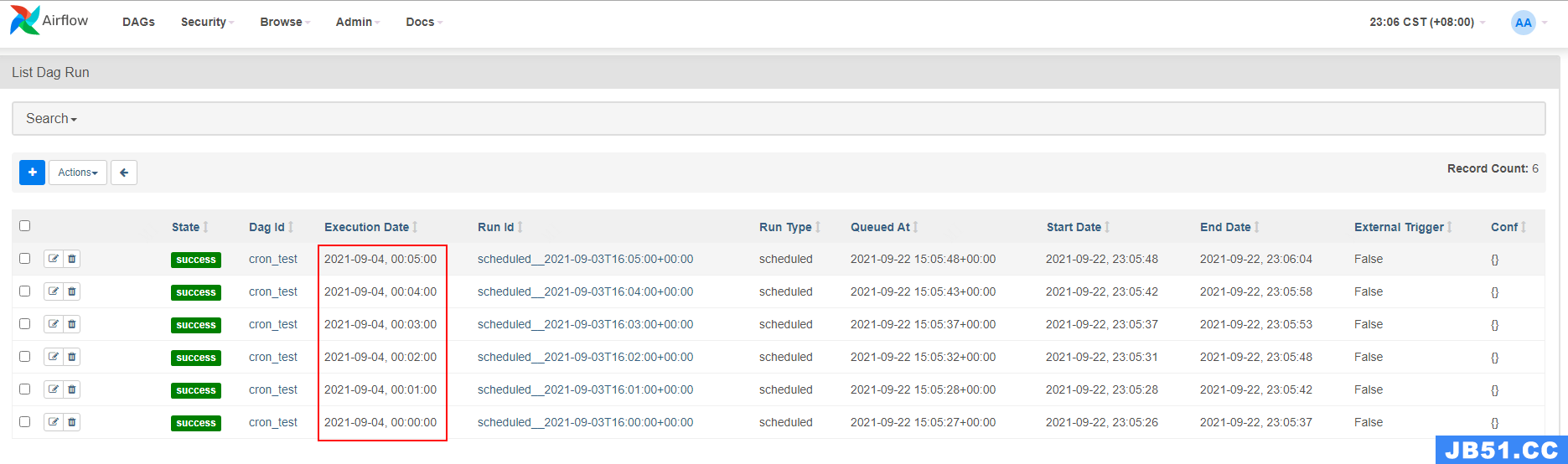
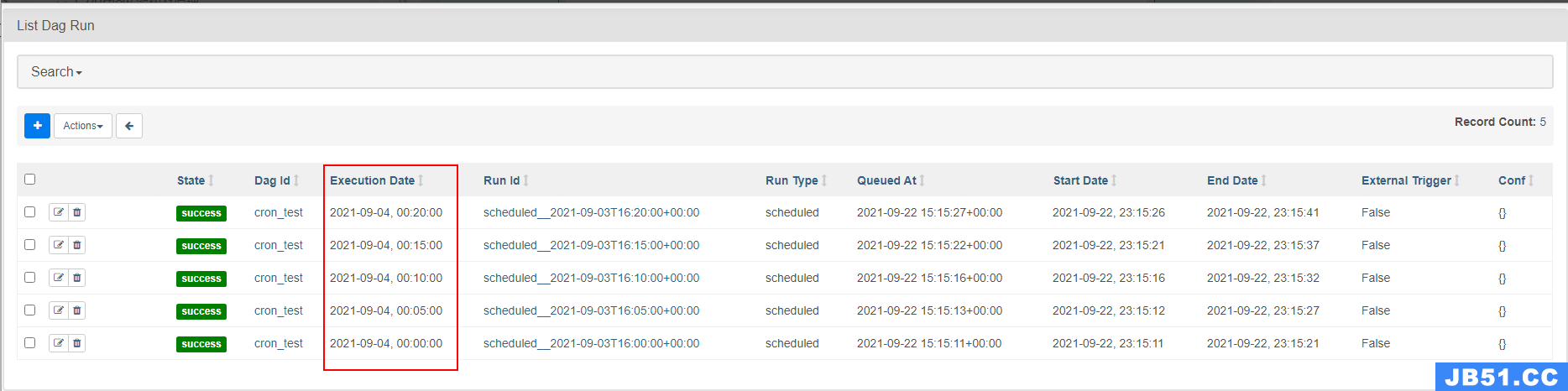
如下图,在 airflow 中,“execution_date”不是实际运行时间,而是其计划周期的开始时间戳。例如:execution_date 是 2021-09-04 00:00:00 的 DAG 自动调度运行的实际时间为 2021-09-05 00:00:00。当然除了自动调度外,我们还可以手动触发执行 DAG 执行,要判断 DAG 运行时计划调度(自动调度)还是手动触发,可以查看“Run Type”。


三、DAG catchup 参数设置
在 Airflow 的工作计划中,一个重要的概念就是 catchup(追赶),在实现 DAG 具体逻辑后,如果将 catchup 设置为 True(默认就为 True),Airflow 将“回填”所有过去的 DAG run,如果将 catchup 设置为 False,Airflow 将从最新的 DAG run 时刻前一时刻开始执行 DAG run,忽略之前所有的记录。
例如:现在某个 DAG 每隔 1 分钟执行一次,调度开始时间为 2001-01-01 ,当前日期为 2021-10-01 15:23:21,如果 catchup 设置为 True,那么 DAG 将从 2001-01-01 00:00:00 开始每分钟都会运行当前 DAG。如果 catchup 设置为 False,那么 DAG 将从 2021-10-01 15:22:20(当前 2021-10-01 15:23:21 前一时刻)开始执行 DAG run。
举例:有 first,second,third 三个 shell 命令任务,按照顺序调度,每隔 1 分钟执行一次,首次执行时间为 2000-01-01。
设置 catchup 为 True(默认),DAG python 配置如下:
from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,timedeltadefault_args = {'owner': 'airflow',# 拥有者名称'start_date': datetime(2001,1,1),# 失败重试间隔}dag = DAG(dag_id = 'catchup_test1 ',#外部定义的 dic 格式的参数schedule_interval = timedelta(minutes=1),# 定义DAG运行的频率,可以配置天、周、小时、分钟、秒、毫秒catchup=True # 执行DAG时,将开始时间到目前所有该执行的任务都执行,默认为True)first = BashOperator(task_id='first',dag=dag)middle = BashOperator(task_id='second',bash_command='echo "run second task"',dag=dag)last = BashOperator(task_id='third',bash_command='echo "run third task"',retries=3)first >> middle >>last
复制代码
上传 python 配置文件到 $AIRFLOW_HOME/dags 下,重启 airflow,DAG 执行调度如下:

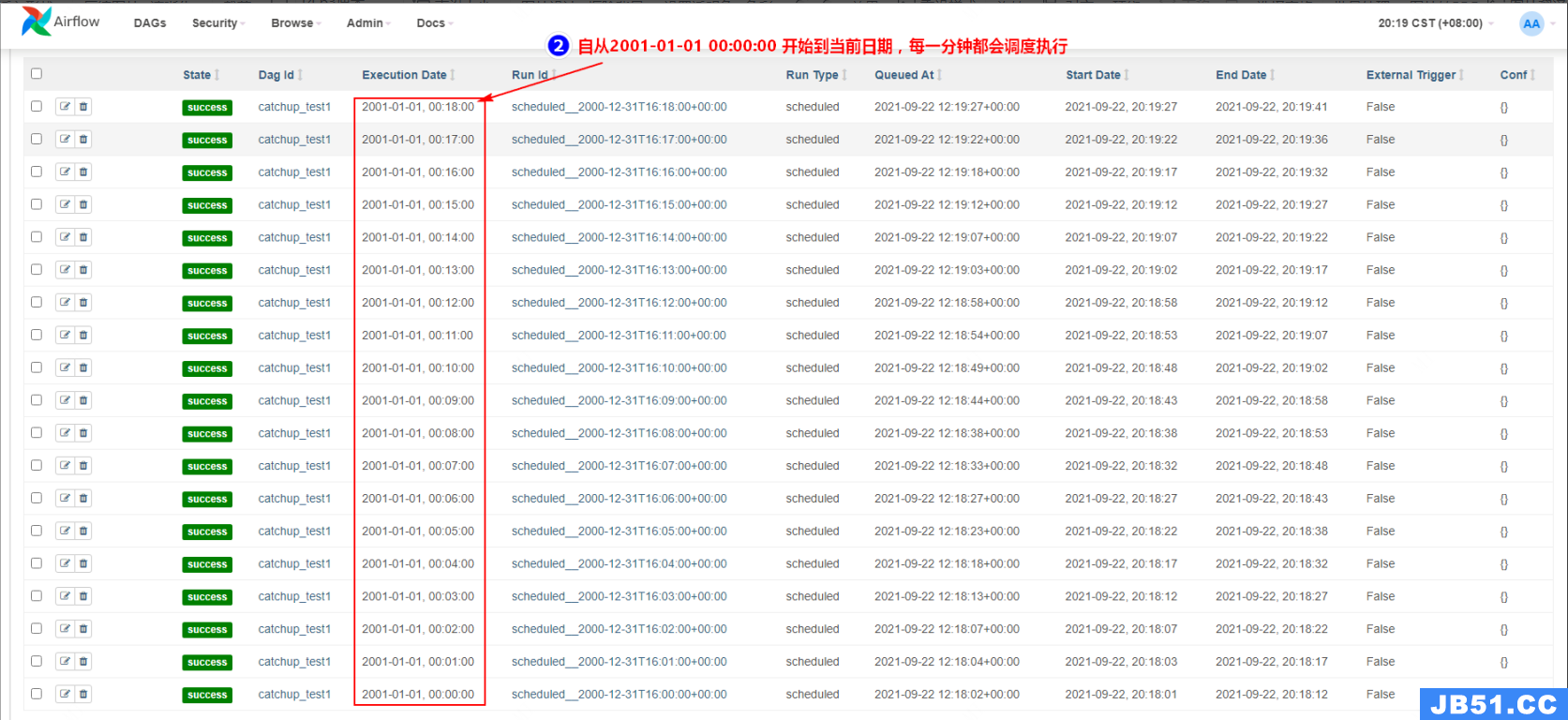
设置 catchup 为 False,DAG python 配置如下:
from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,# 失败重试间隔}dag = DAG(dag_id = 'catchup_test2',可以配置天、周、小时、分钟、秒、毫秒catchup=False # 执行DAG时,将开始时间到目前所有该执行的任务都执行,默认为True)first = BashOperator(task_id='first',DAG 执行调度如下:
有两种方式在 Airflow 中配置 catchup:
全局配置
在 airflow 配置文件 airflow.cfg 的 scheduler 部分下,设置 catchup_by_default=True(默认)或 False,这个设置是全局性的设置。
DAG 文件配置
在 python 代码配置中设置 DAG 对象的参数:dag.catchup=True 或 False。
dag = DAG(dag_id = 'myairflow_execute_bash',default_args = default_args,catchup=False,schedule_interval = timedelta(days=1))复制代码
四、DAG 调度周期设置
每个 DAG 可以有或者没有调度执行周期,如果有调度周期,我们可以在 python 代码 DAG 配置中设置“schedule_interval”参数来指定调度 DAG 周期,可以通过以下三种方式来设置。
预置的 Cron 调度
Airflow 预置了一些 Cron 调度周期,可以参照:
DAG Runs — Airflow Documentation,如下图:
在 python 配置文件中使用如下:
default_args = {'owner': 'airflow',# 失败重试间隔}dag = DAG(dag_id = 'cron_test',#外部定义的 dic 格式的参数schedule_interval = '@daily' # 使用预置的Cron调度,每天0点0分调度复制代码
Cron
这种方式就是写 Linux 系统的 crontab 定时任务命令,可以在https://crontab.guru/网站先生成对应的定时调度命令,其格式如下:
minute hour day month weekminute:表示分钟,可以从0~59之间的任意整数。hour:表示小时,可以是从0到23之间的任意整数。day:表示日期,可以是1到31之间的任何整数。month:表示月份,可以是从1到12之间的任何整数。week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。复制代码
以上各个字段中还可以使用特殊符号代表不同意思:
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。逗号(,):可以用逗号隔开的值指定一个列表范围,例如,”1,2,5,7,8,9”中杠(-):可以用整数之间的中杠表示一个整数范围,例如”2-6”表示”2,4,6”正斜线(/):可以用正斜线指定时间的间隔频率,步长,例如”0-23/2”表示每两小时执行一次。复制代码
在 python 配置文件中使用如下:
default_args = {'owner': 'airflow',#外部定义的 dic 格式的参数schedule_interval = '* * * * *' # 使用Crontab 定时任务命令,每分钟运行一次)复制代码
datetime.timedelta
timedelta 是使用 python timedelta 设置调度周期,可以配置天、周、小时、分钟、秒、毫秒。在 python 配置文件中使用如下:
default_args = {'owner': 'airflow',#外部定义的 dic 格式的参数schedule_interval = timedelta(minutes=5) # 使用python timedelta 设置调度周期,可以配置天、周、小时、分钟、秒、毫秒)复制代码
五、DAG 任务依赖设置
1、DAG 任务依赖设置一
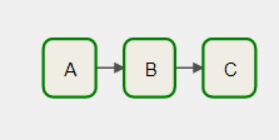
DAG 调度流程图
task 执行依赖
A >> B >>C复制代码
完整代码
'''airflow 任务依赖关系设置一'''from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,timedeltadefault_args = {'owner': 'airflow',22),# 失败重试间隔}dag = DAG(dag_id = 'dag_relation_1',#外部定义的 dic 格式的参数schedule_interval = timedelta(minutes=1) # 定义DAG运行的频率,可以配置天、周、小时、分钟、秒、毫秒)A = BashOperator(task_id='A',bash_command='echo "run A task"',dag=dag)B = BashOperator(task_id='B',bash_command='echo "run B task"',dag=dag)C = BashOperator(task_id='C',bash_command='echo "run C task"',retries=3)A >> B >>C复制代码
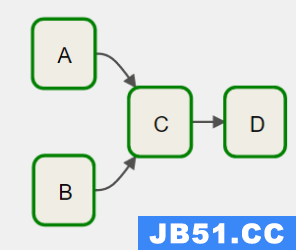
2、DAG 任务依赖设置二
DAG 调度流程图
task 执行依赖
[A,B] >>C >>D复制代码
完整代码
'''airflow 任务依赖关系设置二'''from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,# 失败重试间隔}dag = DAG(dag_id = 'dag_relation_2',retries=3)D = BashOperator(task_id='D',bash_command='echo "run D task"',dag=dag)[A,B] >>C >>D复制代码
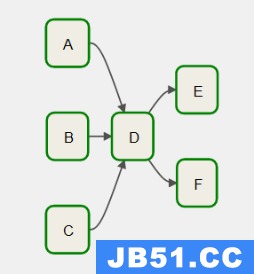
3、DAG 任务依赖设置三
DAG 调度流程图
task 执行依赖
[A,B,C] >>D >>[E,F]
完整代码
'''airflow 任务依赖关系设置三'''from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,# 失败重试间隔}dag = DAG(dag_id = 'dag_relation_3',dag=dag)E = BashOperator(task_id='E',bash_command='echo "run E task"',dag=dag)F = BashOperator(task_id='F',bash_command='echo "run F task"',F]4、DAG 任务依赖设置四
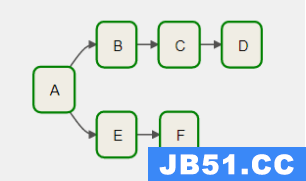
DAG 调度流程图
task 执行依赖
A >>B>>C>>DA >>E>>
完整代码
'''airflow 任务依赖关系设置四'''from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,# 失败重试间隔}dag = DAG(dag_id = 'dag_relation_4',dag=dag)A >>[B,C,D]A >>[E,F]5、DAG 任务依赖设置五
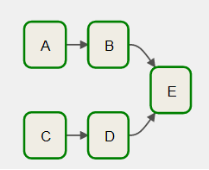
DAG 调度流程图
task 执行依赖
A >>B>>EC >>D>>E
完整代码
'''airflow 任务依赖关系设置五'''from airflow import DAGfrom airflow.operators.bash import BashOperatorfrom datetime import datetime,# 失败重试间隔}dag = DAG(dag_id = 'dag_relation_5',dag=dag)A >>B>>EC >>D>>E原文地址:https://blog.csdn.net/wr_java/article/details/130196172
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。