
【作者主页】:吴秋霖
【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作!
【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布式爬虫平台感兴趣的朋友可以关注《分布式爬虫平台搭建与开发实战》
还有未来会持续更新的验证码突防、APP逆向、Python领域等一系列文章
1. 写在前面
随笔写一下,最近比较忙。这里我还是拿开源情报或者舆情项目来展开描述,因为现在有自研爬虫系统的企业基本上所涉及的数据源第一个比较多,第二个则是数据更新及时性高。爬虫业务单一少的基本也到不上平台级,爬虫写完基本挂到容器里面就完了,有的甚至可能容器都用不上!
舆情项目中数据采集是一个极其关键的部分!核心技术则是爬虫技术的构建,这里说的不是指简单的一些爬虫脚本程序,数据源肯定是很多的,每天几乎覆盖的源或多或少都在变化,数据源状态或者页面结构变化
这里我画了一个基础且常见的爬虫平台架构:
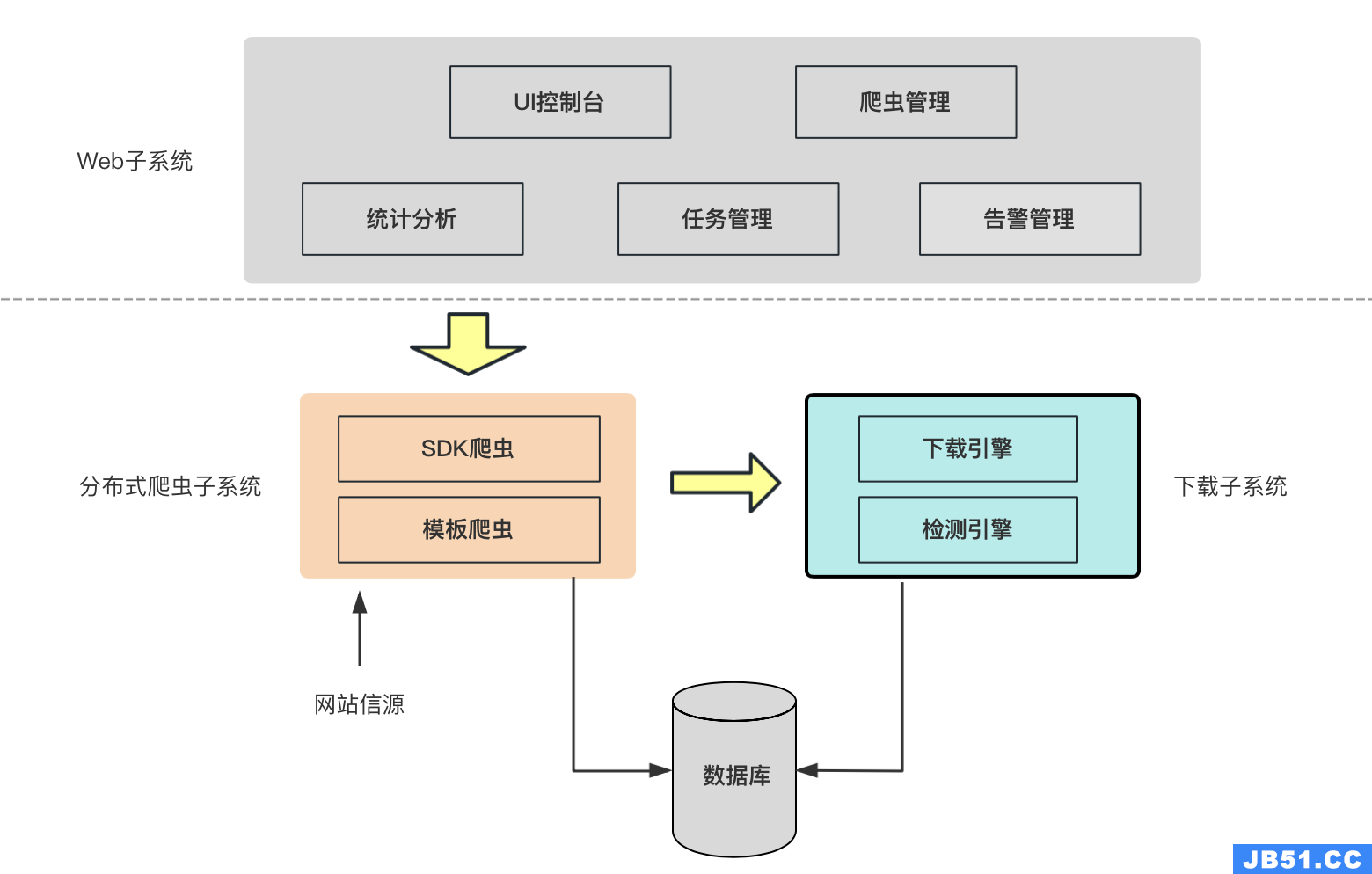
2. 数据获取挑战
数据需求范围广,难以全面采集!很多产品需要数据的赋能。对数据的需求往往需要采集全网或特定领域的数据,在有限的时间和成本内,批量深度爬取,尤其目前国内的一些渠道数据获取采集的难度越来越大
数据获取时间长,难以保证时效性!如果在短时间内需要的数据量庞大,并且及时性高!导致爬取到数据的时间过长,难以将数据实时的流转并供给业务分析应用。数据产生的时间过长,导致数据的时效价值被严重降低
数据源防护技术加大采集数据的难度!越来越多的网站具有大数据防护技术,并不断更新增强反爬策略,以及各国加大对隐私信息的保护,这些措施都在不断加大数据采集的难度
3. 基础架构
既然是分布式系统,那么爬虫肯定是比较多的,这些爬虫的任务必须分配到多台机器上执行。所以这些爬虫程序如何部署?部署在哪?当然是容器里面,为了更加便捷的部署、拓展与管理、Kubernetes+Docker将会成为分布式爬虫采集系统中基础架构承载底座!
4. 爬取管理
-
爬虫状态:爬虫分布式在很多台服务器上,不知道在哪个服务器上的哪个爬虫程序出了问题是很痛苦的事情,甚至抓取数据量猛增导致服务器挂掉都不知道。所以,需要能对服务器监控,对服务器上每一个爬虫程序进行监控。监控每个爬虫运行是否正常,监控每个运行爬虫的服务器是否正常
-
采集状态:抓取的站点时常发生变化,我们就需要知道每个目标采集的站点抓取的数据是否都正常的采集下来了,通过给每个爬虫编上采集任务编号,展示在web界面上,就可以直观的看见数据采集下来的效果。通过邮件告警和每天发送邮件统计数据,可以实时对采集状态进行监控
-
任务调度:任务调度模块实现数据爬取任务的分布式任务调度,包括添加、执行、监控、停止、删除爬虫的这些功能。系统能够自动根据任务优先级和资源状态进行任务分配和任务调整,在数据爬取任务发,可以看看我之前写的关于Scrapyd爬虫部署的文章:Scrapyd核心源码剖析及爬虫项目实战部署
-
资源管理:资源管理是对某些站点的账号资源、IP 资源和采集节点等与采集相关的资源信息的集中管理
-
状态监测:状态监测模块提供对网页页面改版、网页反爬策略、节点运行状态和数据产量等进行告警的功能,并以通知的方式实时推送到web前端,可以看看之前我写的这篇告警设计文章:【爬虫系统设计系列】好的爬虫系统一定要这样去设计告警功能)
5. 数据采集
-
模板配置:例如新闻这类的网站源,页面的结构基本都是一样的,列表到详情页。可以采用模板配置的方案交给XPATH工程师,模板爬虫功能设计可以参考我的这篇文章【爬虫系统设计系列】模板爬虫的动态配置策略设计与实现
-
可视化采集:爬取难度低的这类网站可以通过可视化配置的方式,所见即所得通过点击页面生成爬虫工程的方式。感兴趣的可以去看看开源可视化爬虫项目:可视化爬虫-Portia
-
人工配置:这类网站一般难度较高、需要定制化开发、更新频率高!
-
智能解析:像新闻、小说、应用市场这些页面特征相似的网站可以采用通用抽取算法!

6. 增量与去重设计
这一部分可以说是非常重要也是经常接触的,除了一次性爬虫外几乎都要添加去重的功能,有的则需要定期或实时增量爬取
-
增量设计:可以根据时间,记录最新更新的时间,这个是比较常见的,或者说咱们对页面的内容计算哈希值,将哈希值与上次爬取时存储的哈希值进行比较,不同则更新!
-
去重设计:可以根据URL、数据内容计算指纹!可以使用Bloom或者是Set具体根据实际的业务场景跟数据体量去做一个技术选型
好了,到这里又到了跟大家说再见的时候了。创作不易,帮忙点个赞再走吧。你的支持是我创作的动力,希望能带给大家更多优质的文章
原文地址:https://blog.csdn.net/qiulin_wu/article/details/134439821
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。