
文章目录
一、概述
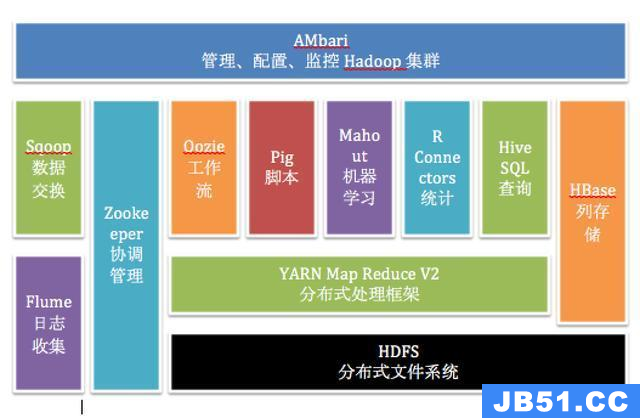
Apache Ambari 是 Hortonworks 贡献给Apache开源社区的顶级项目,它是一个基于web的工具,用于安装、配置、管理和监视 Hadoop 集群。 Ambari 目前已支持大多数 Hadoop 组件,包括 HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop 和 Hcatalog 等。
Apache Ambari 支持 HDFS、MapReduce、Hive、Pig、Hbase、Zookeper、Sqoop 和 Hcatalog 等的集中管理。也是 5 个顶级 hadoop 管理工具之一。
Ambari 主要取得了以下成绩:
-
通过一步一步的安装向导简化了集群供应。
-
预先配置好关键的运维指标(metrics),可以直接查看 Hadoop Core(HDFS 和 MapReduce)及相关项目(如 HBase、Hive 和 HCatalog)是否健康。
-
支持作业与任务执行的可视化与分析,能够更好地查看依赖和性能。
-
通过一个完整的 RESTful API 把监控信息暴露出来,集成了现有的运维工具。
-
用户界面非常直观,用户可以轻松有效地查看信息并控制集群。
Ambari 使用 Ganglia 收集度量指标,用 Nagios 支持系统报警,当需要引起管理员的关注时(比如,节点停机或磁盘剩余空间不足等问题),系统将向其发送邮件。
此外,Ambari 能够安装安全的(基于 Kerberos)Hadoop 集群,以此实现了对 Hadoop 安全的支持,提供了基于角色的用户认证、授权和审计功能,并为用户管理集成了 LDAP 和 Active Directory。
- GitHub地址:https://github.com/apache/ambari
- 官方地址:https://ambari.apache.org/
- Ambari WIKI:https://cwiki.apache.org/confluence/display/AMBARI/Ambari
- Hortonworks社区:https://community.hortonworks.com/index.html
- https://docs.hortonworks.com/HDPDocuments/Ambari-2.6.1.5/bk_ambari-operations/content/ch_Overview_hdp-ambari-user-guide.html
【温馨提示】
从2021年1月开始,
ambari开始收费了,如果想使用ambari,要么基于源码自己编译
https://ambari.apache.org/,
要么给钱下载
https://www.cloudera.com/products/open-source/apache-hadoop/apache-ambari.html
二、 Ambari 与 HDP 关系
Ambari和HDP(Hortonworks Data Platform)是用于管理和运维Hadoop集群的两个关键组件。
-
Ambari是一个开源的集群管理工具,提供了一个直观的Web界面,用于简化Hadoop集群的配置、管理和监控。通过Ambari,管理员可以轻松地进行集群部署、服务配置、扩展和监控。它还提供了一些高级功能,如自动服务恢复、告警管理和权限控制等。 -
HDP是Hortonworks提供的一个完整的数据平台,基于开源的Apache Hadoop生态系统构建而成。它包含了一系列的核心组件,如HDFS(Hadoop分布式文件系统)、YARN(Yet Another Resource Negotiator)、MapReduce、Hive、HBase、Spark、Pig等。HDP通过集成这些组件,为用户提供了一个稳定、可靠和易于管理的Hadoop平台。 -
Ambari和HDP之间的关系是,Ambari作为一个集群管理工具,可以用于管理和运维HDP所构建的Hadoop集群。通过Ambari,管理员可以在HDP集群上进行各种操作,如添加/删除节点、配置服务参数、监控集群健康状态等。同时,Ambari还提供了一些附加功能,如服务自动发现、日志聚合和可视化等,以提高Hadoop集群的可管理性和可视化性。
总结起来,Ambari是用于管理和运维Hadoop集群的工具,而HDP是一个完整的数据平台,基于Hadoop生态系统构建而成。Ambari可以用于管理和操作HDP集群,提供了一种简化和集中化的方式来管理Hadoop集群中的服务和组件。【温馨提示】CDH 和 HDP 都已经开始收费了。
简单来讲就是 Ambari 好比 CDH 中的Cloudera manager,HDP 就如 CDH 一样。如想了解CDH的小伙伴可以观看我这篇文章:大数据Hadoop之——Cloudera Hadoop(CM 6.3.1+CDH 6.3.2环境部署)
三、Ambari 与 Cloudera manager 的对比
Ambari 和 Cloudera Manager 都是用于管理和监控Hadoop集群的工具,它们在功能和特点上有一些区别。以下是Ambari和Cloudera Manager之间的一些对比:
1)开源性
-
Ambari:Ambari是一个开源项目,由Apache软件基金会进行开发和维护。 -
Cloudera Manager:Cloudera Manager是Cloudera公司的产品,它是基于开源Hadoop分发版本构建的,但Cloudera Manager本身不是开源的。
2)支持的发行版
-
Ambari:Ambari可以与各种Hadoop发行版集成,包括Apache Hadoop、Hortonworks Data Platform(HDP)和IBM Spectrum Scale。 -
Cloudera Manager:Cloudera Manager主要用于管理Cloudera发行版(Cloudera Distribution including Apache Hadoop,CDH)。
3)用户界面
-
Ambari:Ambari提供了一个直观的Web界面,用于配置、管理和监控Hadoop集群。它的界面相对简洁,易于使用。 -
Cloudera Manager:Cloudera Manager也提供了一个Web界面,但它更加详细和功能丰富。它提供了更多的集群管理和调优功能,适用于大型和复杂的集群环境。
4)功能和扩展性
- Ambari:Ambari提供了基本的集群管理功能,例如组件安装、配置管理、监控和警报。它还支持Ambari Views,允许用户通过自定义视图扩展和定制功能。
-
Cloudera Manager:Cloudera Manager提供了广泛的集群管理和运维功能,包括自动化安装、配置管理、故障排除、性能优化等。它还支持一些高级特性,例如数据备份和恢复、Kerberos集成、高可用性配置等。
5)社区支持和生态系统
-
Ambari:Ambari是Apache软件基金会的项目,拥有庞大的开源社区支持和活跃的开发者社区。它与其他Apache生态系统项目有良好的集成。 -
Cloudera Manager:Cloudera Manager作为Cloudera公司的产品,提供了商业支持和服务,并与Cloudera的其他产品和解决方案集成。
综上所述,Ambari和Cloudera Manager都是功能强大的集群管理工具,但它们在开源性、支持的发行版、用户界面、功能和生态系统等方面存在一些区别。选择适合的工具取决于你的具体需求、集群规模和技术栈。
四、Apache Ambari 术语
-
Service(服务):Service是指 Hadoop 堆栈中的服务。 HDFS、HBase 和 Zookeeper等是服务的⽰例。⼀个服务可能有多个组件(例如,HDFS 有 NameNode、Secondary NameNode、DataNode 等)。服务也可以只是⼀个客⼾端(例如,Pig没有任何守护程序服务,但只有⼀个客⼾端库) -
Component(组件):Service由⼀个或多个Component组成。例如,HDFS 有 3 个组件:NameNode、DataNode 和 Secondary NameNode。组件可能是可选的。⼀个组件可以跨越多个节点(例如,多个节点上的 DataNode 实例)。 -
Node/Host(节点):Node/Host是指集群中的⼀台机器。 -
Node-Component(节点组件):Node-Component是指特定节点上的组件实例。例如,特定节点上的特定 DataNode 实例是节点组件。 -
Operation(操作):Operation是指在集群上执行的⼀组更改或操作,以满⾜⽤⼾请求或在集群中实现所需的状态更改。例如,启动服务是⼀项操作,运行冒烟测试是⼀项操作。如果⽤⼾请求向集群添加新服务并且还包括运行冒烟测试,那么满⾜⽤⼾请求的整个操作集将构成⼀个操作。 -
Task(任务):Task是发送到节点执行的⼯作单元。Task是节点作为Action的⼀部分的⼯作。例如,“Action”可以包括在节点 Node1上安装DataNode,在节点 Node2 上安装DataNode和SNameNode。在这种情况下,Node1 的“任务”将是安装⼀个DataNode,⽽ Node2的“任务”将是安装⼀个DataNode和⼀个SNameNode。 -
Stage(阶段):Stage是指完成⼀项操作所需的⼀组任务,并且相互独⽴;同⼀阶段的所有任务都可以跨不同节点并行运行。 -
Action(动作):Action由⼀台机器或⼀组机器上的⼀个或多个任务组成。每个动作都有动作 id 跟踪,并且节点⾄少在动作的粒度上报告状态。⼀个动作可以被认为是⼀个正在执行的阶段。 -
Stage Plan(阶段计划):⼀个操作通常由不同机器上的多个任务组成,它们通常具有依赖关系,要求它们以特定顺序运行。有些任务需要先完成,然后才能安排其他任务。因此,⼀个操作所需的任务可以划分为多个阶段,每个阶段必须在下⼀个阶段之前完成,但同⼀阶段的所有任务可以跨不同节点并行调度。 -
Manifest(清单):Manifest是指发送到节点执行的任务的定义。清单必须完全定义任务并且必须是可序列化的。清单也可以保存在磁盘上以进行恢复或记录。 -
Role(⻆⾊):Role映射到组件(例如,NameNode、DataNode)或操作阶段计划(例如,HDFS rebalancing、HBase smoke test、其他管理命令等)
五、Apache Ambari 核心组件介绍
Apache Ambari 是一个开源的集群管理工具,用于简化、管理和监控Hadoop生态系统中的大数据集群。它提供了一个直观的Web界面,使用户可以轻松地配置、部署和管理Hadoop集群的核心组件。下面是Ambari的一些核心组件的介绍:
-
Ambari Server:Ambari Server是Ambari的主要组件,负责整个集群的管理和控制。它提供了一个Web界面,允许管理员配置和监控集群的各个方面。Ambari Server负责收集和显示有关集群的信息,以及在需要时执行操作,例如安装、启动、停止和升级组件。 -
Ambari Agent:Ambari Agent是在集群中每个主机上运行的代理程序。它负责与Ambari Server通信,并执行Ambari Server下发的命令。Ambari Agent在各个主机上安装和管理组件,收集主机的指标数据,并将其发送给Ambari Server进行监控和分析。 -
Ambari Web:Ambari Web提供了一个用户友好的Web界面,允许管理员和操作员直接与Ambari交互。通过Ambari Web,用户可以轻松地配置和管理集群的各个方面,包括添加/删除主机、安装/升级组件、配置服务和管理用户权限等。 -
Ambari Database:Ambari Database是Ambari Server使用的后端数据库,用于存储集群的元数据和配置信息。常见的数据库选项包括MySQL、PostgreSQL和Oracle。Ambari Database存储有关集群拓扑、组件配置、主机信息和用户权限等的数据。 -
Ambari Metrics:Ambari Metrics组件负责收集和存储集群的指标数据。它使用开源的时间序列数据库,例如Apache HBase或Apache Phoenix,将各个组件和主机的指标数据持久化存储起来。Ambari Metrics还提供了一个Web界面,用于查看和分析集群的指标数据。 -
Ambari Views:Ambari Views是Ambari的插件机制,允许用户通过自定义视图扩展Ambari的功能。它提供了一种可扩展的方式,允许用户根据自己的需求添加和集成自定义的Web界面或应用程序。
这些是Ambari的一些核心组件,它们共同协作,使用户能够方便地管理和监控Hadoop集群的各个方面。通过Ambari,用户可以简化集群管理任务,并提供可视化的界面来监控集群的运行状况和性能。
六、Apache Ambari 架构
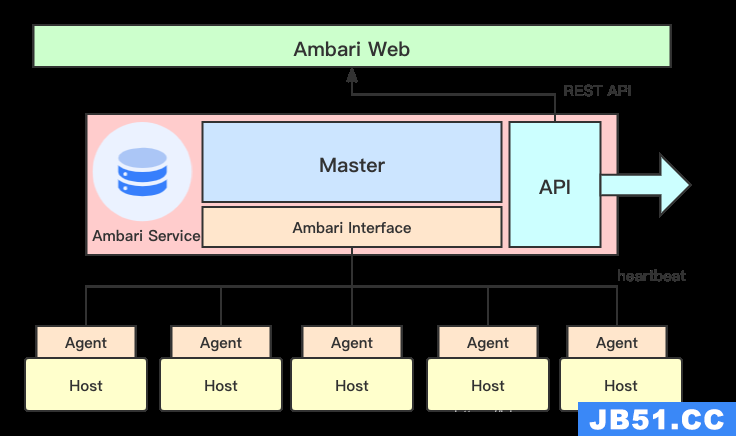
Ambari框架采用的是Server/Client的模式,主要由两部分组成:ambari-agent 和 ambari-server 。ambari依赖其它已经成熟的工具,例如其ambari-server 就依赖 python ,而 ambari-agent 还同时依赖ruby,puppet,facter等工具,还有它也依赖一些监控工具 nagios 和 ganglia 用于监控集群状况。
-
Ambari-server:主要管理部署在每个节点上的管理监控程序。 -
Ambari-agent:部署在监控节点上运行的管理监控程序。 -
ambari-web:作为用户与 Ambari server 交互的。
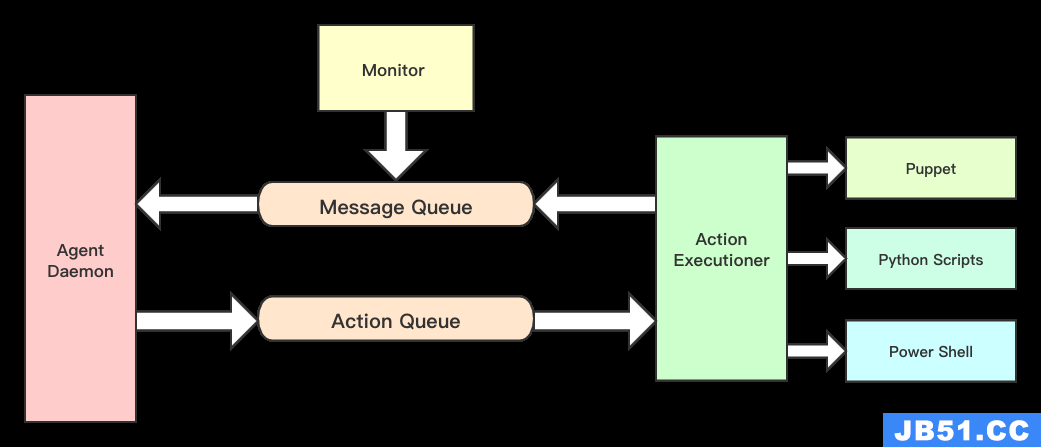
1)Ambari-agent 内部架构
Ambari-agent是一个无状态的,其功能分两部分:
- 采集所在节点的信息并且汇总发送心跳发送汇报给ambari-server。
- 处理ambari-server的执行请求。
因此它有两种队列:
-
消息队列
Message Queue,或称为ResultQueue。包括节点状态信息(包括注册信息)和执行结果信息,并且汇总后通过心跳发送给ambari-server。 -
操作队列
ActionQueue。用于接收ambari-server发送过来的状态操作,然后交给执行器调用puppet或Python脚本等模块执行任务。
2)Ambari-server 内部架构
三种状态:
-
Live Cluster State:集群现有状态,各个节点汇报上来的状态信息会更改该状态; -
Desired State:用户希望该节点所处状态,是用户在页面进行了一系列的操作,需要更改某些服务的状态,这些状态还没有在节点上产生作用; -
Action State:操作状态,是状态改变时的请求状态,也可以看作是一种中间状态,这种状态可以辅助LiveCluster State向Desired State状态转变。
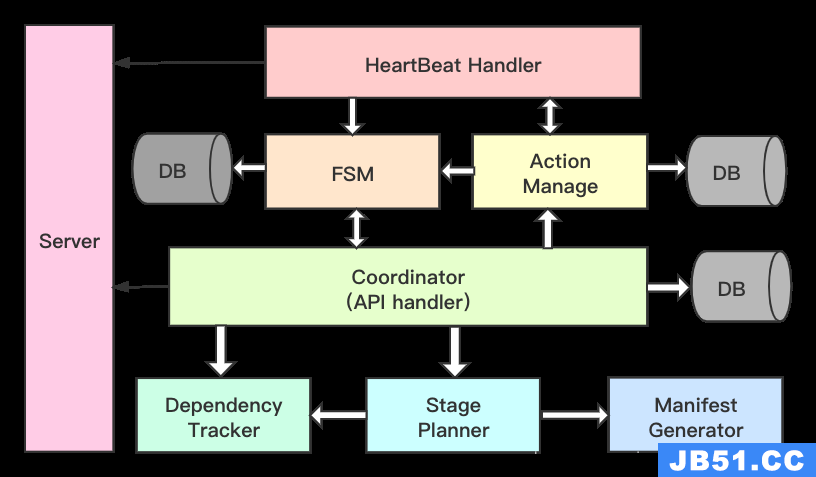
-
Heartbeat Handler模块用于接收各个agent的心跳请求(心跳请求里面主要包含两类信息:节点状态信息和返回的操作结果),把节点状态信息传递给FSM状态机去维护着该节点的状态,并且把返回的操作结果信息返回给Action Manager去做进一步的处理。 -
Coordinator模块又可以称为API handler,主要在接收WEB端操作请求后,会检查它是否符合要求,stageplanner分解成一组操作,最后提供给ActionManager去完成执行操作。
因此,从上图就可以看出,Ambari-Server的所有状态信息的维护和变更都会记录在数据库中,用户做一些更改服务的操作都会在数据库上做一些相应的记录,同时,agent通过心跳来获得数据库的变更历史。
3)Ambari-web 内部架构
Ambari-web 使用了一个流行的前端 Embar.js MVC 框架实现,Embar.js 是一个 TodoMVC 框架,它涵盖了现今典型的单页面应用(single page application)几乎所有的行为。使用了 nodejs。使用 brunch 作为项目的构建管理工具。
Brunch 是一个超快的HTML5构建工具。它有如下功能:
-
编译你的脚本、模板、样式、链接它们。
-
将脚本和模板封装进common.js/AMD模块里,链接脚本和样式。
-
为链接文件生成源地图,复制资源和静态文件。
-
通过缩减代码和优化图片来收缩输出,看管你的文件更改。
-
并通过控制台和系统提示通知你错误。
Nodejs 是一个基于Chrome JavaScript 运行时建立的一个平台,用来方便的搭建快速的易于扩展的网络应用,NodeJS 借助事件驱动,非阻塞I/O模型变得轻量和高效,非常适合运行在分布式设备的数据密集型的实时应用。
1、Ambari-web 目录结构
| 目录或文件 | 描述 |
|---|---|
| app/ | 主要应用程序代码。包括Ember中的view、templates、controllers、models、routes |
| config.coffee | Brunch应用程序生成器的配置文件 |
| package.json | Npm包管理配置文件 |
| test/ | 测试文件 |
| vendor/ | Javascript库和样式表适用第三方库。 |
2、Ambari-web/app/
| 目录或文件 | 描述 |
|---|---|
| assets/ | 静态文件 |
| controllers/ | 控制器 |
| data/ | 数据 |
| mappers/ | JSON数据到Client的Ember实体的映射 |
| models | MVC中的Model |
| routes/ | 路由器 |
| styles | 样式文件 |
| views | 试图文件 |
| templates/ | 页面模板 |
| app.js | Ember主程序文件 |
| config.js | 配置文件 |
七、Apache Ambari 安装
1)前期准备
1、机器信息
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.182.110 | local-168-182-110 | master |
| 192.168.182.111 | local-168-182-111 | slave |
| 192.168.182.112 | local-168-182-112 | slave |
2、配置 /etc/hosts
192.168.182.110 local-168-182-110
192.168.182.111 local-168-182-111
192.168.182.112 local-168-182-112
3、配置互信
### 在master节点上生成公钥
ssh-keygen -t rsa -P ""
### 参数解释:
# -t 参数表示生成算法,有rsa和dsa两种;
# -P表示使用的密码,这里使用""空字符串表示无密码。
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
ssh-copy-id -i ~/.ssh/id_rsa.pub local-168-182-111
ssh-copy-id -i ~/.ssh/id_rsa.pub local-168-182-112
4、配置时间同步(非常重要)
yum install chrony -y
# 配置
echo 'server ntp1.aliyun.com iburst' >> /etc/chrony.conf
systemctl start chronyd
systemctl enable chronyd
# 查看时间同步情况
chronyc sources -v
5、关闭防火墙
systemctl disable firewalld
systemctl stop firewalld
6、禁用 SELINUX
# 临时关闭
setenforce 0
# 永久禁用
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
2)安装 JDK
官网下载:https://www.oracle.com/java/technologies/downloads/
百度云下载
链接:https://pan.baidu.com/s/1-rgW-Z-syv24vU15bmMg1w
提取码:8888
# 编辑/etc/profile,文末插入以下内容:
# set java
export JAVA_HOME=/usr/java/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
加载生效
source /etc/profile
3)安装 mysql
如果想快速安装MySQL,仅仅只是学习或测试用,可以参考我这篇通过docker部署MySQL的文章:通过 docker-compose 快速部署 MySQL保姆级教程
# 登录mysql
mysql -uroot -p12346
4)获取 Ambari 安装包
编译过程中可能会遇到很多问题,这里就不一一列举了,可关注我公众号 大数据与云原生技术分享 回复 hdp 获取已编译好的安装包。
其中安装包说明:
-
Ambari:WEB应用程序,后台为Ambari Server,负责与HDP部署的集群工作节点进行通讯,集群控制节点包括Hdfs,Spark,Zk,Hive,Hbase等等。 -
HDP:HDP包中包含了很多常用的工具,比如Hadoop,Hive,Hbase,Spark等 -
HDP-UTIL:是HDP的另一个软件包,它包含了一些额外的实用工具和服务,用于增强HDP的功能和管理能力。这些实用工具和服务可以与HDP集群一起使用,以提供更多的功能和工具支持。 -
HDP-GPL:是HDP的一部分,它包含了HDP中使用的开源软件的源代码,这些软件遵循GPL(GNU通用公共许可证)或其他开源许可证。
5)安装 httpd 搭建本地安装源
### 1、安装httpd
yum -y install httpd
### 2、在/var/www/html下创建ambari和hdp目录
cd /var/www/html/
mkdir ambari
### 3、上传资源包
# 上传ambari-2.7.5.0-centos7.tar、HDP-3.1.5.0-centos7-rpm.tar、HDP-GPL-3.1.5.0-centos7-gpl.tar、HDP-UTILS-1.1.0.22-centos7.tar
### 4、解压到指定目录
tar -zxvf /opt/apache/ambari/ambari-2.7.5.0-centos7.tar -C /var/www/html/ambari/
tar -zxvf /opt/apache/ambari/HDP-3.1.5.0-centos7-rpm.tar -C /var/www/html/ambari/
tar -zxvf /opt/apache/ambari/HDP-GPL-3.1.5.0-centos7-gpl.tar -C /var/www/html/ambari/
tar -zxvf /opt/apache/ambari/HDP-UTILS-1.1.0.22-centos7.tar -C /var/www/html/ambari/
### 5、启动httpd
systemctl restart httpd
web访问:
现在可以通过访问http://192.168.182.110/ambari/查看是否能成功访问
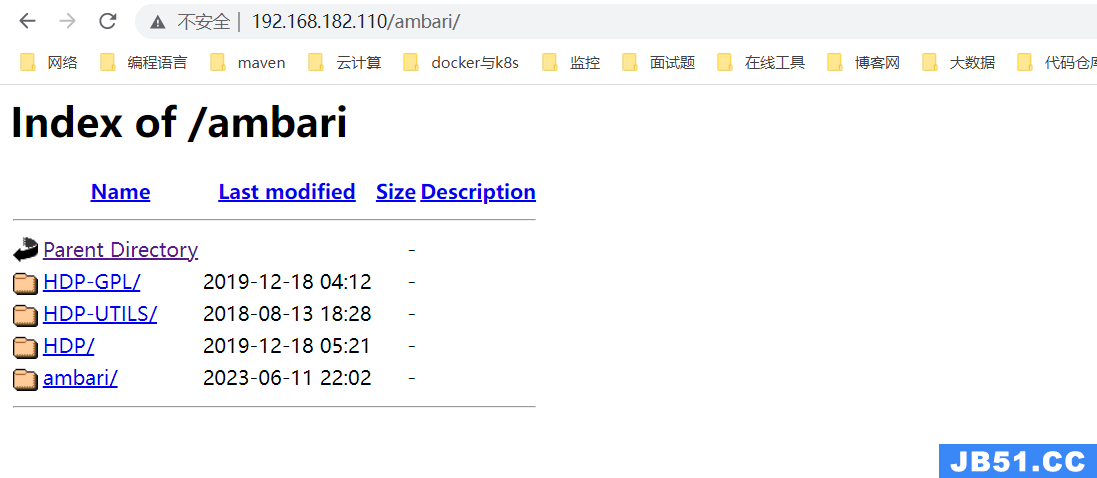
6)配置Ambari+HDP本地yum源
1、 安装本地源制作相关工具
yum install -y yum-utils createrepo yum-plugin-priorities
2、配置 ambari.repo
# /etc/yum.repos.d/ambari.repo
#VERSION_NUMBER=2.7.5.0-72
[ambari-2.7.5.0]
#json.url = http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json
name=ambari Version - ambari-2.7.5.0
baseurl=http://192.168.182.110/ambari/ambari/centos7/2.7.5.0-72/
gpgcheck=1
gpgkey=http://192.168.182.110/ambari/ambari/centos7/2.7.5.0-72/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
3、配置 hdp.repo
# /etc/yum.repos.d/hdp.repo
#VERSION_NUMBER=3.1.5.0-152
[HDP-3.1.5.0]
name=HDP Version - HDP-3.1.5.0
baseurl=http://192.168.182.110/ambari/HDP/centos7/3.1.5.0-152/
gpgcheck=1
gpgkey=http://192.168.182.110/ambari/HDP/centos7/3.1.5.0-152/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.22]
name=Hortonworks Data Platform Utils Version - HDP-UTILS-1.1.0.22
baseurl=http://192.168.182.110/ambari/HDP-UTILS/centos7/1.1.0.22/
gpgcheck=1
gpgkey=http://192.168.182.110/ambari/HDP-UTILS/centos7/1.1.0.22/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
4、将创建好的文件拷贝到子节点
scp /etc/yum.repos.d/ambari.repo 192.168.182.111:/etc/yum.repos.d/
scp /etc/yum.repos.d/hdp.repo 192.168.182.111:/etc/yum.repos.d/
scp /etc/yum.repos.d/ambari.repo 192.168.182.112:/etc/yum.repos.d/
scp /etc/yum.repos.d/hdp.repo 192.168.182.112:/etc/yum.repos.d/
最后执行
yum clean all && yum makecache
6)开始安装 ambari
1、安装 ambari-server
yum -y install ambari-server
2、创建用户和数据库
#在mysql上创建 database ambari;
mysql -uroot -p123456
# 创建数据库
create database ambari;
create database ambari character set utf8 ;
CREATE USER 'ambari'@'%'IDENTIFIED BY 'ambari';
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'%';
FLUSH PRIVILEGES;
# 创建数据库
create database hive;
#创建 hive用户
create database hive character set utf8 ;
CREATE USER 'hive'@'%'IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%';
FLUSH PRIVILEGES;
# 创建 oozie 用户
create database oozie character set utf8 ;
CREATE USER 'oozie'@'%'IDENTIFIED BY 'oozie';
GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'%';
FLUSH PRIVILEGES;
3、将Ambari数据库脚本导入到数据库
#在mysql上创建 database ambari;
mysql -uroot -p123456
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
4、下载mysql驱动
下载地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/
wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.39/mysql-connector-java-5.1.39.jar
mkdir /usr/share/java
cp mysql-connector-java-5.1.39.jar /var/lib/ambari-server/resources/
cp mysql-connector-java-5.1.39.jar /usr/share/java/
cp mysql-connector-java-5.1.39.jar /usr/lib/ambari-server/
5、配置 ambari-server
[root@local-168-182-110 ambari]# ambari-server setup
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'disabled'
Customize user account for ambari-server daemon [y/n] (n)? y
Enter user account for ambari-server daemon (root):root
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 2
WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts.
WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts.
Path to JAVA_HOME: /opt/jdk1.8.0_212
Validating JDK on Ambari Server...done.
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? y
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL / MariaDB
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
[7] - BDB
==============================================================================
Enter choice (1): 3
Hostname (localhost): 192.168.182.110
Port (3306): 13306
Database name (ambari):
Username (ambari): ambari
Enter Database Password (bigdata):
Re-enter password:
Configuring ambari database...
Enter full path to custom jdbc driver: /usr/share/java/mysql-connector-java-5.1.39.jar
Configuring remote database connection properties...
WARNING: Before starting Ambari Server,you must run the following DDL directly from the database shell to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
Proceed with configuring remote database connection properties [y/n] (y)? y
Extracting system views...
ambari-admin-2.7.5.0.72.jar
....
Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json,updating stacks repoinfos with it...
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
6、启动 ambari
ambari-server start
注意:如果出现
Server not yet listening on http port 8080 after 50 seconds. Exiting异常执行以下语句:
echo 'server.startup.web.timeout=120' >> /etc/ambari-server/conf/ambari.properties
浏览器访问: http://192.168.182.110:8080/
默认登录用户:admin,密码:admin
7)通过 Ambari Web UI 部署大数据组件
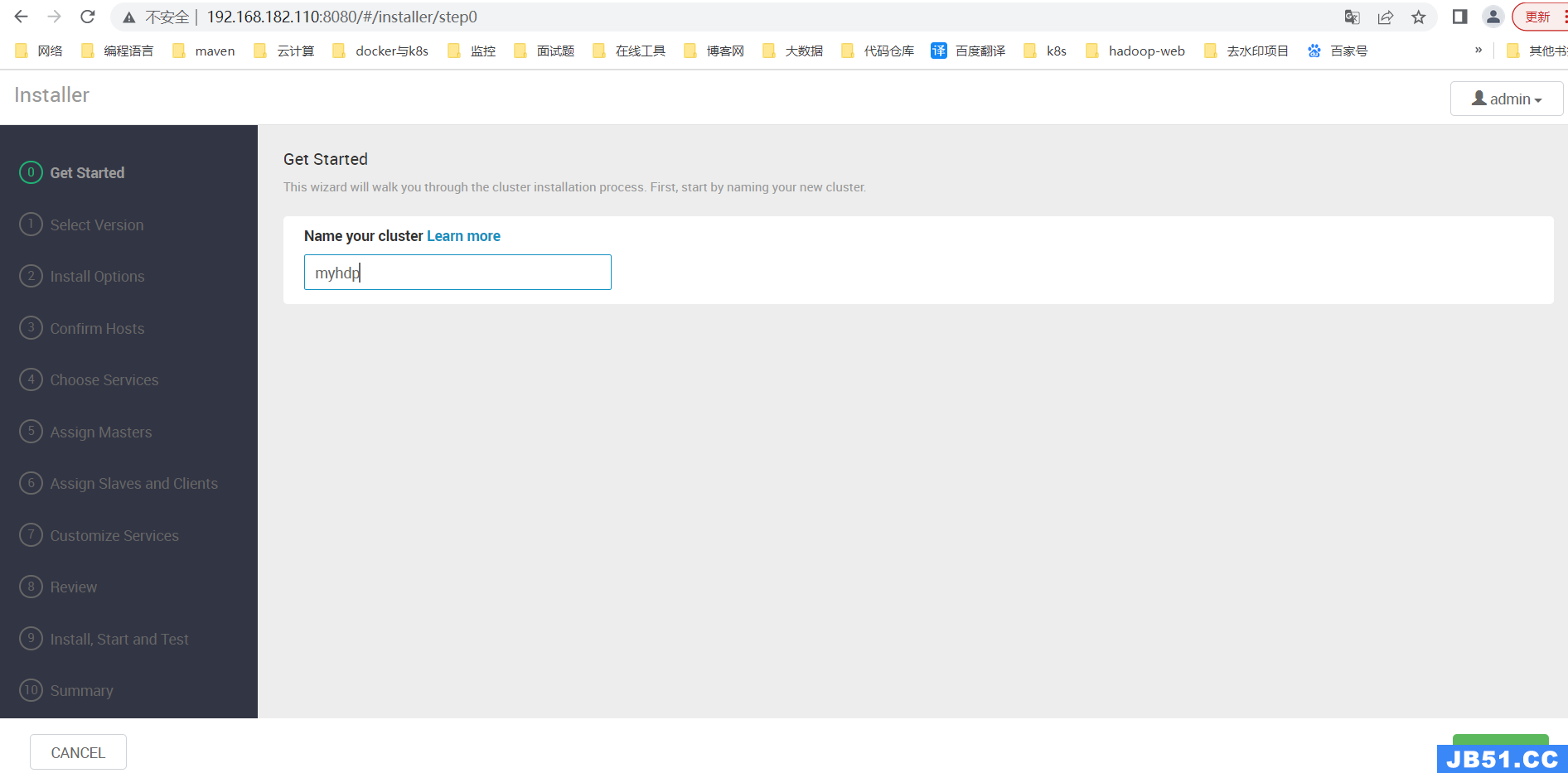
【第一步】设置集群名称
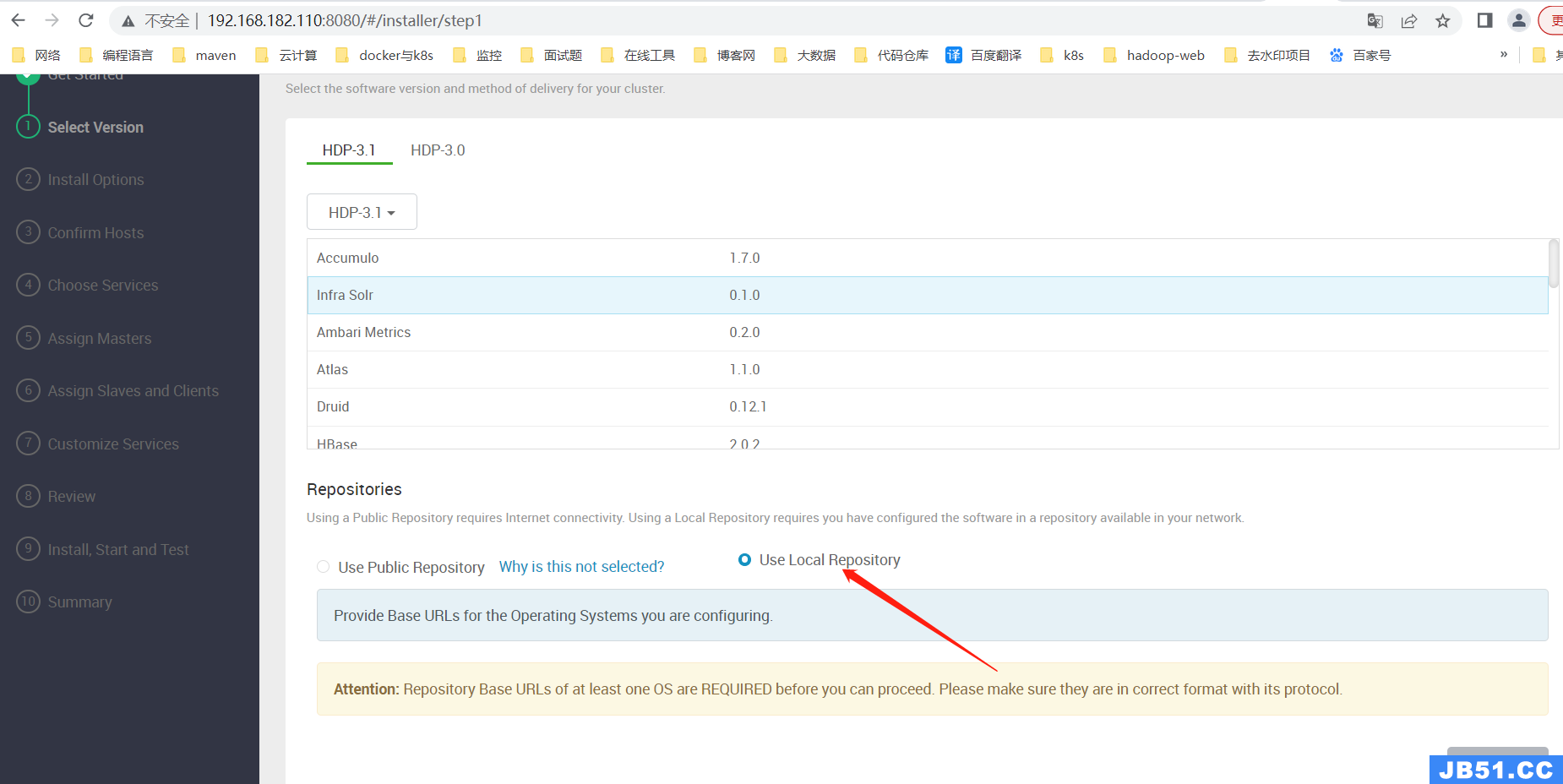
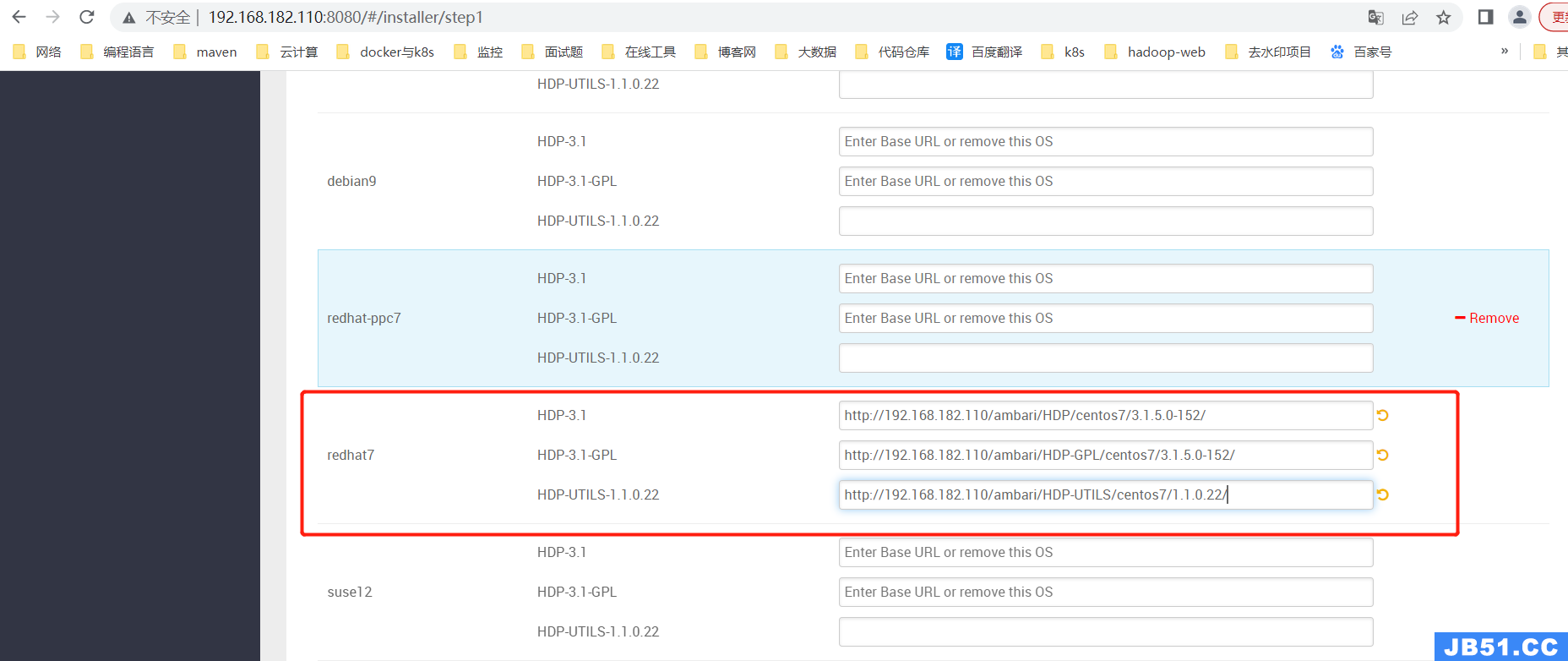
【第二步】配置本地镜像仓库
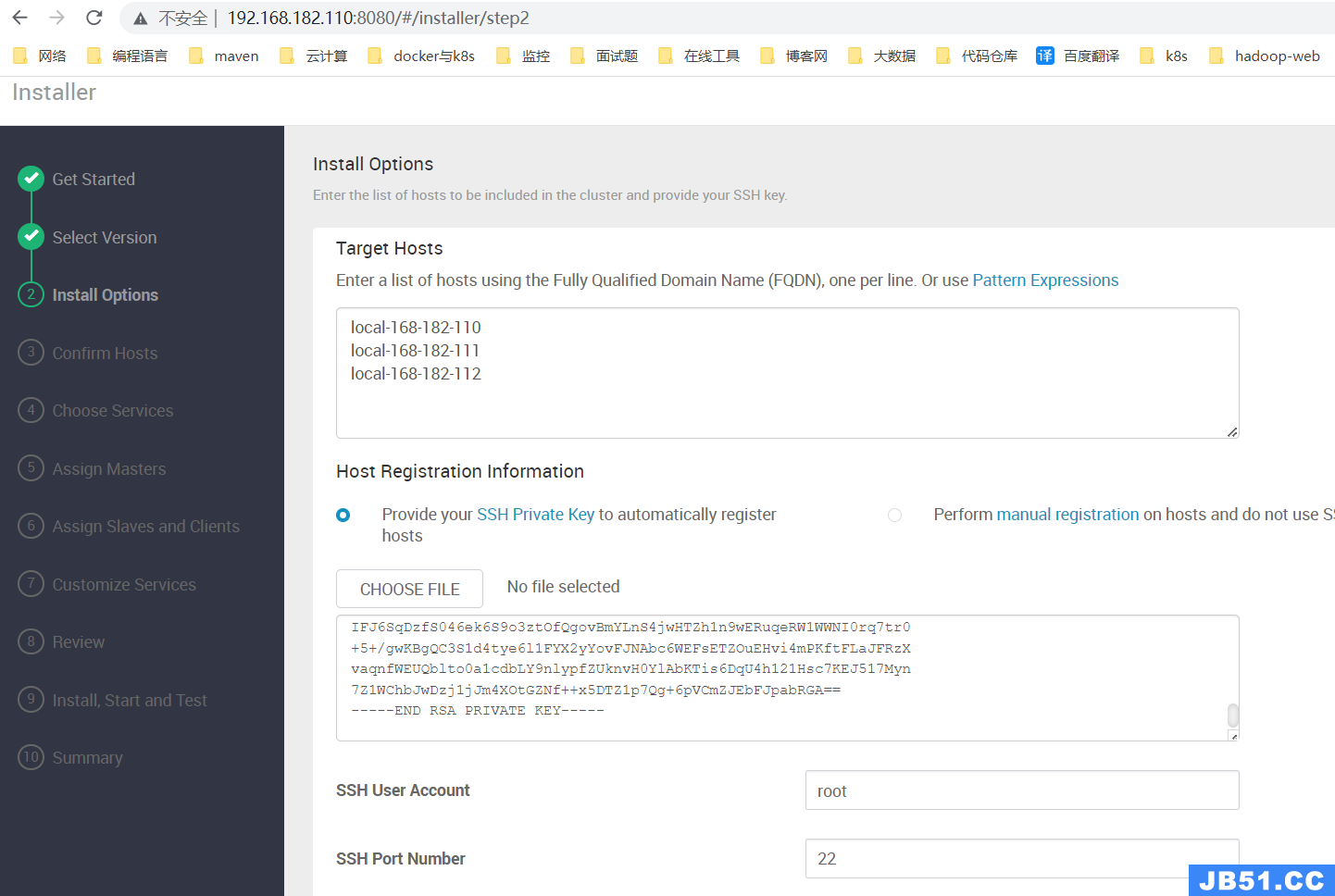
【第三步】输入集群节点host(FQDN)和Ambari-Server节点SSH的私钥
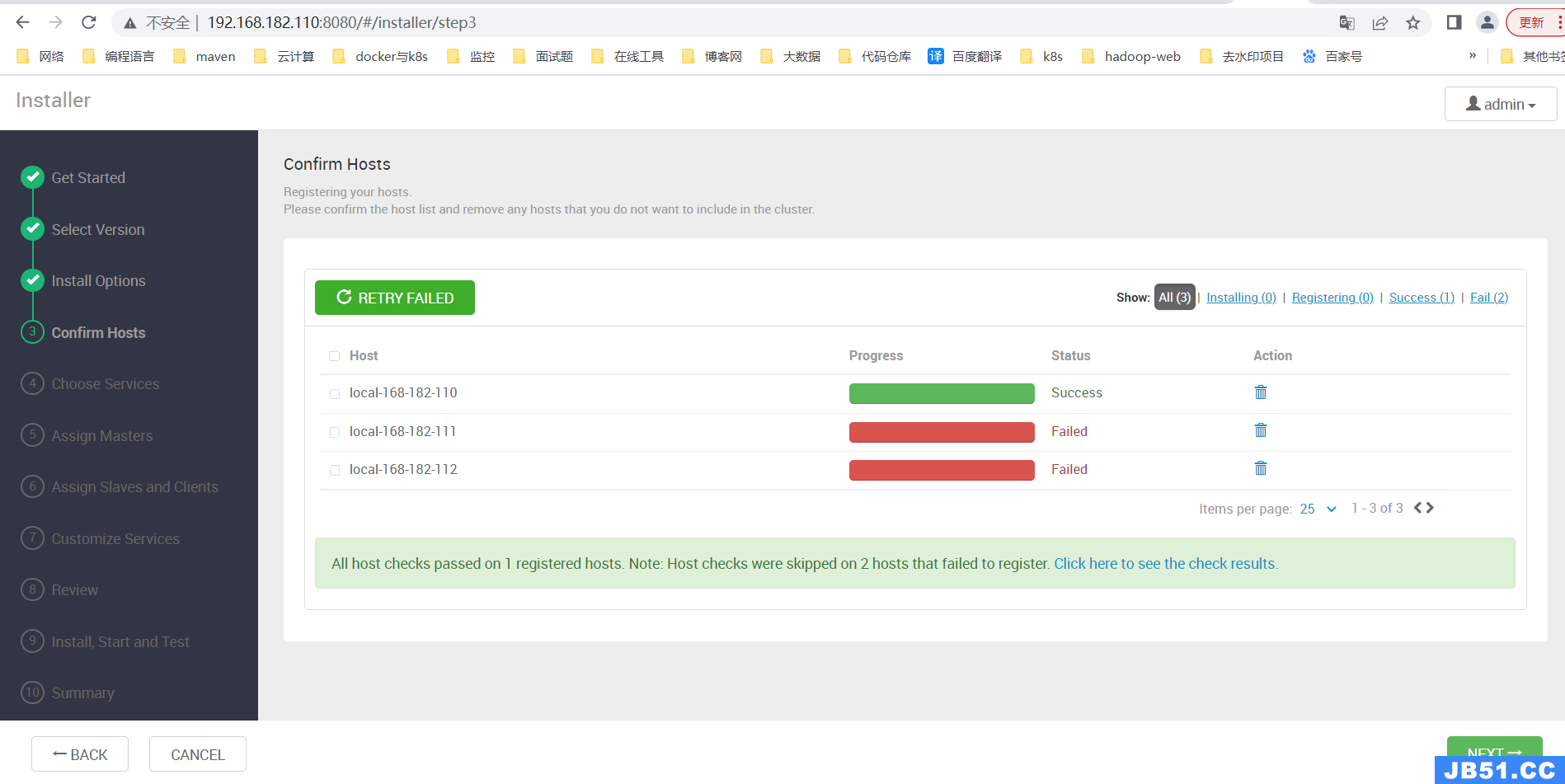
因为机器资源有限,只启动了一个节点
【第四步】选择需要安装的大数据组件
因我电脑资源有限,就选择了一个了。小伙伴根据需要选择对应的大数据组件。
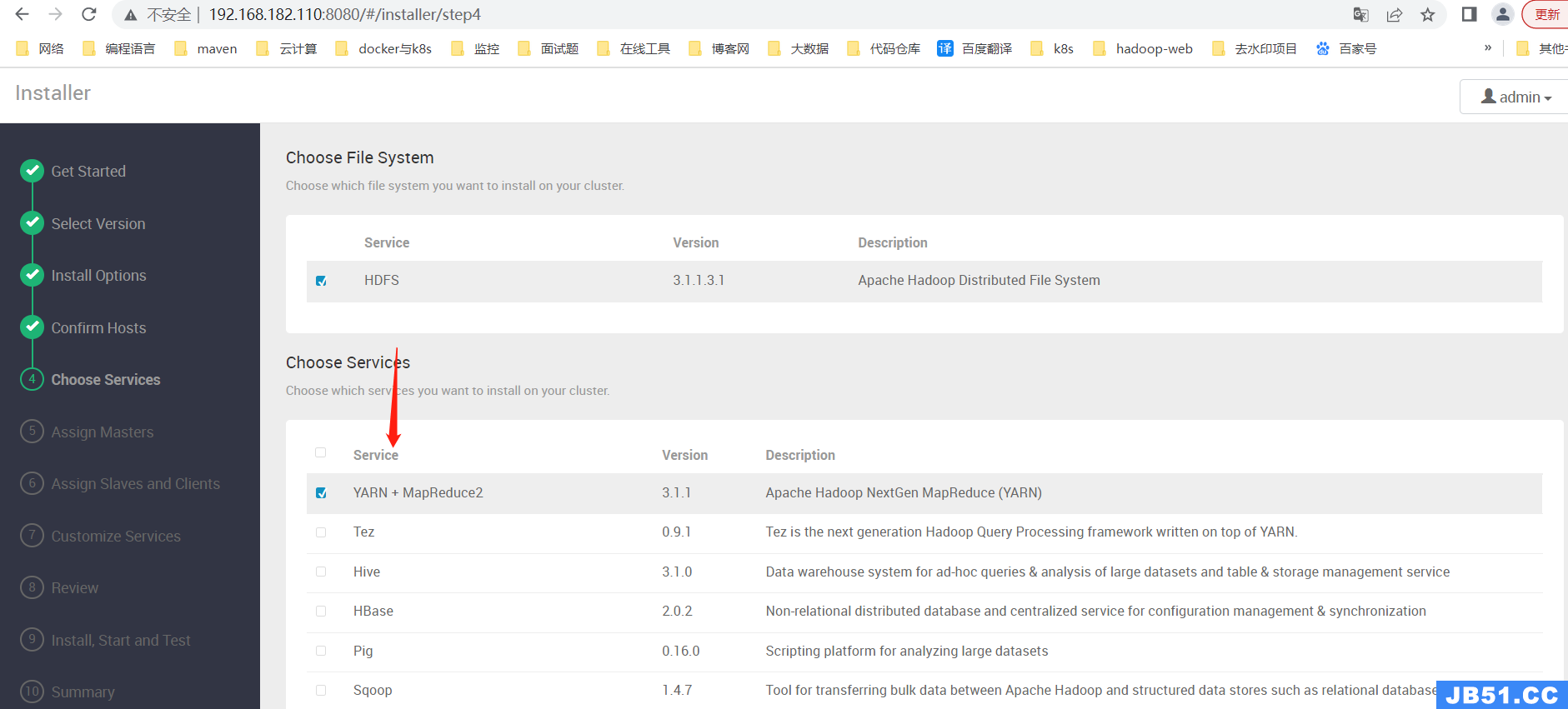
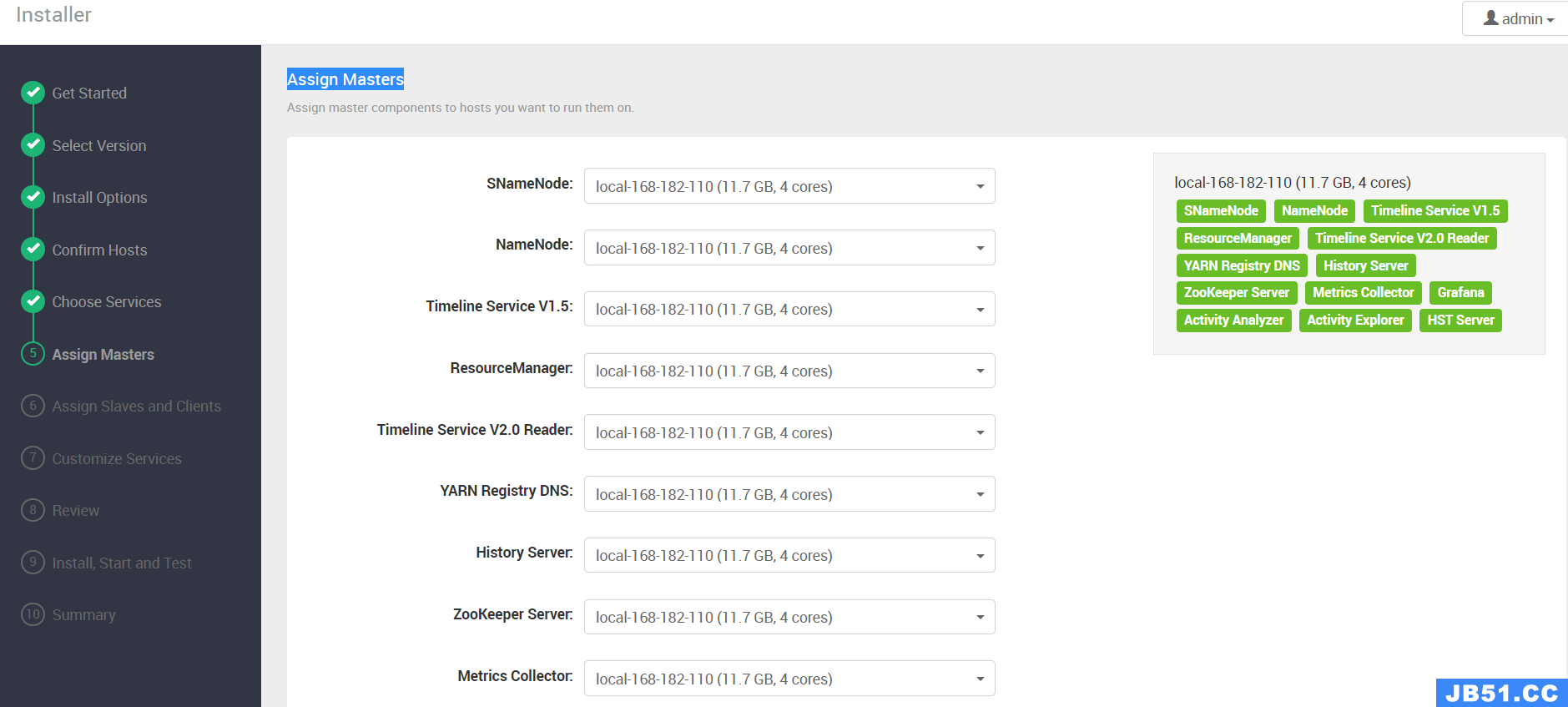
【第五步】Assign Masters
【第六步】Assign Slaves and Clients

【第七步】Customize Services

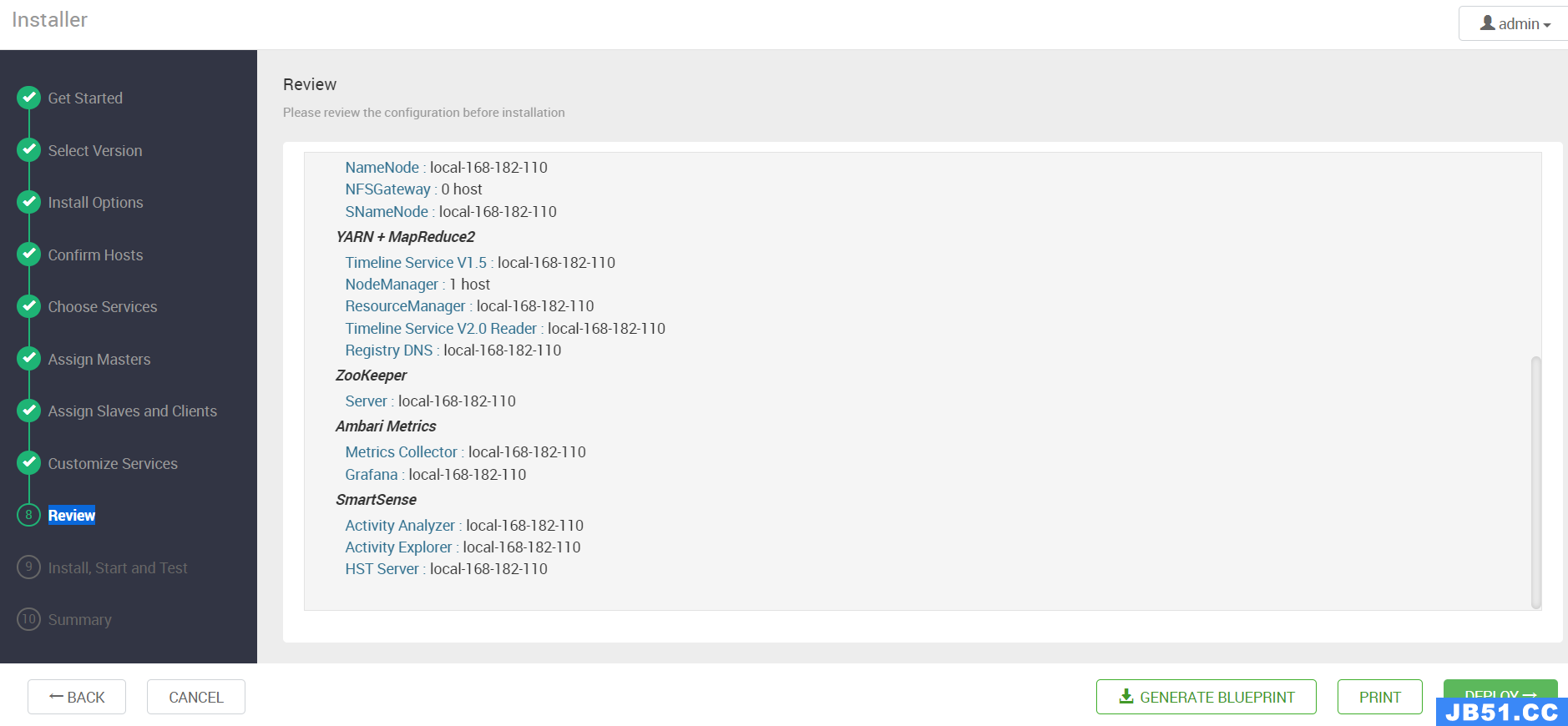
【第八步】Review
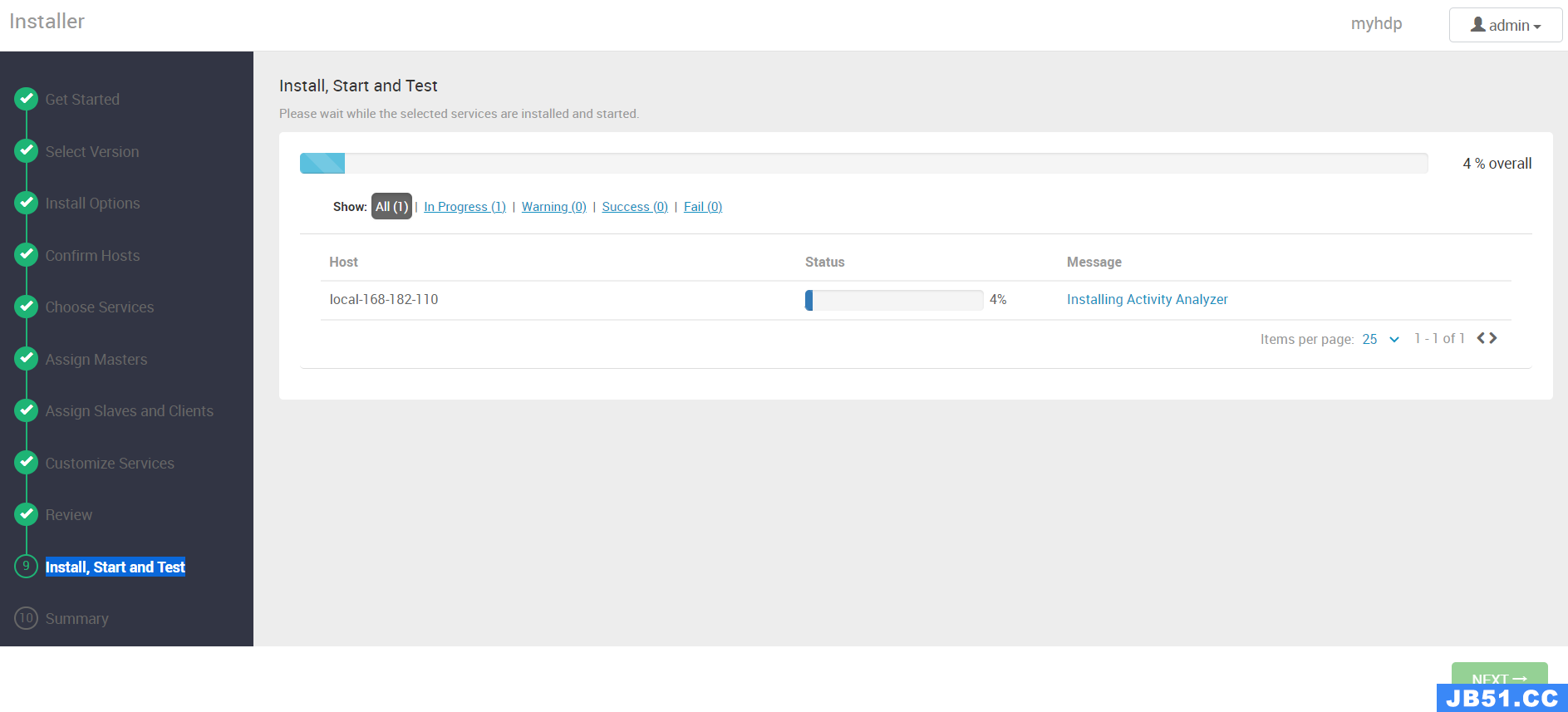
【第九步】Install,Start and Test
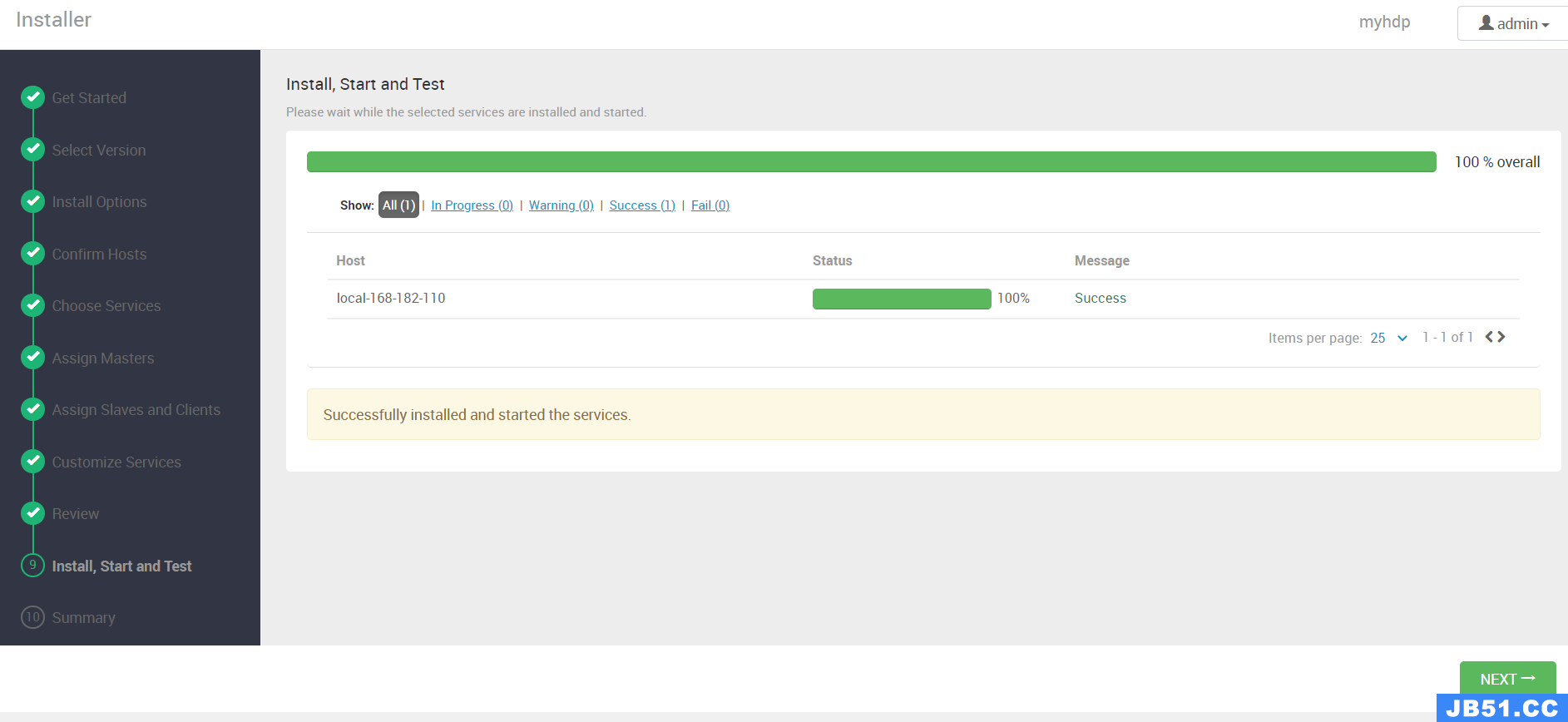
【第十步】Summary
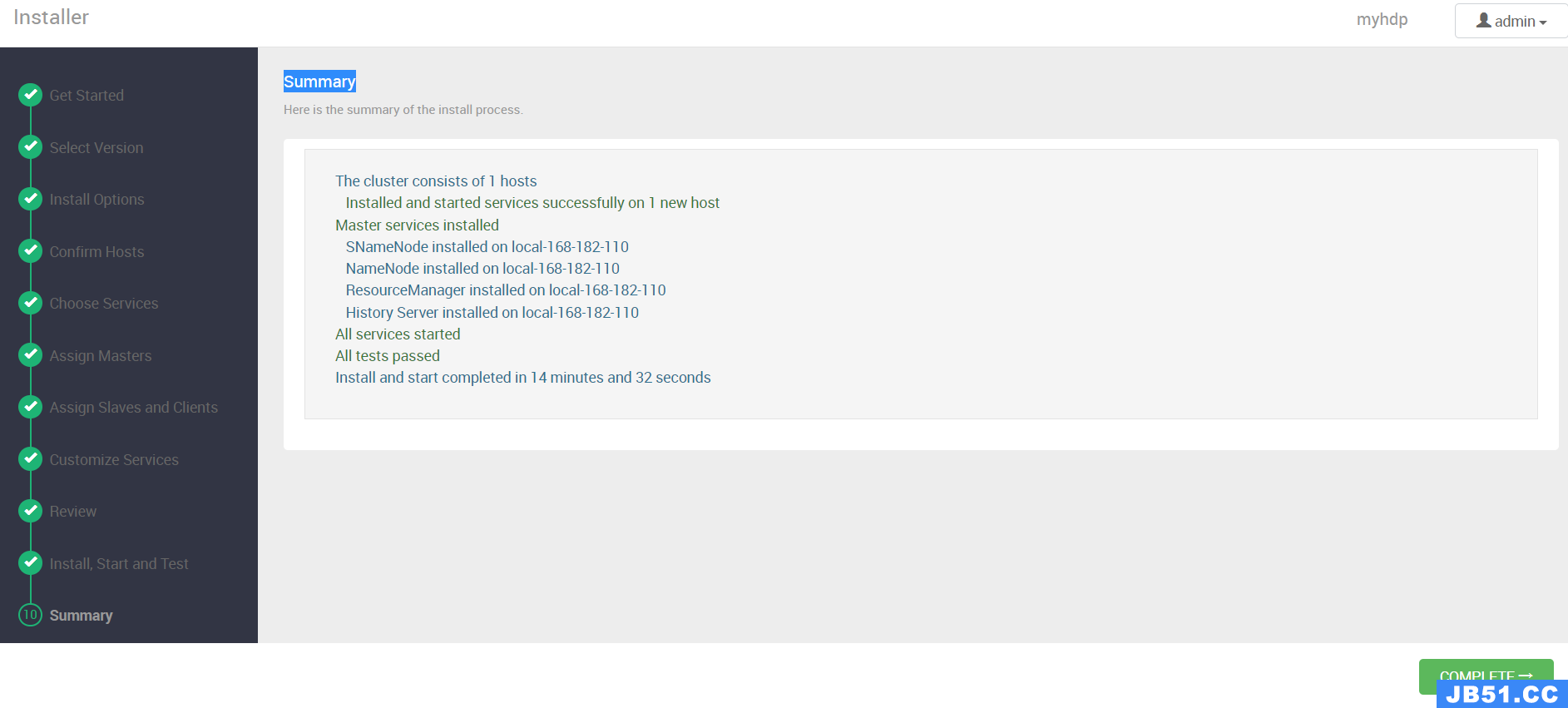
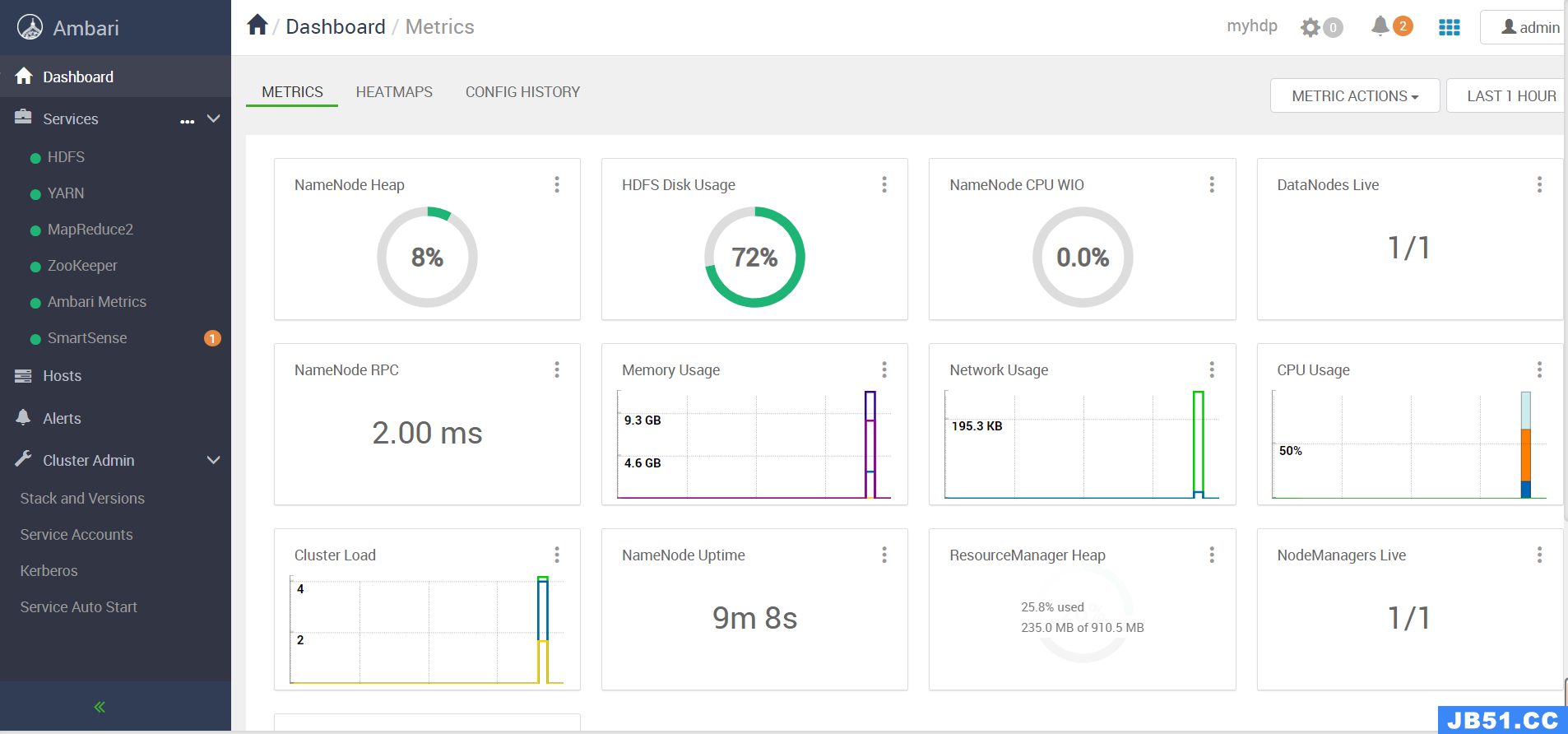
到此部署就完成了,下面就是Hadoop生态组件的监控面板。
到这里 大数据 Hadoop 管理工具 Apache Ambari 部署以及通过 Ambari 部署大数据组件教程就结束了,有任何疑问关注公众号
大数据与云原生技术分享 加群交流或私信沟通,相关的软件包在公众号回复 hdp 即可获取。原文地址:https://blog.csdn.net/qq_35745940/article/details/131028832
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 dio@foxmail.com 举报,一经查实,本站将立刻删除。