

在大数据领域,现在普遍认为是后 Hadoop 时代,CDH 的停更和闭源导致传统的 Hadoop 体系组件栈没有一个称手好用的管理工具,越来越多新一代的大数据项目也在层出不穷,同样也需要管理,并且需要适配云原生的能力。不管技术如何演进都面临组件栈管理和运维的难题,鉴于此 DataSophon 作为 Datavane 开源组织的推荐项目重磅开源。
新一代大数据管家DataSophon
DataSophon 是一个国产开源的大数据管理平台,在兼顾传统 Hadoop 组件的同时又支持新一代大数据组件栈,并且支持云原生的能力,致力于快速实现大数据组件部署、监控以及自动化运维管理,旨在帮助用户快速构建稳定、高效、自愈、可弹性伸缩的大数据云原生平台。项目自开源以来,得到了很大关注,社区发展迅速,近日 DataSophon 社区正式发布了 1.2.0 版本,带来了诸多改进和新功能的更新,具备更高的可用性和稳定性,欢迎大家下载使用。
新特性解读
1.2.0 版本,作为 DataSophon 开源之后发布的第一个版本,因此团队非常重视。在该版本全面支持了 Apache Doris,通过 DataSophon 可以便捷的部署、管理、监控 Doris。除此以外本次新增了初始化模块,可以自动完成集群环境初始化工作,避免因环境不一致导致集群安装失败的问题,还优化服务指令执行流程等,具体更新如下:
1. 全面支持 Doris
Apache Doris 是基于 MPP 架构的新一代开源实时数据仓库,以极速易用的特点被人们所熟知,在实时数仓和数据分析领域越发流行,本次 DataSophon 对 Doris 做了全面的支持,现在可在 DataSophon 上轻松的完成 Apache Doris 的集群部署和运维管理。
DataSophon 全面支持Apache Doris
集群部署
在 Doris 集群部署方面,本次的新版本能够自动将 Apche Doris 的 Follower、Observer、Be 等多种角色添加到集群中,全程界面化操作,动动鼠标即可完成,部署进度一目了然,大大省去了手动添加角色的麻烦,轻松实现集群的快速扩展和管理。
集群监控
对于 Apache Doris 集群的各项监控指标,也重点做了支持。您可以的在 DataSophon 中获得 Doris 集群的实时指标的各项信息,包括集群的节点数、详情、连接信息、运行状态和 CPU、JVM、内存、磁盘大小和 IO 的使用情况... 此外,您还可以查看集群的任务运行情况和其他详细信息,以便更好地了解集群的运行状况。
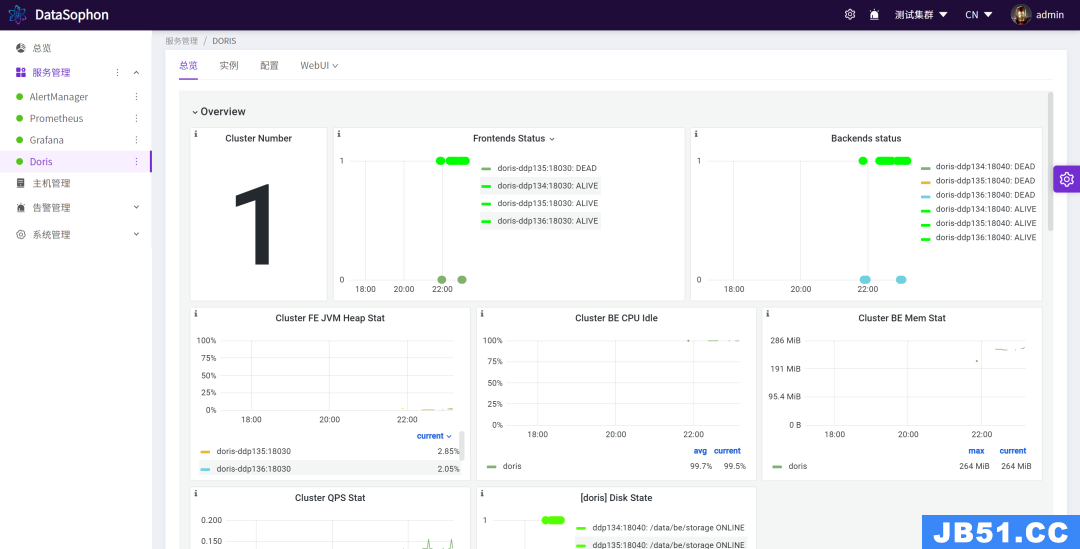
集群运维
在集群运维方面 DataSophon 支持对 Doris 整个集群、FE、BE 节点进行启动、停止、重启等常规操作,同时支持了对 Doris FE、BE 节点进行在线扩/缩容。可以很轻松的设置 Doris 的监控指标和告警,Apache Doris 各项参数也可以很方便的进行单个或批量设置,同时提供进入Doris 的原生WebUI 的入口,DataSophon 中 提供的各种丰富的运维操作可以极大的方便用户去运维管理 Doris 。
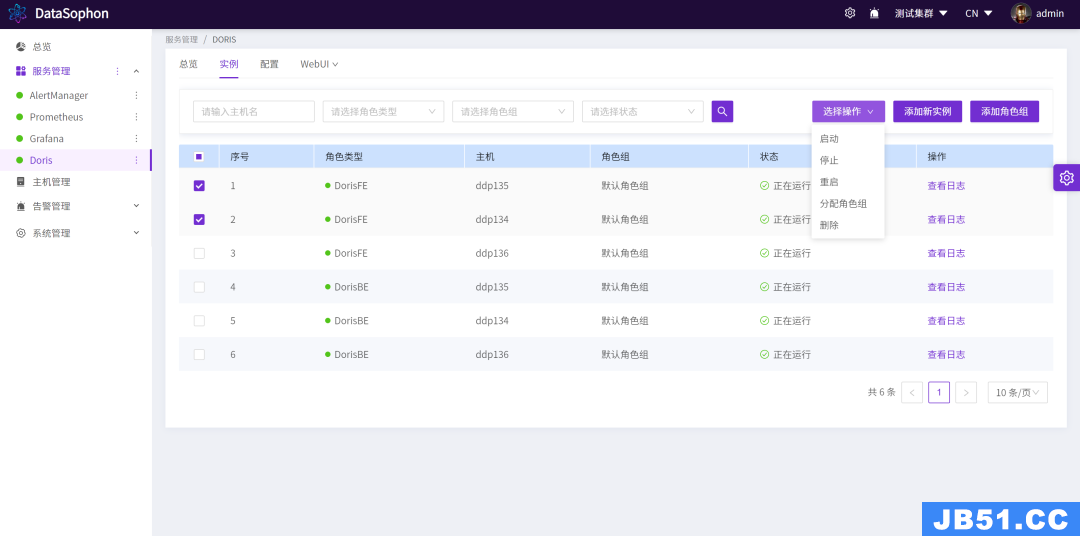
2. 新增多个监控指标
本次新增了多个生产环境中普遍关心的运维指标,旨在满足大数据集群生产环境中的关键需求。这些运维指标的引入,使得用户能够更加有效地管理大数据集群,提高集群性能,降低故障率,从而实现高效运维。主要新增指标如下:
-
HDFS 整个集群的客户端连接数。
-
NameNode 丢失的块数。
-
DataNode RPC 被调用次数。
-
DataNode RPC 队列积压长度。
-
DataNode RPC 平均处理时间。
-
ResouceManager RPC 队列平均处理时间。
-
ResouceManager RPC 队列积压长度。
-
NodeManager Container 启动个数。
-
NodeManager Container 正在运行个数。
-
NodeManager Container 初始化中个数。
-
NodeManager 磁盘损坏个数。
...
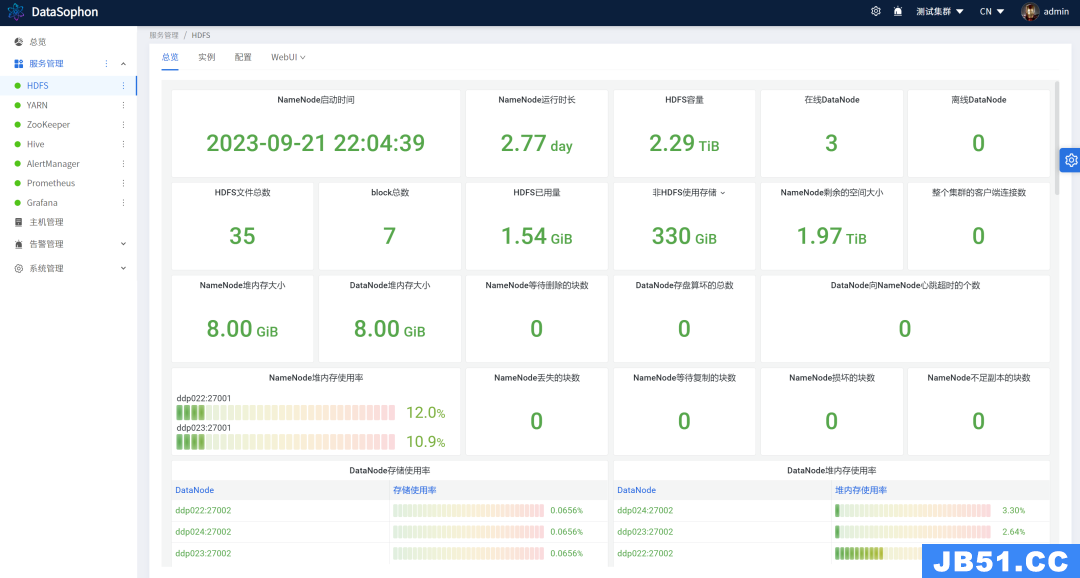
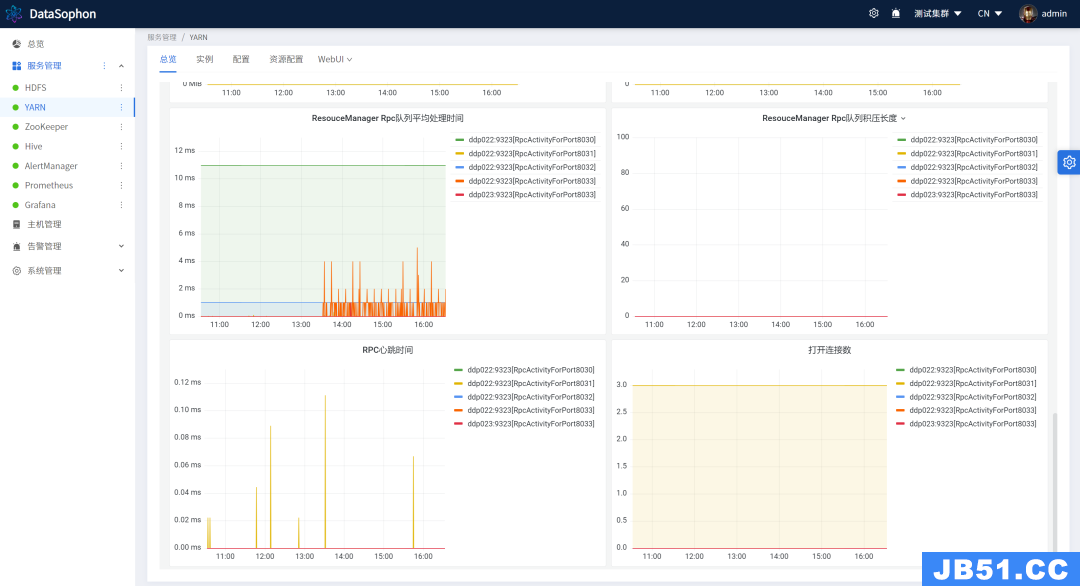
3. 新增初始化模块
在集群部署过程中,都需要进行集群环境初始化,例如配置主机名、配置免密登录、安装离线 yum 源等初始化环境操作。DataSophon 通过 datasophon-init 模块自动初始化安装和配置所需的依赖项,省去手动安装和配置的繁琐步骤,从而大大提高部署效率,减少因集群环境不一致导致集群安装失败的风险。
同时为了方便运维人员操作和使用,系统不仅提供了友好的用户界面还提供了二次开发接口。通过自定义扩展二次开发,可以实现与不同类型的操作系统的兼容,满足不同用户的需求。这样一来,用户可以根据自己的实际情况进行灵活的配置和部署,提高了工作效率和准确性。
4. 其他改进和更新
1、升级 SpringBoot 版本为 2.6.1。
2、新增项目启动时自动创建数据表和初始化数据功能。
3、优化服务指令执行流程,避免出现服务指令进度卡死的情况。
4、优化 Hive 默认使用 Hive on YARN 环境配置。
5、新增集群删除功能。
6、修复不选择安装的服务实例时依然生成服务指令的问题。
7、修复租户管理中租户列表分页不生效的问题。
8、修复服务角色实例警告报警状态无法恢复的问题。
9、修复租户管理租户列表和用户组列表未按集群隔离的问题。
10、修复 Doris 安装部署时,未自动生成 Doris BE 数据目录的问题。
11、修复 HDFS 安装部署时出现找不到 keystore 文件的问题。
12、 修复项目启动时出现的 "because it exists,maybe from xml file" 错误。
新官网上线
本次 DataSophon 上线了新官网,也完善了相关使用文档。在此感谢 Apache StreamPark 社区提供的技术支持,感谢 @songjianet、@haitaodesign 对官网的贡献。
感谢贡献者
DataSophon 开源社区的发展,离不开广大用户群体的积极反馈和宣传布道,更离不开贡献者们的无私贡献,感谢对此版本做出贡献的每一位贡献者。
致谢名单(排名不分先后):
88fantasy、a19920714liou、haitaodesign、WujieRen、thomasg19930417、AllDataDC、zhaoxiaoyi、liu-hai、gtk96、lnnlab、javaht、hzluting、zhzhenqin、liugddx、zq0757、chenss-1、zhu-mingye、zhangdw123、liuxin319、whybeyoung、hitozhu、green241、chyueyi、zhegemingzimeibanquan、songjianet
加入我们
DataSophon 项目自开源以来,得到了很大关注,社区发展迅速, 越来越多的用户开始在生产环境部署使用 DataSophon,开发者也逐渐变多。如果 DataSophon 项目对您有帮助,请在 Gitee 或 Github 搜索 DataSophon 支持一下,点击 star 加关注。
我们明白项目只有真正解决问题, 给用户带来实际的价值才是立命之本,目前我们正在努力构建发展社区,我们坚信道阻且长,行则将至,竭诚欢迎广大的开发者和我们一起建设 DataSophon 项目,共同推动项目的发展。
原文地址:https://blog.csdn.net/Datavane/article/details/133375370 版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。