
# 0 简介
今天学长向大家介绍一个适合作为毕设的项目
毕设分享 python大数据房价预测与可视化系统
项目获取:
https://gitee.com/assistant-a/project-sharing
1 数据爬取
1.需求描述
对于数据挖掘工程师来说,有时候需要抓取地理位置信息,比如统计房子周边基础设施信息,比如医院、公交车站、写字楼、地铁站、商场等,一般的爬虫可以采用python脚本爬取,有很多成型的框架如scrapy,但是想要爬百度地图就必须遵循它的JavaScriptApi,那么肯定需要自己写JavaScript脚本与百度API进行交互,问题是:这种交互下来的数据如何储存(直接写进文本or使用sql数据库?),如何自动化这种交互方式。
因此,本文的目标是用一个rails应用配合js脚本来实现这种自动化抓取和储存,思路是js脚本负责与百度地图Api交互,rails服务器端负责储存抓取的数据,js和rails服务器用ajax方式传递数据.前提是rails服务器里已经有相应的房屋数据,如房屋的街道地址,小区名字等. 接下来需要做的就是为周边信息数据建表以及相应的关联表(因为它们为多对多关系)
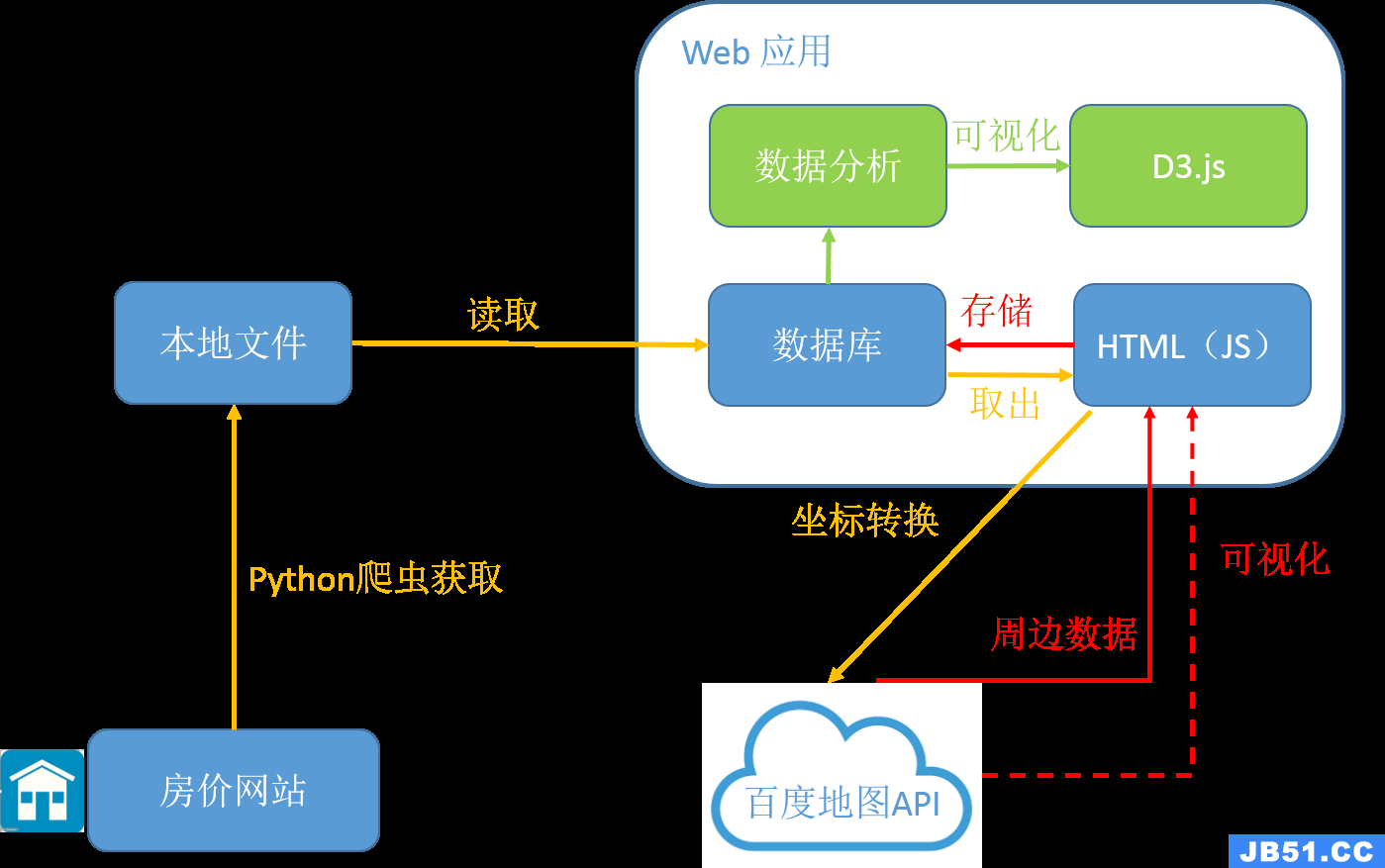
2.流程详解
js代码在用户浏览器中执行,因此爬取的主要部分逻辑都需要写在js脚本里,而rails服务器端需要完成的是获得当前需要抓取的房屋数据以及储存js抓取的数据。下图为对id=1的房屋周边数据抓取的分解过程:

-
- 首先由用户在浏览器中点击开始按钮,激活GetDataFromServer()方法,浏览器向rails服务器发送请求,服务器的return_next()方法返回当前需要抓取的房屋数据(主要是街道或者小区的位置信息)
-
- 通过getPoint方法,浏览器向Baidu API 发送请求查找房屋坐标,若有结果则继续,否则直接递归调用GetDataFromServer()
-
- 使用查询到的房屋坐标搜索周边的信息:对于每一类信息(如地铁,医院等),在查询到结果后立即向服务器发送查询结果以及房屋信息,并标记当前的数据类型(地铁,医院…).服务器在接收到数据后,先判断数据类型,然后根据类别再对房屋的周边信息进行储存.
-
- 如果完成当前房屋所有的周边数据的查询后,再次调用GetDataFromServer()来获得下一个房屋的数据
3. 代码实现
3.1 浏览器端(js)
1.GetDataFromServer: ajax向get_data_url地址以get方法请求json格式的数据,成功拿到数据后先用小区来匹配房屋坐标,如果失败再用街道匹配,若两者都没找到结果,那么此房屋的地理信息为空,则查询下一个房屋;若能找到房屋坐标,调用SearchStart()开始搜索周边数据
function GetDataFromServer() {
$.ajax({
type: "GET",
url: get_data_url,
dataType: 'json',
success: function (house_data) {
// 拿到房屋数据后先显示出来
displayHouseData(house_data);
// 然后先用街道去查坐标
myGeo.getPoint(house_data.street, function (point) {
if (point) {
// 如果查到坐标,开始检索周围信息
SearchStart(point, house_data);
} else {
// 如果
2.SearchStart和SearchNearby: SearchStart为SearchNearby的入口,SearchNearby方法构建了一个BMap.LocalSearch对象的函数变量,调用searchNearby并传入关键词就可以查找house_loc附近的所有的包含关键词的位置信息,search_range能指定查找附近的范围.
BMap.LocalSearch通过onSearchComplete指定了查询完成后的回调函数:这里我们对查询的结果做一个遍历,计算出这个查询结果与房屋的距离,然后将这些信息整合到一个数组里,传给sendData()来发送数据
function SearchStart(point, house_data) {
// 先在地图上标记出来
map.centerAndZoom(point, 16);
map.addOverlay(new BMap.Marker(point));
// 首先查询此房屋的第一个关键词信息(公交车站,idx=0)
setTimeout(function () {
SearchNearby(point, house_data, 0);
}, timeInterval);
}
function SearchNearby(house_loc, keyword_idx) {
var nearby_info = [];
// 清除地图覆盖物
map.clearOverlays();
var local = new BMap.LocalSearch(map, {
renderOptions: {map: map, autoViewport: false},
pageCapacity: 50,
onSearchComplete: function (results) {
DisplayClear();
if (local.getStatus() == BMAP_STATUS_SUCCESS) {
// 百度地图成功返回,将每个周边信息储存到nearby_info里
for (var i = 0; i < results.getCurrentNumPois(); i++) {
var locate = results.getPoi(i);
if (locate != null) {
// 查询结果与房屋的距离
var distance = parseFloat(map.getDistance(locate.point, house_loc)).toFixed(1);
nearby_info.push(locate.title + "/" + locate.point.lng + '/' + locate.point.lat + '/' + distance);
DisplayNearbyData(nearby_info, locate, distance)
}
}
// 获得百度地图查询结果后立即发送给服务器
return sendData(keywords_en[keyword_idx], nearby_info, house_loc, keyword_idx)
} else {
GetDataFromServer();
console.log("No records with baiduAPI:", local.getStatus());
return false;
}
}
});
local.searchNearby(keywords[keyword_idx], search_range);
}
3.sendData: sendData负责发送查询数据nearby_info,周边数据类型由nearby_type指定,房子本身的数据信息由house_data提供而坐标由house_loc给出,idx记录着现在查询的关键词的索引.
sendData使用ajax post方法提交数据,当提交成功后,通过调用SearchNearby并传递下一个关键词的id来检索这个房子其他周边信息;如果当前关键词已经是最后一个,那么调用GetDataFromServer来启动下一轮的查询
function sendData(nearby_type, idx) {
data = "nearby_type=" + nearby_type + "&nearby;_info=" + nearby_info + "&id;=" + house_data.id + "⪫=" + house_loc.lat + "&lng;=" + house_loc.lng;
$.ajax({
type: "POST",
url: post_data_url,
data: data,
dataType: "JSON",
success: function (data) {
if (flag) {
console.log("warning", 'pause');
} else {
// 当查询到最后一个kewords时,请求服务器获得下一个房屋信息
if (idx == keywords.length - 1) {
GetDataFromServer();
} else {
// 查询此房屋的下一个关键词信息
setTimeout(function () {
SearchNearby(house_loc, idx + 1);
}, timeInterval);
}
console.log("success", data);
}
return true;
},
error: function () {
alert('error in post');
return false;
},
timeout: function () {
alert('time out in post');
return false;
}
});
}
2 设计内容
2.1. 数据挖掘 (Done)
1.1 在房价网站上利用爬虫爬下当前所有房子的价格和基本信息(房型、面积、楼层、建造时间等)
1.2 利用百度API对每套房产的周边信息进行挖掘(公交车站、地铁、写字楼、医院、学校、商场等)
1.3 将所有信息储存在关系型数据里,构建数据仓库(Data Warehouse)
2.2. 建立模型对数据进行分析(Under Construction)
2.1 选择模型
2.2 训练
2.3. 数据可视化(Partial done)
3.1 导入百度的可视化工具库(Echarts)
3.2 利用训练的模型对指定房屋价格进行评估和预测,并以科学地方法将结果进行可视化展示
房屋预测功能具体应用场景:
-
对于买家,输入那个房子的坐标,我们通过这个数据集对这个房子的价钱进行预测,以帮助买家合理判断值不值买这个房子(开发中)
-
对于卖家,输入他自己的房子坐标,我们可以对这个房子价钱进行评估,让卖家对自己的卖价有个大致的定位,更好的选择自己的出手价格(开发中)
设计效果截图
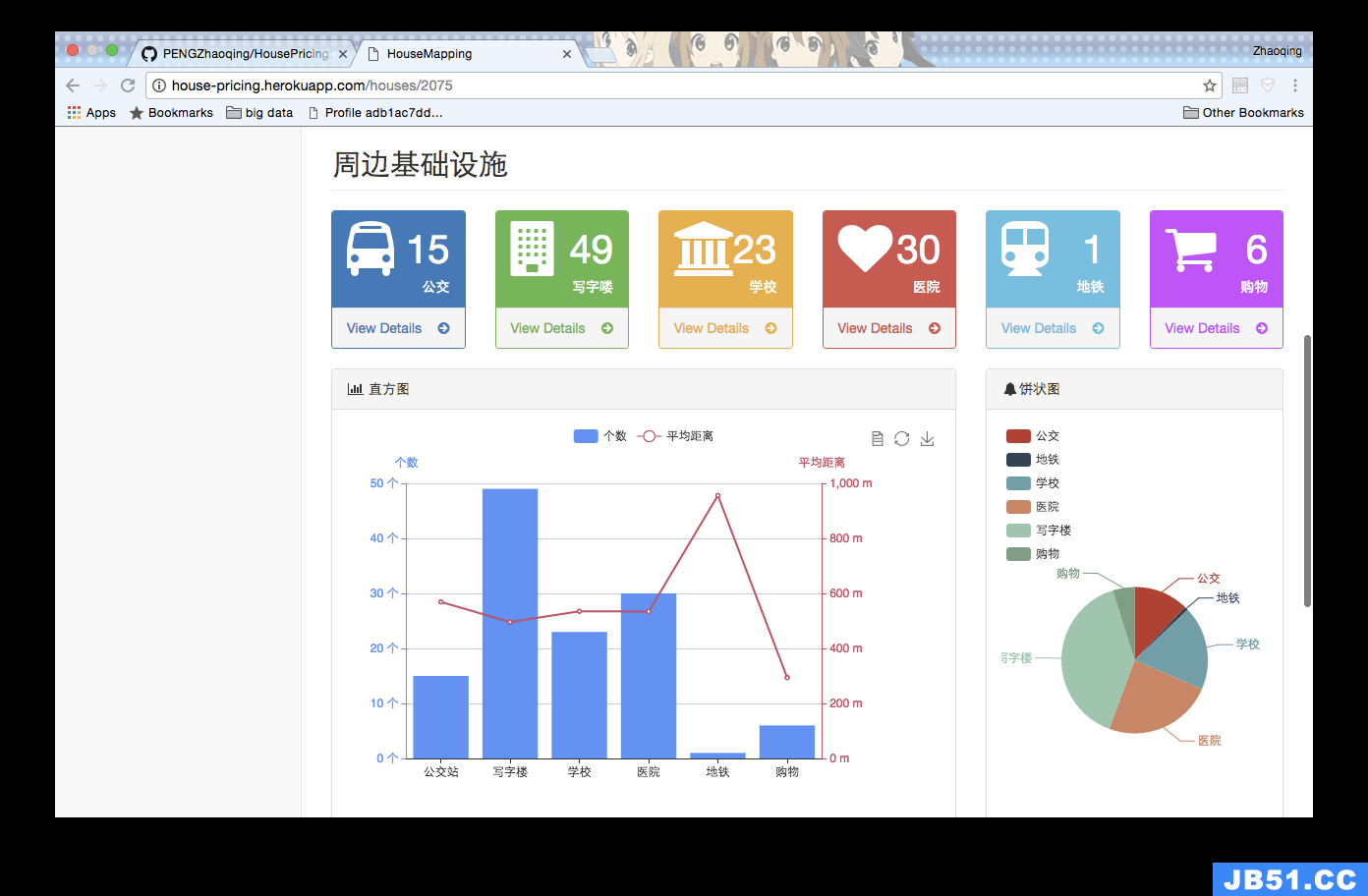
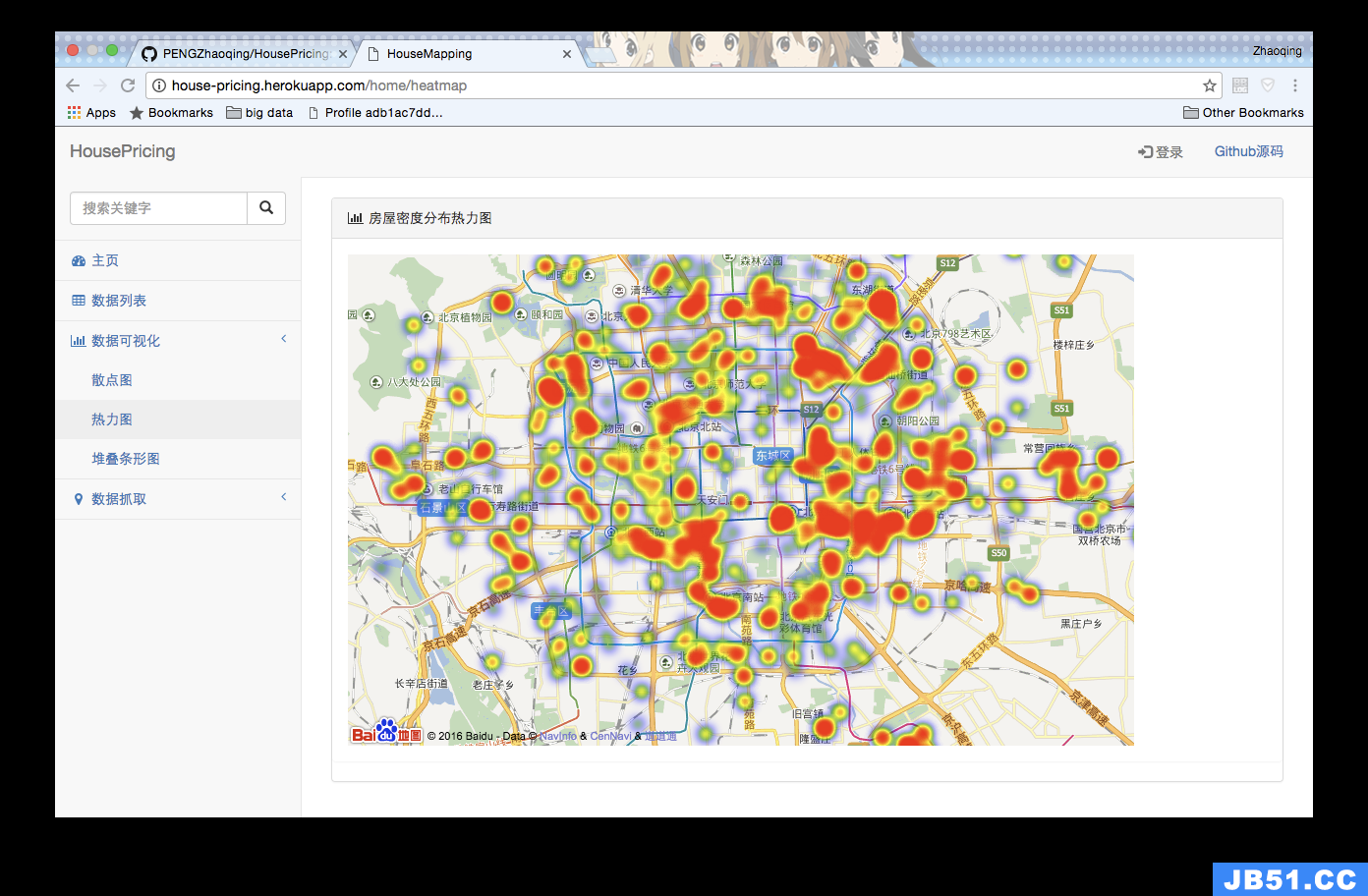


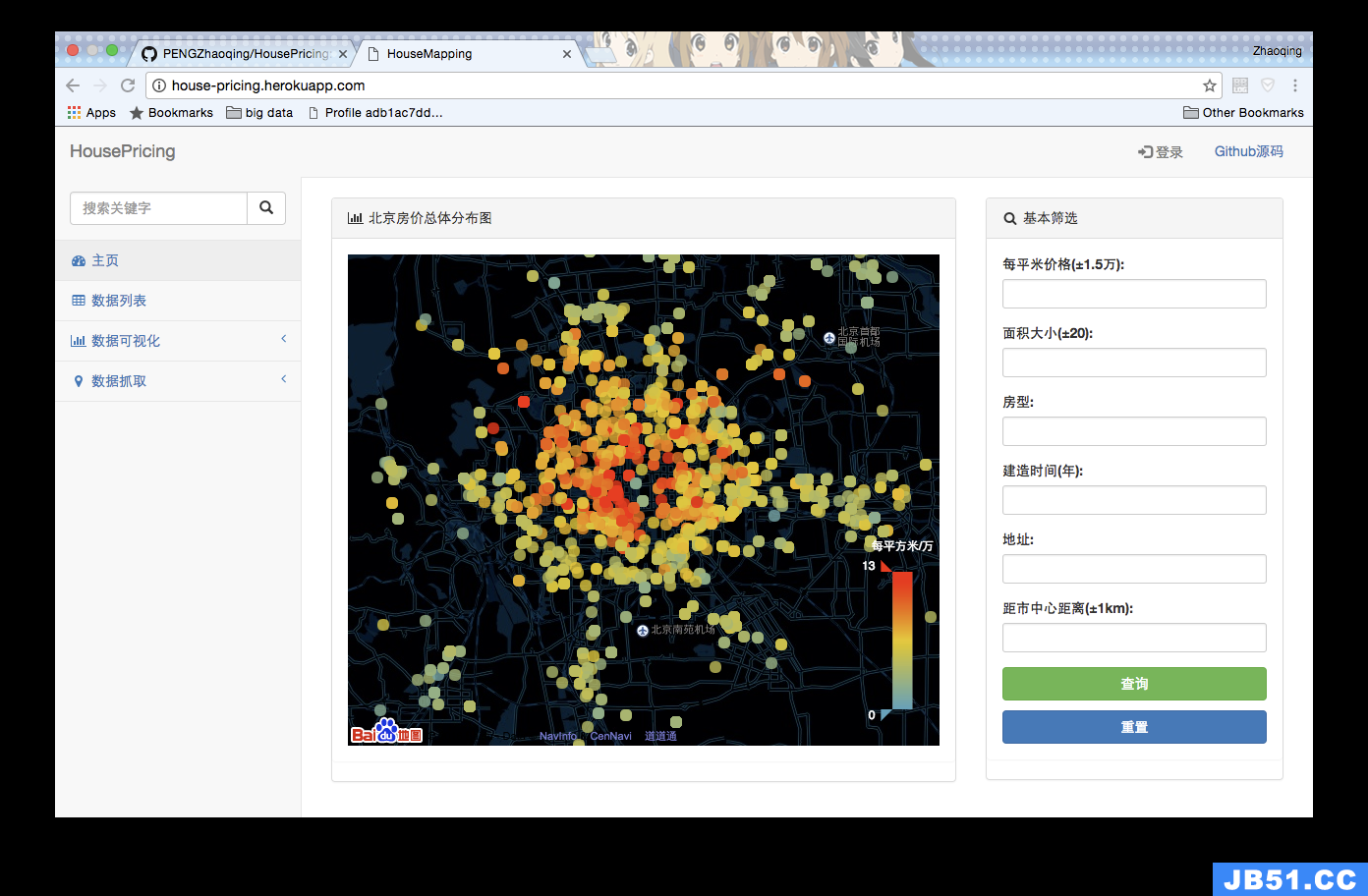
数据说明
现有的一些字段以及字段之间的关联如下:
data_type.png

7.开发
原始数据由[scrapy-hoursepricing]爬取,抓取后的数据将存为json格式,然后由HousePricing进行解析并储存在数据库中
本项目由rails框架开发,请自行安装相关环境,请先fork此项目,然后运行下面:
git clone your_forked_project
cd project_path
bundle install
rake db:migrate
rake db:seed
在浏览器中输入localhost:3000,即可访问主页
8.Docker运行
为了方便运行和部署,这里提供了简单的docker镜像。
开发者首先需要在电脑上安装docker和docker-compose,然后运行下面:
# 编辑数据库配置
cp docker-util/app.env.example docker-util/app.env
vim docker-util/app.env
# 拉取或生成镜像
docker-compose build
# OR
docker pull pengedy/housepricing
# 运行
docker-compose up
即可访问http://localhost:3000
若需要原数据(我目前用的数据),请导入根目录下的mydb.dump到postgresql数据库
最后
项目分享:
https://gitee.com/assistant-a/project-sharing
原文地址:https://blog.csdn.net/noopier/article/details/135935199
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。